中医藏象辨证量化诊断系统
1.内容
对深度学习、集成学习等算法进行深入研究,探索利用相关算法开展中医辨证的创新研究与应用,利用相关算法实现临床数据采集、量化诊断和可视化结果展示。具体功能如下:
a) 在藏象辨证体系指导下,利用算法实现中医智能诊断,即从临床信息到中医证型的计算;
b) 利用算法对中医医案进行分析,从准确率、召回率、F1 值等比较模型优劣;多标记问题采用汉明损失、覆盖率、one-error 等进行评价;
c) 设计智能辨证程序,将算法集成到程序中,实现输入“症状信息”得“辨证结果”;
d) 设计两种用户交互模式,包括单个病人智能辨证和批量数据导入后的智能辨证;数据导入至少支持 1-2 种格式,建议采用文本、Excel 等常用格式;相关结果存储到数据库中,用于历史记录的查询;
e) 历史辨证数据的可视化结果展示,包括症状体征的分布、证型的分布等,采用图表展示。
2.意义
a) 本毕业设计课题尝试利用集成学习、深度学习等机器学习算法从中医临床数据中挖掘常见证型的量化诊断规律,形成“以数据为支撑”、“以算法为驱动”的辨证量化诊断体系,为大数据时代中医辨证研究提供参考;
b) 通过本毕业设计的实践,可以学习到中医藏象辨证理论,理解机器学习算法实现与优化原理,掌握 Web 开发技术,为进一步的科研或工作打下理论与实践基础。
本课题围绕根据中医藏象辨证理论如何利用现有的机器学习算法对中医医案、门诊病历数据进行量化诊断展开的,所以课题在理论准备阶段要通过查阅文献对以下若干问题的探讨:
a) 在中医理论的辨证论治体系中,是否存在由症状信息到证型的映射规律?
b) 现有的机器学习算法能否实现这样的映射关系?
c) 这些算法的思想、流程是什么?
d) 如何实现一个用户友好的量化诊断的系统?
本文将在查阅大量文献的基础上对以上问题进行探究与综述。
1.从症状信息量化诊断出证型这一过程的理论可行性问题
要解决这一问题,首先要弄清中医理论中辨证论治是一种怎样的模型。中医模型系统的基础是“天人合一”的思想,人体——这个宇宙及社会的相似物中的每一个成分都与自然、社会的相应部分相互联系着,人体内部的运转机制也同宇宙和社会运转的机制相似,并与之发生作用。因此,中医的诊断模型是将人体的内部结构和运转机制看作黑箱,对于人体内部的变化往往用对体外事物观察的结果去解释。[1]用符号化工具来描述这一模型就如下图 1 所示:

其中 W、X、Y、Z 为四组内部相互之间有特定关系的直观事物,W 表示对人体产生作用和影响的事物的状态;X 表示正常人体内部事物的状态;Y 表示病人身体内部事物的状态;Z 表示病人外表事物的状态。由此看出中医保留了人类直观地认识事物的自然特征,通过一个个模型之间的转换(时间的、空间的、类比的、隐喻的、投射的、扩大或缩小的等无需习得的方式)达到对对象的了解,发展了非量化的直观推理形式。基于这样的推理中医形成了“人-症-病-证”的辨证论治体系。[2]
在这个体系里,“症”包括症状和体征,症状是主观体会到的痛苦或不适,体征是医生客观检查到的异常;“证”指证候,是疾病过程中某一阶段或某一类型的病理概括,一般由一组相对固定的、有内在联系的、能揭示疾病某一阶段或某一类型病变本质的症状和体征构成。中医临床诊断,“症”是确立“证”的主要依据,因此在中医的理论中,由症状信息到证型的映射是存在的。
2.用机器学习的方法解决完成中医推理的技术可行性问题
要解决这个问题,首先要解决机器学习的定义及其作用范围。机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的人工智能分支。
机器学习算法分为四类,将实例数据划分到合适的分类中的分类算法、用于预测数值型数据的回归算法、将数据集合分成由类似的对象组成的多个类的聚类算法以及寻找描述数据统计值的密度估计算法。
显然,机器学习的分类算法能够满足本课题的任务需求,即根据症状信息将病人分到对应证型类里去。分类算法又分为传统的分类算法和深度学习算法,而传统的分类算法包括 K-近邻算法、决策树算法、朴素贝叶斯、Logistic 回归、支持向量机以及由弱分类器组合而成的强分类器的集成学习算法。[3]
根据李凯的研究实验中得出的结论,基于数据的集成学习算法在大多数数据集上优于基于特征集的集成学习算法且基于数据集的集成学习算法中 Bagging 算法和 Boosting 算法的表现无论是正确率还是泛化性能都优于其他算法。[4]故本课题选择 Bagging 算法的代表随机森林算法和 Boosting 算法的代表 AdaBoost 算法以及深度学习算法。
3.集成学习与深度学习的算法思想和流程是怎样的
集成学习是将多个不同的单个模型组合成一个模型,其目的是利用这些单个模型之间的差异,来改善模型的泛化性能。当学习模型具有较高的正确率且具有差异性时,则模型集成的效果明显。[5]
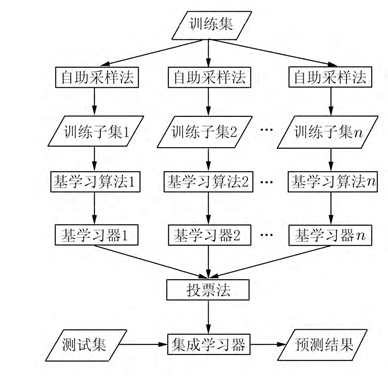
其中,Bagging 思想是多次放回采样通过学习算法形成多个弱分类器,投票(权重相等)形成强分类器[6],算法具体流程如下:
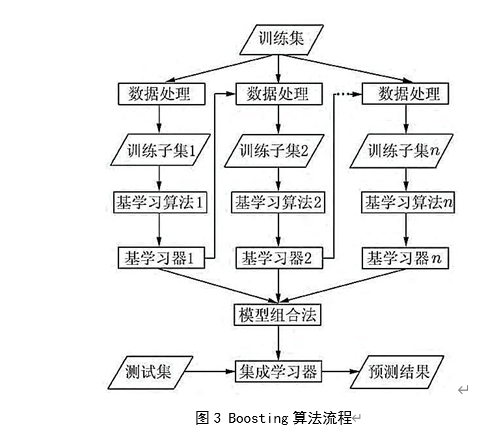
而 Boosting 算法思想是每次使用全部样本对多个弱分类器进行线性组装,各分类器根据错误率调整的权重投票强分类器。具体算法流程如下:
总结起来,Bagging 和 Boosting 的区别如下:
a) 样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的;
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化,而权值是根据上一轮的分类结果进行调整。
b) 样例权重:
Bagging:使用均匀取样,每个样例的权重相等;
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
c) 预测函数:
Bagging:所有预测函数的权重相等;
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
d) 并行计算:
Bagging:各个预测函数可以并行生成;
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。[7]
深度学习的思想是基于样本数据通过一定的训练方法得到包含多个层级的深度网络结构,这个深度网络结构包含大量的单一神经元,每个神经元与大量其他神经元相连接,神经元间的连接强度在学习过程中修改并决定网络的功能。[8]
其算法的流程如下:
a) 根据学习任务即输入输出设计神经网络结构;
b) 将样本输入网络计算输出结果;
c) 根据输出与实际样本标签误差选择误差反向传播算法;
d) 调整神经元权重,训练神经网络;
e) 使用对神经网络性能进行验证,调整网络结构,重复 b-e 过程直到验证结果满意为止。
4.如何实现一个用户友好的量化诊断系统
由于本课题的涉及的大量算法开发,而 Python 语言对于科学计算的工具支持具有良好的生态环境,故选用现有的 Python Web 开发框架,其包含了多种组件,可以实现关系映射、动态内存管理、界面管理等功能。Django 开发采用 DRY 原则,同时拥有独立的轻量级 Web 服务器,能快速开发 Web 应用。[9]
Django 开发遵循 MVC 模式,包括模型·、视图、控制三部分:
a) 模型层是应用程序底层, 主要负责处理与数据有关的事务, 如数据存取验证等;
b) 视图层组成应用程序的业务逻辑, 负责在网页或其他类型的文档中展示数据;
c) 控制层负责从用户端收集用户的输入,可以看成提供 View 的反向功能。
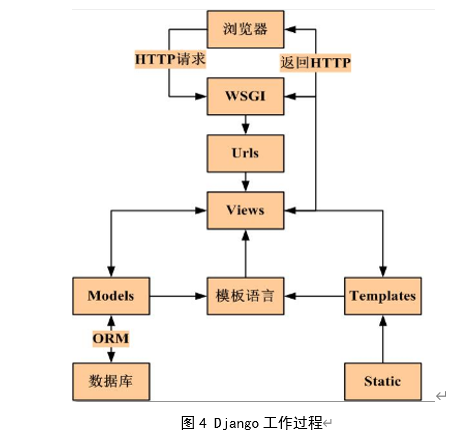
Django 的工作过程如下:
a) 浏览器向 Web 服务器发送 HTTP 请求;
b) Web 服务器收到请求转发给 Django 应用;
c) Django 请求中间件层,按照 URLconf 模式来匹配、映射到合适的视图函数上,视图函数利用模型和模板,按照要求生成相应的响应,中间件层把响应封装成 HTTP 响应,返回给 Web 服务器;
d) Web 服务器把响应转发给客户端浏览器。[10]
具体工作过程如图 4 所示:
参考文献
[1]王志康.回归自然的认知策略——中医诊断的模型化推理及其方法论启示[J].自然辩证法通讯,2009,31(03):26-31+25+110.
[2]江泳,陈建杉,江瑞云,郭子光.论辨证论治的完整体系:人-症-病-证[J].中医杂志,2011,52(17):1447-1450.
[3] Peter Harrington.机器学习实战[M].北京:人民邮电出版社,2013:3-9.
[4]李凯,崔丽娟.集成学习算法的差异性及性能比较[J].计算机工程,2008(06):35-37.
[5]付忠良,赵向辉.分类器动态组合及基于分类器组合的集成学习算法[J].四川大学学报(工程科学版),2011,43(02):58-65.
[6]徐继伟,杨云.集成学习方法:研究综述[J].云南大学学报(自然科学版),2018,40(06):1082-1092.
[7]李晓波.集成分类对比:Bagging NB & Boosting NB[J].微电子学与计算机,2010,27(08):136-139.
[8]尹宝才,王文通,王立春.深度学习研究综述[J].北京工业大学学报,2015,41(01):48-59.
[9]朱贇.Python 语言的 Web 开发应用[J].电脑知识与技术,2017,13(32):95-96.
[10]龚新定,余艳梅,吴小强,何小海.基于 Django 的实验室信息管理系统设计[J].微型机与应用,2016,35(22):108-111.
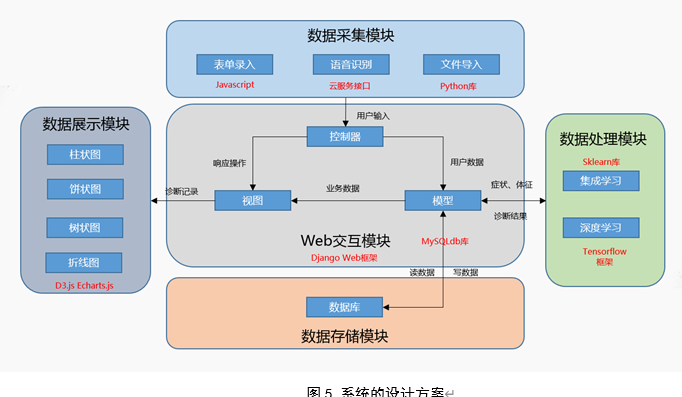
1.设计方案
本系统采用 B/S 架构,使用 Python 语言进行后端开发,HTML、JavaScript、CSS 进行前端开发。系统分为五个功能模块,即数据采集模块、Web 交互模块、数据处理模块、数据存储模块以及数据展示模块:
a) 数据采集模块,顾名思义,用于收集用户门诊信息,支持单项表单录入或语音输入,以及批量文件导入。表单录入用 JavaScript 进行预处理之后发送给服务器进行进一步处理;语音输入利用云服务提供的语音识别接口将音频文件转化为文字信息,再由用户编辑确认发送给服务器处理;文件批量导入功能利用 Python 强大的工具库对用户本地进行读写操作,提取多条患者信息;
b) Web 交互模块,即负责与用户进行交互,同时协调后端组件进行工作,系统基于 Python 强大的 Django 框架进行开发,采用 MVC 的软件设计模式,控制器负责接受处理用户输入请求,指示响应操作,模型负责与数据库以及数据处理模块的交互,对数据进行读写并发送给视图,视图负责处理要返回给用户的界面;
c) 数据处理模块,即负责算法模型对数据的处理,利用 Sklearn 包的 AdaBoost、随机森林等算法进行集成学习,利用 Tensorflow 框架进行深度学习,对输入的症状、体征信息进行量化诊断并返回准确率、召回率等指标,以便进行优化调整;
d) 数据存储模块,本系统采用 MySQL 数据库,仅需要 MySQLdb 库即可用 Python 与之交互读写;
e) 数据展示模块,即负责向用户直观地展示历史诊断结果,系统采用 Echarts.js 和 D3.js 脚本进行作图。
具体设计方案如下图 5 所示:
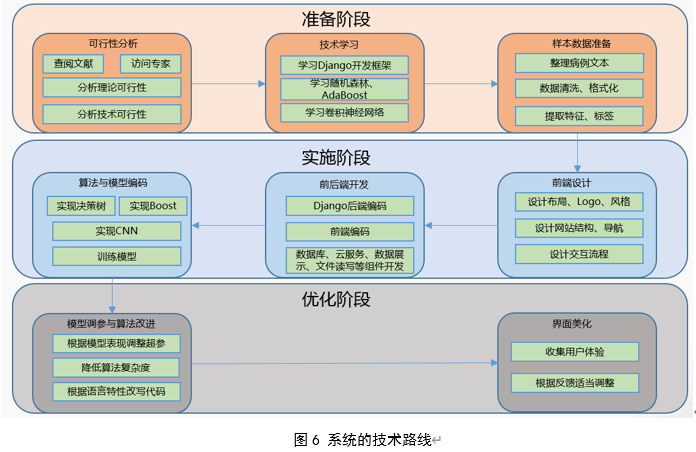
2.技术路线
2 月 20 日——2 月 29 日:前后端设计与开发
3 月 01 日——3 月 15 日:机器学习算法设计与编码实现
3 月 15 日——3 月 31 日:模型训练与优化
4 月 01 日——4 月 15 日:项目完善与改进
4 月 15 日——4 月 30 日:论文撰写
5 月 01 日——5 月 15 日:准备答辩材料
5 月 15 日——6 月 20 日:课题扩展开发
参考文献
- 基于知识图谱的智能诊断信息系统设计与实现(南京理工大学·唐公成)
- 基于WPF的中医证治智能诊断系统的设计和开发(华中科技大学·苏功闯)
- 藏医尿诊的计算机辅助决策研究(电子科技大学·杜兆威)
- 藏医尿诊的计算机辅助决策研究(电子科技大学·杜兆威)
- 基于中医方剂知识图谱的核心药物发现与方剂推荐算法研究(电子科技大学·梁尘逸)
- 中医药临床实践指南库的建立与应用(天津中医药大学·李楠)
- 基于语音识别技术和中医知识图谱的智能中医问诊系统的设计与实现(厦门大学·罗智平)
- 中医名方知识图谱构建与链路预测模型的研究及应用(东北师范大学·刘禹琪)
- 面向中医问答的知识图谱构建及问题表示算法研究(北京交通大学·吕颖)
- 基于多标签学习的中医辨证分析研究(南京邮电大学·陈诗琪)
- 面向中医问答的知识图谱构建及问题表示算法研究(北京交通大学·吕颖)
- 基于机器学习的中医方证推荐系统(桂林电子科技大学·周璨)
- 基于中医方剂知识图谱的核心药物发现与方剂推荐算法研究(电子科技大学·梁尘逸)
- 基于知识图谱的中医药问答系统的研究与实现(青岛大学·李学良)
- 基于知识图谱的舌像诊疗系统研究与构建(电子科技大学·张莹莹)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设工坊 ,原文地址:https://bishedaima.com/yuanma/35999.html