
基于Python实现房天下爬虫项目
任务清单:
1.爬取网站 :房天下 2.爬取内容:各个省市所有的新房、二手房的信息 3.爬取策略:分布式爬取(会先从单机开始,之后再改成分布式) 4.存储位置:存储在 MongoDB上(有时间,会考虑使用集群) 5.数据分析:对爬取下的数据进行分析,如哪个省、市平均房价等等(有时间可以做做) 6.数据可视化:使用pyecharts或者自带的matplotlib(有时间做做)
一.分析网站
想想要获取所有的省市的房子信息,前提是要知道所有的省市具体名称。幸运的是,还真的有这个页面。
在更多城市那, 点击进去,是一个完整的省市信息。如下图:

ok,没毛病了。爬取这个页面所有的城市的链接,第一级链接就搞到手了。
还没完,接着分析: 以福建省福州市为例子,进入第一级链接。观察URL发现,新房的URL为:
(http://fz.newhouse.fang.com/house/s/)。二手房的URL为:(http://fz.esf.fang.com/)发现,貌似有点意思。
再换另一个城市,如厦门的新房和二手房URL分别是:
http://xm.newhouse.fang.com/house/s/ ,http://xm.esf.fang.com/,
这下,规律就出来了吧。不过,有些坑需要注意一下,北京,它的新房和二手房URL并不是 http://bj.esf.fang.com/这样的。URL竟然是这样的:http://newhouse.fang.com/house/s/和https://esf.fang.com/,毕竟它是首都嘛。
ok,页面分析差不多了,现在看看,需要获得到哪些字段。 根据自己需求来获取,使用xpath进行解析。 给个参考:
python
class NewHouseItem(scrapy.Item):
# 省份
province = scrapy.Field()
# 城市
city = scrapy.Field()
# 小区名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
# 几居
rooms = scrapy.Field()
# 地址
address = scrapy.Field()
# 行政区
district = scrapy.Field()
# 是否在售
is_sale = scrapy.Field()
# 详情页面 url
orgin_url = scrapy.Field()
```python class OldHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 小区名字 name = scrapy.Field() # 几室几厅 rooms = scrapy.Field() # 几层 floor = scrapy.Field() # 朝向 toward = scrapy.Field() # 年代 year = scrapy.Field() # 地址 address = scrapy.Field() # 建筑面积 area = scrapy.Field() # 单价 unit_price = scrapy.Field() # 总价 total_price = scrapy.Field()
```
创建项目
一步步来吧,先创建单机版本的
python
scrapy startproject FangTianXinSingle
用 Pycharm 打开,看到以下目录结构

多出来的utils和log是我手动创建的,utils主要是工具类,之后 会使用到IP代理池,一些接口会放在那,log也就是日志目录。
别急着创建爬虫,先改改settings.py中的配置文件吧。
- ROBOTSTXT_OBEY = False (不解释)
- DOWNLOAD_DELAY = 5(防止IP被封了)
- COOKIES_ENABLED = False (推荐不使用cookie)
- 至于USER-AGENT可设可不设,因为下面会写一个 UA中间件
- 其它的先不改
二、创建爬虫
python
先进入spiders目录中,cd spiders
控制台执行 scrapy genspider soufang fang.com
如图:

首先,把 start_urls 给改了,换成之前分析的那个url http://www.fang.com/SoufunFamily.htm
其次,别忘记我们的需求,要获得所有的 城市的链接。分析页面,使用xpath,解析出所有的链接。
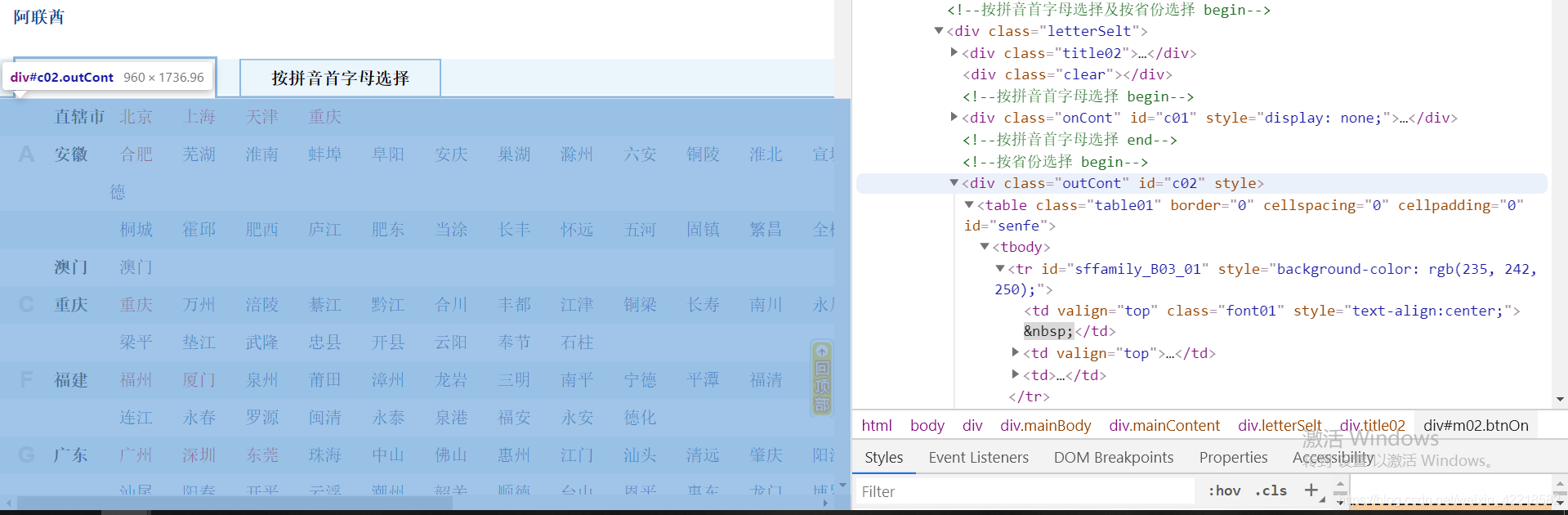
通过检查发现,其所有的城市是放在一个 id=c02 的div容器中,这下好办了,直接上代码。懒癌犯了,就不一一分析xpath语法了。
```python
- - coding: utf-8 - -
import scrapy
class SoufangSpider(scrapy.Spider): name = 'soufang' allowed_domains = ['fang.com'] start_urls = ['https://www.fang.com/SoufunFamily.htm']
def parse(self, response):
trs = response.xpath("//div[@id='c02']//tr")
province = None
for tr in trs:
tds = tr.xpath(".//td[not(@class)]")
province_td = tds[0].xpath(".//text()").get().strip()
if province_td:
province = province_td
city_links = tds[1].xpath(".//a")
# 不需要爬取国外的
if province == '其它':
continue
for city_link in city_links:
city_name = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
scheme, domain = city_url.split("//")
# 北京的新房和二手房链接需要特别处理
if 'bj.' in domain:
newHouseLink = 'http://newhouse.fang.com/house/s'
oldHouseLink = 'http://esf.fang.com/'
else:
newHouseLink = scheme + "//" + "newhouse." + domain + "house/s"
oldHouseLink = scheme + "//" + "esf." + domain
print(newHouseLink, oldHouseLink)
```
执行该爬虫,看看成效:
python
scrapy crawl soufang
如果你能打印出以下内容,恭喜!
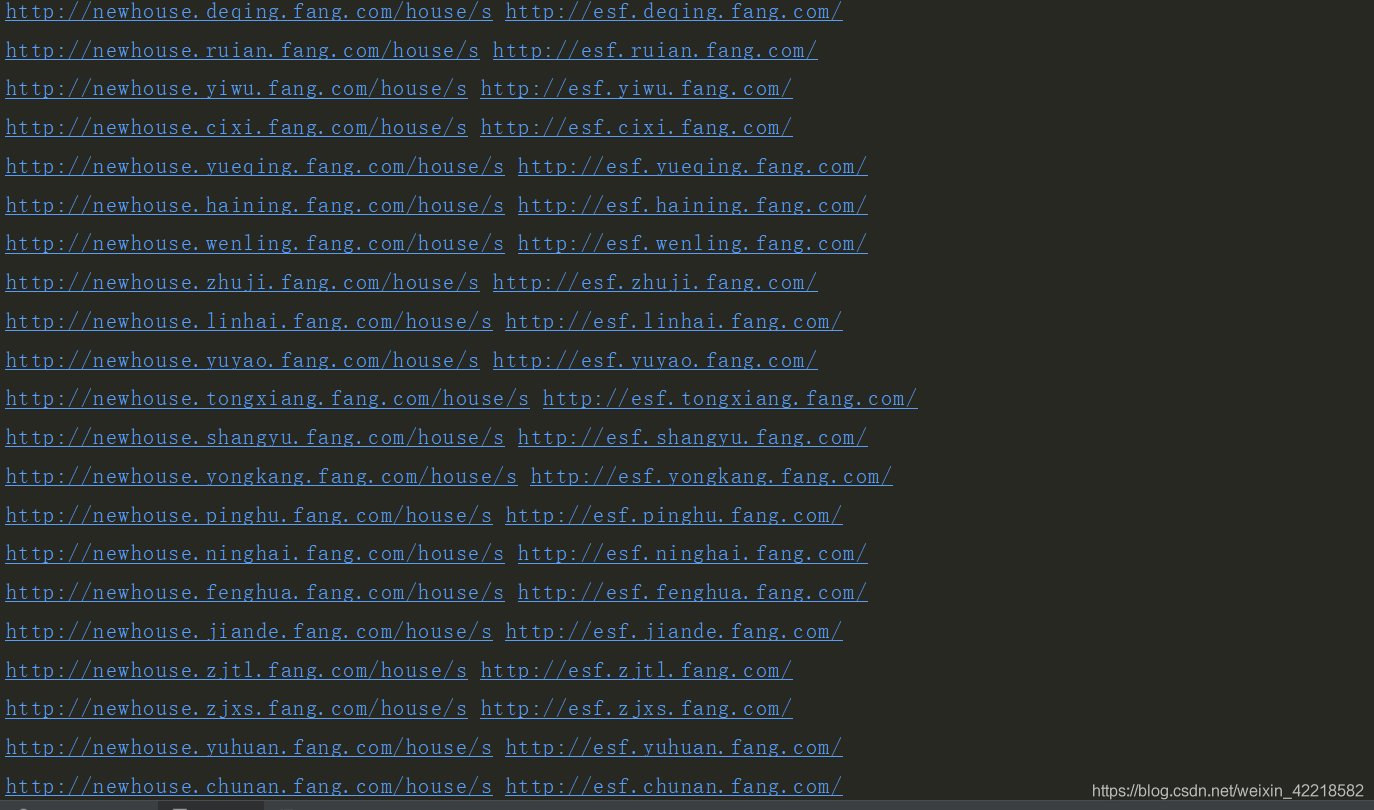
三. 反爬虫策略
对这些链接再次访问之前,要做一些反爬虫策略了。
由于刚刚只对该网站的一个页面进行爬取,做不做反爬虫无所谓。但是接下去需要对网站这么网址进行爬取,不做点什么好像对不起这个网站。
策略1:UA中间件
在目录下创建UserAgentMiddleware.py文件,我一般不在scrapy提供的middlewares.py文件中写
```python
author:dayin
Date:2019/12/18 0018
from fake_useragent import UserAgent
class UserAgentMiddleware(object): ua = UserAgent()
def process_request(self, request, spider):
request.headers['User-Agent'] = self.ua.random
```
别忘记了!要去settings文件中 downloadmiddleware中加入你创建的中间件!
python
DOWNLOADER_MIDDLEWARES = {
'FangTianXiaSingle.UserAgentMiddleware.UserAgentMiddleware': 543,
}
策略2:使用IP代理池
关于IP代理池可以说的有很多。我简略的说一下
-
考虑到经济基础 (穷学生一个),我还是老老实实的使用一些免费的代理IP吧。
-
github上有很多开源的免费IP代理,我找了一个挺不错的,分享给大家。
代理IP池
- 关于代理IP配置
根据他给的文档即可,写的很详细。里面可以使用redis和ssdb数据库,我使用的是redis数据库。
直接贴出我的代码:
在 utils中创建 getProxyIP.py文件
```python
author:dayin
Date:2019/12/18 0016
import requests def get_proxy(): return 'http://' + requests.get("http://192.168.43.115:5555/get").json()['proxy'] def delete_proxy(proxy): if proxy: requests.get("http://192.168.43.115:5555/delete/?proxy={}".format(proxy)) if name == ' main ': print(get_proxy()) ```
这里解释一下,我没有使用该代理IP池自带的API接口,我是自己创建一个轻量的Flask框架。根据自己的需求,自定制一个api
工具有了,接下来就创建 代理中间件
在目录下,创建 ProxyMiddleWare.py文件
```python
author:dayin
Date:2019/12/18 0018
设置IP代理池 中间件
from FangTianXiaSingle.utils.getProxyIP import *
class ProxyMiddleWare(object):
def process_request(self, request, spider):
try:
proxy = get_proxy()
request.meta['proxy'] = proxy
except:
# 有异常,使用本机IP进行爬取
print('代理池里没有IP了....只能使用自己的啦')
def process_exception(self, request, spider, exception):
print('----' * 100)
print("这个代理IP超时,把它删了吧,换下一个...")
delete_proxy(request.meta.get('proxy'))
request.meta['proxy'] = get_proxy()
print('----' * 100)
return request.replace(dont_filter=True)
```
这样就基本搞定了IP代理池了,少年,你可以放肆的去爬了。
PS:免费的代理毕竟不稳定,经常会连接不上。心累,没钱买好用的代理
对了,记得去settings.py文件中加入该中间件!
python
DOWNLOADER_MIDDLEWARES = {
'FangTianXiaSingle.ProxyMiddleWare.ProxyMiddleWare': 300,
'FangTianXiaSingle.UserAgentMiddleware.UserAgentMiddleware': 543,
}
四. 解析各城市链接
既然已经有了反爬虫策略,那么接下去便是分别解析各个城市二手房和新房的链接了
具体页面就不去分析了,给出代码,供大家参考:
```python
- - coding: utf-8 - -
import scrapy import re
from FangTianXiaSingle.items import OldHouseItem, NewHouseItem
class SoufangSpider(scrapy.Spider): name = 'soufang' allowed_domains = ['fang.com'] start_urls = ['https://www.fang.com/SoufunFamily.htm']
def parse(self, response):
trs = response.xpath("//div[@id='c02']//tr")
province = None
for tr in trs:
tds = tr.xpath(".//td[not(@class)]")
province_td = tds[0].xpath(".//text()").get().strip()
if province_td:
province = province_td
city_links = tds[1].xpath(".//a")
# 不需要爬取国外的
if province == '其它':
continue
for city_link in city_links:
city_name = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
scheme, domain = city_url.split("//")
# 北京的新房和二手房链接需要特别处理
if 'bj.' in domain:
newHouseLink = 'http://newhouse.fang.com/house/s'
oldHouseLink = 'http://esf.fang.com/'
else:
newHouseLink = scheme + "//" + "newhouse." + domain + "house/s"
oldHouseLink = scheme + "//" + "esf." + domain
yield scrapy.Request(url=newHouseLink, callback=self.parse_newhouse,
meta={'info': (province, city_name)})
yield scrapy.Request(url=oldHouseLink, callback=self.parse_oldhouse,
meta={'info': (province, city_name)})
def parse_newhouse(self, response):
province, city = response.meta.get("info")
lis = response.xpath(".//div[contains(@class,'nl_con')]/ul//li")
for li in lis:
# 房子的名称
name = li.xpath(".//div[@class='nlcd_name']//text()").getall()
if name:
name = re.sub(r'[\s\n]', '', ''.join(name))
# 价格
price = li.xpath(".//div[@class='nhouse_price']//text()").getall()
price = re.sub(r'[\s\n广告]', '', ''.join(price))
# 居式
rooms = li.xpath(".//div[contains(@class,'house_type')]//text()").getall()
rooms = re.sub('-', '一共', re.sub(r'[\s\n]', '', ''.join(rooms)))
# 地址
address = li.xpath('.//div[@class="c54_a4c7_c71f428 address"]/a/@title').get()
address = re.sub(r'\[.+\]', '', address)
# 地区
district = li.xpath(".//div[@class='address']//text()").getall()
try:
district = re.search(r'(\[.+\])', ''.join(district)).group(1)
except:
district = ''
# 是否在售
is_sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()
# 房源的链接
orgin_url = response.urljoin(li.xpath(".//div[@class='nlcd_name']/a/@href").get())
items = NewHouseItem(province=province, city=city, name=name, price=price, rooms=rooms, address=address,district=district,is_sale=is_sale, orgin_url=orgin_url)
yield items
next_url = response.xpath("//div[@class='page']//a[@class='next']/@href").get()
if next_url:
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse_newhouse, meta={'info': (province, city)})
def parse_oldhouse(self, response):
province, city = response.meta.get("info")
lis = response.xpath("//div[contains(@class,'shop_list')]//dl[@dataflag='bg']")
for li in lis:
try:
name = li.xpath(".//p[@class='add_shop']/a/@title").get()
address = li.xpath(".//p[@class='add_shop']//span/text()").get()
house_info = li.xpath(".//p[@class='tel_shop']//text()").getall()
house_info = ''.join(house_info).split('|')
house_info = list(map(lambda x: re.sub(r'[\r\n\s]', '', x), house_info))
rooms, areas, floor, toward, year, *ags = house_info
unit_price = li.xpath(".//dd[@class='price_right']/span[not(@class)]/text()").get()
total_price = li.xpath(".//dd[@class='price_right']/span[@class='red']//text()").getall()
total_price = ''.join(total_price)
item = OldHouseItem(province=province, city=city, name=name, address=address, rooms=rooms, floor=floor,toward=toward, year=year, area=areas, unit_price=unit_price,total_price=total_price)
yield item
except:
continue
next_url = response.xpath("//div[@class='page_al']//span/following-sibling::p//a[text()='下一页']/@href").get()
if next_url:
yield scrapy.Request(response.urljoin(next_url), callback=self.parse_oldhouse,meta={'info': (province, city)})
```
页面信息获取并不难,只要掌握了xpath的语法规则,获取页面上的元素不是轻而易举?
最后,别忘记了。要在items.py文件中定义好字段噢
```python
- - coding: utf-8 - -
Define here the models for your scraped items
See documentation in:
https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NewHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 小区名字 name = scrapy.Field() # 价格 price = scrapy.Field() # 几居 rooms = scrapy.Field() # 地址 address = scrapy.Field() # 行政区 district = scrapy.Field() # 是否在售 is_sale = scrapy.Field() # 详情页面 url orgin_url = scrapy.Field()
class OldHouseItem(scrapy.Item): # 省份 province = scrapy.Field() # 城市 city = scrapy.Field() # 小区名字 name = scrapy.Field() # 几室几厅 rooms = scrapy.Field() # 几层 floor = scrapy.Field() # 朝向 toward = scrapy.Field() # 年代 year = scrapy.Field() # 地址 address = scrapy.Field() # 建筑面积 area = scrapy.Field() # 单价 unit_price = scrapy.Field() # 总价 total_price = scrapy.Field() ```
五. 数据存储
将数据存储到MongoDB中
按照我的习惯,我不会在已经定义好的pipelines.py文件中创建,而是在目录下创建一个 MongoPipeline.py文件
对了,最好把MongoDB的配置文件放在settings.py中,便于管理
```python
settings.py文件
设置Mongodb配置信息
MONGO_URI = '192.168.43.115' MONGO_DB = 'FangTianXiaSingle' ```
代码如下:
```python
author:dayin
Date:2019/12/18 0018
from pymongo import MongoClient
from FangTianXiaSingle.items import NewHouseItem, OldHouseItem
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
# 新房和二手房的数据分开存放
if isinstance(item, NewHouseItem):
self.db['newHouse'].insert(dict(item))
print('[success] insert into the newHouse : ' + item.get('name') + ' to MongoDB')
elif isinstance(item, OldHouseItem):
self.db['oldHouse'].insert(dict(item))
print('[success] insert into the oldHouse : ' + item.get('name') + ' to MongoDB')
return item
def close_spider(self, spider):
self.client.close()
```
对咯,别忘记将它添加到settings.py文件中的ITEM_PIPELINES中
python
ITEM_PIPELINES = {
'FangTianXiaSingle.MongoPipeline.MongoPipeline': 300,
}
六. 关于优化
- 优化1, 取消 重试中间件
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’: None,’
-
优化2,可以取消重定向中间件,自己写一个。
-
优化3,可以设置超时下载时间。
DOWNLOAD_TIMEOUT = 5
ok,单机版本的就基本上完成了。让我们看看效果

效果还行,几秒钟就爬了几千条数据。不过,这和分布式爬虫比起来,还是个弟弟。
七、进阶分布式爬虫
这里,我不介绍原理概念什么的,相信有接触过 scrapy分布式爬虫的都门儿清。
说起来,单机版的能够成功爬取,那么只需要修改几个地方,就能轻松变成分布式爬虫,所以说啊,会写单机版本的爬虫才是王道
想必大家都懂,scrapy实现分布式爬虫,是基于 scrapy-redis,so,直接切入主题。我把修改的几个地方贴出来:
1.settings.py文件增加 scrapy-redis配置
```python
增加 Scrapy-redis配置
确保request存储到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
确保所有爬虫共享相同的去重指纹
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
可以实现暂停和恢复的功能
SCHEDULER_PERSIST = True
REDIS_HOST = '192.168.43.115' REDIS_PORT = 6379 REDIS_PARAMS = {'password': 'chendayin'} ```
2.修改soufang.py文件
主要改两个地方,第一个不在从scrapy.Spider中继承了,而是继承scrapy-redis中RedisSpider,需要导入包:
python
from scrapy_redis.spiders import RedisSpider
第二个地方,去掉start_urls,增加 redis_key = ‘soufang’
完整代码如下:
```python import scrapy import re
from FangTianXiaSingle.items import OldHouseItem, NewHouseItem from scrapy_redis.spiders import RedisSpider
class SoufangSpider(RedisSpider): name = 'soufang' allowed_domains = ['fang.com'] # start_urls = ['https://www.fang.com/SoufunFamily.htm'] redis_key = 'soufang'
...中间省略...和之前单机版一样
```
3.手动在redis数据库创建一个列表
值为: https://www.fang.com/SoufunFamily.htm
python
lpush soufang https://www.fang.com/SoufunFamily.htm
只有这样,爬虫才会启动。否则一直阻塞
最后,你可以将项目拷贝到Linux服务器上,或者远程服务器上。启动它们,就完成了分布式的爬取。
待完善
- 重定向中间件编写
- MongoDB 集群
- 数据分析处理
- 数据可视化
参考文献
- 基于redis的分布式自动化爬虫的设计与实现(华中科技大学·曾胜)
- 网络爬虫系统的研究与实现(电子科技大学·赵茉莉)
- 深度可定制的工具化爬虫系统的设计与实现(北京邮电大学·李笑语)
- 基于WEB的爬虫系统的设计与实现(西安电子科技大学·卢哲辉)
- 基于Hadoop的分布式爬虫及其实现(北京邮电大学·程锦佳)
- 基于分布式计算的网络爬虫技术研究(大连海事大学·么士宇)
- 基于Storm云平台的分布式网络爬虫技术研究与实现(电子科技大学·付志鸿)
- 面向金融信息的主题爬虫研究与应用(哈尔滨工业大学·卜永忠)
- 基于网络爬虫的水利信息聚合系统的设计与实现(华中科技大学·闫宁)
- 面向人物简介的主题爬虫设计与实现(吉林大学·蒋超)
- 主题爬虫的实现及其关键技术研究(武汉理工大学·张航)
- 基于网络爬虫的数据采集系统设计与实现(东北大学·赵彦松)
- 面向垂直搜索的聚焦爬虫研究及应用(浙江大学·吕昊)
- 基于网络爬虫理论的GIS信息获取方式研究(辽宁工程技术大学·袁方波)
- 主题爬虫的实现及其关键技术研究(武汉理工大学·张航)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈网 ,原文地址:https://bishedaima.com/yuanma/35829.html









