二分网络上的链路预测实验报告
实验内容
根据网络结构特征给出节点相似性度量指标;
基于相似性在二分网络上进行链路预测;
采用交叉验证的方法验证预测结果;
画出 ROC 曲线来度量预测方法的准确性。
分析与设计
参考:
注意: 本算法自己设计,因此可能存在很大缺陷。
将用户 ID,电影 ID 作为二分图的两类结点,同时打分作为边的权重。
相似度指标:使用对于和某个用户共同评分的电影的带权重余弦相似度作为指标。

预测方式: 取最为相似的前 SEARCH_NUM 个节点,取众数,如果众数 >=3 则喜爱,否则不喜爱。
详细实现
- 使用 Python 编写代码
- 使用 networkx 作为实现网络的包
- 使用 sklearn 计算一些统计数据,进行数据生成。
- 使用 matplotlib 绘制 ROC 曲线
- 使用 numpy 构建矩阵
主要的函数:
build_network(data):由于用户和电影的 ID 存在重合,因此在前面加上字母作为区别,然后构建二分图。

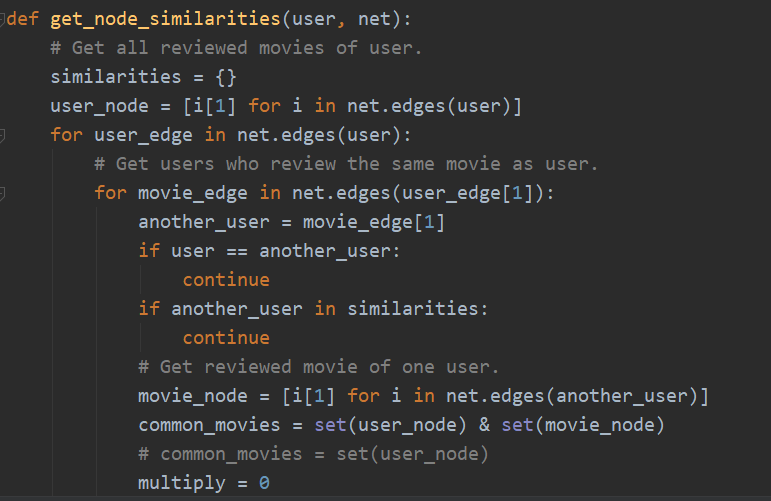
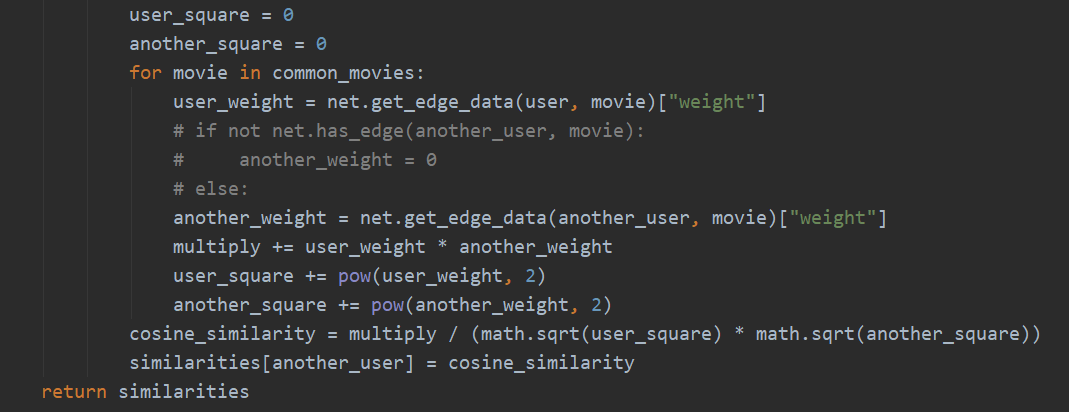
- get_node_similarities(user, net):用来计算对于某个用户在图中相似的节点,思路:寻找这个用户看过的所有电影,针对每个电影,寻找同样看过的用户,并记录下来。取两个用户共同看过的电影,并且计算相似度,得到相似度字典。
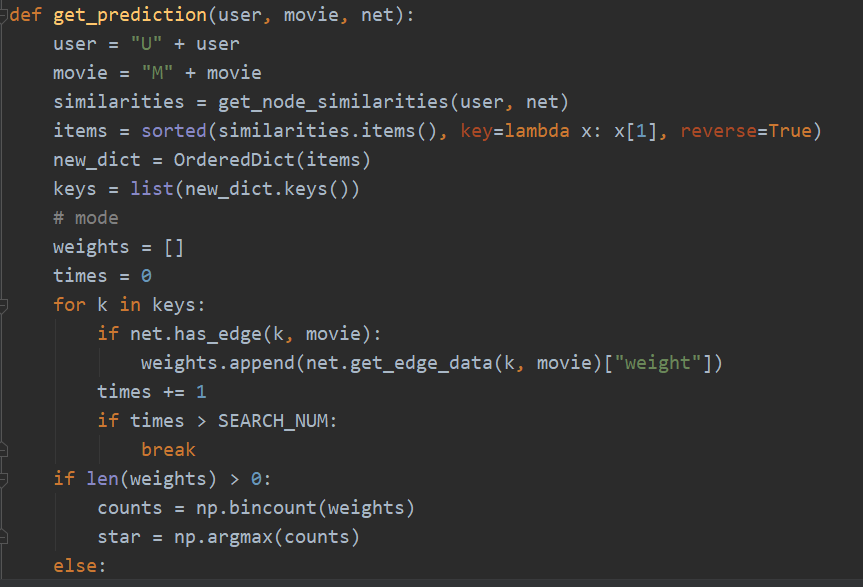
- get_prediction(user, movie, net):针对某个用户预测其对电影是否喜爱。思路:得到用户的相似度字典后,求最为相似并且评论过要求电影的前 SEARCH_NUM 名用户的评分众数作为返回结果。
实验结果
算法缺陷
仅仅使用很少测试样本,因为本算法搜索过慢,一定程度提高 SEARCH_NUM 有利于提高准确度。
准确度:
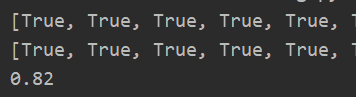
- ROC:

-
心得体会
本次算法均为自己设计并且寻找相似度。
设计中遇到了很多阻碍,包括对于链路分析概念不清楚,对于算法时间估计有问题。
本算法依旧存在很多缺陷,例如计算相似度时没有考虑共同评论电影的数量,搜索时过慢等等。
美国国会投票记录实验报告
实验内容
对于美国国会他投票记录数据,使用 Apriori 算法,支持度设为 30%,置信度为 90%,挖掘高置信度的规则。
分析与设计
参考:
利用第三包。
详细实现
实验结果
{0} -> {-1} (conf: 0.990, supp: 0.462, lift: 0.995, conv: 0.467)
{1} -> {-1} (conf: 0.998, supp: 0.995, lift: 1.002, conv: 1.995)
{-1} -> {1} (conf: 1.000, supp: 0.995, lift: 1.002, conv: 2298850.575)
{republican} -> {-1} (conf: 0.994, supp: 0.384, lift: 0.999, conv: 0.772)
{0} -> {1} (conf: 0.995, supp: 0.464, lift: 0.997, conv: 0.467)
{republican} -> {1} (conf: 0.994, supp: 0.384, lift: 0.996, conv: 0.386)
{democrat} -> {-1} (conf: 0.996, supp: 0.611, lift: 1.001, conv: 1.228)
{democrat} -> {1} (conf: 1.000, supp: 0.614, lift: 1.002, conv: 2298850.575)
{0, 1} -> {-1} (conf: 0.995, supp: 0.462, lift: 1.000, conv: 0.929)
{-1, 0} -> {1} (conf: 1.000, supp: 0.462, lift: 1.002, conv: 2298850.575)
{0} -> {-1, 1} (conf: 0.990, supp: 0.462, lift: 0.995, conv: 0.467)
{1, republican} -> {-1} (conf: 1.000, supp: 0.384, lift: 1.005, conv: 4597701.149)
{-1, republican} -> {1} (conf: 1.000, supp: 0.384, lift: 1.002, conv: 2298850.575)
{republican} -> {-1, 1} (conf: 0.994, supp: 0.384, lift: 0.999, conv: 0.772)
{0, democrat} -> {-1} (conf: 0.993, supp: 0.326, lift: 0.998, conv: 0.657)
{1, democrat} -> {-1} (conf: 0.996, supp: 0.611, lift: 1.001, conv: 1.228)
{-1, democrat} -> {1} (conf: 1.000, supp: 0.611, lift: 1.002, conv: 2298850.575)
{democrat} -> {-1, 1} (conf: 0.996, supp: 0.611, lift: 1.001, conv: 1.228)
{0, democrat} -> {1} (conf: 1.000, supp: 0.329, lift: 1.002, conv: 2298850.575)
{0, 1, democrat} -> {-1} (conf: 0.993, supp: 0.326, lift: 0.998, conv: 0.657)
{-1, 0, democrat} -> {1} (conf: 1.000, supp: 0.326, lift: 1.002, conv: 2298850.575)
{0, democrat} -> {-1, 1} (conf: 0.993, supp: 0.326, lift: 0.998, conv: 0.657)
心得体会
使用了包,因此实验没有什么难度。之后或许会考虑自己实现。
利用层次聚类思想实现一个社区发现算法,在 karate 数据集上进行检测。
分析与设计
参考: Newman M E J, Girvan M. Finding and evaluating community structure in networks
算法采用 Girvan-Newman 算法,利用模块度 Q 作为寻找社区数量的依据。
Girvan-Newman 算法的基本流程如下:
计算网络中所有边的边介数;
找到边介数最高的边并将它从网络中移除;
重复步骤 2,直到每个节点成为一个独立的社区为止,即网络中没有边存在。

详细实现
使用 Python 编写代码
使用 networkx 作为实现网络的包
使用 matplotlib 绘制 Q 的变化
使用 gephi 查看图
构建 GN 类,其中有两个主要方法的划分方法:
GN.run(self):以 Q 最大作为划分依据
GN.run_n(self, n):当划分为 n 个时,停止划分
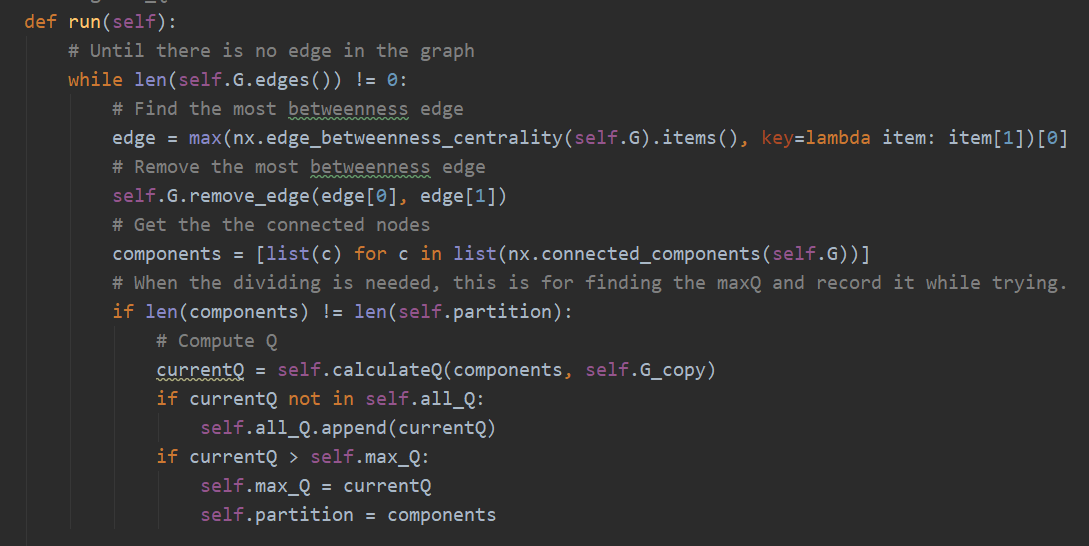
以 run 为例:一直去除介数最大的边,同时计算划分后的图的 Q 是否最大,如果最大,则以此图作为新的结果,否则继续划分。
GN.add_group(self):将原图的拷贝按照划分后的节点进行标记,方便之后的查看
GN.draw_Q(self):画出 Q 的变化趋势
GN. calculateQ(partition, G):计算目前的 Q
其余可参见代码:
结构如下:
Main.py 程序实现
/data:
karate.gml:原始数据
out.gml:依据 Q 最大划分结果
two_parts.gml:依据两个社区划分结果
实验结果
依据真实情况,即两个社区划分:
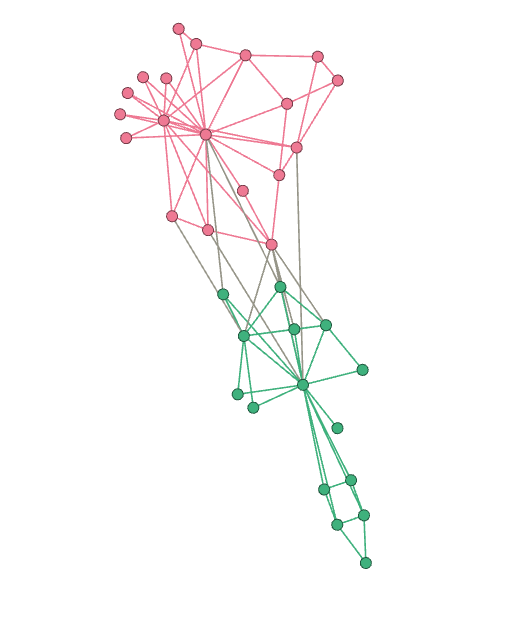
依据 Q 最大划分:
Q 的变化如下:

最终结果被划分为五个社区:

参考文献
- 复杂网络的链路预测算法研究(贵州大学·张希康)
- 基于sFlow的网络链路流量采集与分析(武汉理工大学·范亚国)
- 基于图神经网络的多层网络链接预测研究(兰州大学·韩雨彤)
- 基于路径相似性的复杂网络链路预测研究(华东交通大学·楼俊涛)
- 图流中针对节点的链路预测算法研究(华中科技大学·肖洋)
- 基于节点重要度的链路预测算法研究(西南大学·杜珞民)
- 基于节点行为特征的时序链路预测方法研究(西南大学·吴家云)
- 基于群体检测技术的推荐系统研究(南京邮电大学·蔡小雨)
- 基于信息融合图嵌入的链路预测方法研究(内蒙古科技大学·倪祥明)
- 基于网络节点属性的深度链路预测及推荐算法的研究(深圳大学·)
- 基于节点相似性的符号网络链接预测研究及应用(东北石油大学·扈庆翠)
- 以太坊智能合约的自动化漏洞检测方法研究(北京交通大学·宋晶晶)
- 基于节点行为特征的时序链路预测方法研究(西南大学·吴家云)
- 社交网络中基于链路预测的推荐系统研究(江苏大学·郭军超)
- 面向P4数据平面的SDN网络虚拟化系统设计与实现(东南大学·张小民)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码驿站 ,原文地址:https://bishedaima.com/yuanma/35762.html