神经网络作业一实验报告
使用了 tensorflow 框架,参考了官方手册和教程进行实现,搭建了一个多层感知机对 MNIST 数据集进行分类。main.py 是入口函数,负责读取 MNIST 数据、调用各项学习方法、并绘制最后的性能图。MLP 相关代码位于 baseline.py,实现了一个单隐层的多层感知机,采用 sigmoid 激活函数,训练轮数为 50 轮。
其余文件均为 baseline 的变体,修改了对应的需要对比的点。
一、如何运行
运行 main.py 即可。
| 方法 | 50 轮后的测试集准确率 | 训练集准确率 |
|---|---|---|
| baseline | 0.8944 | 0.8935 |
| 全 0 初始化 | 0.1138 | 0.1162 |
| 均方误差 | 0.8320 | 0.8413 |
| adam 自适应学习率 | 0.9564 | 0.9502 |
| L2 正则化方法 | 0.8861 | 0.8937 |
各项方法对比 不同的参数初始化方法
这里选择了全 0 初始化来与 baseline 方法的随机初始化对比。
不同的损失函数
这里选择了均方误差来与 baseline 方法的交叉熵损失对比。
不同的学习率调整方法
这里选择了 adam 自适应学习率方法来与 baseline 方法的固定学习率对比。
不同的正则化方法
这里选择了 L2 正则化方法(正则化项权重设为 0.001)来与 baseline 方法的无正则化对比。
对比结果
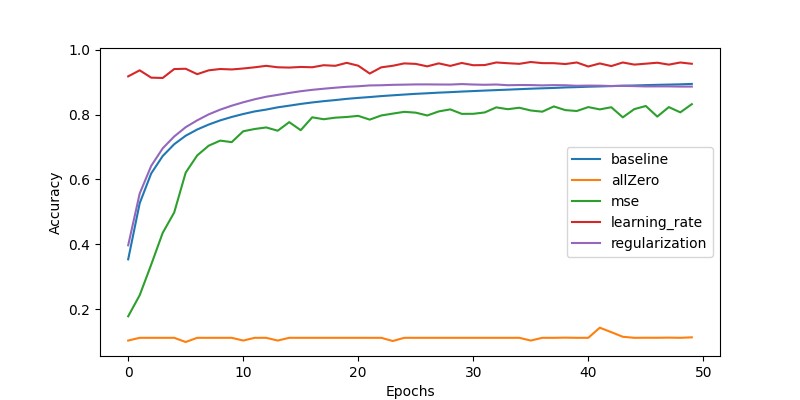
全 0 初始化让 MLP 无法训练,故准确率一直保持在 11% 左右;均方误差性能不如交叉熵,因为是多分类而不是回归问题,使用交叉熵损失函数会更合适一些;采用自适应学习率比固定学习率更灵活高效,故收敛也更快,且性能更好,可以找到全局最优;使用 L2 正则化后训练集准确率提升更快,但最后达到收敛时训练集准确率比不正则化要略低一些,可能是因为防止了过拟合,并且使用 L2 正则化后测试集准确率略有提高。
二、最后选用的方法
随机初始化,交叉熵损失函数,adam 自适应学习率方法和无正则化。
因为 adam 自适应学习率方法和 L2 正则化都能提升性能,但我测试了一下同时采用这两种方法,性能反而下降了。所以还是只改进成 adam 自适应学习率方法性能最好。50 轮内训练集准确率最高为 0.9604,最终测试集准确率为 0.9502。
参考文献
- 基于动态连接池的数据集成中间件的研究与实现(广西师范大学·黄桂花)
- 面向人物简介的主题爬虫设计与实现(吉林大学·蒋超)
- 数据操纵建模技术的研究与应用(西安工程大学·陈静)
- 基于网络爬虫的信息采集分类系统设计与实现(厦门大学·周茜)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 文本综合处理平台的研究与实现(济南大学·王孟孟)
- 基于Web的网络搜索技术研究(西北工业大学·郭晨娟)
- 基于B/S的考卷搜索和标记系统的设计与实现(华中师范大学·沈亮)
- 面向特定网页的Web爬虫的设计与实现(吉林大学·马慧)
- 主题网络爬虫的研究与设计(南京理工大学·朱良峰)
- 基于数据挖掘的电视节目个性化推荐研究及实现(曲阜师范大学·徐晟杰)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 一种高适应性面向领域的爬虫系统的设计与实现(北京邮电大学·李东博)
- 云环境下面向大数据的模糊C均值算法研究与实现(武汉理工大学·余长俊)
- 数据集市在电信经营分析中的应用研究(苏州大学·赵平)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设导航 ,原文地址:https://bishedaima.com/yuanma/35990.html