
基于 Python 实时图像获取及处理软件设计
摘要
随着信息技术的发展、电子设备的普及以及通信技术的进步,人们已经越来越习惯于使用图像这种便捷高效的方式进行交流,图像获取与处理也由此进入了一个高速发展的时期。
现如今,图像处理相关技术在日常生活中随处可见。USB 摄像头因其即插即用的便捷性、相对廉价的成本和不弱的性能,成为最具优势的图像获取设备。而在图像处理方面,人脸识别无疑是当前最热门的领域之一。随着技术的进步,尤其是机器学习、人工智能的突破性发展,人脸识别技术逐渐应用到众多的个人设备上,用于解锁、移动支付,甚至交友相亲等方方面面。
本文是在 Windows 系统下基于 Python 语言开发的图像获取与处理软件,实现了图像实时获取、显示并处理的功能。其中,图像获取使用的便是 USB 摄像头,并且能够摄像头的部分属性参数进行调整以便获取更高质量的数字图像;图像处理部分实现了灰度化、直方图、边缘检测以及人脸检测与识别功能。选用开源的可以跨平台运行的计算机视觉库 OpenCV 来实现以上各种功能;最后使用 GUI 开发库 PyQt 5 整合各功能模块,编写生成可执行的软件供用户使用。
关键词 :图像获取;图像处理;人脸识别
一、绪 论
1.1 课题背景及研究的目的和意义
随着信息技术的发展、电子设备的普及以及通信技术的进步,人们已经越来越习惯于使用图像这种便捷高效的方式进行交流,图像获取与处理也由此进入了一个高速发展的时期。摄像头作为最常用到的图像获取设备,非但已经遍布大街小巷,更是走进了千家万户、被人们时常捧在手中。USB 摄像头因其即插即用的便捷性、相对廉价的成本和不弱的性能,成为最具优势的图像获取设备。而在图像处理方面,人脸识别无疑是当前最热门的领域之一。
本课题旨在利用 Python 语言,提取 USB 摄像头相关参数及图像,并对数字图像进行灰度化、直方图绘制、边缘检测以及人脸检测和识别等处理。通过在 Windows 操作系统下使用 Python 语言编写的可视化软件,用户可以方便的查看和设置 USB 摄像头的主要参数,并实时监控、保存图像的各特征,着力提高摄像头获取图像的便捷性和实用性,而人脸识别技术的应用,更大大扩展了该软件的应用空间。
1.2 摄像头图像获取及人脸检测与识别的应用
如今,摄像头在人们生产生活中已经随处可见。人脸识别技术也已广泛应用于各个行业,如:楼宇人脸门禁、人脸考勤系统;互联网移动支付终端、交友、相亲终端 APP 系统等。
打开摄像头,刷一下脸,便可以完成支付;从大量的人脸数据库中,公安部门通过人脸识别系统更轻松地找出嫌疑人,如近日警方接二连三的在张学友演唱会中通过人脸识别系统抓获犯罪嫌疑人,如此壮举举国瞩目。这些从侧面反映出这些人脸识别技术如科幻电影一样,已经变成现实。
当然在当下极为火热的人脸考勤系统中,进行“刷脸”考勤,而目前考勤正确率已经达到很高的级别,最典型的就是“刷脸”考勤机,这其实就是一种新型的存储类考勤机,在这之前首先只需以员工人脸图像作为采集对象建立起训练数据库,当员工在上下班考勤时,只需要站在考勤机的识别区域内,考勤机上就会根据输入的图像与自身的训练数据库作为比对,同时也将记录此时的人脸数据并存储。
人脸识别在安防系统中也扮演着不可忽视的作用与价值。人脸识别门禁系统在住所、办公大楼等重要场所也发挥着作用,它利用着人脸识别技术相当于一把 “钥匙”作为通行证,这项技术的关键是通过扫描设备将所扫描的人脸图像作为输入人脸图像与预先录入的人脸库比对,如果比对一致将使门禁系统打开,否则关闭,这其实就是“刷脸”来开启或关闭建筑物内的人脸识别门禁系统。同样的近年来许多火车站进站口也改用了人脸识别来代替人工核验身份证。
二、实时图像获取及处理的相关原理
2.1 实时图像获取设备
图像采集与处理在实时图像处理系统占有重要地位,是数字图像处理的一个关键的前提。只有实现目标场景图像的视频捕获显示及其数据获取,才能对之进行相应的分析与处理。视频采集是将一个视频流数字化,然后储存在硬盘或其它存储介质上形成一个整块集中的数据块,以供进一步处理。所以本文将首先介绍图像获取的相关内容。
2.1.1 USB 摄像头图像采集原理
当前,几乎所有的图像都是通过光学镜头获取的,而我们更关心的是对图像的数字化采集。捕获图像可以采用视频采集卡,也可使用 USB 接口的数码摄像头,视频采集卡一般提供了特定品牌和型号的动态连接库和开发工具包,价格相对较贵,USB 接口的数码摄像头价格适中,性能尚可。另外,采用 USB 接口的数码摄像头,系统的硬件体系结构比较简洁,无需再配图像采集卡上位机便可直接进行图像数据处理[9]。基于对课题需求的分析,显然 USB 摄像头是最合适的选择。
数字摄像头其实是把感光器件和视频捕捉器件做到了一起,一般是由镜头、感光器件、A/D(模/数转换器)、微处理器、内置存储器和接口(计算机接口、电视机接口)等部件组成。 其中感光器件一般有 CCD 和 CMOS 两种。而 USB 技术由于其便捷的操作, 热插拨形式的支持, 可以实现即用即连, 在多个领域有着广泛应用。
不同品牌不同型号的摄像头功能和性能是各不相同的。在与软件交互、实现对摄像头图像采集的控制时,实际是一操作系统(驱动层)为中介完成的。

因此我们必须关注 USB 摄像头的驱动。
2.1.2 Windows 操作系统下摄像头的驱动
在本课题中,选择了基于 USB 的普通摄像头,上位机采用 PC 机。在上位机中,系统采用 Windows 操作系统,在 Windows 操作系统下 USB 设备的驱动和视频应用开发都是一项非常复杂的工作。幸运的是,Windows 内核承担了大部分的工作。为了提高系统的稳定性,Windows 操作系统对硬件操作进行了隔离;应用程序一般不能直接访问硬件,程序开发者是通过接口在应用层面,而非硬件层面,来完成相关软件开发。
根据使用驱动程序的类型不同,目前市场上的图像获取设备大致分为两大类:
VFW(Video for Windows)和 WDM(Windows Driver Model)。前者是一种趋于废弃的驱动模型,而后者是前者的替代模型。
VFW 是 Microsoft 1992 年推出的关于数字视频的一个软件包。在 Windows 9x 及以上版本系统中,当用户在安装 VFW 时,安装程序会自动地安装配置视频所需要的组件,如设备驱动程序、视频压缩程序等。VFW 软件开发工具包为在 Windows 系统中实现视频捕获提供的标准接口可以被大多数视频采集卡支持,并有多种视频压缩驱动供选择。
现在许多新的视频捕捉设备都采用的是 WDM 驱动方法(Windows Driver Model(WDM)的缩写,中文意思是“视窗驱动程序模块”),在 WDM 机制中,微软提供了一个独立于硬件设备的驱动,称为类驱动程序。驱动程序的供应商提供的驱动程序称为 Minidrivers。Minidrivers 提供了直接和硬件打交道的函数,在这些函数中调用了类驱动。
操作系统仍然支持 VFW 驱动程序,但是依赖于 VFW 的开发将逐渐减少。
表 2-1 WDM 驱动下常用接口
| DirectShow 接口 | 相关属性 |
|---|---|
| IAMTuner | PROPSETID_VIDCAP_TUNER |
| IAMTVAudio | PROPSETID_VIDCAP_TVAUDIO |
| IAMCrossbar | PROPSETID_VIDCAP_CROSSBAR |
| IAMVideoProcAmp | PROPSETID_VIDCAP_VIDEOPROCAMP |
| IAMAnalogVideoDecoder | PROPSETID_VIDCAP_VIDEODECODER |
| IAMAnalogVideoEncoder | PROPSETID_VIDCAP_VIDEOENCODER |
| IAMCameraControl | PROPSETID_VIDCAP_CAMERACONTROL |
从编程实现的角度看,对 WDM 卡选择视频输入端子、设置采集输出的图像格式、设置图像的对比度、亮度、色调、饱和度等显示参数,都是通过 COM 接口 IAMCrossbar、IAMStreamConfig 和 IAMVideoProcAmp 来实现的。但对于 VFW 卡,我们却不能编程实现上述设置,而必须将驱动程序定制的设置对话框直接显示给用户(让用户在这些对话框上做出选择);VFW 驱动程序定制的设置对话框包括: Video Source(设置图像源属性)、Video Format(设置图像输出格式)和 Video Display
(设置图像显示参数)。
对于应用程序开发人员来说,以上内容原理不可以不知,但也没必要研究得太透彻,而只需有一个总体的认识、作为背景知识了解一下就够了。
2.2 数字图像处理与人脸识别原理
数字图像处理概念广泛。就本课题而言,图像源已确定为从 USB 摄像头获取的图像,故为视觉图像。而在图像处理方面,在摄像头获取的彩色图像的基础上,进行初级的灰度化处理、中级的边缘检测、灰度直方图和高级的人脸检测和识别。
2.2.1 图像处理基础
彩色空间与灰度化
图像获取是图像处理的第一步,通过 USB 摄像头获取的图像一般是与人类视觉图像相仿的彩色图像。彩色模型(也成为彩色空间或彩色系统)的目的是在某些标准下用通常可以接受的方式方便地对彩色加以说明。本质上,彩色模型是坐标系统和子空间的说明,其中,位于系统中的每种颜色都由单个点表示。
在数字图像处理中,实际中最通用的面向硬件的模型是 RGB(红、绿、蓝)模型,该模型用于彩色监视器和大多数彩色视频摄影机。本课题需要处理的图像即RGB 彩色模型的数字图像。
在 RGB 模型中表示的图像由 3 个分量图像组成,每种原色一幅分量图像。当送入 RGB 显示器时,这三幅图像在屏幕上混合生成一幅合成的彩色图像。在 RGB 空间中,用于表示每个像素的比特数称为像素深度。考虑一幅 RGB 图像 ,其中每一幅图像都是 8 比特图像,在这种条件下,可以说每个 RGB 彩色像素有 24 比特的深度。
而很多图像处理操作是以灰度图像为基础的,因为将各种格式的图像转变成灰度图多通道的彩色图像变换为单通道的灰度图像后,这样一来计算量就会少得多了[10]。
一幅图像可以定义为一个二维函数 f(x,y),其中 x 和 y 是空间(平面)坐标,而在任何一对空间坐标(x,y)处的幅值 f 称为图像在该点处的强度或灰度。
一般有分量法、最大值法平均值法加权平均法四种方法对彩色图像进行灰度化。

图 2-2 灰度化图片
而灰度变换是直接以图像中的像素操作为基础的空间域处理。空间域就是简单的包含图像像素的平面,某些图像处理任务在空间域执行更容易或者更有意
义,而且通常空间域技术在计算上更有效,且在实行上需要较少的处理资源。
灰度变换是所有图像处理技术中最简单的技术。
直方图
一幅图像由不同灰度值的像素组成,图像中灰度的分布情况是该图像的一个重要特征。图像的灰度直方图就描述了图像中灰度分布情况,能够很直观的展示出图像中各个灰度级所占的多少。图像的灰度直方图是灰度级的函数,描述的是图像中具有该灰度级的像素的个数:其中,横坐标是灰度级,纵坐标是该灰度级出现的频率。
具体的说:灰度级范围为[0,L-1]的数字图像的直方图是离散函数 h(rk)= nk,其中 rk 是第 k 级灰度值,nk 是图像中灰度为 rk 的像素个数。在实践中,经常用成绩 MN 表示的图像像素的总数除它的每个分量来归一化直方图,通常 M 和 N 是图像的行和列的维数。因此,归一化后的直方图由 h(rk)= nk/MN 给出,其中 k=0,1,…,L-1。简单地说 p(rk)是灰度级 rk 在图像中出现的概率的一个估计。
直方图是多种空间域处理技术的基础。直方图在软件中计算简单,而且有助于商用硬件实现,因此已经成为实时图像处理的一种流行工具。
2.2.1 边缘检测
边缘检测是图像处理和计算机视觉中的基本问题,其目的是标识数字图像中亮度变化明显的点。图像属性中的显著变化通常反映了属性的重要事件和变化。这些包括深度上的不连续、表面方向不连续、物质属性变化和场景照明变化。边缘检测是图像处理和计算机视觉中,尤其是特征提取中的一个研究领域。
边缘检测是基于灰度突变来分割图像的最常用方法。我们从介绍一些边缘建模的方法开始,讨论一下边缘检测的原理和几种方法。边缘模型根据它们的灰度剖面来分类,一般可以分为台阶、斜坡和屋顶三种模型。下图展示了这三种模型的灰度剖面和理想表示:
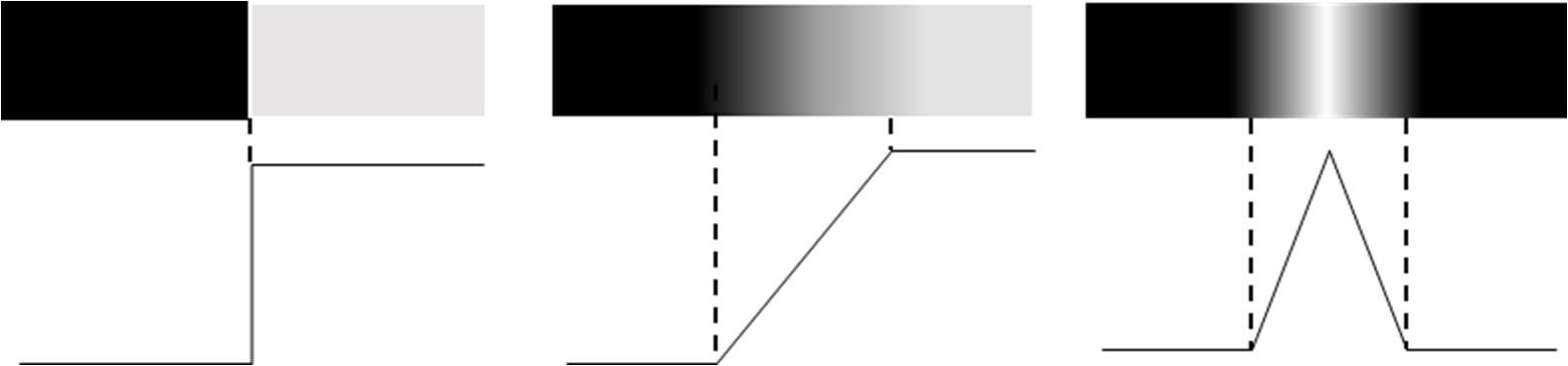
台阶模型 b.斜坡模型 c.屋顶模型图 2-3 三种灰度剖面的理想模型
实际中。虽然噪声和模糊会导致与理想模型有偏差,但类似与这三种模型的边缘图像并不罕见。因此我们进行边缘检测时,能够根据这几种模型写出边缘数学表达式,这些算法的性能将取决于实际边缘和算法开发过程中所用模型之间的差别。

图 2-4 理想斜坡模型及其各阶导数
观察理想斜坡模型及其各阶导数,如右图所示。很容易看出,在斜坡开始和斜坡上各个点处,一阶导数为正。而在灰度区域一阶导数为零。在斜坡开始时,二阶导数为正;在斜坡结束处,二阶导数为负;在斜坡上和恒定灰度区域的各点二阶导数均为零。于是我们可以得出结论,一阶导数的幅值可用于检测图像中的某个点处是否存在一个边缘,二阶导数的符号可用于确定边缘像素位于该边缘亮的一侧还是暗的一边,同时二阶导数零交叉点可用于定位粗边缘的中心。类似的结论可以适用于图像中任何区域的边缘。
根据以上结论,可以得出边缘检测的三个基本步骤:平滑降噪、边缘点检测和边缘定位。
最通用的方法是使用一阶和二阶导数来检测。检测灰度值的不连续性。从梯度来看,根据其微分特性,在恒定灰度区域的值为零,且其梯度值与灰度变化值变化程度相关。要得到一幅图像的梯度,则要求在图像的每个像素位置计算偏导数,当对对角线方向的边缘感兴趣时,我们需要一个二位模板。常用的模板有 Sobel 模板、Prewitt 模板等。使用模板求得各方向响应,再结合合适的阈值,便能够找到图像的边缘。
一些更为先进的边缘检测技术尝试考虑诸如图像噪声和边缘本身特性的因素改进简单的边缘检测,以获得更好的效果。成功的尝试有 Marr-Hildreth 边缘检测器、Canny 边缘检测等。大量的计算机视觉库都有相关算法的集成,在使用时直接调用即可。
2.2.2 基于机器学习的人脸检测与识别
人脸识别技术,作为一种典型的模式识别问题,简而言之,这是首先利用计算机分析人脸图像,进而从中提取有效的识别信息,最后用来辨认身份的一门技术。模式识别主要分为两大领域:决策理论方法和结构方法。第一类方法处理的是定量描绘子来描述的各种模式。第二类方法处理的是由定性描绘子来描述的各种模式。下文所述为本课题所要实现的基于机器学习的人脸检测与识别原理。
机器学习本质是将数据转换为信息——通过从数据中提取规则或模式来把数据转换为信息。在学习了一系列数据之后,我们需要机器能够回答与这些数据有关的问题。就人脸识别而言,假如我们有一个数据库,它是对 10000 张人脸图像进行边缘检测,然后收集特征,如边缘方向、边缘长度、边缘相对脸中心的偏移度。我么从每张脸中获得一个含有 500 个数据和 500 项特征向量。然后我们通过机器学习技术根据这些特征数据创建某种模型。如果我们仅仅想把这些数据分成不同的类(如检测判断是否为人脸),一个“聚类”算法就足够了。如果想学习从人脸的边缘的模式测算他的年龄,甚至识别出他是谁的话,我们则需要一个“分类”的算法。为了达到这个目的,机器学习算法分析我们收集的数据,分配权重、阈值和其他参数来提高性能。这个调整参数来达到目的的过程被称为“学习”(learning)。
机器学习用到的大量的原始数据一般会分为三部分使用,即训练集、验证集和测试集。我们利用训练集来训练我们的分类器,学习人脸模型,训练结束后,我们用测试集来测试检测识别人脸。验证集常常在开发训练分类系统时使用。有的时候测试整个系统是一个太大的工作。我们需要在提交分类器进行最终测试之前调整参数。即当训练完之后,我们尝试性的提前用验证集来测试分类器效果。只有对分类器性能感到满意,才用测试集做最后的判断。
基本上,所有机器学习算法都使用特征构成的数据向量作为输入。在本课题中,人脸识别的最终目标是能够从摄像头获取的图像中检测人脸,并最终识别出作者本人。因此所有的训练集、验证集和测试集数据都是通过摄像头获取,并通过必要的预处理工作,提取出高质量的人脸数据用于训练和测试。
数据准备好后,下面就是选择分类器了。分类器不存在“最好”,但如果给定了特定的数据分布的话,通常存在一个最好的分类器。一般分类器的选择需要考虑计算速度、数据形式和内存大小。对于人脸检测和识别这类不需要很快训练而需要准确度高、判断快的任务,神经网络可以满足要求,但性能更好的选择是 boosting 和随机森林算法。
Boosting 是多个分类器的组合。最终的分类决策是由各个子分类器的加权组合来决定的。在训练时,逐个训练子分类器,且每个子分类器是一个弱分类器(只是优于随机选择的性能)。这些弱分类器由单变量决策树组成,被称为树桩,而且还根据识别精度学习“投票”的权重。当逐个训练分类器的时候,数据样本的权重被重新分配,使之能够给与分错的数据更多的注意力。训练过程不停地执行,直到总错误低于某个已经设置好的阈值。为了达到好的效果,这种方法需要很大数据量的训练数据。
综上所述:人脸识别由图像获取、人脸检测部位、图形预处理、特征提取和选择、训练和识别六大功能模块组成。
本课题用到的 Haar 人脸检测分类器便是巧妙地使用了 boosting 算法,建立了 boost 筛选式级联分类器。具体实现方法将在第三章相关章节介绍。通过调用训练的到的 XML 文件,人脸检测的难题便迎刃而解了。而人脸识别需要根据识别对象的大量数据训练对应的 XML 文件用于识别。
三、基于 Python 的软件设计与编程
本课题使用 Python 作为编程语言。诞生于 1989 年的 Python 语言,作为第四代计算机编程语言 ,具有卓越的通用性高效性、平台移植性和安全性,同时又因其功能强大的解释性、交互性和面向对象编程的特性,既简单易学、又清晰高效,成为当下极为流行的编程语言之一。
Python 代码很容易阅读和编写,并且非常清晰没有什么隐秘的。Python 是一种表达能力非常强的语言, 这意味着, 在设计同样的应用程序时, 使用 Python 进行编码所需要的代码量远少于其他语言的代码量。目前 Python 官方网站版本已经更新至 Python 3.6.4 和 Python 2.7.14,强大的标准库奠定了 Python 发展的基石,丰富的第三方库保证了 Python 不断发展的,其开源特性和活跃的社区更是提供了强大的发展动力。
Python 自带的 IDLE,精简又方便,不过一个好的编辑器能让 python 编码变得更方便,更加优美些。常用的 Python 编译器有 PyCharm、Sublime 等。不过本课题选用 Visual Studio Code 作为编译器。这是微软公司发布的一款跨平台编辑器,轻便又易用。
当我们搭建好 Python 开发环境,安装好编译器以后,就可以着手开始软件编写了。接下了一整章的内容,我们将详细介绍如何基于 Python 语言实现本课题的所有功能。
3.1 程序结构设计
图形用户界面设计与程序结构设计是互为表里的。或者说,程序结构设计是软件设计最本质、最核心的内容。徒有界面而内部逻辑结构混乱的软件一无是处。
Windows 操作系统是一款图形化的操作系统,相比于早期的计算机使用的命令行,图形界面对于用户来讲更易于接受。GUI 程序是一种基于消息驱动模型的可执行程序,程序的执行依赖于和用户的交互,实时响应用户操作。GUI 程序执行后不会主动退出。GUI 程序运行模型如图 3-2 所示。

图 3-2 GUI 程序运行模型
程序框图是展现程序结构最直观、最清晰的方式,该软件总体的结构框图将在文末附录 Ⅰ 中给出。
本程序充分继承了 Python 语言面向对象编程的优势,各模块之间相互独立又彼此联系,同时 GUI 编程是采用了界面显示与业务逻辑分开的思想,既结构清晰又便于软件维护更行。为了使条理更清晰、也限于篇幅,图 3-2 仅着重展现了程序各模块之间的相互关系。各模块内部逻辑,将在下文分别给出。
3.2 利用 OpenCV 获取图像
3.2.1 从摄像头获取图像
如 2.1 节所述,在 Windows 操作系统下调取摄像头是一件牵涉到应用程序、驱动程序、硬件接口等的相当复杂的事情,但使用 OpenCV 让它变的简单起来。
OpenCV 在 HigeGUI 模块中做了很多工作,整合了 DirectShow 等等,使我们在获取摄像头图像时不需要考虑这些问题,只需要调用其封装好的接口,便能获取摄像机图像序列,像一般的图片或视频文件一样进行处理。
本次毕设中用到的 VideoCapture 类,便是 OpenCV 的 HigeGUI 中的获取视频图像的常用工具。在 Python 中的调用方式主要有以下两种:
cv2.VideoCapture(filename) → < VideoCapture object>
cv2.VideoCapture(device) →< VideoCapture object>
前者用于从文件中获取视频图像,”filename”即视频文件获取路径及名称。后者即我们需要用到的读取摄像头视频的形式,”device”是已加载的摄像头设备的 ID,如果仅仅连接了一个摄像头设备的话,只需输入“0”即可默认选中。如果我们想要允许用户自主选择的话,可以输入参数“-1”,这样在程序运行时会自动弹出一个对话框,列出所有可供选用的摄像头设备。

图 3-4 切换摄像头方法程序框图
本课题中,切换摄像头功能的实现是通过循环输入设备 ID 的列表来实现的,其程序程序框图如图 3-4 所示。这样的话,我们需要判断使用该 ID 的设备是否存在。于是用到了 VideoCapture 类。
cv2.VideoCapture.isOpened() → flag
该方法的返回值是一个布尔值,即当摄像头成功开启的话,返回 True,否则返回 False。之后,我们只需要再次调用 VideoCapture 中的另一个方法:
cv2.VideoCapture.read([image]) → successFlag, image 便能够从所选中的摄像头中获取当前帧了。
当然,从摄像头获取图像时有诸多属性参数是有必要进行一些调节的,这个操作我们同样可以使用 OpenCV 来完成。
在此之前,有一点还是需要明确的:OpenCV 虽然十分强悍,但它本质上仍是计算机视觉库,而不是视频流编码器或者解码器。之所以将视频获取这一部分做的强大一些,只是为了更方便后续的处理。而我选用 OpenCV 一方面是因为其方便易用的特点,更重要的是因为它能够满足本次毕业设计对摄像头操作的需求。如果想要突破限制实现功能更强大的多媒体功能的话,OpenCV 并不是一个好的选择。
3.2.2 摄像头相关参数获取与设置
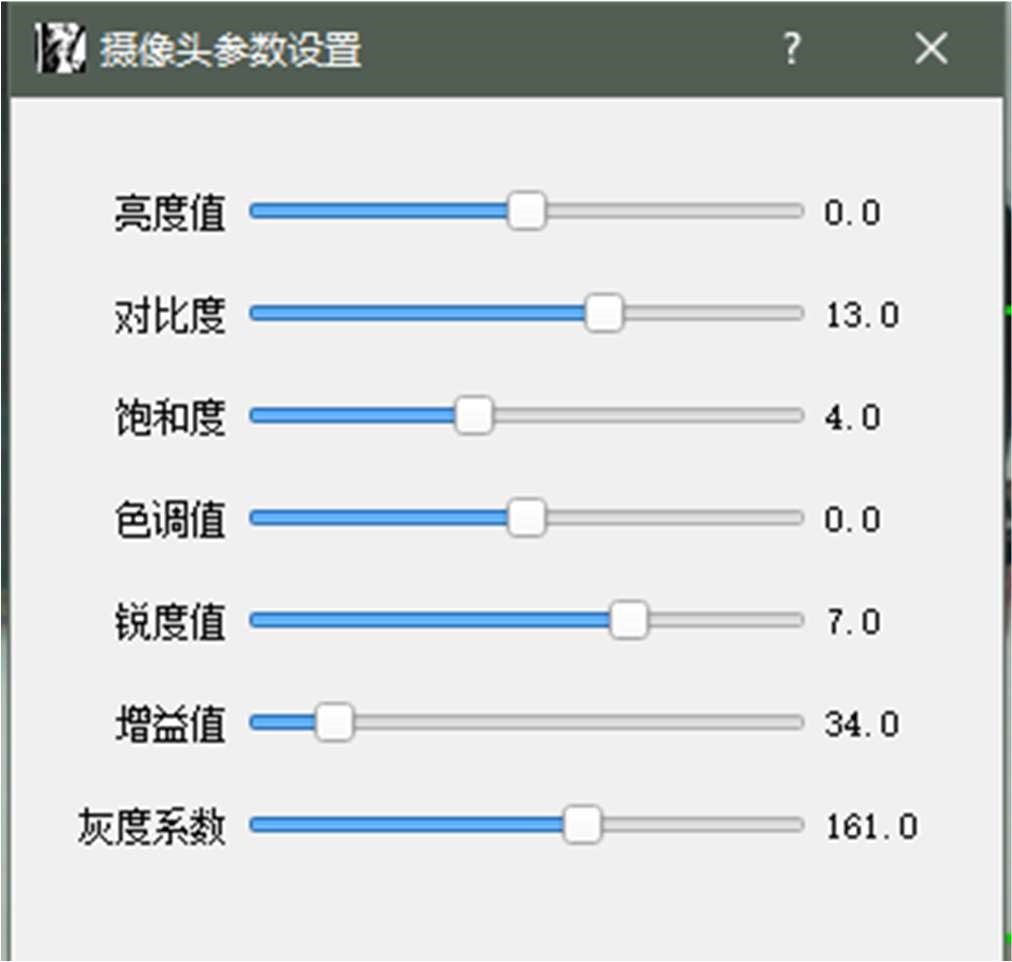
我们在使用 USB 数字摄像头获取图像的时候,在不同的外部环境条件下,有一些属性参数——如亮度、对比度等——是需要随时做出调整的。当然,目前多数摄像头都是可以自动调节的,但是针对不同的图像获取需求,对属性参数进行手动设置还是不可或缺的。
不同型号摄像头可调节的参数是各不相同的,有些高端摄像头可调参数甚至多达上百个。就一般需求而言,最常用到的属性参数,无非就是亮度、对比度、饱和度、增益、锐度、白平衡、色调、灰度系数等等。对于这些参数,我们同样可以通过 OpenCV 的 VideoCapture 类来获取和设置:
cv2.VideoCapture.get(propId) → retval
cv2.VideoCapture.set(propId, value) → retval
前者用于参数值获取,后者用于设置。其中,“propID”即属性标识符(Property identifier),部分可选项及其含义列于表 3-1。
不过对于属性参数可调的范围,OpenCV 并未给出确定的方法。不过我们可以通过循环设置参数值的方法,找到上下限。
摄像头参数设置的功能通过程序弹出对话框的方式实现,因为涉及到 GUI 编程的知识,更详细介绍和程序结构示意图将在 3.5.3 节中呈现。
表 3-1 部分属性标识符及其含义
| 属性标识符 | 涵义 |
|---|---|
| cv.CAP_PROP_FRAME_WIDTH | Width of the frames in the video stream. |
| cv.CAP_PROP_FRAME_HEIGHT | Height of the frames in the video stream. |
| cv.CAP_PROP_FPS | Frame rate. |
| cv.CAP_PROP_BRIGHTNESS | Brightness of the image (only for those cameras that support). |
| cv.CAP_PROP_CONTRAST | Contrast of the image (only for cameras). |
| cv.CAP_PROP_SATURATION | Saturation of the image (only for cameras). |
| cv.CAP_PROP_HUE | Hue of the image (only for cameras). |
| cv.CAP_PROP_GAIN | Gain of the image (only for those cameras that support). |
| cv.CAP_PROP_EXPOSURE | Exposure (only for those cameras that support). |
| cv.CAP_PROP_CONVERT_RGB | Boolean flags indicating whether images should be converted to RGB. |
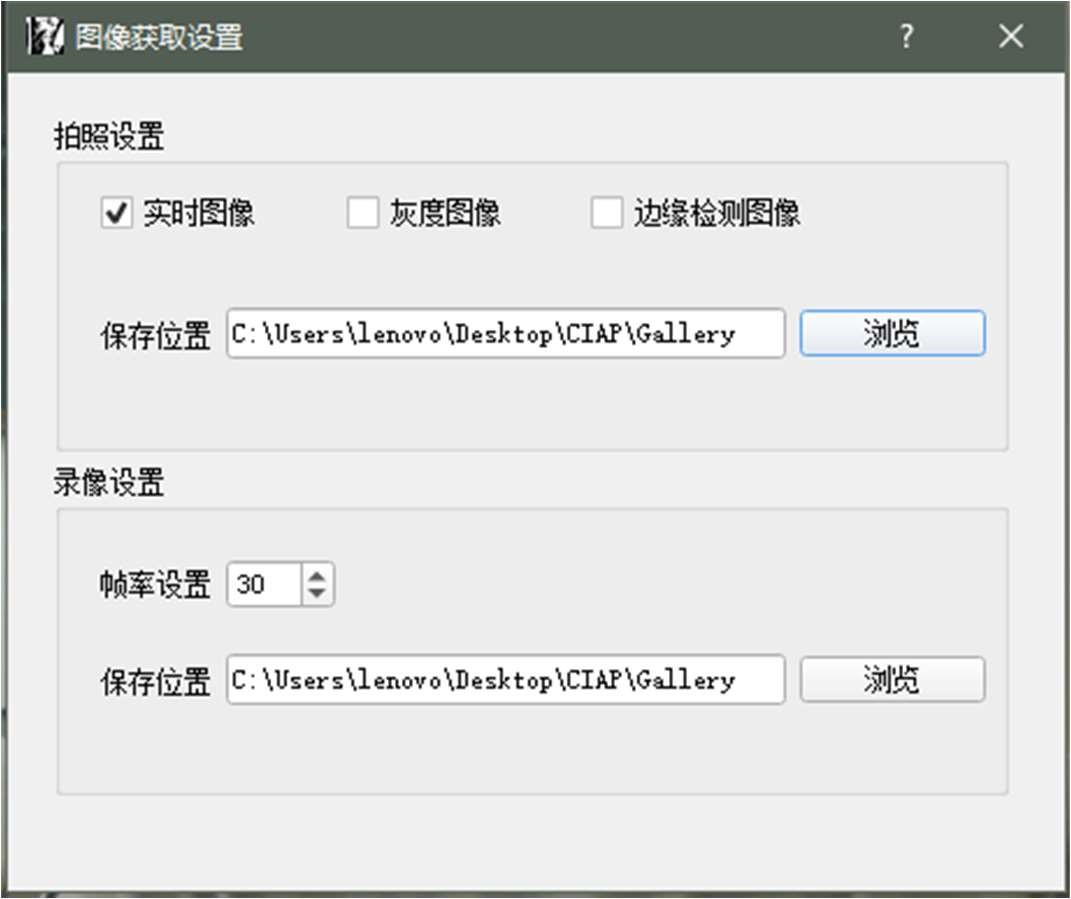
3.2.3 保存图像和视频
将从摄像头获取到的图像保存到本地相对来说就容易多了,再次仅给出所使用的 OpenCV 方法:
retval, buf = cv.imencode(ext, img[, params]) 具体的用法读者可以从 OpenCV 的官方文档中找到详尽的叙述。
保存视频则用到了一个新的类:
c++
cv2.VideoWriter([filename, fourcc, fps, frameSize[, isColor]])→<VideoWriter object> 使用所要保存的视频的文件名、格式、帧率、画幅、色彩的创建一个 VideoWrite 类后,再按照帧率读取摄像头图像存入即可。如 3.3.1 节末尾所述,在 Windows 系统下,其本质是集成了 FFMPEG 和 VFW 来实现时候视频操作,局限颇多,比如视频格式有限且不能收取音频等。但对于图像获取的需求来说已经足够了。
关于定时将读取当前帧并存取,用到的是 GUI 编程多线程中 QTimer 模块,同样的,将留待 3.5.4 节中再做详述。保存视频则用到了一个新的类:
cv2.VideoWriter([filename, fourcc, fps, frameSize[, isColor]]) → < VideoWriter object>
使用所要保存的视频的文件名、格式、帧率、画幅、色彩的创建一个 VideoWrite 类后,再按照帧率读取摄像头图像存入即可。如 3.3.1 节末尾所述,在 Windows 系统下,其本质是集成了 FFmpeg 和 VFW 来实现时候视频操作,局限颇多,比如视频格式有限且不能收取音频等。但对于图像获取的需求来说已经足够了。
关于定时将读取当前帧并存取,用到的是 GUI 编程多线程中 QTimer 模块,同样的,将留待 3.5.4 节中再做详述。
3.3 使用 OpenCV 进行图像处理
在第二章中,我们已经详细的讨论过了需要进行的图像处理及其原理,本节内容则是在实际编程过程中,如何使用 OpenCV 来便捷高效的完成这些操作[14]。其中,灰度化、直方图、边缘检测等相对基础的操作不会占用太多篇幅,重点将会放在第二部分人脸检测与识别上。
3.3.1 基本图像处理
色彩空间变换与灰度化
灰度化是彩色空间变换的一种。在 OpenCV 中,函数 cv2.cvtColor 可以将图像从一个颜色空间(通道的数值)转换到另一个,其用法如下: dst=cv.cvtColor(src, code[, dst[, dstCn]])
其返回值为转换后的图像,具体转换操作由参数 code 来制定,下表列出了此参数的部分取值。
表 3-2 色彩空间变换函数 cv.cvtColor 参数 code 取值
| Code | 解释 |
|---|---|
| cv.COLOR_BGR2BGRA | 在 RGB 或 BGR 图像中加入 alpha 通道 |
| cv.COLOR_RGB2BGRA cv.COLOR_RGB2BGR | 在 RGB 或 BGR 色彩空间之间转换 |
| cv.COLOR_BGR2RGB cv.COLOR_RGB2GRAY cv.COLOR_BGR2GRAY | 转换 RGB 或者 BGR 色彩空间为灰度空间 |
灰度化过程中用到了 cv2.COLOR_BGR2RGB、cv2.COLOR_BGR2GRAY,即将摄像头获取到的 BGR 彩色空间的帧图像转换至 OpenCV 图像处理常用的 RGB 空间后,再转换至灰度空间,完成灰度化。
灰度化是图像处理最基础的工作,接下来的边缘检测、直方图,甚至人脸检测与识别,都将在灰度化得到的灰度图像的基础上进行。
灰度直方图
直方图的计算是很简单的,无非是遍历图像的像素,统计每个灰度级的个数[11]。
在 OpenCV 中封装了直方图的计算函数 calcHist,为了更为通用该函数的参数有些复杂,其声明如下:
hist=cv.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
该函数能够同时计算多个图像,多个通道,不同灰度范围的灰度直方图。使用该函数可以得到一个数组列表,包含所求灰度级范围内不同灰度级的像素个数,进而可以有多种方式使用这些数据绘制直方图,我们将会在 3.5.5 节中再做讨论。(3)边缘检测
OpenCV 中常用于边缘检测的是 Canny 边缘检测法。Canny 算子首先使用高斯平滑滤波器卷积降噪;接着在 x 和 y 方向求一阶导数,按照 sobel 滤波器的步骤来操作,计算梯度幅值和方向,梯度方向一般取 0 度、45 度、90 度、135 度这 4 个可能的角度之中达到局部最大值的点组成边缘候选点;最后,Canny 算法最重要的一点就是运用滞后阈值来试图将独立边的候选像素拼装成轮廓,这需要两个阈值(高阈值和低阈值):若某一像素位置的幅值超过高阈值,该像素被保留为边缘像素;若某一像素位置的幅值小于低阈值,该像素被排除;若某一像素位置的幅值在两个阈值之间,该像素仅仅在连接到一个高于高阈值的像素时被保留[12]。
因此,Canny()函数通过如下格式调用:
edges = cv.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]]) 其中,threshold1 为第一个滞后性阈值,用于边缘连接;threshold2 为第二个滞后性阈值,用于控制强边缘的初始段;高低阈值比在 2:1 到 3:1 之间。
当高低阈值分别取不同值时,从下图可以看出边缘检测的不同效果如图 3-5 所示。



阈值为 10,25 b.阈值为 20,50 c.阈值为 100,250 图 3-5 阈值取不同值时边缘检测效果对比
3.3.2 人脸检测与识别
人脸检测与识别是数字图像处理中比较高级的玩法,且目前十分流行。从第二章可以看到,其原理是相当复杂的。不过,如果借用强大的计算机视觉库 OpenCV 的话,实现起来会容易的多。
人脸检测
OpenCV 的 CV 库提供的机器学习算法“Hear 分类器”可以用于人脸检测。这个物体检测方法巧妙的使用了 Boosting 算法。OpenCV 提供正面人脸检测器,它的检测效果非常好。
Haar 分类器是一个基于树的技术,它是首先由 Paul Viola 和 Michael Jones 设计的 boost 筛选式级联分类器,又称为 Viola-Jones 检测器。它使用 Haar 特征,更
准确的描述是类 Haar 的小波特征,该特征由矩形图像区域的加减组成[13]。
OpenCV 包含一系列预先训练好的物体识别文件,存储于 OpenCV 安装目录的如下路径:…\opencv\sources\data\haarcascades,其中本次毕业设计中使用的是正面人脸识别效果最好的模型文件”haarcascade_frontalface_alt2.xml”。
测试效果如图 3-6。
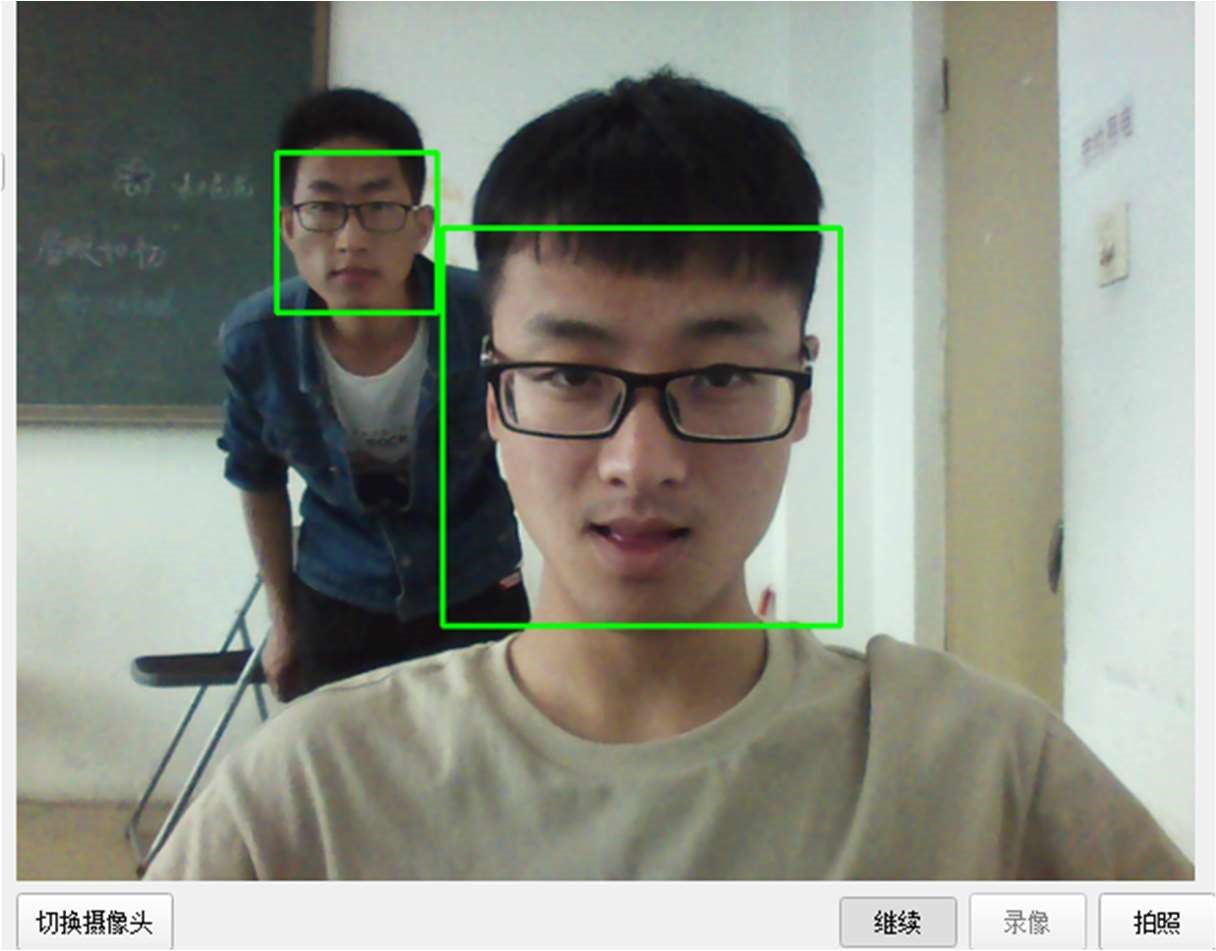
图 3-6 人脸检测
人脸识别
以上我们已经知道怎么加载和运行一个预先训练并存储在 XML 文件中的沉降分类器以实现人脸检测的功能。现在我们转到怎么训练分类器来进行人脸识别。
OpenCV 中有一个专门用于人脸识别的 face 模块。其中 FaceRecognizer 这个类目前包含三种人脸识别方法:基于 PCA 变换的人脸识别(EigenFaceRecognizer)、基于 Fisher 变换的人脸识别(FisherFaceRecognizer)、基于局部二值模式的人脸识别(LBPHFaceRecognizer)。
我们选用 LBPHFaceRecognizer 来完成人脸识别,其过程大致可以分为一下的3个步骤:
- 收集打算学习的物体数据集——在这里,指的就是大量的鄙人正面人脸图片了。如果希望分类器充分发挥作用,则需要收集很多高质量的数据(1000—10000 个正样本)。高质量指已经把所有不需要的变量从数据中除掉。利用上文人脸检测程序可以很方便的收集数据:只需将从摄像头图像中检测到的人脸区域裁剪下来,并经过相同规格的预处理存储到指定路径中即可。使用此方法收集得到的部分数据如图 3-7 所示。

图 3-7 收集的部分人脸图像
-
使用 cv2.face.LBPHFaceRecognizer 中的 train()函数来训练模型。需要将训练集中的图像创建为一个数据列表,并为每幅图像添加标签,要告知训练函数分别不同的人脸。根据数据量的大小和计算机性能的不同,训练时间往往会花费几分钟乃至于更长。因此为了避免每次识别时都进行训练,我们可以把训练得到的分类器用 save()函数保存成 XML 文件存储下来,下次用的时候直接用 laod()加载就行。
-
要使用训练的得到的模型来识别一幅人脸图像,只需要使用 prient()函数即可。该函数返回一个元祖格式值(标签,系数)。系数和算法有关,对于 LBPH 人脸识别算法,通常认为系数低于 50 为相对可靠,80-90 之间已经不可靠了,而高于 90 几乎可以确定识别正确率无穷小了。
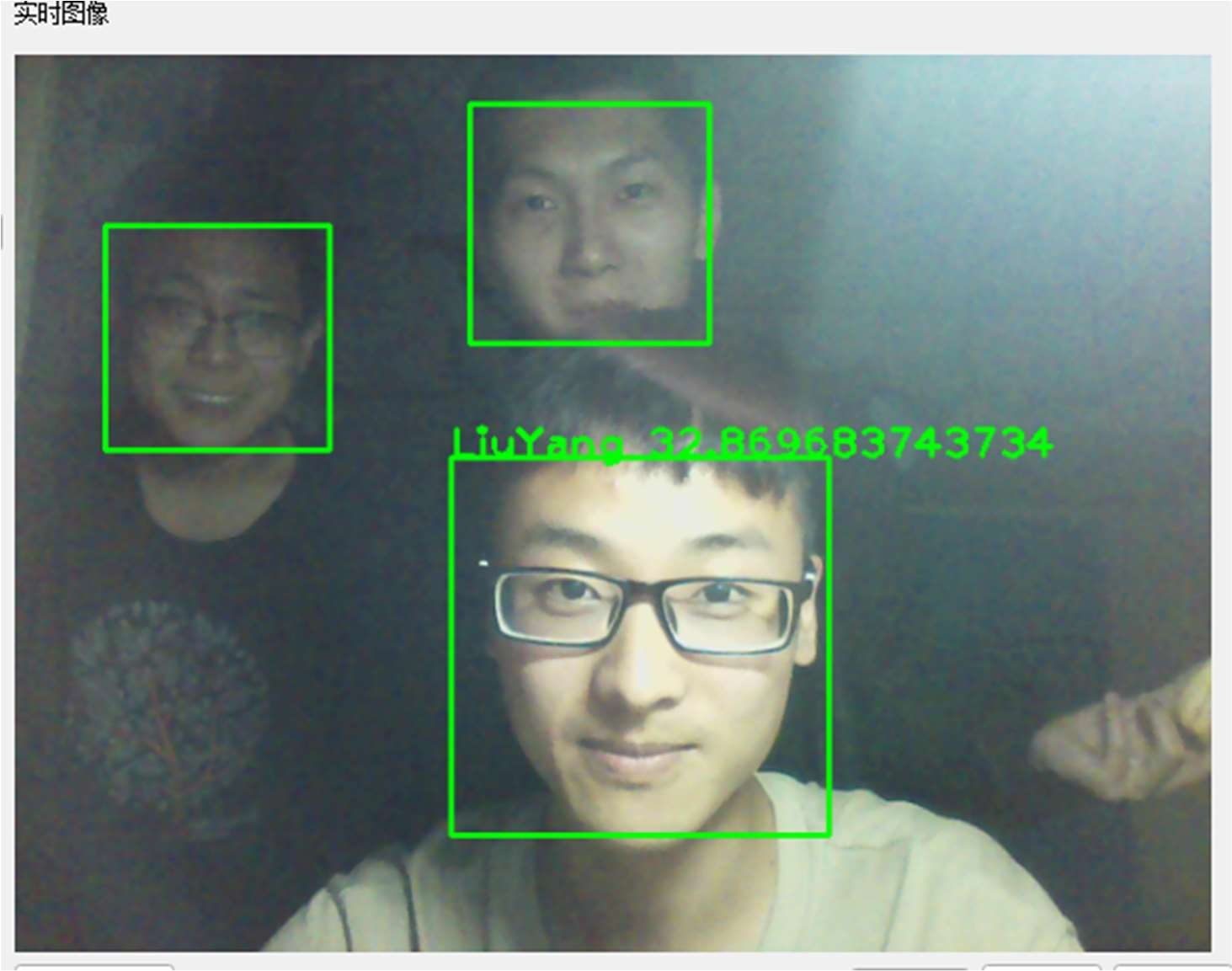
图 3-8 人脸识别
对于基于 PCA 变换和基于 Fisher 变换的人脸识别算法,其使用方法类似。以上本毕业设计就是利用 OpenCV 的 face 模块实现人脸识别的全部过程。
四、附录 Ⅰ 软件总体设计框图
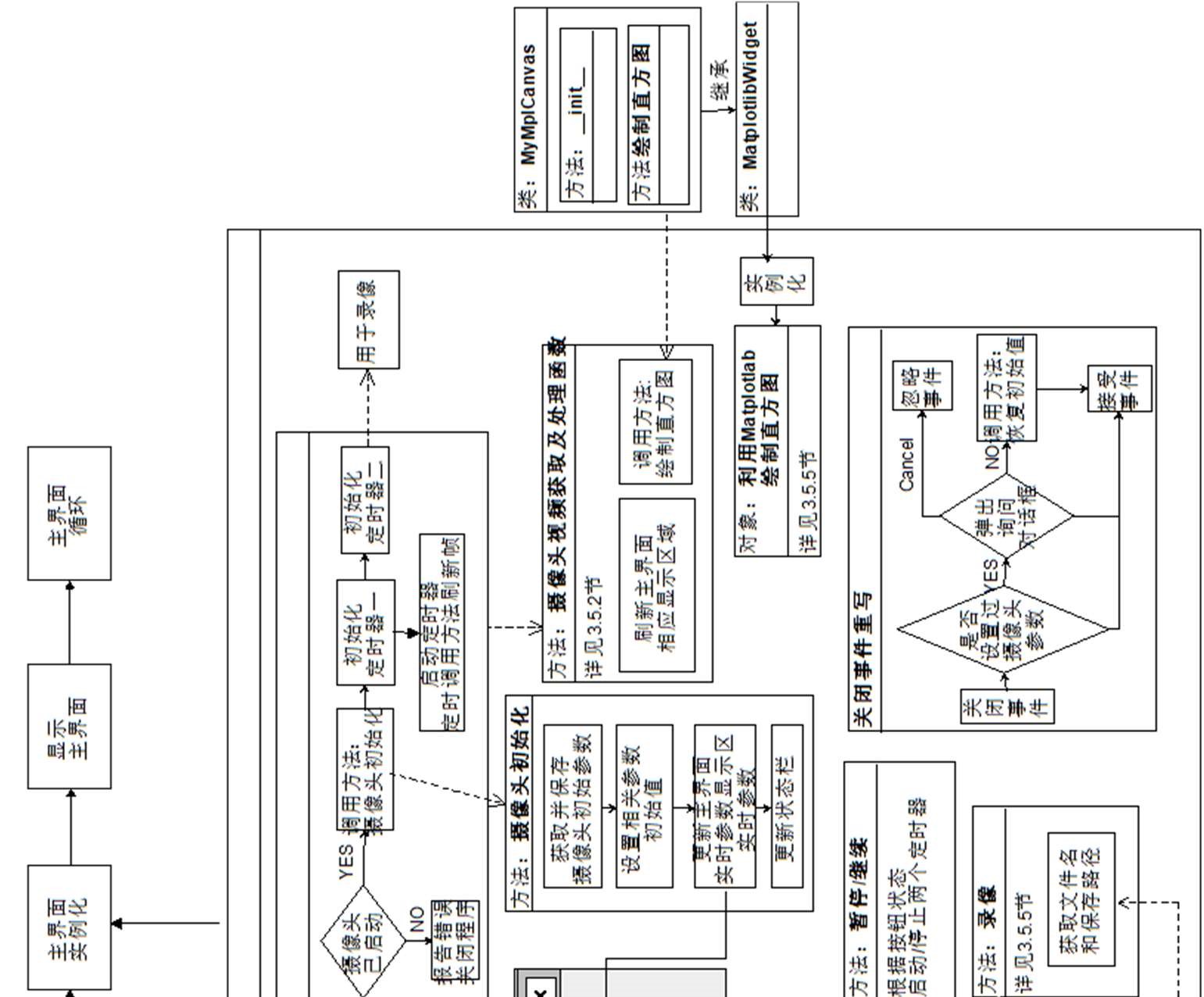

五、附录 Ⅱ 毕业设计软件效果
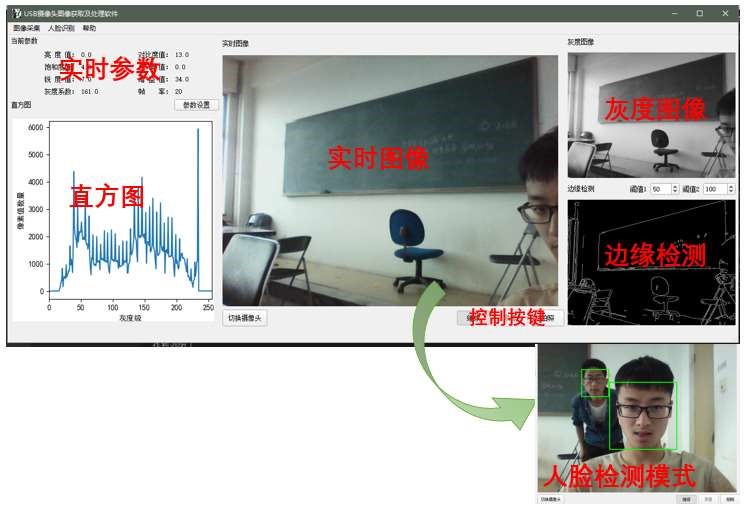
参考文献
- 基于CAD平台的建筑设计院电子图档管理系统的设计与实现(北京工业大学·伊宏光)
- 基于云平台的智能家居生态与安防系统设计与研究(贵州大学·王伟)
- 基于Web的图片管理系统的设计与实现(中国科学院大学(工程管理与信息技术学院)·郑晓君)
- 面向几何量测量的智能图像采集系统设计与实现(华中科技大学·李彧楚)
- 数字图像与矢量数据在空间数据库中的存取分析与应用(山东科技大学·姜永阐)
- 数字图像与矢量数据在空间数据库中的存取分析与应用(山东科技大学·姜永阐)
- 城市时景分享与管理系统设计与实现(北京交通大学·郭佳琦)
- 基于FC-SAN的图形文件存储管理系统(电子科技大学·杨易)
- 仿真支撑平台数据管理和网络通信的设计与实现(武汉理工大学·骆彬)
- 建筑设计院图档管理系统的设计与实现(吉林大学·时淮龙)
- 基于FPGA的图像预处理算法研究(沈阳航空航天大学·王贵宇)
- 基于J2EE的遥感影像数据库检索与发布系统的设计与实现(首都师范大学·陈於立)
- 基于.NET的动态图像生成与跟踪实验系统的设计与实现(中国海洋大学·梁纪袖)
- 基于XML/SVG的实时Web GIS的研究与实现(山东大学·孙涛)
- 基于Python的非结构化数据检索系统的设计与实现(南京邮电大学·董海兰)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码港湾 ,原文地址:https://bishedaima.com/yuanma/35833.html









