
基于Python的疫情数据爬虫及可视化
一、《企业实训》报告
《企业实训》报告填写要求
《企业实训》报告主要内容:
实训报告必须真实反映实训工作及完成的成果;
实训报告内容包括实训目标、实训内容(实训的步骤、每个步骤产生的文档和数据)、实训总结等三部分组成,后两部分是重点内容;
格式规范,篇幅控制在 5000 字~ 8000 字之间;
报告内容用小四号宋体字编辑,采用 A4 号纸双面打印,封面与封底采用浅蓝色封面纸(卡纸)打印。要求内容明确,语句通顺。
指导教师根据大纲评分标准进行评分,评语用蓝、黑钢笔手写或小四号宋体字编辑。
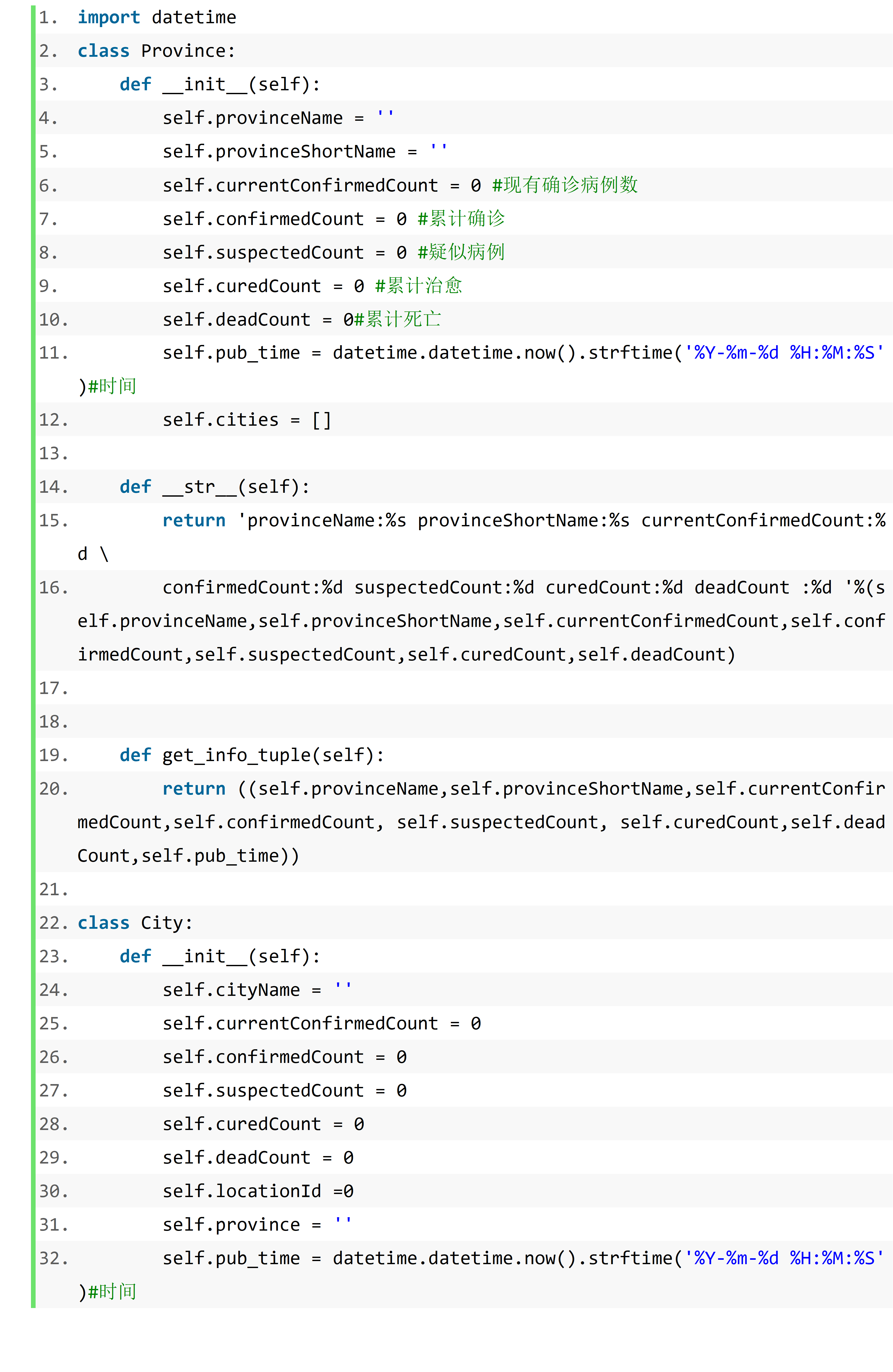
实训目标
了解并掌握企业协同开发的流程,系统的学习爬虫以及可视化相关技术,相关工具的使用和相关环境的搭建,重点懂得服务器端开发的几个通用概念:API 设计,数据库操作,传输验证和异常报错,熟悉并掌握前端 HTML,CSS,js 的使用以及 MySQL 数据库的使用,熟悉前后端交互的相关技术实现,熟练掌握 echarts 框架的使用。
深入理解小组成员之间合作的重要性,分工的重要性,共同协同开发项目。一起合作,分配任务,完成项目。明白企业开发项目流程,系统的掌握相关方法,不断完善项目,在项目中寻找项目经验,对前后端开发有一定的了解。
通过本次实训,系统的掌握 Git 这个版本开发工具,python 基本语法以及其一些内置函数,python 爬虫相关的类库如 beautifulsoup,re,JSON 等库。MySQL 数据库的搭建以及相关操作,python 爬虫与 MySQL 数据库之间的交互。Flask 框架虚拟环境的搭建,echarts 可视化框架的应用,以及 flask 前后端交互。
实训内容
Git 版本工具的使用
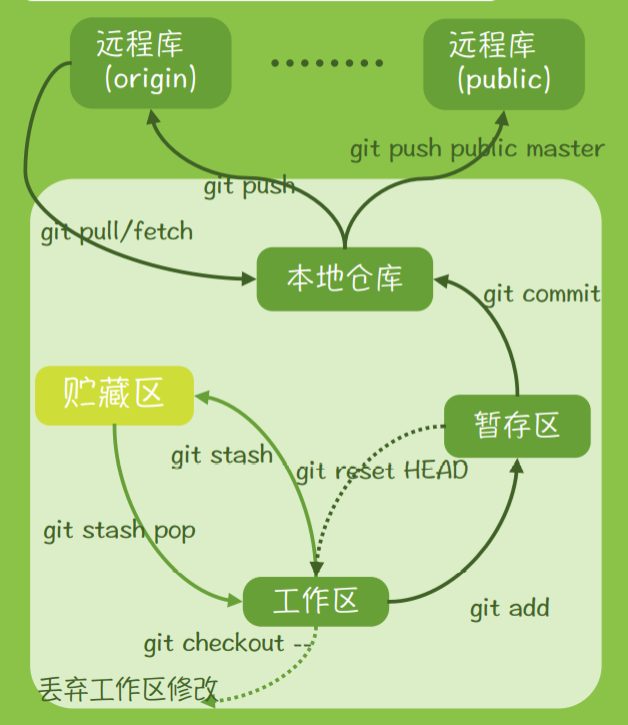
安装了 Git 版本管理工具,系统的学习了 Git 工具的四个主要结构,分别是工作区,缓存区,版本库和远程仓库,并系统掌握了各个工作区之间的转换命令。懂得了 Git 上传远程库的相关命令,创建分支与合并分支的相关命令。还有 Git 标签的使用,以及 Git 分支管理和 Git 服务器的搭建。
通过 Git init 这个命令,我们可以初始化当前这个目录,把他变成 Git 管理的仓库。
Git add 文件名 可以将文件存到暂存区中,若使用通配符.则可以将工作区中的所有文件存入暂存区
Git commit -m ‘命名’ 可以将暂存区中的文件形成一个版本库,存放在本地仓库中
Git push origin(远程库名称) master:分支名 可以将本地仓库中的最新版本提交到远程代码仓库 master 的相应分支下
Git clone 远程仓库地址 可以将远程仓库上的代码文件克隆下来
Git pull origin master:分支名 可以将远程仓库上相应 master 中的分支拉取下来
python 基础语法的学习
系统的学习了 python 中的循环,分支,条件和枚举等相关语法,及其 python 语言本身的特色(缩进,代码块),系统的学习了 python 的基本数据类型和相关系统内置函数的使用(基本数据类型包括字符串、数字、容器、布尔、None 五大类),以及类、面向对象的特征( init ,私有变量的定义等),包、模块、函数与变量作用域的理解,pythonic 的深刻理解。函数式编程的相关概念(包括闭包等),最后学习了相关类库,为之后的爬虫开发打下了坚实的基础。在实训过程的第一周的时候,练习了 python 中多线程,和进程的相关知识点的练习和相关概念。
数据类型
Python 中的数据类型可以分为五大类:字符串、数字、容器、布尔、None。字符串可以使用单引号或者双引号,用加号将两个字符串合并。数字包括整形、浮点型和复数。容器包括:List(列表)、Tuple(元组)、Sets(集合)、Dictionary(字典)
列表可以修改,可以用于切片、增、删、改、查。元组和列表类似,但是不同的是元组不能修改,元组使用小括号。元组中的元素值是不允许修改的,但可以对元组进行连接组合。Set 是无序的集合,不能有重复的元素,也不能排序。布尔主要应用在条件判断上面,发生即为 True,未发生即为 False。Python 严格区分大小写,所以一定要注意不要写错。None 是 Python 里面特殊的空值,不能理解为 0 字典是另一种可变容器模型,且可存储任意类型对象。键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
条件语句
if 语句用来检验一个条件, 如果条件为真,我们运行一块语句(称为 if-块 ), 否则我们处理另外一块语句(称为 else-块 )。 else 从句是可选的。elif 语句可以检查多个表达式的真值,并执行一个代码块的条件之一计算结果为 true。if...elif 语句是可选的。然而不像 else,对此可以有最多一个语句,if 语句下边可以有任意数量 elif 语句。
循环语句
Python 中的循环语句有 for 和 while。break 可以用来终止当前的循环语句,即使循环没结束,执行了 break 语句这个循环就终止了,直接跳出整个循环。continue 语句是用来告诉程序跳出本次循环,然后执行下一轮循环,不同与 break,break 是跳出整个循环,continue 是结束这一次循环,继续下一次循环。
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。在 Python 中,定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号 : ,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。一般在函数体外定义的变量成为全局变量,在函数内部定义的变量称为局部变量。全局变量所有作用域都可读,局部变量只能在本函数可读。函数在读取变量时,优先读取函数本身自有的局部变量,再去读全局变量。
类
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。和静态语言不同,Python 允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同
多线程火车票练习代码如下:
爬虫的开发及使用
在完成爬虫的过程中主要学习的知识点是,正则表达式,re 库的相关概念,包括配位符等概念,安装 MySQL 数据库,还有 beautifulsuop 库的使用,学会了分析网页结构(包括网页的分析和网页标签的使用),对于 JSON 传输方式也有了许多的了解,对于 MySQL 数据库的存取,游标的定义以及操作也有了深刻的认识,爬虫开发让我学到了许多有用的网页结构的知识,数据库的操作,相关类库的使用,类的使用和数据怎么样通过 python 的类进行存储。
- 正则表达式
- re.search(pattern, string, flags)扫描整个字符串,直到找到第一个匹配的对象(查找)
- re.findall(pos[string 开始位置:string 结束位置])扫描整个字符串,找到所有匹配的对象并返回 List(查找所有)
re.sub(pattern, repl, string, count)将 pattern 替换 repl,类似文本编辑的替换,count 设置替换次数,返回替换后字符串,其中 repl 可设置为一个(替换)
基本字符类
\d 数字匹配符 digit
\D 匹配除了 0~9 的字符
\s 空格匹配符,包括\t\s\n\r\f\v
\S 匹配除了空格的字符
\w 数字 + 字符匹配符
\W 匹配除了数字或字母
\b 边界匹配符,匹配数字字母与符号的边界
\B 匹配数字字母与数字字母边界以及符号与符号边界
.万能匹配符,匹配一切除了\n 换行符
digit,space,word,boundary,数字空格字符边界,大写取反,.对一切
规则类
^ 开头符
$ 结尾符
| 或运算
+1+ 次
*0+ 次
?非贪心字符,0 和 1 次
搭配使用 *?或 +?表示非贪心,第一次匹配上就停止,0909090 用 09+?匹配到 09,09+ 则匹配到 090909
{m,n}匹配 m 到 n 次,{m,}匹配 m+,{,n}匹配 0~n 次
多重匹配
匹配括号内字符
-z]- 代表 a 到 z 的所有字符
[+*()]匹配符号时不用加\
[^ab]^ 代表取反,不代表开头
BeautifulSoup
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种:
c++
Tag
NavigableString
BeautifulSoup
Comment
JSON
(Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于(欧洲计算机协会制定的 js 规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
Python 爬虫中使用 JSON 来传输数据,JSON 在 python 中格式与字典类似。
JSON 的 dumps 方法和 loads 方法,可实现数据的序列化和反序列化。具体来说,dumps 方法,可将 JSON 格式数据序列为 Python 的相关的数据类型;loads 方法则是相反,把 python 数据类型转换为 JSON 相应的数据类型格式要求。在序列化时,中文汉字总是被转换为 unicode 码,在 dumps 函数中添加参数 ensure_ascii=False 即可解决。
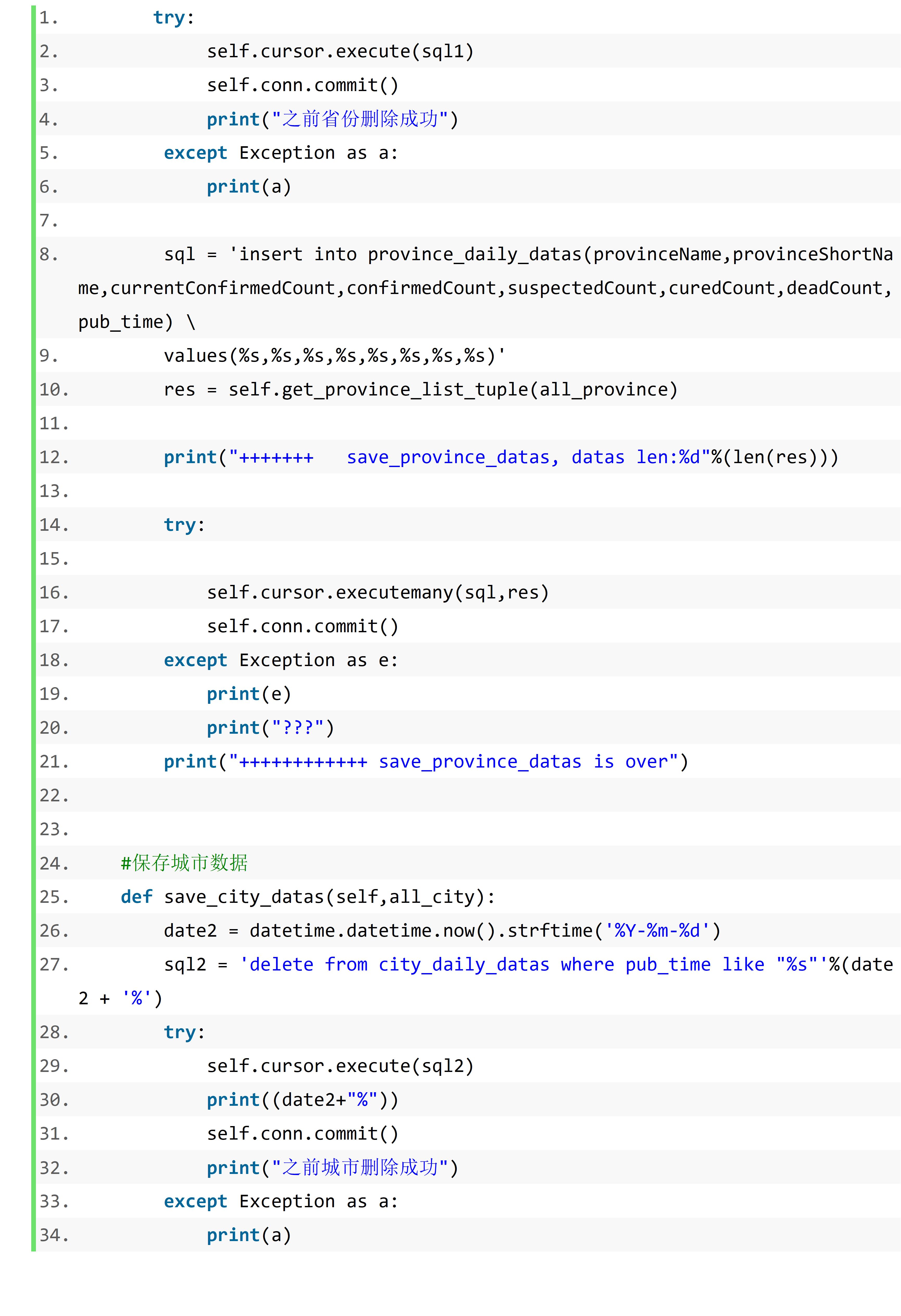
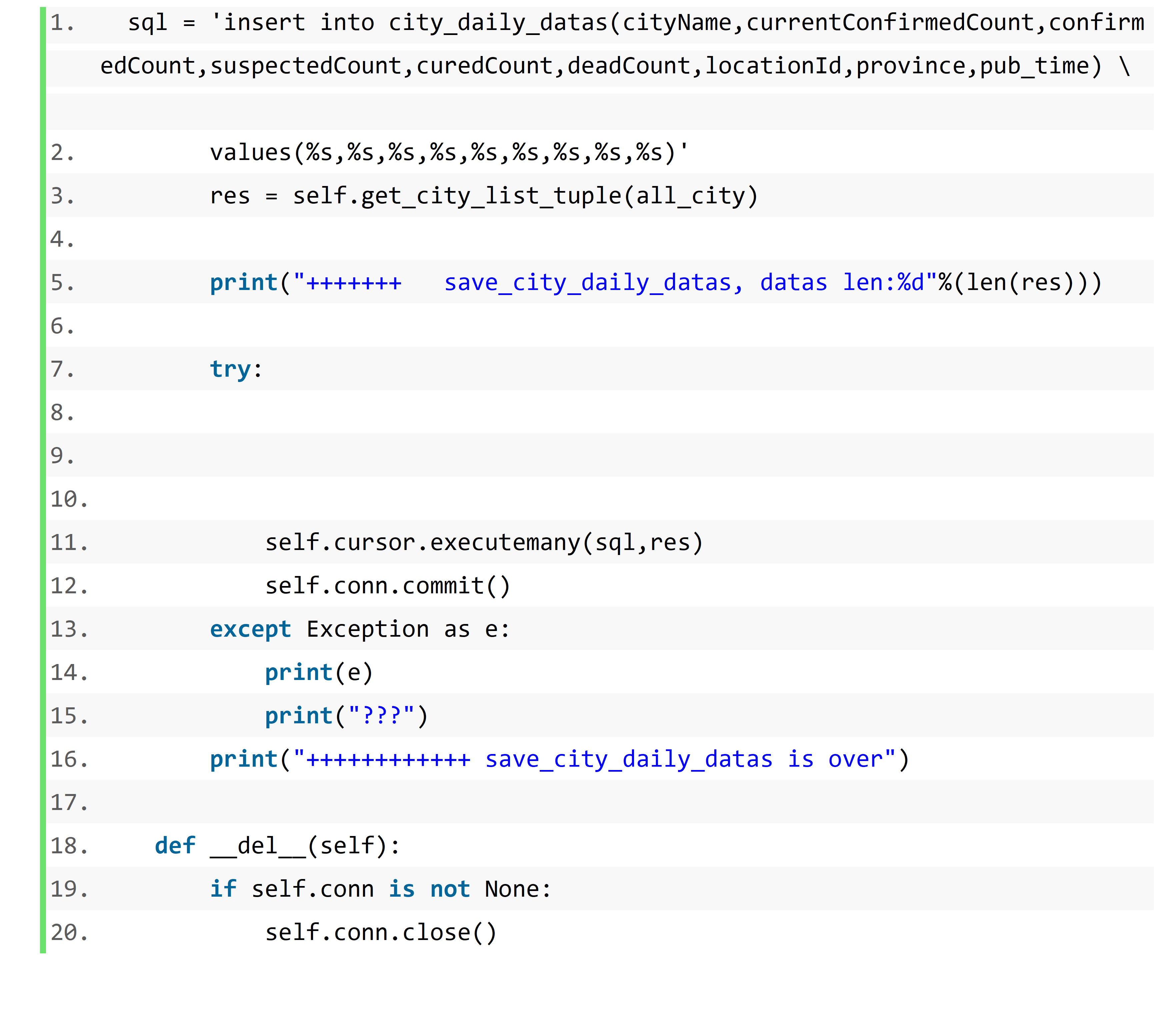
MySQL 与 python 交互
插入操作可以通过游标的 execute 和 executemany 两个方法来完成。注意:只要是对数据表有修改的操作(插入、更新、删除)在使用 execute 方法后,都需要再次调用 commit 方法对数据库的修改才会最终生效。
execute 方法一次插入一条记录,executemany 一次插入多条记录
插入、更新、删除操作必须再执行 commit 操作之后才会生效,而查询操作也只有在执行 fetch 操作之后才会生效。fetch 操作包括 3 个方法,分别是 fetchone()、fetchall()、fetchmany()。
fetchall():查询指定的所有记录
fetchmany(size):查询指定数量的记录
fetchone():取出第一条记录
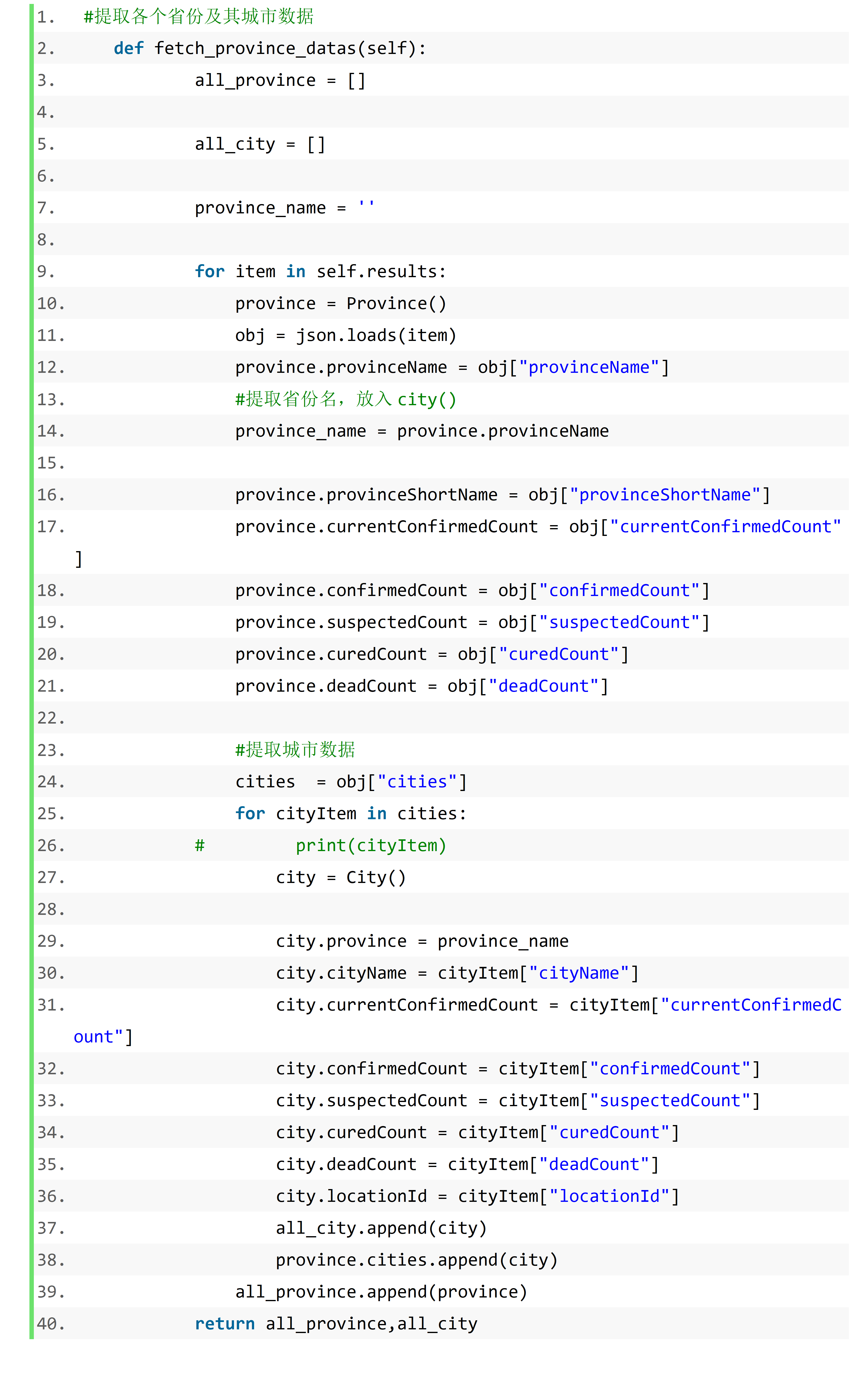
我在小组中的任务是完成丁香园国内数据的爬取操作
代码如下:



Flask 的安装及使用
Flask 框架的安装包括虚拟环境的搭建,以及 vscode 的相关操作及使用。
Flask 函数接收一个参数__name__,它会指向程序所在的包
c++
app = Flask(__name__)
装饰器的作用是将路由映射到视图函数 index
python
@app.route('/')
def index():
return 'Hello World'
Flask 应用程序实例的 run 方法 启动 Web 服务器
c++
if __name__ == '__main__':
app.run()
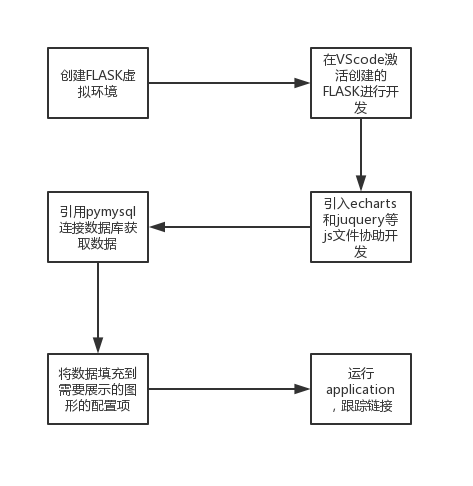
可视化的编写及展示
在这个阶段,系统的学习了前端的三件套,包括 HTML,CSS,js 等,以及 echarts 框架的使用,对于前后端交互,flask 路由,AJAX 的操作,数据库的读取以及传送等操作。
ECharts 是一个使用 JavaScript 实现的开源可视化库,涵盖各行业图表,满足各种需求。遵循 Apache-2.0 开源协议,免费商用。兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari 等)及兼容多种设备,可随时随地任性展示。ECharts 提供了很多交互组件:例组件 legend、标题组件 title、视觉映射组件 visualMap、数据区域缩放组件 dataZoom、时间线组件 timeline。
jQuery
jQuery 是一个快速、简洁的 JavaScript 框架,是继 Prototype 之后又一个优秀的 JavaScript 代码库(或 JavaScript 框架)。jQuery 设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。它封装 JavaScript 常用的功能代码,提供一种简便的 JavaScript 设计模式,优化 HTML 文档操作、事件处理、动画设计和 AJAX 交互。
jQuery 的核心特性可以总结为:具有独特的链式语法和短小清晰的多功能接口;具有高效灵活的 CSS 选择器,并且可对 CSS 选择器进行扩展;拥有便捷的插件扩展机制和丰富的插件,jQuery 兼容各种主流浏览器。
完成折线图,饼图,柱状图展示如下,以下为柱状图的相应 js 代码:
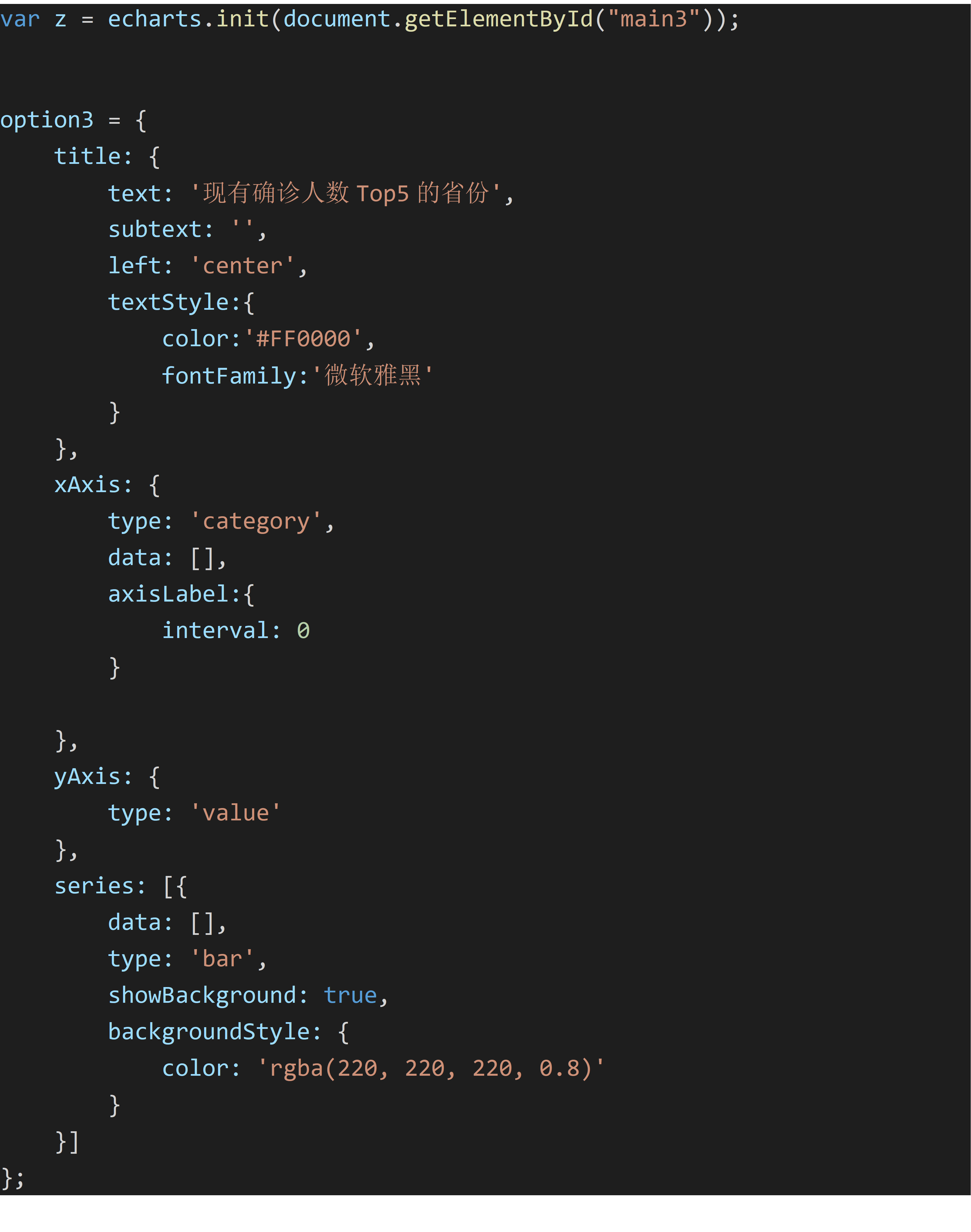
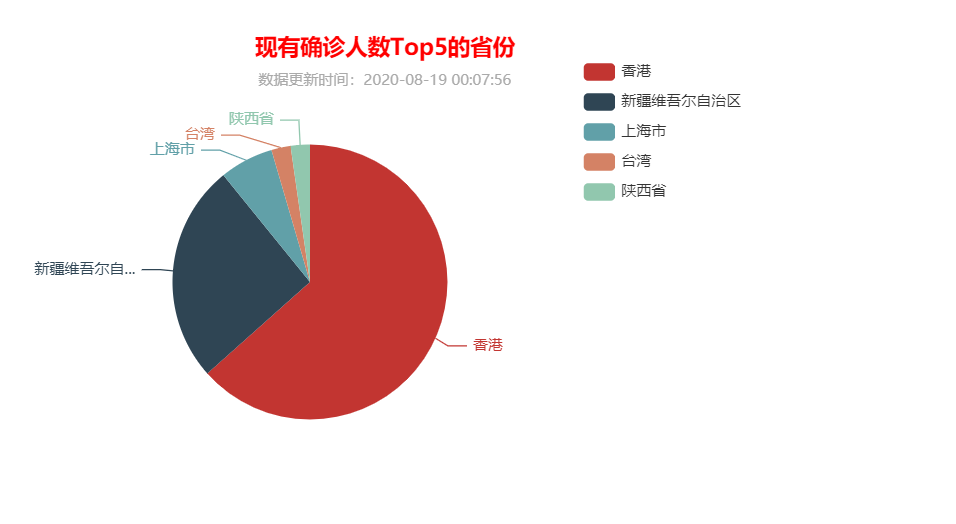
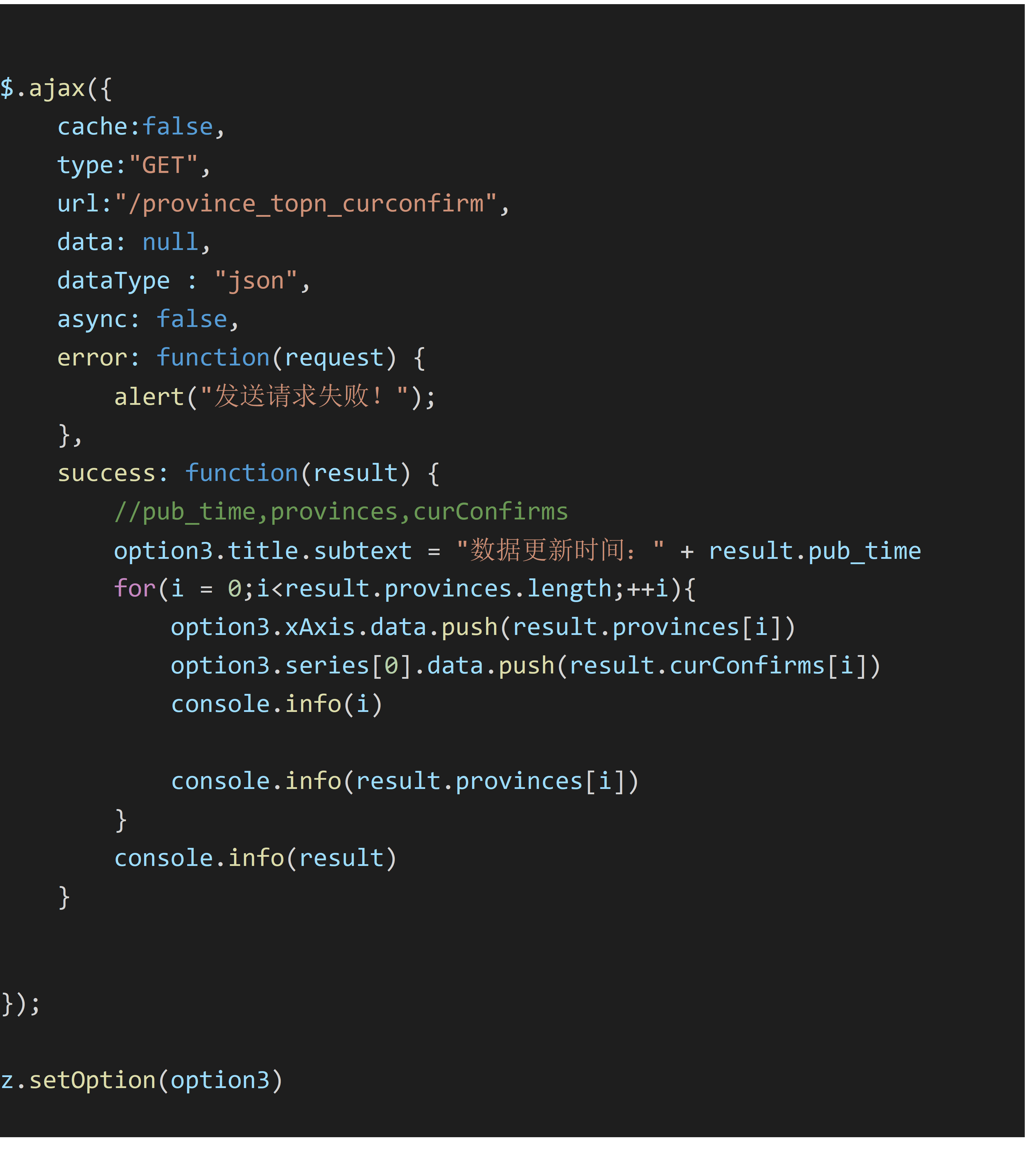
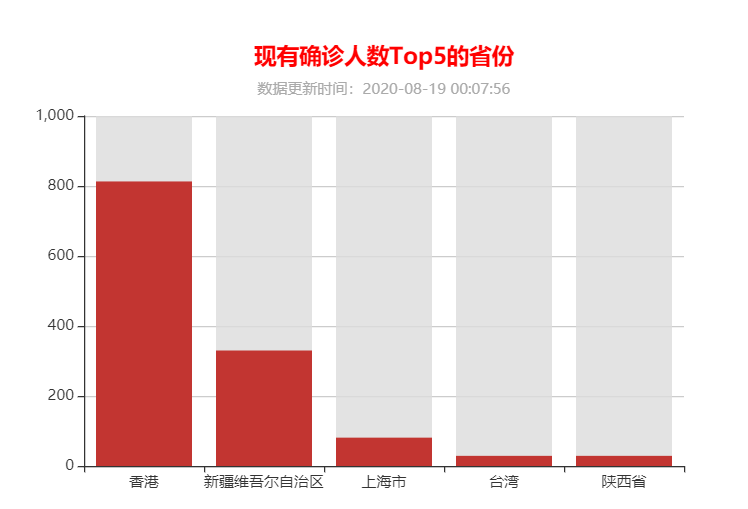
实训总结
实训过程中遇到的相关问题及突破:
在安装 flask 虚拟环境时,遇到了环境变量的问题。
解决:重新安装 anaconda 这一个软件,并且在软件安装的过程中设置了全局环境变量,使得在 window 的 cmd 中能执行 conda 这个命令,并且成功的创建出虚拟环境进行相应的开发。
在 echarts 可视化搭建中,前端页面丢包,完全显示不出来。
解决:清除浏览器缓存,并且关闭浏览器代理软件,避免浏览器页面被劫持,重新刷新网页就能通过控制台成功看到相应的 js,HTML 包的加载。
vscode 软件出现 ps 无法执行 conda 命令,激活虚拟环境
解决:通过修改 vscode 中 shell 的相应设置,将 vs 控制台 powershell 转化为 cmd 控制台页面。
在可视化开发时需要解决的问题:
如何基于 VScode 进行前端开发
如何引入需要展示的图形的模板
如何修改模板按照我们所需的图形来展示
如何使用数据库存储的数据,填充模板的数据
通过系统的练习与小组成员之间的合作,最终解决以上问题,成功完成项目的开发。
实训经验总结:
在本次实训过程中,我充分意识到了小组成员协同开发的重要性,明白了团结就是力量这一个简单而又朴素的道理,还让我意识到实践的重要性,动手敲代码才能更加熟练的掌握方法,实践是检验真理的唯一标准。
在本次实训过程中掌握的几项基本技术有 Git 版本库的使用,MySQL 数据库的搭建及使用,flask 虚拟环境的搭建及使用,HTML 前端页面的编写,后端数据库的读写以及前后端数据的交互,echarts 框架的使用。
最重要的是懂得服务器端开发的几个通用概念:API 设计,数据库操作,传输验证和异常报错。
虽然 echarts 在同类型的数据可视化框架中还算是比较的简单易用的,但是在入手的时候可能也会有一些比较麻烦的地方困扰着你,比如文档这么多我怎么看,实例已经比较齐全了我还需要看 API 文档吗,其实 echarts 的学习无外乎就是先了解一下框架大致上的分类,然后是在将全部的 API 阅读以便,使对框架有一个全局的认识,然后在通过实践去深入学习,示例只不过是这一步的一个辅助而已,只有扎扎实实的通过学习 API 一步一个脚印去了解学习,才能做到在使用的时候心中有底。
参考文献
- 基于BERT-CNN的舆情分析及可视化系统的设计与实现(西南大学·张俊龙)
- 面向“新冠肺炎疫情”热点事件的知识图谱构建研究(新疆财经大学·黎洁君)
- 基于J2EE的网络舆情分析系统的设计与实现(南京大学·李伟)
- 基于BERT-CNN的舆情分析及可视化系统的设计与实现(西南大学·张俊龙)
- 基于BERT-CNN的舆情分析及可视化系统的设计与实现(西南大学·张俊龙)
- 新冠疫情舆情信息分析系统的设计与实现(华中科技大学·胡永辉)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 新冠疫情舆情信息分析系统的设计与实现(华中科技大学·胡永辉)
- 网络舆情系统中网络爬虫和报表生成子系统的设计与实现(电子科技大学·李静)
- 利用Nutch研究与实现支持Ajax动态网页的网络爬虫系统(内蒙古师范大学·李松)
- 基于Na(?)ve Bayes算法的定向爬虫系统设计与实现(山东师范大学·张宏宽)
- 新冠疫情信息追踪及趋势预测系统的研究与实现(辽宁大学·李鹏)
- 基于机器学习的新冠肺炎疫情数据可视化分析研究与实现(吉林大学·刘莉萍)
- 面向“新冠肺炎疫情”热点事件的知识图谱构建研究(新疆财经大学·黎洁君)
- 基于标记模板的分布式网络爬虫系统的设计与实现(华中科技大学·杨林)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设助手 ,原文地址:https://bishedaima.com/yuanma/36110.html









