基于python的618电商价格分析
-
云服务器:ESC Ubuntu 16.04 x64
-
PhantomJS:beta-Linux-ubuntu-xenial 2.1.1
-
Python 2.7.12
前言
好久没玩点有意思的了,这次借618这个购物节,自己也要搞台mbp,顺便搞一波大新闻。
内容
对某宝的其中四家店,再加上某东一家店,对比同一款机型,对价格进行监控,至于监控时间,大概是不间断的监控吧,还有邮件提醒哦~

涉及面
-
爬虫中阶知识,因为涉及到动态页面抓取,一个页面对不同型号进行点击操作,之后再获取元素,使用了phantomjs包
-
python字符串处理中阶知识,涉及到数据清洗,重构,还有缺失值的填充,这次没用pandas进行处理,直接用的是字符串处理技巧
-
因为需要进行数据分析展示,故需要初级的JavaScript知识以及echarts的了解,这次构图使用的是echarts,比较简单
开搞-数据挖掘
因为涉及到商家利益,具体的代码细节将不再展开。
流程和以前的动态页面抓取一致,选择需要的url之后进行元素点击操作,目的是为了选中需要比较价格的机型,这都么有问题,主要将一些注意点
-
Q:元素加载过程中出现can't find element问题 A: 首先确定自己的元素位置是否写对,建议使用xpath的方法定位元素,再chrom上直接可用copy xpath,其余都对的情况可以加上wait等待时间, 参考这里
-
Q:如果ip被封了,connection refused A: 请参考 Python爬虫防封杀方法集合
-
Q:动态页面加载过程中,商家交换了商品的次序,导致获取到的div位置不正确,怎么办? A: 解决方法,额,我是每天看一下log,看看有没有不正常的,不正常就kill任务然后修改位置,再接着跑,一般来说,商家不会闲着无聊去修改位置的,另一个解法是对之后的结果手动清洗,如果价格与之前的价格差值大过一定范围,则直接认为是噪声数据,毕竟,怎么可能价格涨跌超过1000的呢,还有一个解法是,确定点击元素的值代表是什么型号,然后点击的价格就是什么型号的了,这个我懒得做了。。。。
-
Q:我想要及时知道哪家店价格已经到我的接受阈值了,怎么通知我? A:写监控邮件,当价格低于某个阈值,直接触发邮件功能,邮件如何书写,请参考,这个是直接可用的 @Kevin_zhai的博客 不再赘述
开搞-数据处理
数据请从同目录下的0613_0621pricedetail进行下载 ;这代码没啥,就是处理一些细节注意,数据抓取的形式也给出,可以套用理解。我最后的目的是获取价格变动的时间戳,不管哪家变动,都获取,然后把值都给选出来,这里有一些问题的是脏数据的处理,还有就是阈值的设定,毕竟某东的优惠券是800这个幅度的,,,,
```python import time
def timestamp(t):
timeArray = time.strptime(t, "%Y-%m-%d %H:%M:%S")
timeStamp = int(time.mktime(timeArray))
return timeStamp
''' 数据形式 '''
2017-06-10 17:24:56|京东|原始价格:8998.0|优惠券:满8000减800|到手价格:8198.0|价格趋势:-
2017-06-10 17:24:56|淘宝_A|原始价格:7890.0|运费:免运费|到手价格:7890.0|价格趋势:-
2017-06-10 17:24:56|淘宝_B|原始价格:7800.0|运费:39.0|到手价格:7839.0|价格趋势:-
2017-06-10 17:24:56|淘宝_C|原始价格:7800.0|运费:30.0|到手价格:7830.0|价格趋势:-
2017-06-10 17:24:56|淘宝_D|原始价格:7750.0|运费:免运费|到手价格:7750.0|价格趋势:-
2017-06-10 17:24:56|最优价格方:淘宝_D|目前最低到手价格:7750.0|历史最低价:7750.0|价格趋势:-
shop = {} with open('/Users/mrlevo/Desktop/project/0613_0621pricedetail') as f: for line in f: linesplit = line.split("|") if ':' in linesplit[1]: # 剔除最优价格方的记录 pass else: needline = str(linesplit[0]) + '|' + linesplit[-2].split(':')[-1] # 获取时间戳和到手价格,毕竟分析的时候只需要这两个就行 if linesplit[1] not in shop: # 进行字典的构建,里面存储list shop[linesplit[1]]=[] shop[linesplit[1]].append(needline) # 预处理-替换缺失值,向上替换,pandas里有直接的方法,这里选择字符串处理方法 if shop[linesplit[1]][-1].split("|")[-1]=='None': shop[linesplit[1]][-1] = shop[linesplit[1]][-1].split("|")[0] + '|' + shop[linesplit[1]][-2].split("|")[-1] t +=1 else: pass # 预处理-波动异常点-由于抓取的时候店家对链接的修改,导致元素异位
try:
if ((float(shop[linesplit[1]][-1].split("|")[-1]) > float(shop[linesplit[1]][-2].split("|")[-1])+500) or (float(shop[linesplit[1]][-1].split("|")[-1]) < float(shop[linesplit[1]][-2].split("|")[-1])-500)) and (linesplit[1]!='京东'):
shop[linesplit[1]][-1] = shop[linesplit[1]][-1].split("|")[0] + '|' + shop[linesplit[1]][-2].split("|")[-1]
else:
pass
except Exception as ex:
print ex
def find_change_time(shop): chang_ = [] for shopname in shop.keys(): pricedetail = shop[shopname] for i in range(len(pricedetail)-2): # 最后一个时刻抛弃 split_f = pricedetail[i].split('|') split_s = pricedetail[i+1].split('|') price_f = split_f[-1] time_f = split_f[0] price_s = split_s[-1] time_s = split_s[0] if price_f == price_s: pass else: chang_.append(time_s) return chang_
获取价格变更时间戳
changtime = sorted(find_change_time(shop)) print changtime
for shopname in shop.keys(): satisfy_ = [k.split('|')[-1] for k in shop[shopname] if k.split('|')[0] in changtime] print satisfy_
```
注意:处理方式,因为只有几万条数据,我就直接采用读文件流的形式来了,数据量大的可以采用pandas和spark,这也是完全可行的
开搞-数据分析
这里就用到了前端的一点点知识了,你可以不用理解这是搞的什么,替换数据即可。

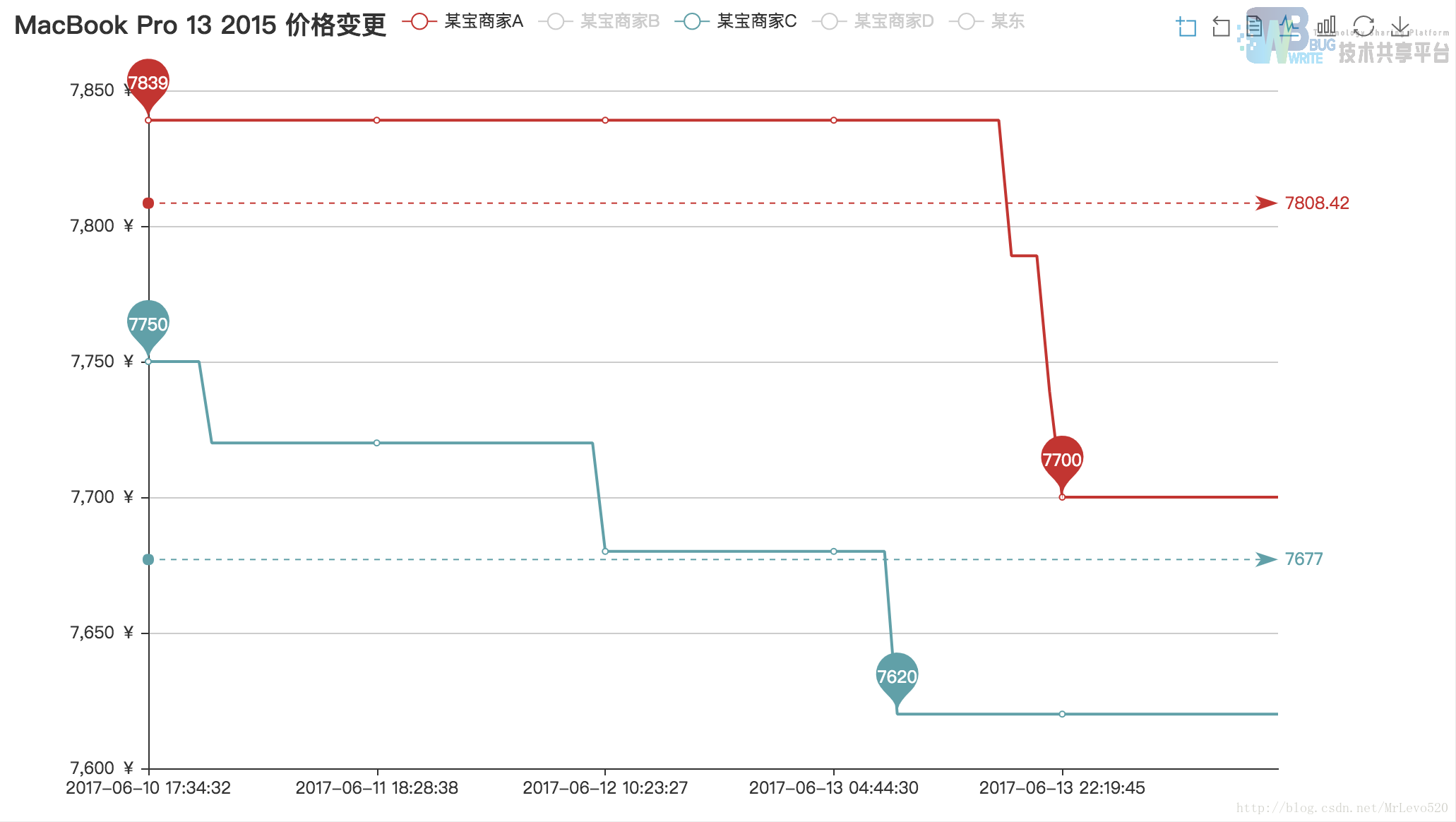
这是总体的一张图,额,我们可以,额,清楚的看到,某东的价格变动次数,相比较于某宝,额,动态调价调的起飞啊
接下来看比较细致的几张图

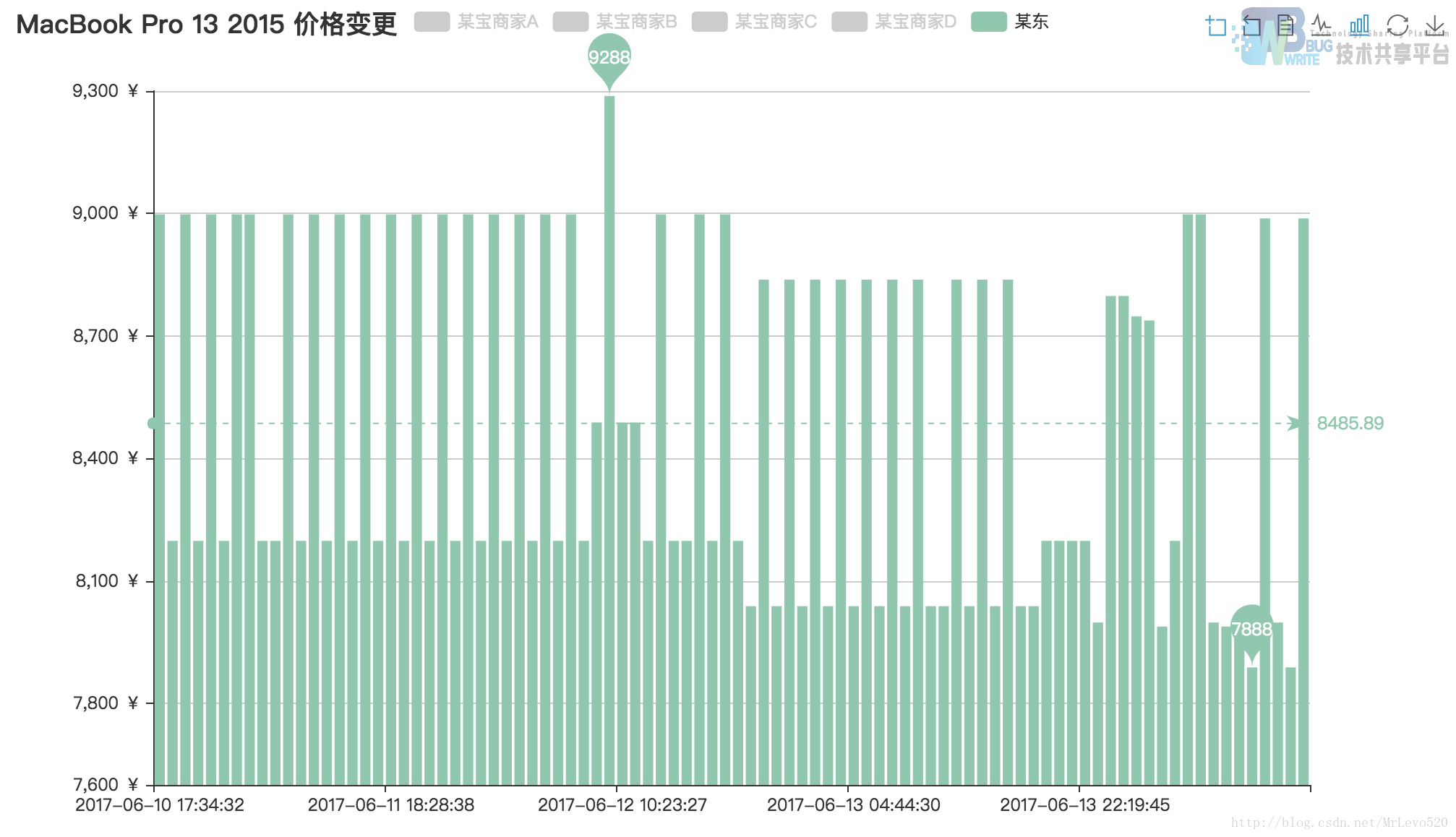
这一幅图可以看出,的确在618那一天,某东到到价格最低,但非第一次到达,我们可以看在16好16点多就又一次达到过这个价格,而相比较于某宝,商家的定价规则在15号之后就没有产生过变动,这点就有点意思了,采集的四家店的三家在13号之后都不变化,一家店最后修改价格的时间15号,嗯哼
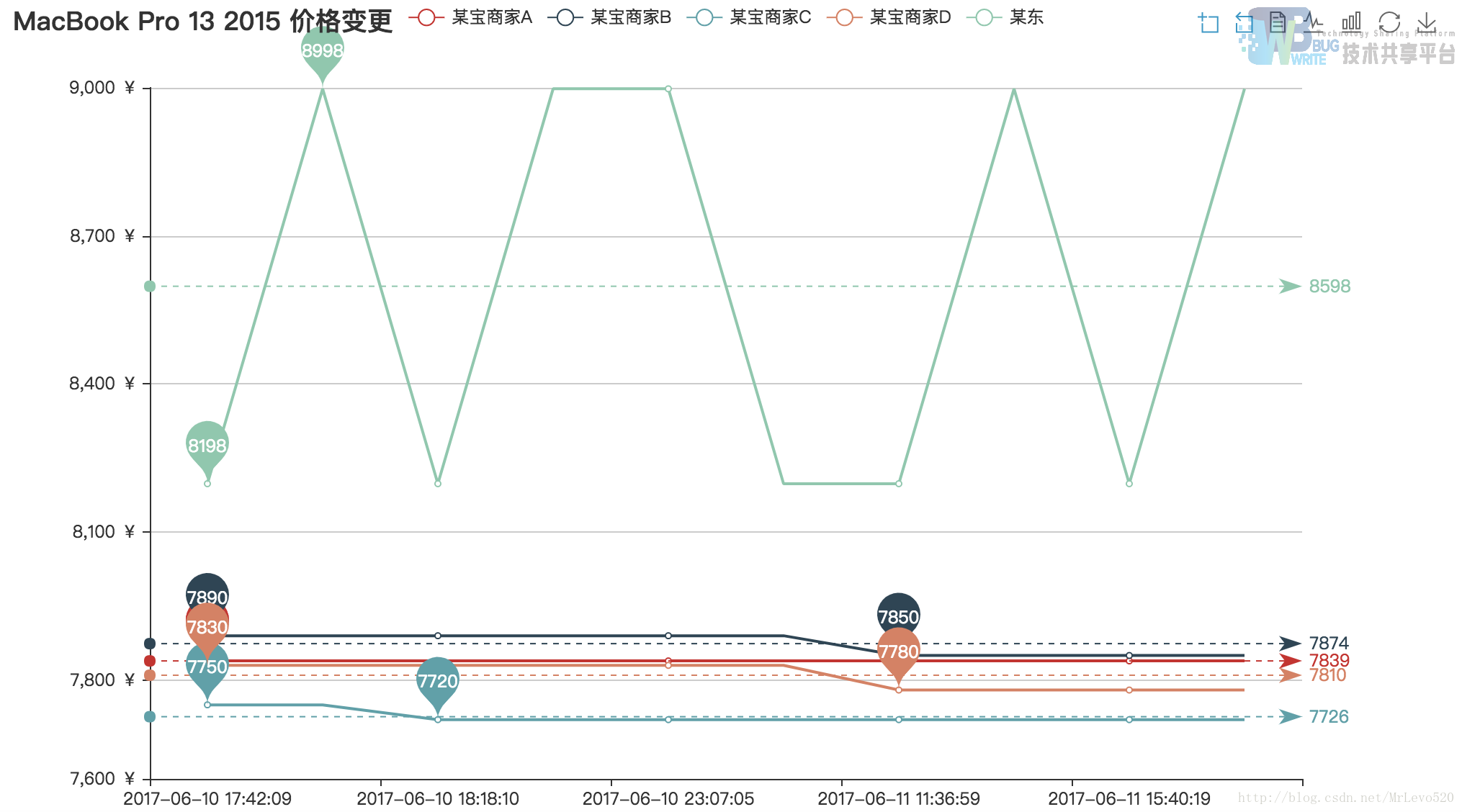
因为抖动太平凡,所以只有用柱状图来表现了
三家店的动态调价,当然趋势是向下的,而且他们的店家貌似也非常关注同行价格,会进行及时调价
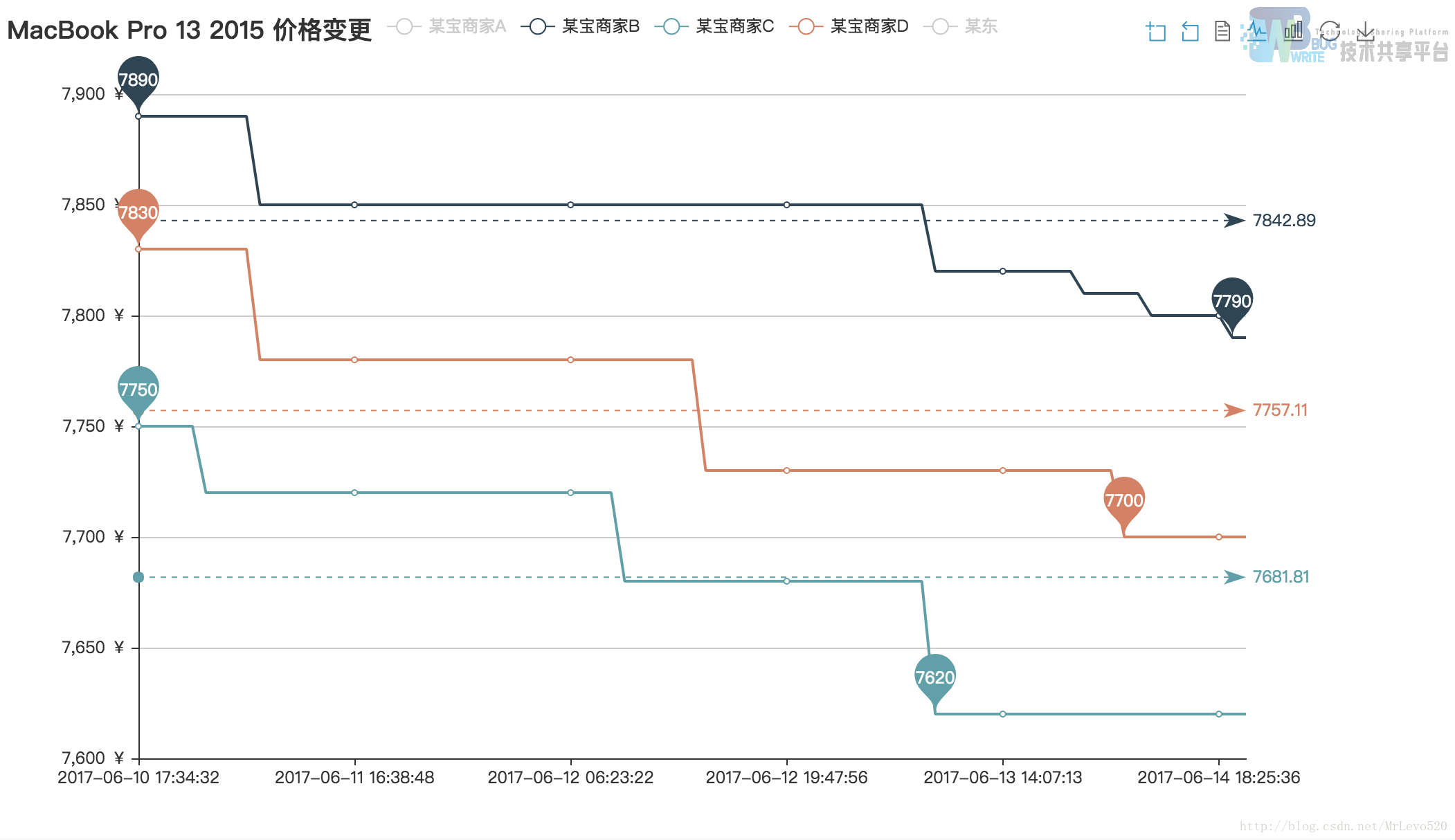
当然也有不关心价格,然后一看同行,我曹,都调价了啊,不行不行,我得赶紧的,--所以,A这家店,调价的幅度是其他三家最大的,如果大家也关注这家店,你也知道原因的,科科。

建议
-
对于节日主办方,的确可以选择那天下手,不过考虑下那天下手的代价就是快递炒鸡慢
-
对于非主场的凑热闹商家,其实商品会和主场错开峰,就像苹果开发布会,三星不也得缓缓,不能直接怼啊对不对,哈哈,所以差不多提前两三天买应该是没有问题的,当别人还在抢购的时候,你已经收到货啦。
-
土豪随意
其他
我就不过度解读了,在18号的确大家可以用最低的价格入手,但是相比较于大家不断的网络流量,这一点差价而言,我想双方都是很乐意看到的,这也就是各种大促销的由来,巴不得一年四季有个节日就搞个促销,当然,抢券这种是比较例外的,的确有很大幅度的降低价格,但还是那句话,流量。更多的数据自己挖掘请下载上述的html文件,enjoy yourself!
最后
想去做的事,就去做,不要再等了,有想法,就去实现吧!与君共勉!
参考文献
- 基于JAVA的B2C电子商城设计与实现(西安电子科技大学·胡峰)
- Web数据挖掘在电子商务中的应用研究(西安工业大学·李健森)
- 基于数据挖掘的电子商务推荐系统设计与实现(吉林大学·陈凤桃)
- 电子产品自动搜索比价系统设计与实现(山东大学·祁良武)
- 基于数据挖掘技术的电子商务推荐系统的研究(北京邮电大学·徐莉)
- 电商平台移动端网络购买预测研究——基于特征选择和分类算法(暨南大学·李国凤)
- 基于多模型融合的电商用户购买行为预测研究(东北财经大学·邵逸伦)
- 电商平台移动端网络购买预测研究——基于特征选择和分类算法(暨南大学·李国凤)
- 基于JAVA的B2C电子商城设计与实现(西安电子科技大学·胡峰)
- Web数据挖掘在电子商务中的应用研究(西安工业大学·李健森)
- 使用智能策略优化的电子商务系统设计与实现(曲阜师范大学·翟逸昕)
- 电商空调产品的评论数据情感分析(山西大学·杨瑞欣)
- 基于数据挖掘的电子商务推荐系统设计与实现(吉林大学·陈凤桃)
- 基于多模型融合的电商用户购买行为预测研究(东北财经大学·邵逸伦)
- 基于PHP+MySQL的图书在线销售系统的设计与实现(吉林大学·万颖)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头 ,原文地址:https://bishedaima.com/yuanma/35534.html