
例句搜索
本题使用 Python 语言实现,开发环境为 Mac OS 下的 JetBrains Pycharm IDE。最终成品为 Python 命令行 版本以及 Web 版(Django + Vue.js)。
1.主要数据结构
(1)语料库 a.数据文件格式 所有的语料均以 txt 格式存储,文件首行为语料出处(如资讯标题等),对文件标题并无要求。本次课程考核所收集的语料均为 Info 网站上近日的计算机前沿进展与新闻。
b.数据结构设计 txt 文件使用 Python 中的 open()函数以及 read()函数打开并读入为 Python 字符串类型。(2)例句库 a.数据文件格式 经过语料处理后,所有被筛选的例句均被存入一 Python 列表(List)类型中,后存入 txt 文件备份。
b.数据结构设计 在命令行版本中,列表中的每一项为一个 Python 字符串类型,字符串为例句本身及其出处的结合;而 Web 版本中,列表中的每一项为一个 Python 列表类型,包含两个字符串,分别为例句本身及其出处,在 Web 请求过程中,列表会转化为 JSON 数据格式中的 Array,如图 2-1-2(2)所示,此为“blockchain”一词在语料库中的例句库。
example: [['这是一句语料库里的例句', '这是例句的出处(Info 的标题)'], ['这是一句语料
库里的例句', '这是例句的出处(Info 的标题)']]

(3)索引字典库 a.数据文件格式 经过语料处理后,建立索引后的词句被存入一 Python 字典(Dictionary)类型中,字典类型更类似于 JSON 数据格式,并未存入本地文件备份。 b.数据结构设计 在命令行版本中,字典中的每一项,索引为单词(Python 字符串类型);Web 版本中,采用与命令行版本一样的组织结构,在 Web 请求过程中,字典会转化为 JSON 数据格式中的 Object,列表会转化为 Array,如图 2-1-3 所示,此为索引字典库的 JSON 格式。 (4)备份词库 a.数据文件格式 经过语料处理后,所有被筛选的单词均被存入一 Python 列表(List)类型中,后存入 txt 文件备份。
b.数据结构设计 在程序中,此备用词库 wordlist (List 数据类型)是用来检测在语料库中是否存在例句所用。(5)词库 a.数据文件格式 在程序中,词库(即包含中文释义、词性、词形转换、同反义词等)并未存在本地,而是使用 Request 方法从金山词霸在线词典中获取(爬虫),词库并未储存在本地。 b.数据结构设计 在命令行版本中,并未对爬虫获得的数据进行整合和组织;而 Web 版本中,涉及到对于 API 的 GET 与 POST 请求,因此封装为 JSON 数据格式进行参数传递。如图 2-1-5 所示,此为“network”在程序中传递的相关参数。代码 2.1.2 为其中的索引字段及其默认值。Phonetic 为音标(List 数据类型,包含两个字符串类型),Meaning 为释义(List 数据类型,包含若干个字符串类型),Exchange 为词形转换(List 数据类型,包含若干个字符串类型),Synonym 为同义词(List 数据类型,包含若干个 List 类型,每个 List 又包含两个字符串类型),Antonym 为反义词(List 数据类型,包含若干个 List 类型,每个 List 又包含两个字符串类型)。 代码 2.1.2Web 版本中单词数据结构举例
word: '感谢使用',
phonetic: ['英[没有内容呢]', '美[也没有内容呢]'],
meaning: ['啊噢~ 没有你要找的单词呢~是不是输错啦~Σ(o д o )'],
exchange: ['啊噢~', '没有你要找的单词呢~', '是不是输错啦~', 'Σ(o д o )'],
synonym: [['啊噢~没有你要找的单词呢~', '是不是输错啦~Σ(o д o )']],
antonym: [['啊噢~没有你要找的单词呢~', '是不是输错啦~Σ(o д o )']],
// 对应参数
phonetic: ['英[英音音标]', '美[美音音标]'],
meaning: ['词性 该词性释义'],
exchange: ['转换形式 1', '转换形式 2', '转换形式 3', '转换形式 4'],
synonym: [['单词词性/类型', '同义词']],
antonym: [['单词词性/类型', '反义词']],

2.主要算法设计
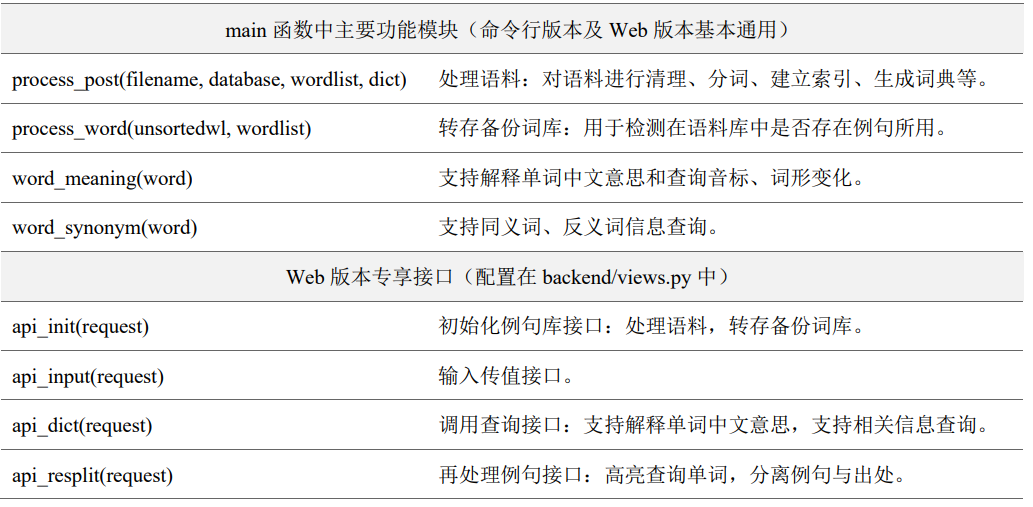
(1)通用功能函数 此处通用功能函数指命令行版本与 Web 版本皆有的功能实现性函数,根据课程考核基本要求与加分功能进行阐述。若命令行版本与 Web 版本有出入,将会备注此处引用代码版本。 代码 2.2.1 准备语料:寻找一些英文文章,例如托福、GRE 文章、英文小说、英语新闻等。处理语料:对准备好的语料进行清理、分词、建立索引、生成词典等。 re 模块:Python 自 1.5 版本起增加了 re 模块,它提供 Perl 风格的正则表达式模式。re.split(): split 方法按照能够匹配的子串将字符串分割后返回列表。 filter()函数:用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
def process_post(filename, database, wordlist, dict):
file = open("./backend/Post/" + filename, "r") # 读入语料库文件夹
title = file.readline() # 读取首行标题
raw = file.read() # 读取正文文本
raw = raw.replace(". ", ".") # 预处理语句结束符
raw = raw.replace("? ", "?")
raw = raw.replace("! ", "!")
sentences = re.split('[.?!\n]', raw) # 使用正则表达式分词进行语料分句
sentences = list(filter(None, sentences))
# 过滤空白分句结果,并转存为 list 类型
for s in range(0, len(sentences)): # 进入初步分词及建立索引
if len(sentences[s]) > 100: # 过滤过短短句及不当分句
sentence = sentences[s]
# 使用正则表达式进行例句分词
words = re.split('[ ,;:\'’‘()\[\]{}/1234567890"“@&]', sentence)
words = list(filter(None, words)) # 过滤空白分句结果,并转存为 list 类型
if sentences[s][len(sentences[s])-1] == ':':
sentences[s] = sentences[s][0:len(sentences[s])-1]
sentences[s] += '. ======' + title
sentence = sentences[s]
for w in range(0, len(words)):
if words[w][0] != '-' and words[w][0] != '+' and \
words[w][0] != '$' and words[w][0] != '&' and \
words[w][0] != '%': # 从首字符过滤非法词汇
word = str.lower(words[w]) # 转换为小写
wordlist.append(word) # 添加进入 Wordlist
# 建立词句索引
if word in dict: # 如果该词已存在索引
dict[word].append(sentence) # 值列表增加例句
else: # 如果该词不存在索引
dict[word] = [] # 新建该词索引
dict[word].append(sentence) # 值列表增加例句
database.write(sentences[s]) # 所有例句写入 database.txt 例句库
return
代码 2.2.2 再次处理语料:剔除重复例句。d 为代码 2.2.1 建立的 dict 索引, wl 为代码 2.2.1 建立的 wordlist.set()函数:创建一个无序不重复元素集,可进行关系测试,删除重复数据,计算交集、差集等
for w in wl:
d[w] = list(set(d[w]))
代码 2.2.3 转存备份词库。
def process_word(unsortedwl, wordlist):
unsortedwl = list(set(unsortedwl)) # 读取先前建立词库
sortedwl = sorted(unsortedwl) # 按字母排序
for w in range(0, len(sortedwl)):
if w != 0:
writeword = '\n' + sortedwl[w]
else:
writeword = sortedwl[w]
wordlist.write(writeword) # 转存备份
return
代码 2.2.4 根据索引进行查询:输入单词,返回相应的例句,要求支持重复查询。(命令行版)
var = 1
MIN = 5
while var == 1: # 支持重复查询
print('欢迎来到计算机英语句句搜。\n作者:林艺珺 18120189\n输入单词进行查询。输入">>>"退出。\n')
target = input() # 输入单词
if target in d:
word_meaning(target) # 调用爬取释义等函数
print('例句')
if len(d[target]) < MIN: # 最多输出 MIN 条例句
for i in range(0, len(d[target])):
print(d[target][i])
else:
for i in range(0, MIN):
print(d[target][i])
代码 2.2.5 支持解释单词的意思。中文解释。( Web 版,带返回值)支持一些相关信息查询。如同义词、反义词、词形变化等。requests 模块:使用 Apache2 licensed 许可证的 HTTP 库。 re.findall(): findall 方法在字符串中找到正则表达式所匹配的所有子串,并返回一个列表。replace()函数:把字符串中的旧字符串替换成新字符串,第三个参数 max 即替换不超过 max 次。
``` def word_meaning(word): url = "http://www.iciba.com/word?w=" + word # 金山词霸请求地址 # 建立空单词索引字典 detail = {'phonetic':[],'meaning':[],'exchange': [],'synonym':[],'antonym':[]} response = requests.get(url) # GET 请求返回 HTML # 筛选音标有效信息 phoneticwhole = re.findall('
-
(.
?)
def word_synonym(word): url = "http://www.iciba.com/word?w=" + word # 金山词霸请求地址 response = requests.get(url) # GET 请求返回 HTML detail = {'synonym': [], 'antonym': []} # 建立空同反义词索引字典 # 筛选同义词有效信息 synonymdiv = re.findall( '
同义词
(. ?)
', synonymli[j]) for k in range(0, len(synonymwl)): synonymw = re.findall('href="/word\?w=(. ?)"', synonymwl[k]) for w in range(0, len(synonymw)): synowl += synonymw[w] + ' ' detail['synonym'].append([synoposmean, synowl]) # 存入字典'synonym'索引 # 筛选反义词有效信息......省略 26 行,与上述同义词近似 if not (synonymdiv or antonymdiv): print('无同义词反义词。') return detail```
代码 2.2.6 支持不断增加语料库:采用 Python os 模块,读取指定目录下文件列表并一一打开,因此只需要在文件夹内添加符合“1.主要数据结构”中“(1)语料库”文件即可。(命令行版) open()函数:用于打开一个文件,并返回文件对象,如果该文件无法被打开,会抛出 OSError 。os 模块:提供了非常丰富的方法用来处理文件和目录。
filelist = os.listdir("Post") # 读取 Post 目录下文件列表
d = dict() # 新建空字典
wl = [] # 新建空列表
db = open("database.txt", "w") # 打开例句库文件
for fn in filelist:
process_post(fn, db, wl, d) # 处理语料
db.close()
sortedwl = open("sortedwl.txt", "w")
process_word(wl, sortedwl) # 存储备份词库
sortedwl.close()
(2)Vue.js 调用 Django 函数 API 搭建 Web 版本应用 由于 Vue.js 以及 Django 不是本课程的教授内容,加上自己也是初学者,因此这一板块略写。 Django Python 下一重量级 Web 框架,采用了 MVT 的软件设计模式,即 Model,View 和 Template。Axios 是一个基于 Promise 的 HTTP 库,可以用在浏览器和 node.js 中。 Vue.js 是一套构建用户界面的渐进式框架;只关注视图层; API 实现响应的数据绑定和组合视图组件。Element-UI 一套为开发者、设计师和产品经理准备的基于 Vue 2.0 的桌面端组件库。 代码 2.2.7 预处理: import django 相关函数;解决前端 post 请求 csrf 问题; Vue.js 中 main.js 配置。
``` // views.py from django.http import JsonResponse, HttpResponse from django.views.decorators.csrf import csrf_exempt
// urls.py from django.urls import path from . import views urlpatterns = [ path('input/', views.api_input, name='api_input'), path('dict/', views.api_dict, name='api_dict'), path('init/', views.api_init, name='api_init'), path('resplit/', views.api_resplit, name='api_resplit'), ] // main.js import Vue from 'vue' import App from './App.vue' import ElementUI from '../node_modules/element-ui'; # import ElementUI 组件 import '../node_modules/element-ui/lib/theme-chalk/index.css'; import VueRouter from "vue-router"; import axios from 'axios' # import axios import qs from 'qs' # import qs 解决 axios 传参问题 Vue.use(VueRouter); # Vue 需要 use 才可生效(......省略 qs,axios,UI 的 use) # 路由配置 const router = new VueRouter({ mode: "history", routes: [ { path: "/", component: () => import("@/components/HelloWorld.vue") }, { path: "/Detail", component: () => import("@/components/Detail.vue") }, ] });
// HelloWorld.vue
参考文献
- 文本信息检索模型研究(西南大学·黄果)
- 基于三层体系结构的网络搜索与信息处理系统(广东工业大学·梁继能)
- 主题网络爬虫关键技术研究(哈尔滨工业大学·王桂梅)
- 基于本体的构件描述以及Jena框架下构件库的设计和实现(吉林大学·黄怡)
- 沈阳地铁门户搜索引擎的设计与实现(东北大学·张森)
- 基于领域的网络爬虫技术的研究与实现(武汉理工大学·谭龙远)
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- 基于网络爬虫的电影集成搜索系统设计与实现(江西农业大学·江沛)
- 基于Lucene技术搜索引擎设计与实现(吉林大学·张阳)
- 主题网络爬虫的分析与设计(北京邮电大学·王洪威)
- 基于网络爬虫的搜索引擎的设计与实现(湖北工业大学·冯丹)
- 基于元搜索的Web信息搜索技术研究(吉林大学·张春磊)
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- 基于主题的多线程网络爬虫系统的研究与实现(北京邮电大学·陈露)
- 基于Lucene的中英文文档全文搜索引擎(电子科技大学·张瑞)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设驿站 ,原文地址:https://bishedaima.com/yuanma/36036.html









