
Python 新浪微博爬虫,支持模拟登陆,微博文字另存为本地文件
网上大部分对微博的爬虫都是先人工登陆获取cookie再进行接下来的抓取操作的,所以我写了一份模拟登陆获取cookie的(因为是分析为主要目的,所以纯手动构建cookie,没有使用requests.session),并实现了提交验证码, 本文我对分析过程和代码进行步骤分解,完整的代码请见末尾 Github 仓库,不过还是建议看一遍正文,因为代码早晚会失效,解析思路才是永恒。
分析 POST 请求
首先打开控制台正常登录一次,可以很快找到登录的 API 接口,这个就是模拟登录 POST 的链接。
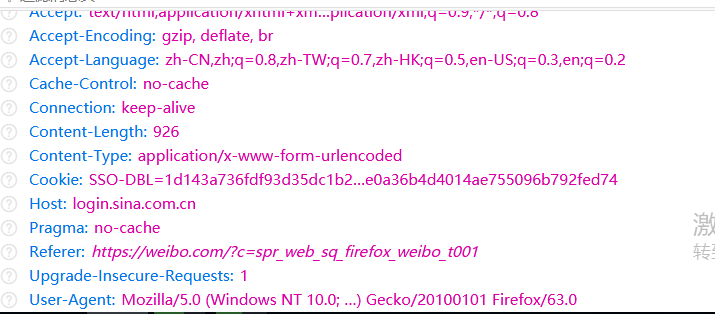
我们要构建header 和 Formdata
构建 Headers
观察POST请求的header发现header里面已经含有cookie了
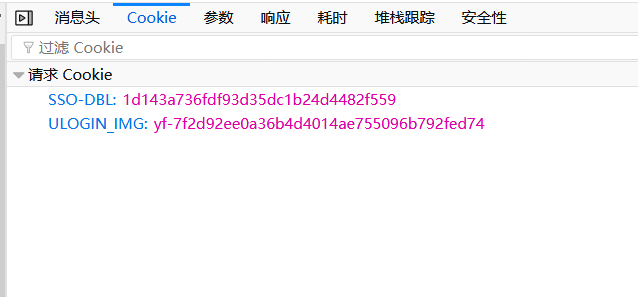
翻看之前的请求,容易发现SSO-DBL来自一个叫prelogin的请求,这个请求在输入完用户名,鼠标点击输入密码的文本框时触发

ULOGIN_IMG则是请求验证码图片的时候获取的,而获取验证码又要带值为SSO-DBL的cookie进行请求

我们来看prelogin请求的参数
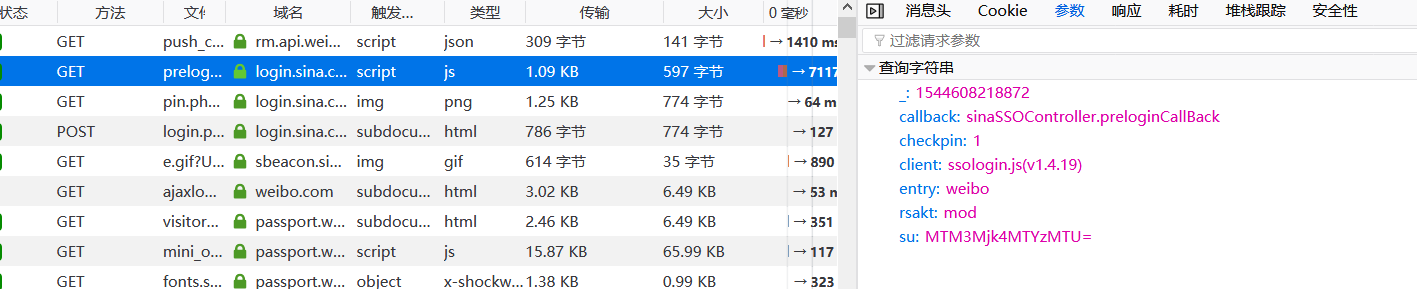
值得关注的是那串数字和su,其余我们估计是固定参数,仔细观察发现那串数字其实是一个13位时间戳,直接使用time模块即可。接下来就要构造su了,Ctrl+F全局搜索 输入'su:'
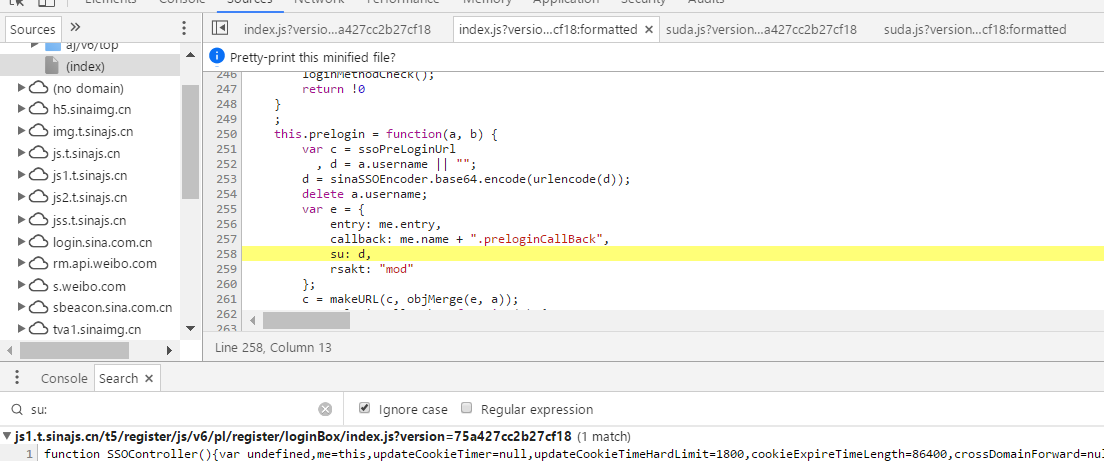
找到构造su的js代码,发现是将用户名进行编码得到的使用bs64模块构造即可。
这样我们就完成了prelogin请求的header和参数构造,可以获得SSO-DBL了
接下来分析验证码图片的请求参数

其中s是固定值,r经测试可以反复使用同一个值,所以只有p是需要获取的,而p可以在刚才prelogin的response中找到

至此POST请求的header已经构建好了,其他的复制黏贴即可
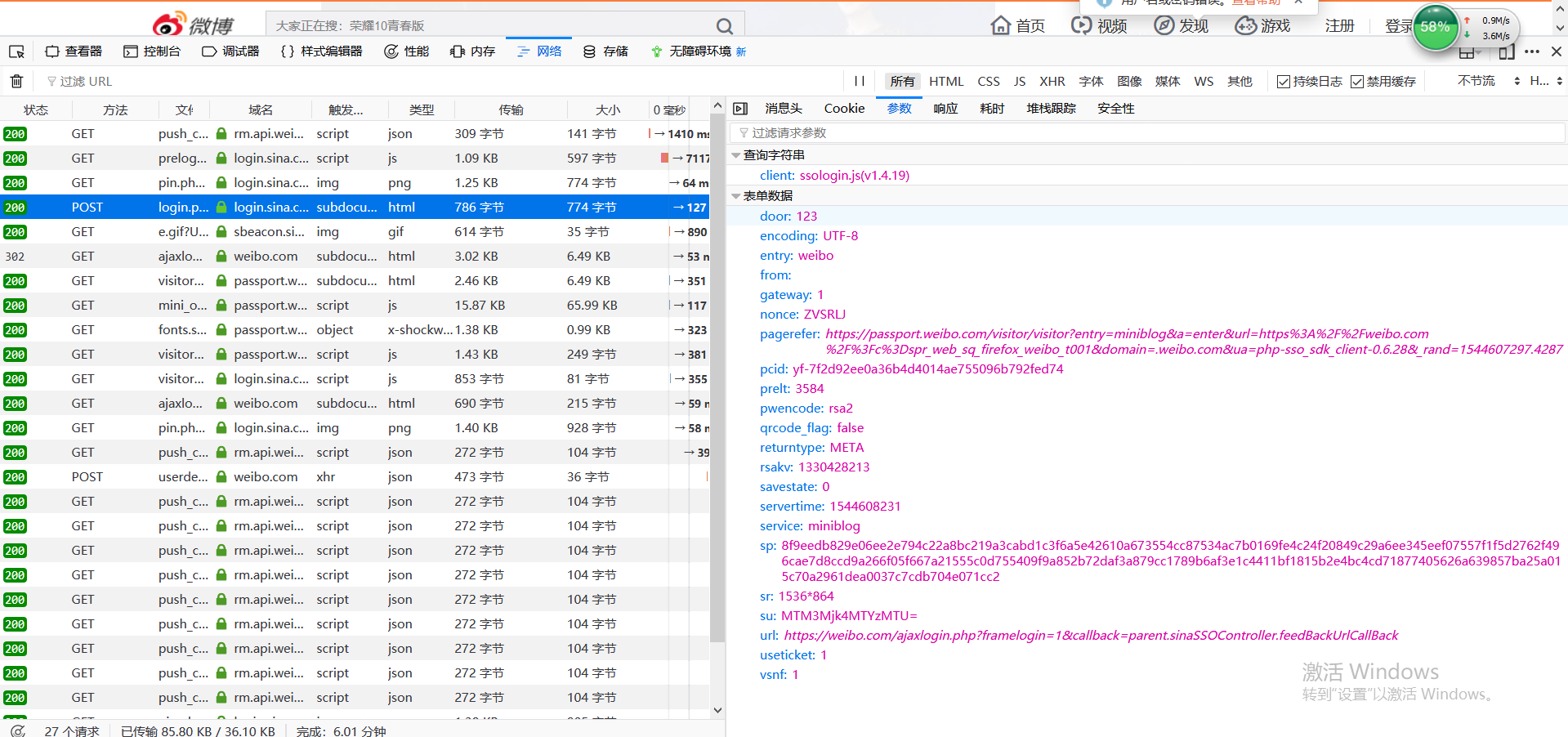
构建 Form-Data

这里nonce, pcid, rsakv都可以在prelogin的response里找到,door是验证码,prelt是随机数,所以每次用同一个就行,servertime是时间戳
值得关注的是sp,老办法Ctrl+F找到构造的js代码
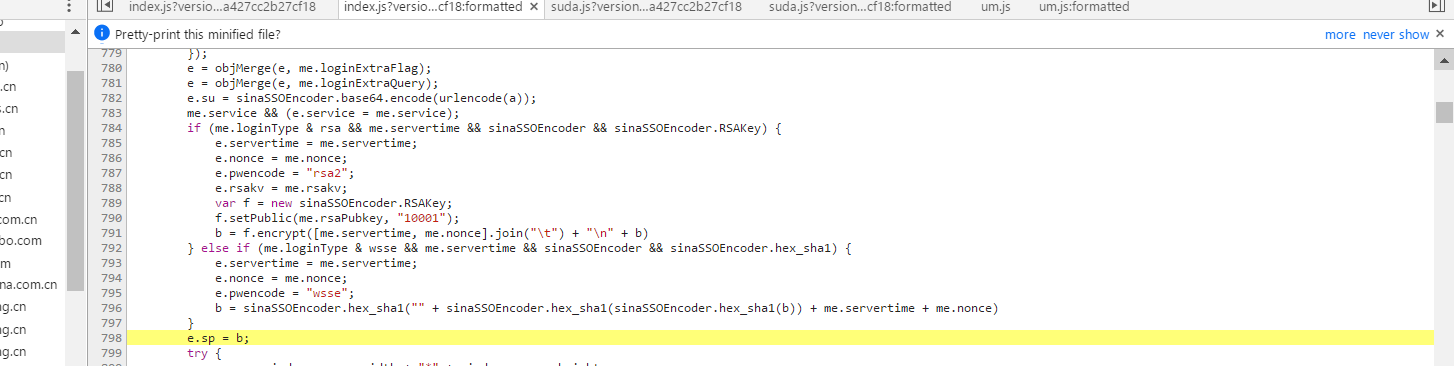
发现这里使用了rsa算法加密,这里的公钥用了从prelogin里返回的一个叫pubkey的16进制数和16进制的10001共同生成,再将包含servertime,刚才提到的nonce,和用户密码的字符串进行加密得出sp,具体实现可以看代码。
到这里所有参数已经找齐了,模拟POST请求即可。
我们可以看到POST请求成功后我们的cookie更新了一大堆值

将这些值取出来后可以更新我们的cookie。
到了这里本来以为已经大功告成,我们找到登陆成功的html请求

看他的请求cookie

发现其中一些值和我们找到的有很大出入,说明之前cookie又发生改变了。我们耐心地往上翻请求,看看新出现的以及改变了值的cookie都在哪些请求中产生。
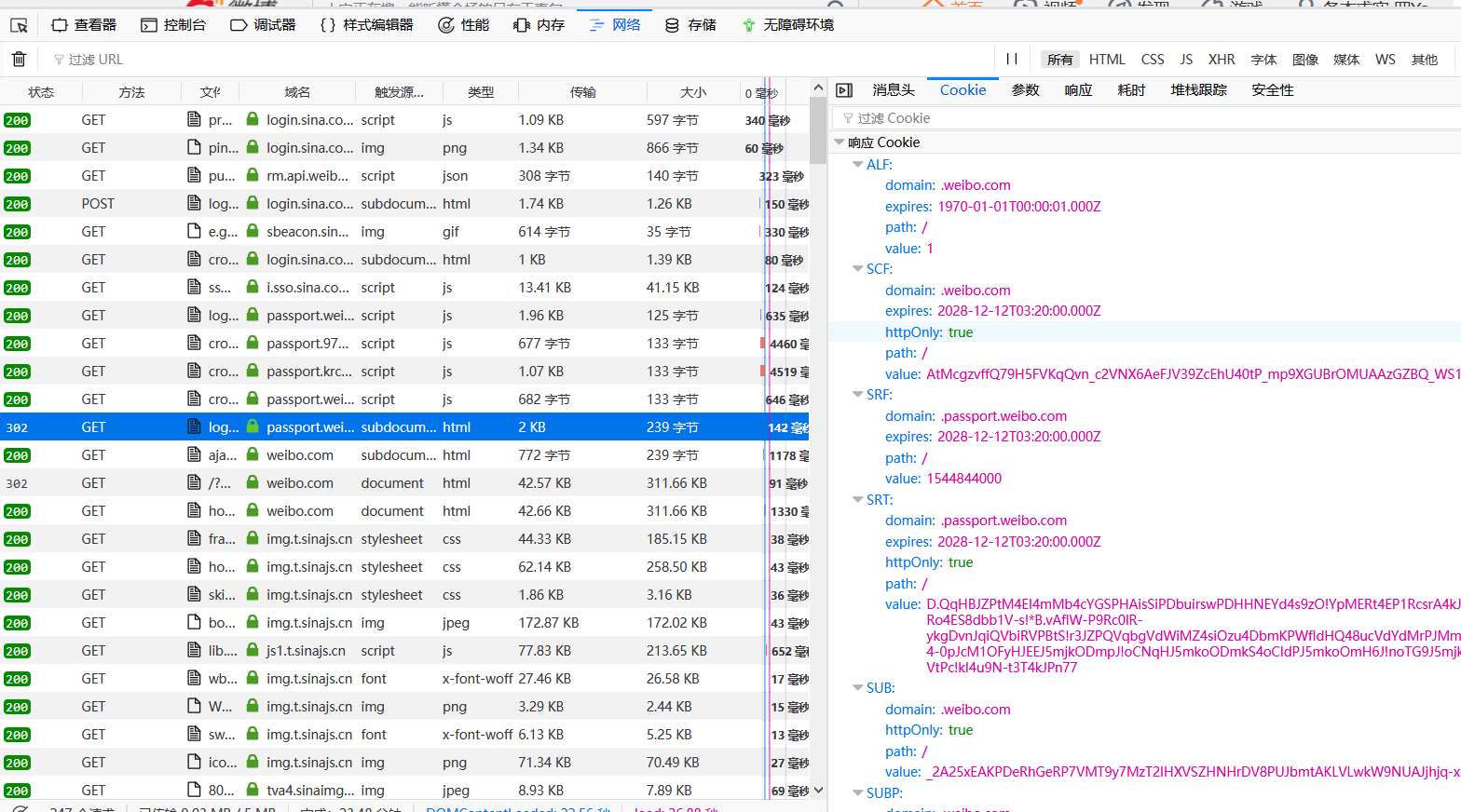
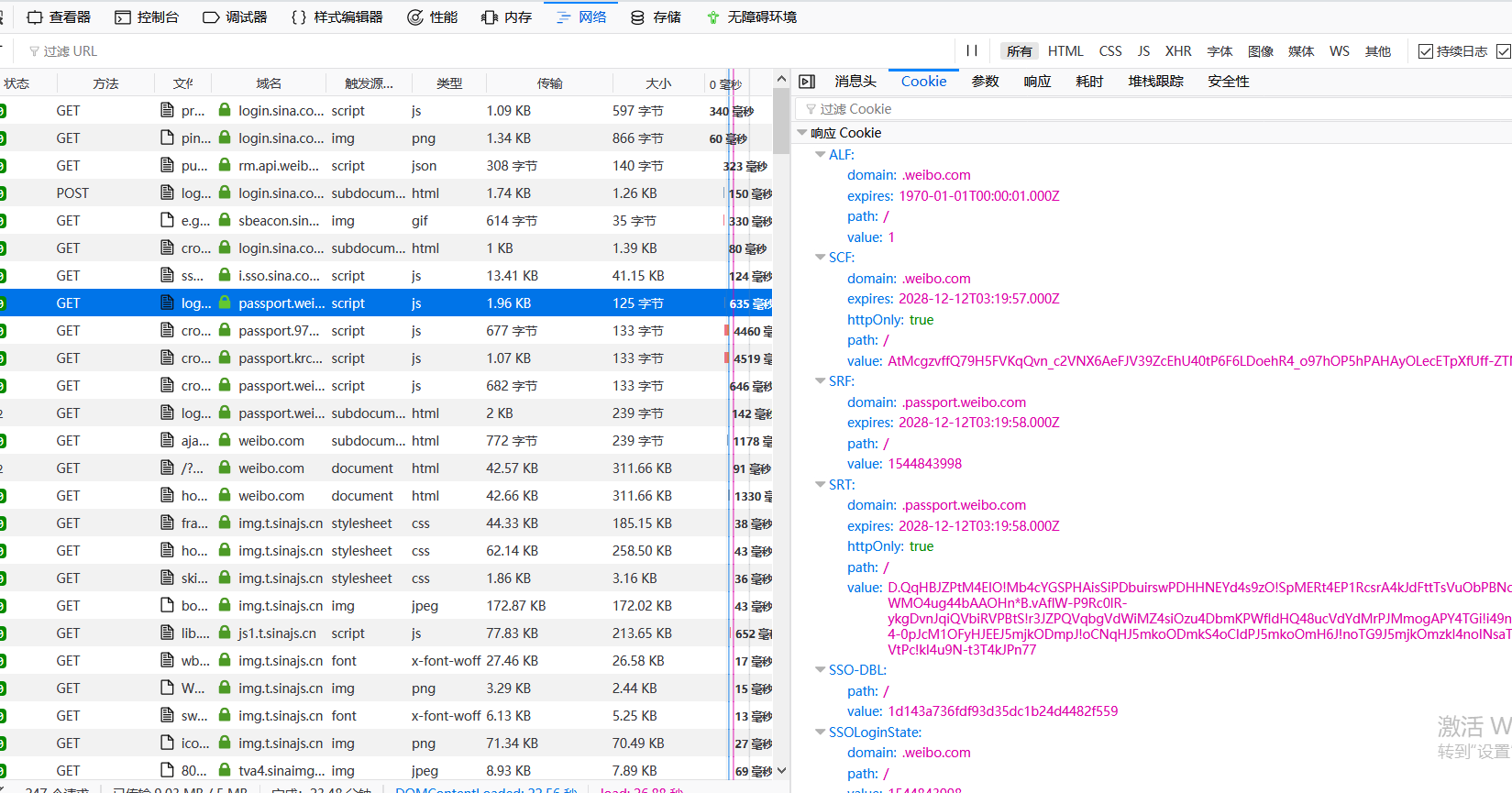

发现我们需要找的变化了的cookie值都可以在这几个请求中找到,用之前的方法模拟请求并且抓下来即可。其中有一些请求的url和参数是每次都不同的,但是也能在我们之前发送的一些请求的response里找得到,用正则匹配出来即可。
至此我们已经完成了最终home请求所需cookie的构造,模拟请求并获得最终登陆成功的cookie即可。
参考文献
- 基于关键词的微博爬虫系统的设计与实现(浙江工业大学·叶婷)
- 基于SSD和时序模型的微博好友推荐系统的设计与实现(江苏大学·景迪)
- 分布式智能网络爬虫的设计与实现(中国科学院大学(工程管理与信息技术学院)·何国正)
- 基于SSD和时序模型的微博好友推荐系统的设计与实现(江苏大学·景迪)
- 基于自定义词典的网络文本情感分析方法(电子科技大学·何博)
- 基于分布式爬虫的社交媒体灾害信息挖掘系统的设计与实现(华中科技大学·单欣刚)
- 基于半监督学习的微博水军识别系统的研究与实现(东南大学·陶涛)
- 基于社交网络的用户多维度求职意向的研究与应用(电子科技大学·冉秋萍)
- 基于SSD和时序模型的微博好友推荐系统的设计与实现(江苏大学·景迪)
- 基于Storm云平台的分布式网络爬虫技术研究与实现(电子科技大学·付志鸿)
- 基于大数据的微博转发预测及热点发现算法的研究(西安电子科技大学·谢子卓)
- 基于微博的网络舆情关键技术的研究与实现(电子科技大学·单月光)
- 微博数据挖掘可视化系统的设计与实现(吉林大学·王婧雅)
- 基于关键词的微博爬虫系统的设计与实现(浙江工业大学·叶婷)
- 面向微博的网络爬虫研究与实现(复旦大学·刘晶晶)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头网 ,原文地址:https://bishedaima.com/yuanma/35947.html









