
面向豆瓣电影的知识图谱的设计与实现
摘要:
本文介绍了 python 面向豆瓣电影的知识图谱的设计与实现。该设计是一个集爬虫、GUI、多线程、知识图谱、NLP 基础文本分析的多功能应用。本文介绍了用面向对象软件工程方法对其进行分析、设计、编码、测试的过程,以及对设计的评估。并提供了相关文档及部分源代码。
关键字:
软件工程,面向对象,爬虫,知识图谱,文本分析
个人的工作及体会在“六.小结”部分
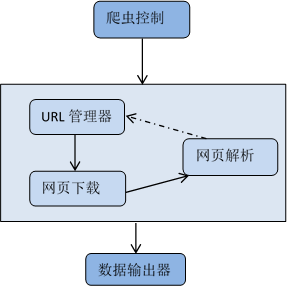
项目概述
该软件技术课程设计目的在于将所学的专业技能转化为实践的能力。学会快速获取和处理海量的数据并从中得到有价值的信息是信息时代的一项重要技能。通过完成本课程设计,将加深对网络爬虫、数据挖掘及软件编程技术的理解,同时锻炼其软件编程与解决实际问题的能力。
本课设通过爬取豆瓣 top250 电影排行榜的信息,利用 neo4j 实现豆瓣 top250 电影的信息可视化,同时自行拓展完成一些附加功能。
考虑到脚本的实时操作性,本项目主要采用面向对象的思想并且采用多线程并发的方法进行程序设计,以满足以上功能的实时性与并发性,从而有较流畅的 GUI 可视化界面操作。
项目设计
需求分析
第一,从用户的角度来看,此项目需要提供一个可视化的图形用户界面以方便用户根据界面按钮与说明书文档进行操作,并且该程序应该可以根据用户的需求从互联网上进行搜集与爬取,将相关内容最终返回到图形用户界面,即完成程序与用户的交互;
第二,从爬虫开发者角度考虑,程序应该可以进行网页爬虫和资源下载,这里使用 request 库可以实现,但也要从开发者的角度考虑频繁访问页面时的代理池的问题;另一方面,由于爬取数据较多,应该可以实现多线程或者多进程并发进行,达到高效率;
第三, 从数据库开发角度考虑,数据库应该可以在导入数据后进行数据节点与关系的建立;
第四,爬取的数据除了具有关系之外,也可以对文本进行一定的分析,比如词频统计、情感分析等 NLP 的基础内容,对文本数据做出数据分析并且图形显示,实现可视化。
下面从用户的角度具体分析需求:
程序启动后有可视化的 GUI 界面,可以支持用户的登录与注册操作;
登录完成时可选择记住用户名/记住密码/自动登录等功能
登录完成后可以进入主窗口,选择“加载豆瓣电影信息”可以实现豆瓣 top250 的爬取
爬取完毕后可点击“导出数据构建知识图谱”进行本地数据库知识图谱构建(知识图谱需提前打开)
执行词频统计按钮可实现多种不同选项的词频统计分析
执行情感分析按钮可实现对需要进行情感分析的电影的热门评论的情感分析与结果可视化
执行返回登录界面按钮可退出主窗口重新登录
执行退出按钮可安全退出程序
以上便是此项目的所有需求,基本实现界面的可交互功能,满足用户的易操作性,并且符合当前 GUI 的主流设计模式,可行,方便,可视化程度高。
设计
面向对象设计将现实世界的 OOA 模型转换为可以用软件实现的 OOD 模型。
设计分为两个阶段:总体设计阶段与详细设计阶段。在总体设计阶段,决定如何解决需求问题,确定解决问题的策略以及目标系统需要的程序,并设计软件的结构。在详细设计阶段,决定怎样具体地实现系统,并设计出程序的详细规格说明。
在总体设计阶段,首先确定了环境,即操作系统以及编译器。这样,就可以以需求分析说明书为依据,针对环境进行有针对性的设计。
环境说明如下:
使用环境:
Windows 操作系统:
此操作系统界面友好,且有较成熟的文件查询,传递等机制可供利用。
开发环境:
Python3.8 发行版 anaconda3
c++
Neo4j-community-4.3.8
编写代码环境:
c++
Pycharm 2021.2.2
IDEA 开发工具,可以实现 Python 的自动补全,纠错,解释直至运行,为 Python 代码的编写和录入提供方便。
概要设计:
根据需求分析,将系统划分成 3 个子模块:
电影信息爬虫模块
知识图谱构建模块
附加功能模块
然后,依据 “类——责任——协作者”模型,在各子系统中确定出类。
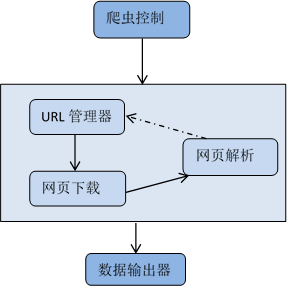
电影信息爬虫模块:
根据广度优先搜索的要求,将该模块分为两个类,一是爬取所有电影的 url 的 PAThread 类,二是通过 url 爬取详细电影数据的 WordThread 类,对数据进行解析。
知识图谱构建模块:
主要包括 neo4j_test.py 模块,定义了相关结点与关系的方法,实现本
地知识图谱数据库构建
环境配置:
下载 neo4j-community 并安装;
在安装好的文件夹里找到 bin 文件夹并打开;
打开 bin 文件,cmd 终端打开;
打开终端后,输入./neo4j console 即可启动连接,打开得到的网址:
打开后,即可看到 neo4j 界面:

注:用户连接前需在代码 neo4j_test.py 中修改登录用户名及密码
c++
graph = Graph('http://localhost:7474', auth=("neo4j", "密码"))
附加功能模块:
包括 GUI 界面(登录窗口 LoginPage()、注册窗口 RegisterPage()、主窗口 MainPage()、词频统计窗口 WordFreq()、情感分析窗口 Motion())、词频统计模块(针对电影的年份、时长、得分、地区、类型等的统计)、情感分析模块(热门评论情感分析);PAThread 与 WordThread 爬取继承多线程 QThread 类;代理池 get_proxy()函数
具体要求如下:
可视化 GUI 界面
实现 GUI 图形用户界面的构建,对爬虫和 neo4j 数据库操作的部分功能进行封装搭建,在 GUI 界面上为二者提供接口(例如利用 GUI 界面按钮来控制爬虫的开始与中断,知识图谱的构建展示以及关键词检索等功能),同时也为其他附加功能提供接口,为用户提供友好的可视化操作界面。
代理池数据库
搭建代理池主要分为存储、获取、检测、接口四个模块。此处由于现有免费代理较差,采用芝麻代理 API 函数进行构建代理池。
多线程
在爬取许多网页或者爬取图片的时候,采用单线程方式下载访问会导致程序运行缓慢。多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。采用多个线程同步爬取多个网页。尤其是结合 GUI 的 QThread 多线程。
词频统计
词频统计模块分为读取、分词统计、写入三个模块,是自然语言处理的基础。可以利用现有的分词工具包(例如 jieba、等)对想要词频统计的信息进行分词,先将文本进行分词和词性标注,实现关键词提取。
情感分析
情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。针对电影的情感分析,是通过对电影评论的文本进行分词及词性标注,将电影的评论情感分为积极的,消极的或者中性。
设计主流程图:

详细设计:
电影信息爬虫模块:
爬取的两个类均是继承 QThread 类,可使用 start()方法进行多线程执行
PAThread 类:
```python
线程:广度爬取TOP250的电影详情信息页url
class PAThread(QThread) ```
模块流程图:
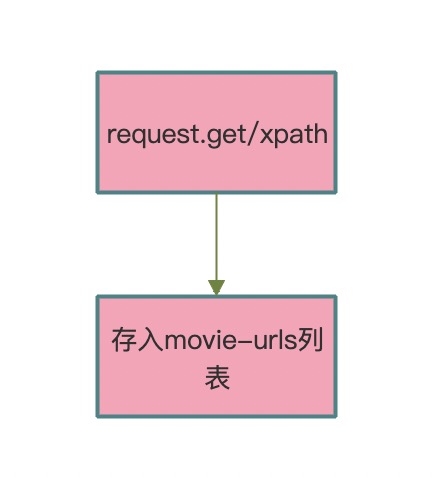
c++
resp = requests.get(url=self.url, headers=headers, proxies=proxies)
html = etree.HTML(resp.text)
lis = html.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li')
通过获得的 url,利用封装好的 run 函数。利用 xpath 解析 HTML。同时获取所以电影的 url 做好类型转换。
c++
movie_urls.append(movie_url)
最后添加到 movie_urls 列表中
Package 解释:
1.1 requests 是一个简单的请求库,其中的 get 方法可以像指定服务器发送 get 请求
1.2 headers 参数。作为请求的请求头。
proxies 参数。作为用户代理,访问服务器会以该代理的 ip 访问服务器,可掩盖本机 ip.
1.2.1 etree.HTML 函数
etree.HTML()可以用来解析字符串格式的 HTML 文档对象,将传进去的字符串转变成_Element 对象。作为_Element 对象,可以方便的使用 getparent()、remove()、xpath()等方法
html.xpath 函数
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
在爬虫中主要用于对 HTML 进行解析
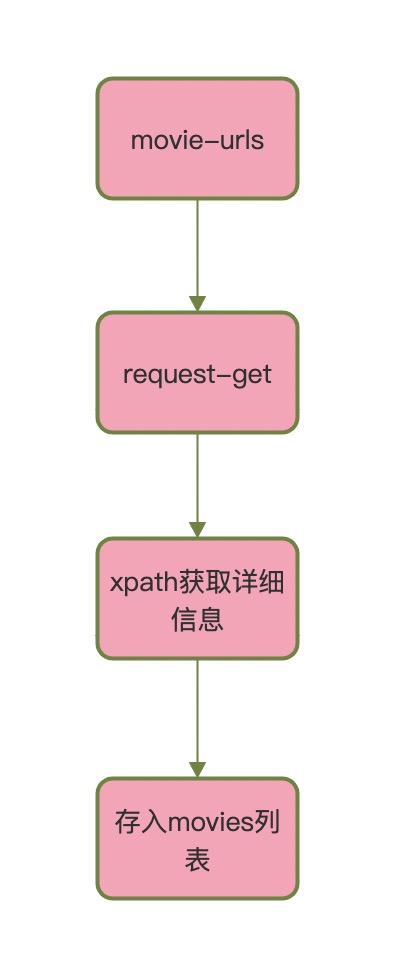
WorkThread 类:
模块流程图:
```python
线程:解析每个电影的url,将详细数据存到缓存列表
class WorkThread(QThread): movie = [] if resp.status_code == 200: soup = BeautifulSoup(resp.text, features='lxml') tree = fromstring(resp.text) title_tmp = ''.join(tree.xpath('//*[@id="content"]/h1/span[1]/text()'))
分割中文与英文名称
title_tmp = re.split(' ', title_tmp, 1)
movie.append(title_tmp[0])
movie.append(title_tmp[1])
movie.append(''.join(tree.xpath('//*[@id="content"]/div[1]/span[1]/text()')))
movie.append(re.search('(?<=(<span class="c9a_de9c_9c64c24 year">\()).*(?=(\)</span>))', resp.text).group())
director_tmp = tree.xpath('//*[@id="info"]/span[1]')[0].text_content()
director_tmp = director_tmp.strip('导演: ')
movie.append(director_tmp)
actor_tmp = tree.xpath('//*[@id="info"]/span[3]')[0].text_content()
actor_tmp = actor_tmp.strip('主演: ')
movie.append(actor_tmp)
```
此类为对每个电影进行详细数据的爬取,需要 get_proxy()函数进行获取 ip 代理,防止被封禁。该类利用全局变量对爬取到的数据进行存储,是为了防止多进程的数据混乱现象。最后将一个电影的所有数据存储到 movie 列表中,再将所有电影信息存储到 movies 中,方便后续操作。
代码与 package 解释:
resp.status_code 意义为网页状态码。Status_code=200 意味着服务器正常响应,404 代表这个页面没有找到。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器。最主要的功能是从网页抓取数据。Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。
fromstring 函数。fromstring() 可以在解析 XML 格式时,将字符串转换为 Element 对象,解析树的根节点。在 python 中,对返回的 page.txt 做 fromstring()处理,可以方便进行后续的 xpath 定位。
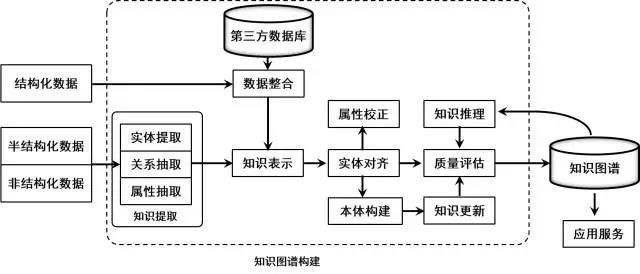
知识图谱构建模块
图数据库简介:
Neo4j 是一个高性能的 NOSQL 图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的 Java 持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j 也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下,而不是严格、静态的表中。

如图所示:在一个图中包含两种基本的数据类型:Nodes(节点)和 Relationships(关系)。Nodes 和 Relationships 包含 key/value 形式的属性。Nodes 通过 Relationships 所定义的关系相连起来,形成关系型网络结构。这种结果就是图形数据结构。
详细代码设计:
模块导入:
python
from py2neo import Node, Relationship, Graph, NodeMatcher, RelationshipMatcher
import csv
图数据库操作函数:
CreateNode 函数
python
def CreateNode(m_graph, m_label, m_attrs):
此函数的作用是在图数据库中创建节点。m_graph 是要构建的图数据库,m_label 是该节点所在的标签(电影、导演、演员、类型等),m_attrs 是该节点的属性(在本数据库中只设置了名称)
c++
m_n = '_.name=' + "\'" + m_attrs['name'] + "\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
if re_value is None:
m_node = Node(m_label, **m_attrs)
= graph.create(m_node)
return n
return None
创建之前先对该属性(名称)的节点进行匹配,如果该节点之前不存在,则创建此节点;如果节点之前已存在,则不再进行创建。调用此函数后,即可在 m_label 标签下创建一个之前不存在的节点 m_attrs。
MatchNode 函数
python
def MatchNode(m_graph, m_label, m_attrs):
此函数运用 matcher.match 方法对节点进行匹配:
c++
re_value = matcher.match(m_label).where(m_n).first()
此函数的作用是判断一个节点是否存在,为后面创建节点之间的关系做准备。
CreateRelationship 函数
python
def CreateRelationship(m_graph, m_label1, m_attrs1, m_label2, m_attrs2, m_r_name):
此函数的作用是创建节点之间的关系:
m_graph 是所在图数据库,m_label1 是第一个节点所在的标签,m_attrs1 是第一个节点的属性(名称),m_label2 是第二个节点所在的标签,m_attrs2 是第二个节点所在的属性(名称),m_r_name 是两个节点之间的关系。
创建关系之前先判断节点是否存在:
c++
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
revalue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or revalue2 is None:
return False
如果节点存在,没有返回,则创建关系:
c++
m_r = Relationship(reValue1, m_r_name, revalue2)
= graph.create(m_r)
return n
调用此函数后,即可创建两个标签下两个不同节点之间的关系。
知识图谱构建模块:通过调用该 package 实现知识图谱的构建
CreateGraph 函数:
构建图数据库的主体功能就是在此函数中,构建流程如下:

其中,获取电影信息时,由于国家、演员、类型等信息一个电影可能包含多个,于是采用切片逐一取出。创建节点时调用了 CreateNode 函数,创建关系时调用了 CreateRelationship 函数。
附加功能模块:
GUI 界面登录界面:
```python
GUI界面 登录窗口
```
初始化:
python
class LoginPage(QWidget):
'''用户注册、登录窗口'''
def __init__(self):
初始化界面,界面布局
方法:
```python
检查文本输入框的方法
def check_input(self):
当用户名及密码输入框均有内容时,设置登录按钮为可点击状态,否则,不可点击
登录方法
def login(self):
```
此处主要利用序列化反序列数据存储方式.pkl 实现模拟数据库存储用户信息
```python
检查用户状态方法,登录的时候查看复选框是否保存数据(是否保存用户名或保存密码或自动登录)
def check_login_state(self):
注册方法,点击注册按钮会进入注册界面
def register(self):
注册成功,登录界面载入刚刚注册的数据
def successful_func(self, data):
```
注册成功提示进入登录界面
```python
以下为用户信息保存方法
记住用户名到tmp_data
def remember_name_func(self):
记住用户名和密码到tmp_data
def remember_password_func(self):
自动登录,保存数据,仅保存上一次的登录用户
def auto_login_func(self):
页面登录信息初始化,包括自动登录等
def login_init(self):
```
GUI 注册对话框界面
```python
GUI界面 注册对话窗口 初始化
class RegisterPage(QDialog):
自定义注册成功信号,传递列表信息
successful_signal = pyqtSignal(list)
def __init__(self):
单行文本输入框初始化方法、槽函数绑定、正则校验等
def line_init(self):
按钮初始化方法
def pushbutton_init(self):
检查输入方法,只有在三个文本输入框都有文字时,注册按钮才为可点击状态
def check_input(self):
取消注册方法
如果用户在注册界面输入了数据,提示用户是否确认取消注册,如未输入数据则直接退出。
def cancel_func(self):
检查用户输入密码合法性方法
def check_password(self):
用户注册方法
def register_func(self):
先获取注册用户ID,检查用户ID是否存在
用户性别信息收集,男为1,女为2,未选择为0
def gender_data(self):
```
GUI 主窗口界面
```c++
GUI界面 登录后主界面窗口 初始化
class MainPage(QWidget): def init (self):
爬虫方法,首先爬取movie_urls,再多线程爬取详细信息
def pa(self):
global movie_urls
global proxies
get_proxy()
for i in range(10):
url = f'https://movie.douban.com/top250?start={i*25}&filter='
PAThread(url).run()
print(f'第{i}页url爬取完毕~')
sleep(0.1)
多线程爬取详细信息
self.work_0 = WorkThread(movie_urls[0])
self.work_0.start()
```
…
```c++
导出数据与构建知识图谱方法,点击后执行
def get_excel_map(self): print('正在导出数据') to_excel() print('导出完成!正在构建知识图谱...')
构建知识图谱
sleep(2)
data_xls = pd.read_excel('movie_data.xls', index_col=0)
data_xls.to_csv('movie_data.csv', encoding='utf-8')
sleep(1)
清空数据库 match (n) detach delete n
CreateGraph()
print('知识图谱构建完成!')
点击获取词频统计按钮打开新界面方法
def get_word_freq(self):
self.wordfreq_page = WordFreq()
self.wordfreq_page.show()
点击情感分析按钮打开新界面方法
def get_motion(self):
self.motion_page = Motion()
self.motion_page.show()
返回登录界面方法
def get_back(self):
self.close()
window.show()
```
GUI 词频统计窗口 WordFreq()
模块流程图:

```python
GUI界面 获取词频统计界面窗口 初始化 布局
class WordFreq(QWidget): def init (self):
方法frq1 对年份进行词频统计 此处调用collections.Counter进行词频统计,并用matplotlib进行绘图
def frq1(self):
读取年份数据
workbook = xlrd.open_workbook('./movie_data.xls')
sheet1 = workbook.sheet_by_index(0)
year = sheet1.col_values(3)[1:]
词频统计
word_counts = dict(collections.Counter(year))
作图
```
以下同理 frq2 方法对评分词频统计 frq3 方法对时长词频统计
```python def frq2(self):
读取评分数据
def frq3(self):
读取时长数据
def frq4(self):
获取电影类型字符串
MyCloud(string_data)
def frq5(self):
获取电影国家地区字符串
MyCloud(string_data)
```
其中 frq4、frq5 调用 MyCloud()函数进行词频统计词云图绘制
```python
词频统计及词云图函数,需传入待处理文本字符串
def MyCloud(string_data):
文本预处理
pattern = re.compile('/|\t| |n') # 正则匹配
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
文本分词
seg_list = jieba.cut(string_data, cut_all=False)
词频统计
word_counts = collections.Counter(seg_list) # 对分词做词频统计
绘制词云图
mask = np.array(Image.open('./img/python_logo.jpg'))
wc = wordcloud.WordCloud(
font_path='C:\Windows\Fonts\STXINGKA.TTF', # 设置字体
mask=mask, # 设置背景图片
max_words=200, # 最多显示字数
max_font_size=250 # 字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云图
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云图颜色设置为背景图方案
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show()
```
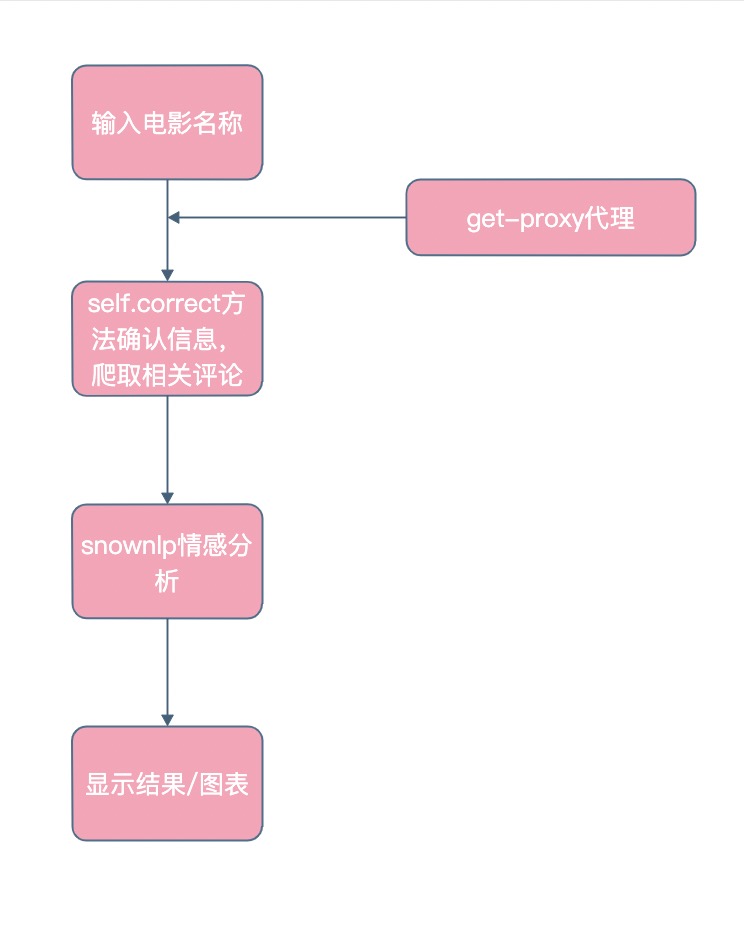
GUI 情感分析窗口 Motion()
模块流程图:
```c++
GUI界面 获取情感分析界面窗口 初始化 布局
class Motion(QWidget): def init (self):
搜索确认方法 并爬取评论10条 进行snownlp情感分析得分
def correct(self):
获取输入的电影名称
shuru = self.shuru.text()
global movie_urls
根据该电影排名从movie_urls中获取url,爬取热门评论10条
获取输入电影名称的url并爬虫
workbook = xlrd.open_workbook('./movie_data.xls')
sheet1 = workbook.sheet_by_index(0)
titles = sheet1.col_values(0)[1:]
爬取热门评论
global proxies
get_proxy()
resp = requests.get(url=url, headers=headers, proxies=proxies)
new_comments = []
new_comments.append(''.join(tree.xpath('//*[@id="comments"]/div[1]/div[2]/p/span/text()')))
将电影信息与评论打印输出再文本框中,并输出情感分析评分
motion_score = []
for i in new_comments:
= SnowNLP(i)
print(a1.words) # 分词
print(a1.tags) # 词性标注
print(a1.sentences) # 断句
= a1.sentiments # 获取得分
motion_score.append(a2)
作出十条评分的情感得分图
作图
plt.figure(figsize=(20, 8), dpi=80)
plt.show()
```
代理函数 get_proxy()
```c++
芝麻代理获取 对芝麻代理的API进行爬取 通过全局变量proxies传递给全局爬虫函数使用,防止IP封禁
def get_proxy(): global proxies print('开始获取代理IP地址...') headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36' } zhima_url = 'http://webapi.http.zhimacangku.com/getip?num=1&type=3&pro=&city=0&yys=0&port=11&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions=' proxy_ip = requests.get(url=zhima_url, headers=headers) tmp = proxy_ip.text.replace('\r', '').replace('\n', '') proxies = {'https': 'http://' + tmp} main
启动程序,创造pyqt实例
if __name__ == '__main__':
page = QApplication(sys.argv)
实例登录界面
window = LoginPage()
if not window.auto_login.isChecked():
window.show()
sys.exit(page.exec())
```
编码
这个阶段的关键任务是写出正确的容易理解、容易维护的程序模块。并且仔细测试编写出的每一个模块。
在本阶段,我们以详细设计文档为依据,充分利用操作系统和编译器提供的便利进行编码。大量的类复用了编译器提供的控件,节省了编码时间。而对于控制类和起基础作用的几个位于底层的类,严格按照详细说明书的说明进行编码。
各单元编码结束后,进行单元测试。因为人手有限,我们采用的方法是程序员互相交换代码进行测试,要求做到代码覆盖。
单元测试结束后,进行系统组装,得到了一个完整的脚本程序,douban.py,其中知识图谱构建通过调用 neo4j_test.py 进行,详细见附录源码说明文档。
测试
这个阶段的关键任务是通过各种类型的测试以及相应的调试,使软件大道预定的要求。最基本的测试是集成测试和验收测试。所谓集成测试是根据设计的软件结构,把经过单元测试检验的模块按照某种选定的策略装配起来,在装配过程中对程序进行必要的测试。所谓验收测试则是按照规格说明书的规定,由用户目标系统进行验收。
下面主要针对设计的 3 个子模块并参考附件功能进行测试并对整个项目做最终测试
爬虫测试:
点击“加载豆瓣电影信息”,开始爬虫

Console 中显示相应的广度 movie_urls 信息,爬取成功,符合预期:

随后进行多线程 WorkThread 类的详细信息爬取:
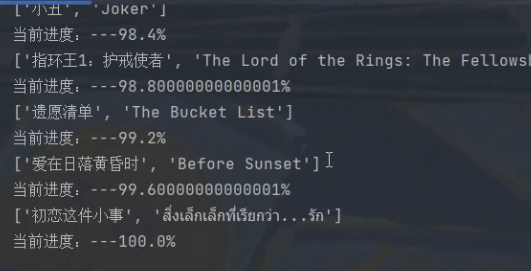
此时显示进度爬取 100%,爬取完成,用时 5s 以内,相比于单线程(几分钟)效率更高。
知识图谱测试:
点击“导出数据构建知识图谱”,开始导出数据
此时将在目录下生成电影信息相应的 xls 与 CSV 文件
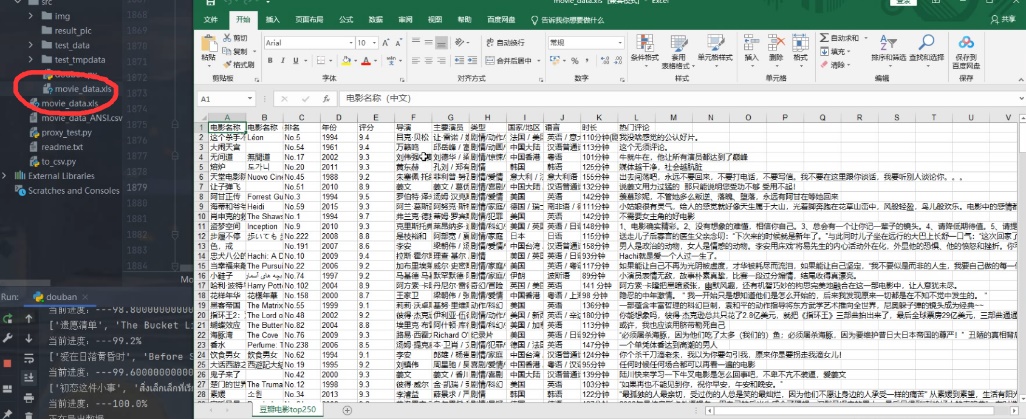
- 可以看出信息导出完成
- 知识图谱:
- 创建之前,图数据库中没有节点:
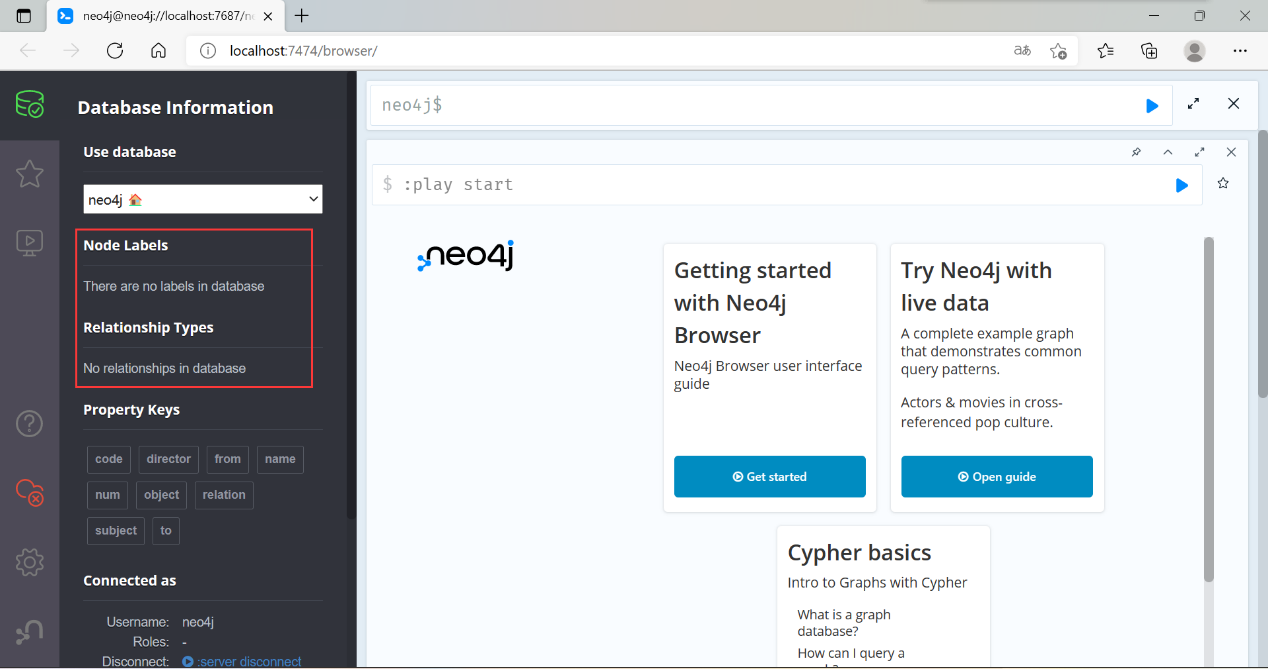
点击“导出数据构建知识图谱”按钮,得到创建之后的图数据库:
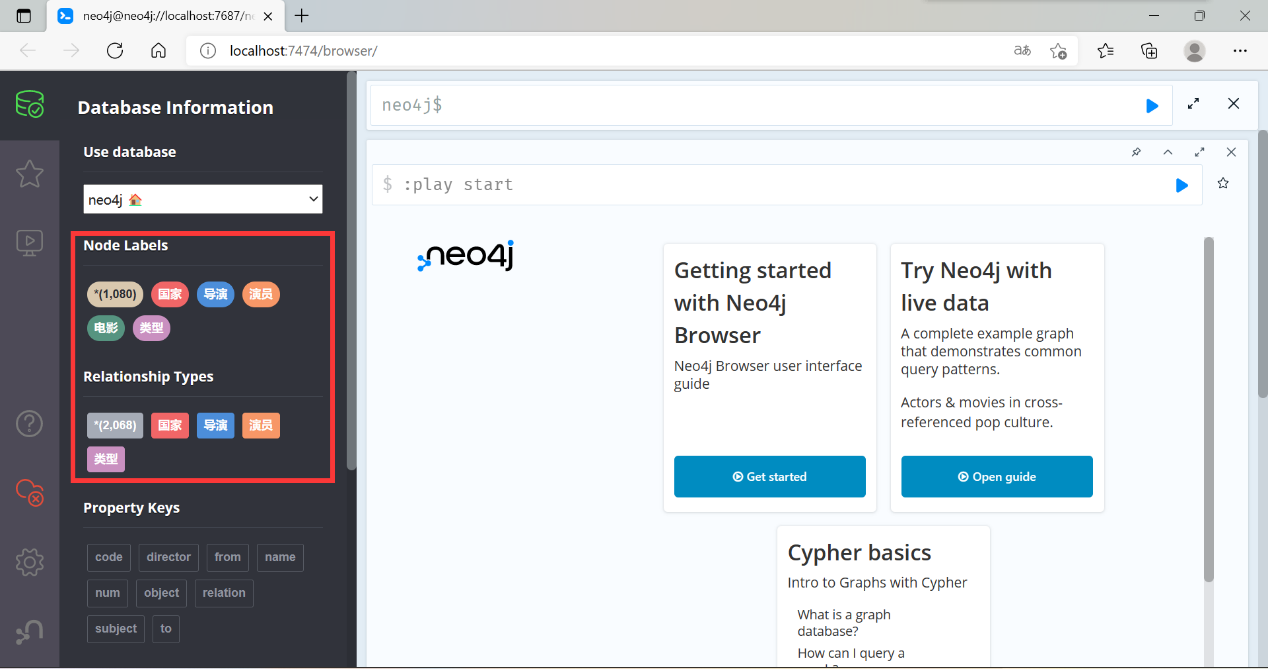
可以看到,新增了电影、国家、导演、演员、类型总共 1080 个节点和 2068 个关系,打开关系图,我们可以看到:
电影与国家关系图:

局部放大:
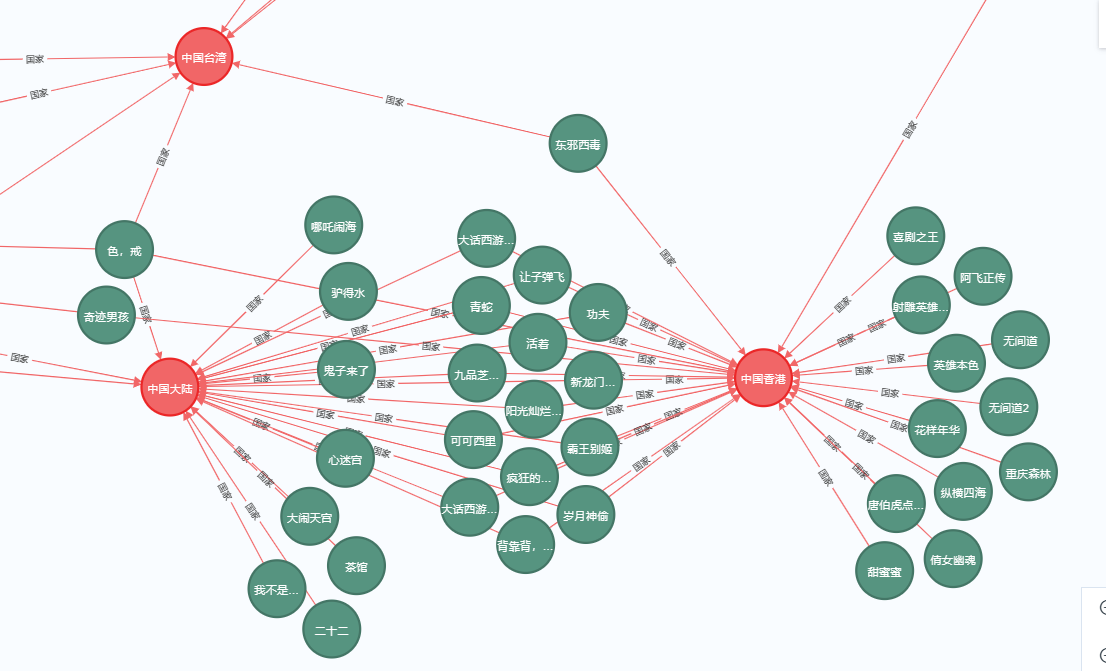
截取两个电影,可以看到与上图的关系相同:


电影与导演关系图:
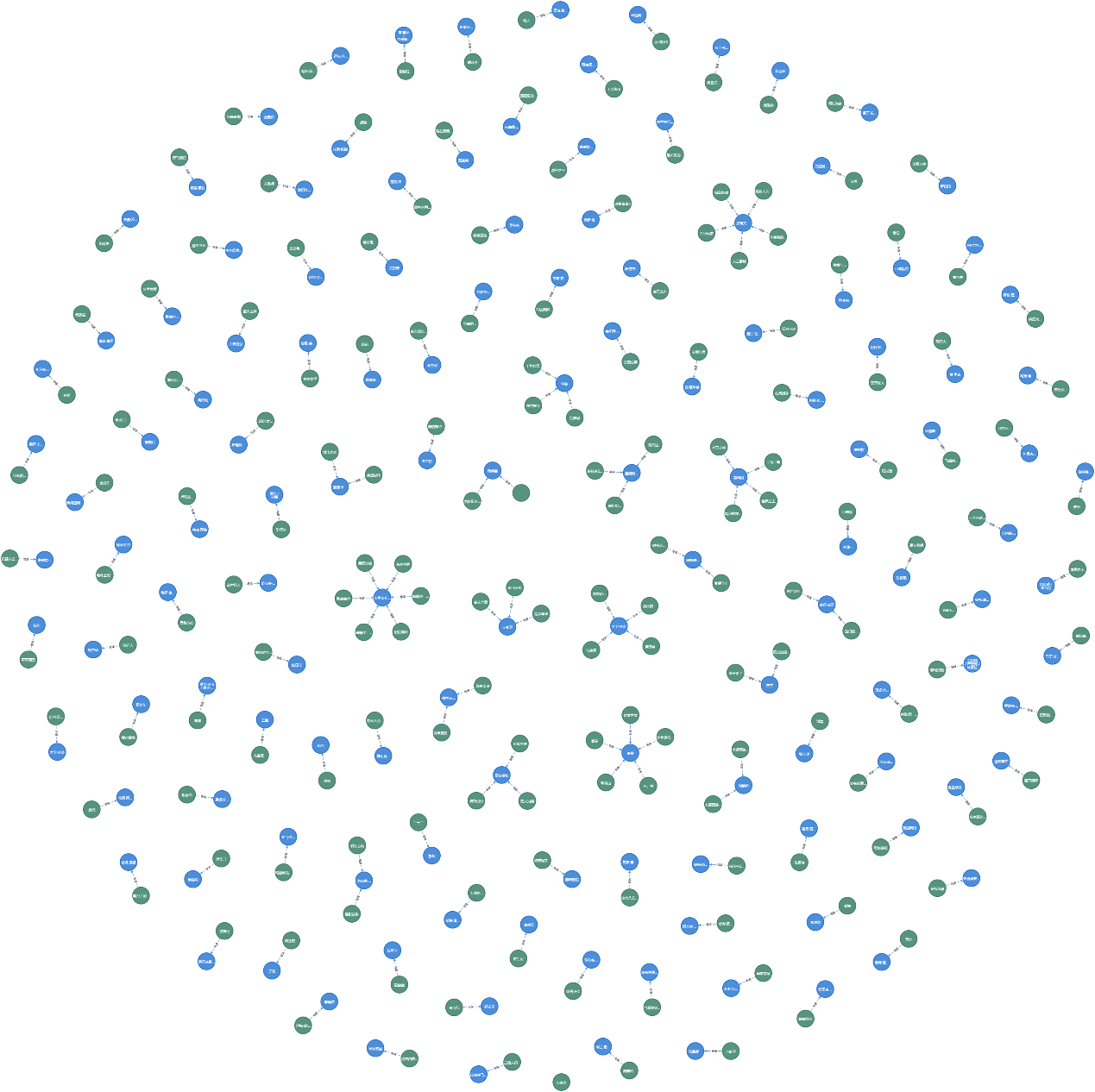
局部放大后:
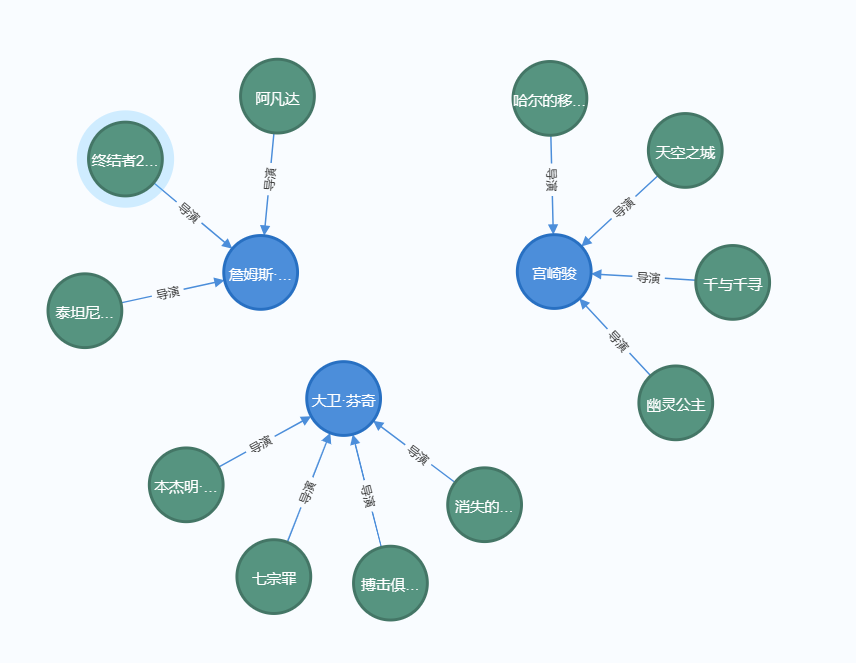
截取爬取到的一些电影数据对比,发现与上图中的关系相同:


电影类型关系图:

- 局部放大后关系图:
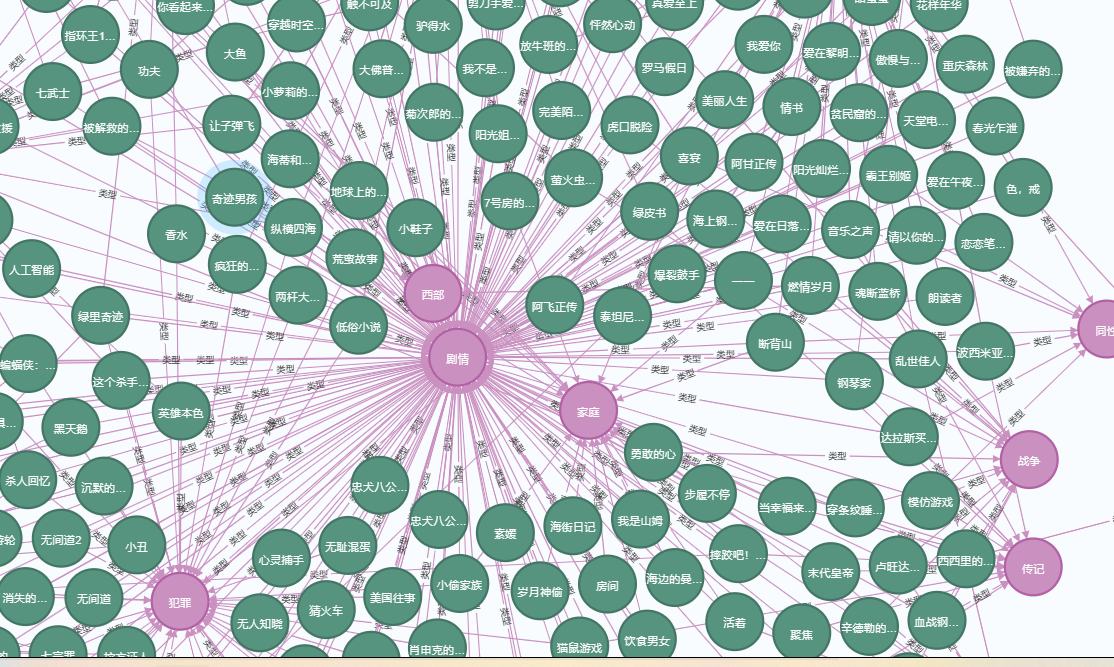
可以看到很多电影都是剧情类,截取几个电影信息对比,发现关系相同:

- 电影与演员关系图(由于结点过多较繁杂,每个电影仅取前三个演员):
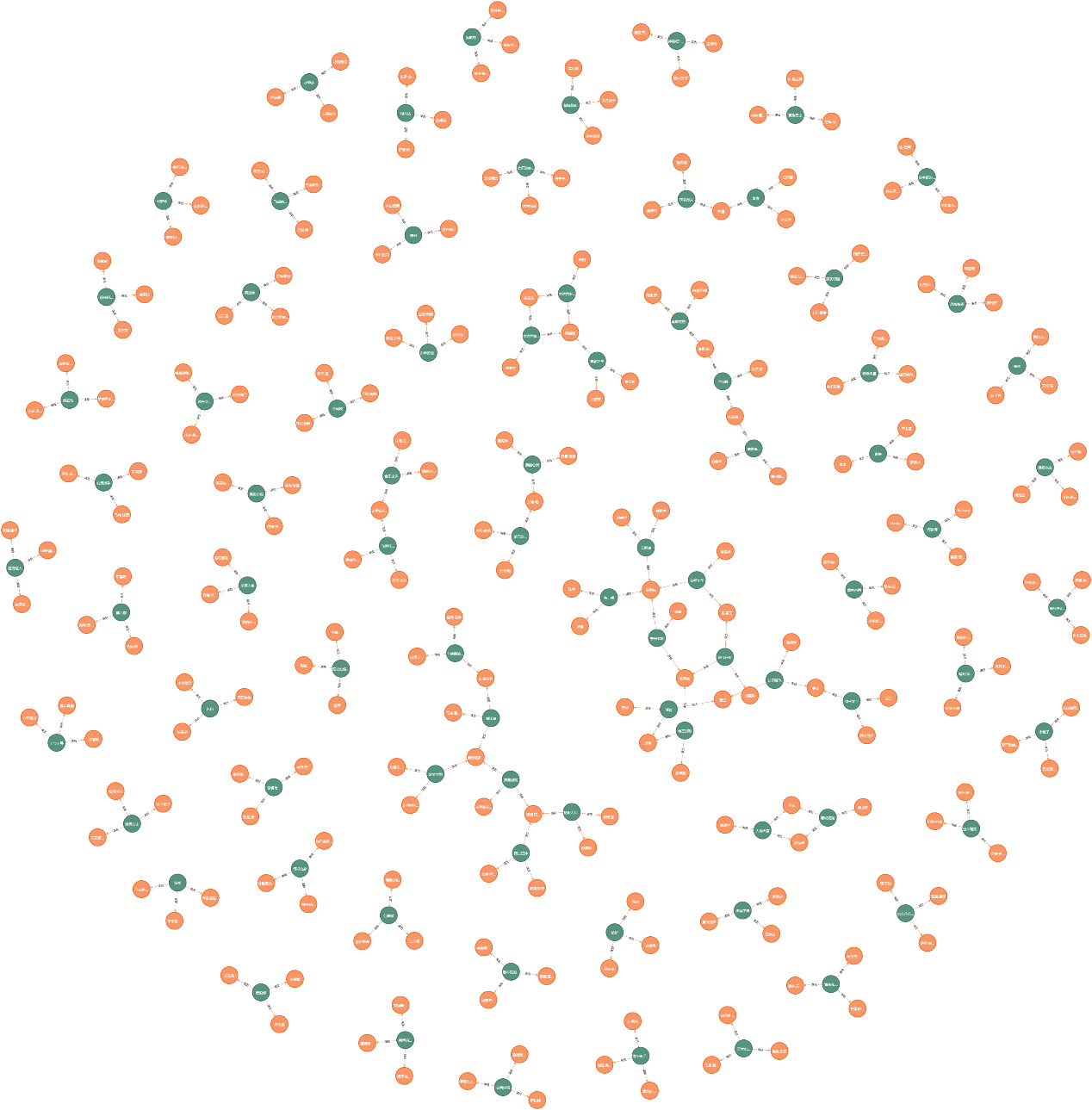
- 局部放大图:

截取部分电影数据进行对比,可以发现关系构建相同:



综上,图数据库构建完成,基本符合预期。
附加功能测试:
登录界面测试:

密码错误状态:
自动登录状态(将直接进入主窗口界面):

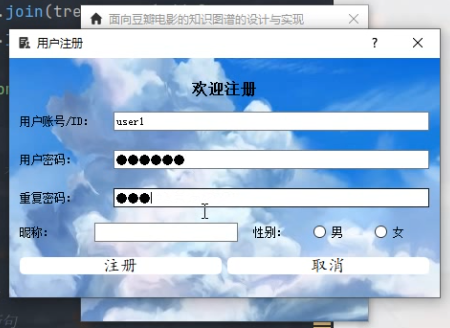
注册对话框界面测试:
主窗口界面测试:

点击“返回登录界面”后即可回到登录窗口;
点击“退出”后将安全退出程序;
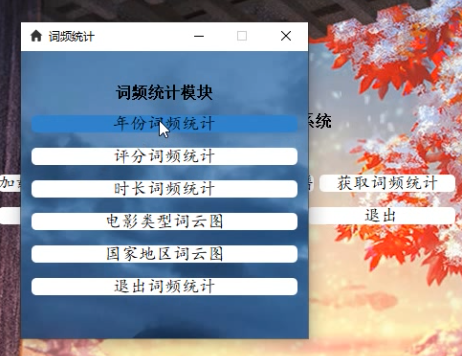
词频统计测试:
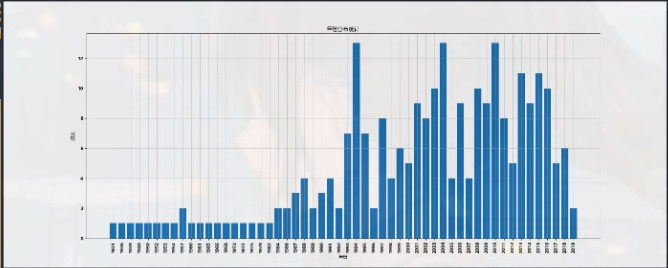
年份词频统计(统计入选 top250 的电影在哪些年电影比较多):
评分词频统计(统计入选 top250 的电影评分分布):

时长词频统计(统计入选 top250 的电影在时长分布):

电影类型词云图:


电影地区/国家分布词云图:

情感分析测试:
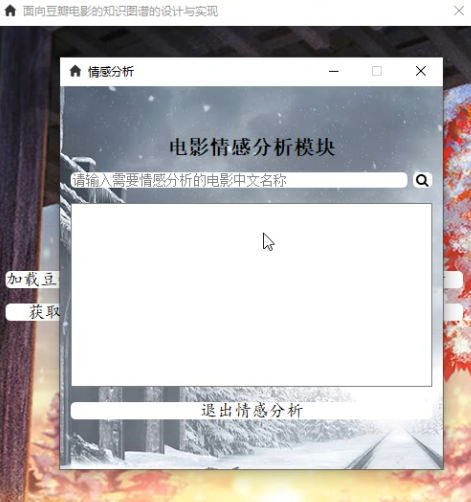
点击“获取情感分析”按钮,出现新界面:
输入需要获取情感分析的电影名称,回车或搜索按钮,得到该电影的 10 条最热门评论并打印内容及情感分析得分,作出情感分析图(0:消极 1:积极):

代理使用测试:

多线程测试:
见爬虫测试结果,效率高,耗时短
设计评估
本软件在分析阶段,从信息域、功能域、行为域多角度分析了用户需求,建立了多模块的类模型与方法、系统执行轨迹流程图,这使我们比较正确、全面的理解与表述了用户需求。设计依据分析说明书,编码依据设计说明书,每个阶段均经过严格的复审,因此做出的软件满足用户提出的需求。
本软件划分的子系统功能明确。子系统中的类基本上只与同一子系统中的其他类传递信息,子系统间的信息通过控制子系统传递。
设计的各个类功能简单,属性数和方法数少。类的接口少,独立性非常强,除控制类外,每个类均可被其他的系统复用。继承类主要继承编译器提供的控件,而该编译器提供的控件库是经典控件库,保证了本系统有着良好的继承关系。
- 本系统在设计时,以用户需求为根本,同时考虑到了实现环境,因此设计较有针对性。设计出来的系统在编码时可以大量复用已有控件,大大节省了编码时间,而且降低了错误发生的几率。
- 软件在设计时,考虑了以后的扩充,在整体结构和数据设计时都为以后的扩充做了准备。因此,此设计为软件的进一步开发提供了一个比较好的基础。
- 遇到的问题及解决方案
第一个遇到的问题是针对 pyqt5 布局时布置的部件无法正常显示(掺杂在一起或者不显示),解决方案是:首先没有将主窗口设置为界面中央,这会导致部件都无法显示;其次,注意到部件的坐标是以窗口的左上角为原点的,最初使用了一些快捷方法进行并排的 label,但发现太死板,无法在 label 间添加图标,于是最后选择了全部使用总体的垂直布局,使得部件分布集中均匀,但因此部件都集中在中间部分,有待改善。
在爬虫使用 PAThread、WorkThread 进行数据爬取时,最开始采用正则表达式进行对字符串的处理,但各个网站的 url 形式不同且存在较多相同的部分使得正则表达式结果不唯一,折腾了很久,最终针对不同的爬取内容采用不同的爬取方式如 re,bs4,xpath 等,哪个方便用哪个,完成代码的简化与最佳性。
第三个问题是解决爬虫的代理与请求头拒绝访问问题。首先是注意到大多数网页如果在同一时间内被多次访问,会对 IP 地址进行封锁与禁用,于是笔者在芝麻代理获取了可用的高匿代理,写了 get_proxy 函数爬取 API 的 ip 并通过全局变量 proxies 使用,防止出现代理拒绝访问的问题;其次,对于大多数浏览器,请求头也需要替换为浏览器里的 User-agent,否则将拒绝访问。
第四个问题是在打开窗口点击进行爬取时,窗口会卡主,问题原因是单线程会使窗口无响应,故采用了 pyqt5 特有的多线程爬取,继承 QThread,使得在爬取时仍然可以点击窗口内容,实现窗口的流畅性,但还是存在一些问题,如窗口的多线程不支持循环,循环启动线程会导致程序崩溃,故笔者只好一个个启动爬虫线程,有待改善。
在导入电影节点时,发现只导入了 249 个电影,于是以 20 个电影为单位进行比对排查,发现有一个名为“小森林”的电影有两个篇章,但由于创建节点时同名节点不再创建,所以只创建了一个。找到问题所在之后,将 CSV 文件中的小森林电影两个篇章名字加以区分后,再次导入,即可得到 250 个电影节点。
在建立国家、类型、演员节点的时候,每个 CSV 单元可能会含有多个信息用‘/’分隔开,直接对其创建节点会导致这些信息会连在一起,因此需对每一个单元格对‘/’进行切片,如下图(以国家为例):
取出所有国家
c++
countries = []
for i in range(1, 251):
lst1 = country[i].split('/')
for j in range(0, len(lst1)):
lst2 = lst1[j].split()
countries.append(lst2[0]) 切片后即可创建节点。同时,由于同名节点不会被重复创建,所以可以先暂时直接存储在列表中。
心得与体会
通过此次面向豆瓣电影的知识图谱的设计与实现,我们对软件课程设计的流程有了一个大致的了解,包括可行性分析、需求分析、概要设计、详细设计、测试调试等一系列过程,并通过这个项目对该过程进行了逐一实现,对项目的规范化与工程化有了一定的概念。此外,强化了 python 语言,锻炼了编程调试能力;重点掌握了 request 库来进行网页爬虫,并解决代理、拒绝访问、数据解析的一系列实践性问题,也加强了对 python 字符串的操作、对正则表达式的运用;其次,熟练了使用类来进行模块化设计,大大提高了代码的可读性与可复用性,在此基础上也掌握并实现了多线程的编程,使用 QThread()对象实现多线程的高效并发执行,尤其是针对我们这个数据量较大的爬虫内容有明显效果,也实现了程序窗口的流畅性,体现了多线程的强大之处,另一方面,通过编写图数据库代码,对 neo4j 图数据库有了基本的了解,熟悉了图数据库启动方法、节点创建方法、关系创建方法,以及一些图数据库基本操作 CQL 语法,对图数据库有了一定的认识;通过知识图谱的构建,对知识图谱思维导图这种关系的构建有了更深刻的理解,认识到知识图谱可以为不同类型的节点构建一定的关系,从而找到不同节点的联系,有利于对全局进行认识和对局部进行查找;最后,我们学会了分块调试与整体调试,使用 pycharm 的调试系统进行 debug,掌握了项目的基本测试方法。
总的来说,通过此次项目设计,我们对 python 有了进一步的锻炼,对另一类的 nosql 图数据库有了一定了解与使用,对 nlp 方面的词频统计、情感分析基础知识有了一定的复现,对知识图谱的设计原理更加理解,对软件工程的概念有了较深刻的认识,对自己的代码实践能力也有了进一步的提升,收获很大。
小结
在本文中,介绍了用面向对象软件工程方法开发面向豆瓣电影的知识图谱的设计与实现的思路以及过程。介绍了面向对象的需求分析、设计、测试、编码过程,介绍了爬虫的机制、neo4j 图数据库的原理、完成了附加功能,实现了整个程序系统的完整性与可执行性,并对设计进行了评估。
在整个过程中,需求分析阶段是关键的。在此阶段不仅要确定用户的需求,而且建立了大量的模块(类)。用户的可执行操作流程图,表述了用户的需求,而且是设计和测试的基础与依据。在设计阶段,采用了从总体到具体的设计思路,先确定用户的主要需求从而建立相应的类,再从用户的具体需求创建对应的方法,并且针对用户的各种操作流程画出了程序执行的流程图,这些流程图不仅是代码框架构建的基础,也是作为综合测试的依据。
在附录部分,给出了开发过程中产生的文档及关键代码。
个人在该课程设计中的工作及体会:
我在本次软件课设中主要完成了图数据库的构建及总体功能的调试和相应接口的设计。在开始阶段,在完成了本地环境搭建之后,我学习了运用 CQL 语言来对知识图谱进行构建,学习了将文件信息导入知识图谱并利用 CQL 语言创建节点和建立关系。由于 neo4j 中读取文件信息时主要运用的文件格式是 CSV 格式,所以在工作前期,我与组员讨论决定将爬虫爬取到的电影信息以 CSV 文件格式进行存储(后来是 python 构建知识图谱,因此对存储电影信息的文件格式没有过多要求,但由于一开始采用的 CSV 格式,之后就没再更改)。在使用 CQL 语句对一部分节点进行构建之后,发现了利用 CQL 语句在本次软件课设中的一些弊端:首先,虽然使用 CQL 能十分便捷的创建节点和节点之间的关系,但无法在创建节点之前对数据文件中的数据进行直接操作,比如演员的分词切割,这会造成创建节点时的一些困扰;另外,利用 CQL 语句难以在本地与爬虫程序、GUI 界面形成交互,无法在 GUI 界面上通过直接点击的操作构建知识图谱。因此,我学习了如何利用 python 来构建知识图谱,从而放弃了 CQL 语句。在网上查找部分资料后,我学习了利用 python 操作知识图谱的方法,在导入了 py2neo 模块后,编写了 CreateNode 函数、MatchNode 函数和 CreateRelationship 函数分别用来创建节点、匹配节点和建立节点之间的关系,再通过读取 CSV 文件中的电影信息来对节点和节点之间的关系进行构建。在创建节点时,如果遇到某一个单元格中含有多个信息的情况(例如一个演员单元格中含有多个用‘/’隔开的演员),可以利用列表的切片对其进行分割,在导入节点创建关系时,也可以通过列表长度内置函数(len(list))对列表之间节点关系进行准确的创建。同时,可以将整个创建知识图谱的函数封装起来,以便 GUI 程序的调用,从而实现与 GUI 界面的交互。在完成了这些功能后,我参与到整体功能的测试与调试中,最后修改了一些不足、改正了一些问题之后,实现了完整的功能。当看到表格中不太直观的电影数据变成条理清晰的知识图谱时,我认识到了知识图谱的功能强大之处,同时也对数据的存储和处理有了更深入的理解。
参考文献
附录一
二、系统规格说明书
系统说明
本系统将要实现的功能主要有:
实现网络爬虫,从豆瓣主页面进入并且以广度优先的方式爬取到每个电影详细页的地址及相关信息;
使用 Neo4j 图数据库,对使用爬虫爬取的电影数据进行分析,提取整合出知识图谱的结点和关系,完成知识图谱构建;
完成附加功能
可视化 GUI 界面
实现 GUI 图形用户界面的构建,对爬虫和 neo4j 数据库操作的部分功能进行封装搭建,在 GUI 界面上为二者提供接口(例如利用 GUI 界面按钮来控制爬虫的开始与中断,知识图谱的构建展示以及关键词检索等功能),同时也为其他附加功能提供接口,为用户提供友好的可视化操作界面。
代理池数据库
搭建代理池主要分为存储、获取、检测、接口四个模块。此处由于现有免费代理较差,采用芝麻代理 API 函数进行构建代理池。
多线程
在爬取许多网页或者爬取图片的时候,采用单线程方式下载访问会导致程序运行缓慢。多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。采用多个线程同步爬取多个网页。尤其是结合 GUI 的 QThread 多线程。
词频统计
词频统计模块分为读取、分词统计、写入三个模块,是自然语言处理的基础。可以利用现有的分词工具包(例如 jieba、等)对想要词频统计的信息进行分词,先将文本进行分词和词性标注,实现关键词提取。
情感分析
情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。针对电影的情感分析,是通过对电影评论的文本进行分词及词性标注,将电影的评论情感分为积极的,消极的或者中性。
立项依据
软件技术课程设计目的在于培养学生将所学的专业技能转化为实践的能力,因此在选题时充分考虑到了技术发展需要与实际的应用价值。学会快速获取和处理海量的数据并从中得到有价值的信息是信息时代的一项重要技能。通过完成本课程设计,将加深学生对网络爬虫、数据挖掘及软件编程技术的理解,同时锻炼其软件编程与解决实际问题的能力。
使用的技术
我们的软件将针对 PC 机制作。
使用目前主流的 Windows 操作系统。
使用 anaconda3 环境及 pycharmIDE 制作。
使用 neo4j 图数据库。
可行性分析
本软件将作为自由软件发放,在此,只进行技术可行性分析。
因目前大多数 PC 机的操作系统为 Windows,因此,使用 Windows 操作系统为平台。
使用 pycharmIDE,可方便界面的制作,其具有较为丰富的插件与编码规范,可节省大量的编码时间。
Anaconda3 提供了大量的 package
三、需求分析说明书
概述
本软件的开发使用多线程模块化编程。
要求实现的功能主要有:爬虫,构建知识图谱,附加功能。
功能需求
总体需求:
第一,从用户的角度来看,此项目需要提供一个可视化的图形用户界面以方便用户根据界面按钮与说明书文档进行操作,并且该程序应该可以根据用户的需求从互联网上进行搜集与爬取,将相关内容最终返回到图形用户界面,即完成程序与用户的交互;
第二,从爬虫开发者角度考虑,程序应该可以进行网页爬虫和资源下载,这里使用 request 库可以实现,但也要从开发者的角度考虑频繁访问页面时的代理池的问题;另一方面,由于爬取数据较多,应该可以实现多线程或者多进程并发进行,达到高效率;
第三, 从数据库开发角度考虑,数据库应该可以在导入数据后进行数据节点与关系的建立;
第四,爬取的数据除了具有关系之外,也可以对文本进行一定的分析,比如词频统计、情感分析等 NLP 的基础内容,对文本数据做出数据分析并且图形显示,实现可视化。
详细需求:
程序启动后有可视化的 GUI 界面,可以支持用户的登录与注册操作;
登录完成时可选择记住用户名/记住密码/自动登录等功能
登录完成后可以进入主窗口,选择“加载豆瓣电影信息”可以实现豆瓣 top250 的爬取
爬取完毕后可点击“导出数据构建知识图谱”进行本地数据库知识图谱构建(知识图谱需提前打开)
执行词频统计按钮可实现多种不同选项的词频统计分析
执行情感分析按钮可实现对需要进行情感分析的电影的热门评论的情感分析与结果可视化
执行返回登录界面按钮可退出主窗口重新登录
执行退出按钮可安全退出程序
附录三
四、概要设计说明书
概述
以需求分析说明书为依据,参照开发环境和使用环境的特点,划分出子系统,并确定出类。描述子系统间的协作关系,以及类间的协作关系。
环境说明
使用环境:
Windows 操作系统:
此操作系统界面友好,且有较成熟的文件查询,传递等机制可供利用。
开发环境:
Python3.8 发行版 anaconda3
c++
Neo4j-community-4.3.8
编写代码环境:
c++
Pycharm 2021.2.2
IDEA 开发工具,可以实现 Python 的自动补全,纠错,解释直至运行,为 Python 代码的编写和录入提供方便。
子系统与类
根据需求分析,将系统划分成 3 个子模块:
电影信息爬虫模块
知识图谱构建模块
附加功能模块
然后,依据 “类——责任——协作者”模型,在各子系统中确定出类。
电影信息爬虫模块:
根据广度优先搜索的要求,将该模块分为两个类,一是爬取所有电影的 url 的 PAThread 类,二是通过 url 爬取详细电影数据的 WordThread 类,对数据进行解析。
知识图谱构建模块:
主要包括 neo4j_test.py 模块,定义了相关结点与关系的方法,实现本
地知识图谱数据库构建

附加功能模块:
包括 GUI 界面(登录窗口 LoginPage()、注册窗口 RegisterPage()、主窗口 MainPage()、词频统计窗口 WordFreq()、情感分析窗口 Motion())、词频统计模块(针对电影的年份、时长、得分、地区、类型等的统计)、情感分析模块(热门评论情感分析);PAThread 与 WordThread 爬取继承多线程 QThread 类;代理池 get_proxy()函数
附录四
五、详细设计说明书
概述
以概要设计说明书为依据,进一步对系统的设计进行细化,并给出主要类的详细规格说明。
类设计
电影信息爬虫模块:
爬取的两个类均是继承 QThread 类,可使用 start()方法进行多线程执行
PAThread 类:
```python
线程:广度爬取TOP250的电影详情信息页url
class PAThread(QThread) ```
模块流程图:
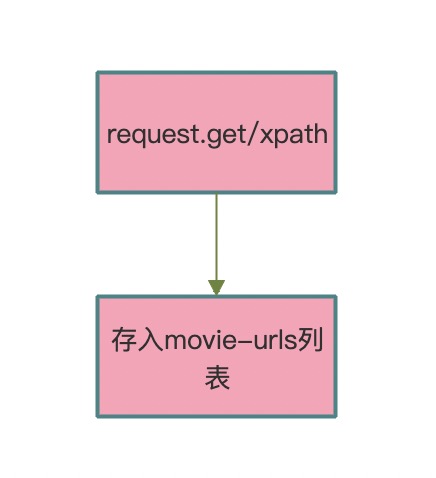
c++
resp = requests.get(url=self.url, headers=headers, proxies=proxies)
html = etree.HTML(resp.text)
lis = html.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li')
通过获得的 url,利用封装好的 run 函数。利用 xpath 解析 HTML。同时获取所以电影的 url 做好类型转换。
c++
movie_urls.append(movie_url)
最后添加到 movie_urls 列表中
WorkThread 类:
模块流程图:

```python
线程:解析每个电影的url,将详细数据存到缓存列表
class WorkThread(QThread): movie = [] if resp.status_code == 200: soup = BeautifulSoup(resp.text, features='lxml') tree = fromstring(resp.text) title_tmp = ''.join(tree.xpath('//*[@id="content"]/h1/span[1]/text()'))
分割中文与英文名称
title_tmp = re.split(' ', title_tmp, 1)
movie.append(title_tmp[0])
movie.append(title_tmp[1])
movie.append(''.join(tree.xpath('//*[@id="content"]/div[1]/span[1]/text()')))
movie.append(re.search('(?<=(<span class="d53_69dc_dccc64c year">\()).*(?=(\)</span>))', resp.text).group())
director_tmp = tree.xpath('//*[@id="info"]/span[1]')[0].text_content()
director_tmp = director_tmp.strip('导演: ')
movie.append(director_tmp)
actor_tmp = tree.xpath('//*[@id="info"]/span[3]')[0].text_content()
actor_tmp = actor_tmp.strip('主演: ')
movie.append(actor_tmp)
```
此类为对每个电影进行详细数据的爬取,需要 get_proxy()函数进行获取 ip 代理,防止被封禁。该类利用全局变量对爬取到的数据进行存储,是为了防止多进程的数据混乱现象。最后将一个电影的所有数据存储到 movie 列表中,再将所有电影信息存储到 movies 中,方便后续操作。
知识图谱构建模块
详细代码设计:
模块导入:
python
from py2neo import Node, Relationship, Graph, NodeMatcher, RelationshipMatcher
import csv
图数据库操作函数:
CreateNode 函数
python
def CreateNode(m_graph, m_label, m_attrs):
此函数的作用是在图数据库中创建节点。m_graph 是要构建的图数据库,m_label 是该节点所在的标签(电影、导演、演员、类型等),m_attrs 是该节点的属性(在本数据库中只设置了名称)
c++
m_n = '_.name=' + "\'" + m_attrs['name'] + "\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
if re_value is None:
m_node = Node(m_label, **m_attrs)
= graph.create(m_node)
return n
return None
创建之前先对该属性(名称)的节点进行匹配,如果该节点之前不存在,则创建此节点;如果节点之前已存在,则不再进行创建。调用此函数后,即可在 m_label 标签下创建一个之前不存在的节点 m_attrs。
MatchNode 函数
python
def MatchNode(m_graph, m_label, m_attrs):
此函数运用 matcher.match 方法对节点进行匹配:
c++
re_value = matcher.match(m_label).where(m_n).first()
此函数的作用是判断一个节点是否存在,为后面创建节点之间的关系做准备。
CreateRelationship 函数
python
def CreateRelationship(m_graph, m_label1, m_attrs1, m_label2, m_attrs2, m_r_name):
此函数的作用是创建节点之间的关系:
m_graph 是所在图数据库,m_label1 是第一个节点所在的标签,m_attrs1 是第一个节点的属性(名称),m_label2 是第二个节点所在的标签,m_attrs2 是第二个节点所在的属性(名称),m_r_name 是两个节点之间的关系。
创建关系之前先判断节点是否存在:
c++
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
revalue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or revalue2 is None:
return False
如果节点存在,没有返回,则创建关系:
c++
m_r = Relationship(reValue1, m_r_name, revalue2)
= graph.create(m_r)
return n
调用此函数后,即可创建两个标签下两个不同节点之间的关系。
知识图谱构建模块:通过调用该 package 实现知识图谱的构建
CreateGraph 函数:
构建图数据库的主体功能就是在此函数中,构建流程如下:
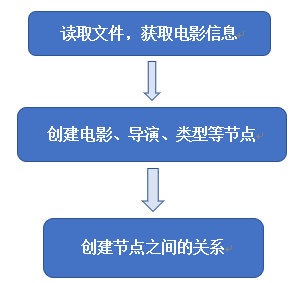
其中,获取电影信息时,由于国家、演员、类型等信息一个电影可能包含多个,于是采用切片逐一取出。创建节点时调用了 CreateNode 函数,创建关系时调用了 CreateRelationship 函数。
附加功能模块:
GUI 界面登录界面:
```python
GUI界面 登录窗口
```
初始化:
python
class LoginPage(QWidget):
'''用户注册、登录窗口'''
def __init__(self):
初始化界面,界面布局
方法:
```python
检查文本输入框的方法
def check_input(self):
当用户名及密码输入框均有内容时,设置登录按钮为可点击状态,否则,不可点击
登录方法
def login(self):
```
此处主要利用序列化反序列数据存储方式.pkl 实现模拟数据库存储用户信息
```python
检查用户状态方法,登录的时候查看复选框是否保存数据(是否保存用户名或保存密码或自动登录)
def check_login_state(self):
注册方法,点击注册按钮会进入注册界面
def register(self):
注册成功,登录界面载入刚刚注册的数据
def successful_func(self, data):
```
注册成功提示进入登录界面
```python
以下为用户信息保存方法
记住用户名到tmp_data
def remember_name_func(self):
记住用户名和密码到tmp_data
def remember_password_func(self):
自动登录,保存数据,仅保存上一次的登录用户
def auto_login_func(self):
页面登录信息初始化,包括自动登录等
def login_init(self):
```
GUI 注册对话框界面
```python
GUI界面 注册对话窗口 初始化
class RegisterPage(QDialog):
自定义注册成功信号,传递列表信息
successful_signal = pyqtSignal(list)
def __init__(self):
单行文本输入框初始化方法、槽函数绑定、正则校验等
def line_init(self):
按钮初始化方法
def pushbutton_init(self):
检查输入方法,只有在三个文本输入框都有文字时,注册按钮才为可点击状态
def check_input(self):
取消注册方法
如果用户在注册界面输入了数据,提示用户是否确认取消注册,如未输入数据则直接退出。
def cancel_func(self):
检查用户输入密码合法性方法
def check_password(self):
用户注册方法
def register_func(self):
先获取注册用户ID,检查用户ID是否存在
用户性别信息收集,男为1,女为2,未选择为0
def gender_data(self):
```
GUI 主窗口界面
```c++
GUI界面 登录后主界面窗口 初始化
class MainPage(QWidget): def init (self):
爬虫方法,首先爬取movie_urls,再多线程爬取详细信息
def pa(self):
global movie_urls
global proxies
get_proxy()
for i in range(10):
url = f'https://movie.douban.com/top250?start={i*25}&filter='
PAThread(url).run()
print(f'第{i}页url爬取完毕~')
sleep(0.1)
多线程爬取详细信息
self.work_0 = WorkThread(movie_urls[0])
self.work_0.start()
```
…
```c++
导出数据与构建知识图谱方法,点击后执行
def get_excel_map(self): print('正在导出数据') to_excel() print('导出完成!正在构建知识图谱...')
构建知识图谱
sleep(2)
data_xls = pd.read_excel('movie_data.xls', index_col=0)
data_xls.to_csv('movie_data.csv', encoding='utf-8')
sleep(1)
清空数据库 match (n) detach delete n
CreateGraph()
print('知识图谱构建完成!')
点击获取词频统计按钮打开新界面方法
def get_word_freq(self):
self.wordfreq_page = WordFreq()
self.wordfreq_page.show()
点击情感分析按钮打开新界面方法
def get_motion(self):
self.motion_page = Motion()
self.motion_page.show()
返回登录界面方法
def get_back(self):
self.close()
window.show()
```
GUI 词频统计窗口 WordFreq()
模块流程图:
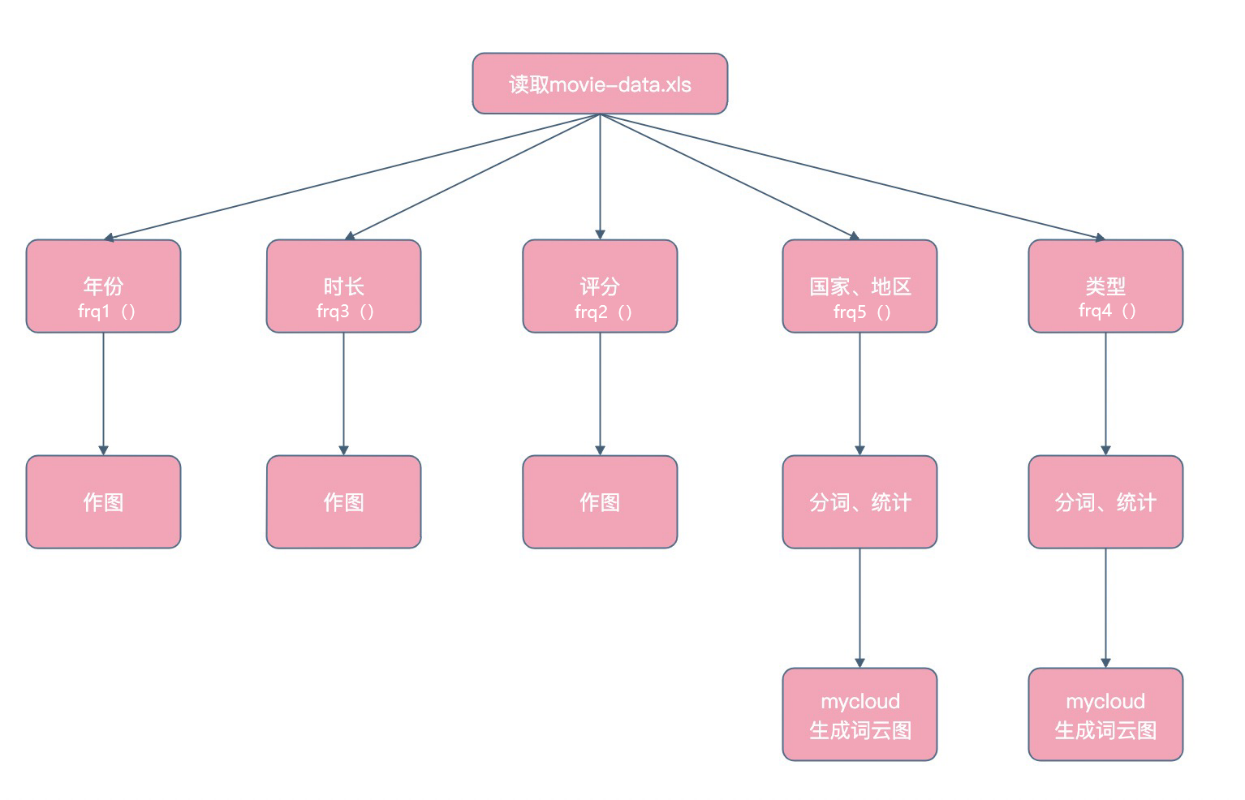
```python
GUI界面 获取词频统计界面窗口 初始化 布局
class WordFreq(QWidget): def init (self):
方法frq1 对年份进行词频统计 此处调用collections.Counter进行词频统计,并用matplotlib进行绘图
def frq1(self):
读取年份数据
workbook = xlrd.open_workbook('./movie_data.xls')
sheet1 = workbook.sheet_by_index(0)
year = sheet1.col_values(3)[1:]
词频统计
word_counts = dict(collections.Counter(year))
作图
```
以下同理 frq2 方法对评分词频统计 frq3 方法对时长词频统计
```python def frq2(self):
读取评分数据
def frq3(self):
读取时长数据
def frq4(self):
获取电影类型字符串
MyCloud(string_data)
def frq5(self):
获取电影国家地区字符串
MyCloud(string_data)
```
其中 frq4、frq5 调用 MyCloud()函数进行词频统计词云图绘制
```python
词频统计及词云图函数,需传入待处理文本字符串
def MyCloud(string_data):
文本预处理
pattern = re.compile('/|\t| |n') # 正则匹配
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
文本分词
seg_list = jieba.cut(string_data, cut_all=False)
词频统计
word_counts = collections.Counter(seg_list) # 对分词做词频统计
绘制词云图
mask = np.array(Image.open('./img/python_logo.jpg'))
wc = wordcloud.WordCloud(
font_path='C:\Windows\Fonts\STXINGKA.TTF', # 设置字体
mask=mask, # 设置背景图片
max_words=200, # 最多显示字数
max_font_size=250 # 字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云图
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云图颜色设置为背景图方案
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show()
```
GUI 情感分析窗口 Motion()
模块流程图:
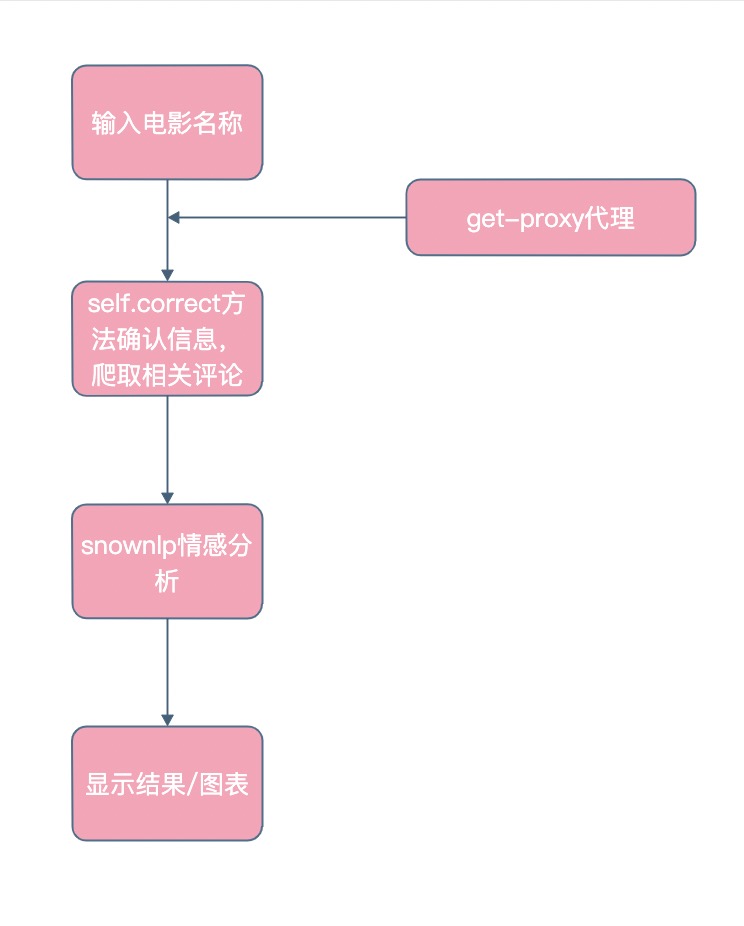
```c++
GUI界面 获取情感分析界面窗口 初始化 布局
class Motion(QWidget): def init (self):
搜索确认方法 并爬取评论10条 进行snownlp情感分析得分
def correct(self):
获取输入的电影名称
shuru = self.shuru.text()
global movie_urls
根据该电影排名从movie_urls中获取url,爬取热门评论10条
获取输入电影名称的url并爬虫
workbook = xlrd.open_workbook('./movie_data.xls')
sheet1 = workbook.sheet_by_index(0)
titles = sheet1.col_values(0)[1:]
爬取热门评论
global proxies
get_proxy()
resp = requests.get(url=url, headers=headers, proxies=proxies)
new_comments = []
new_comments.append(''.join(tree.xpath('//*[@id="comments"]/div[1]/div[2]/p/span/text()')))
将电影信息与评论打印输出再文本框中,并输出情感分析评分
motion_score = []
for i in new_comments:
= SnowNLP(i)
print(a1.words) # 分词
print(a1.tags) # 词性标注
print(a1.sentences) # 断句
= a1.sentiments # 获取得分
motion_score.append(a2)
作出十条评分的情感得分图
作图
plt.figure(figsize=(20, 8), dpi=80)
plt.show()
```
代理函数 get_proxy()
```c++
芝麻代理获取 对芝麻代理的API进行爬取 通过全局变量proxies传递给全局爬虫函数使用,防止IP封禁
def get_proxy(): global proxies print('开始获取代理IP地址...') headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36' } zhima_url = 'http://webapi.http.zhimacangku.com/getip?num=1&type=3&pro=&city=0&yys=0&port=11&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions=' proxy_ip = requests.get(url=zhima_url, headers=headers) tmp = proxy_ip.text.replace('\r', '').replace('\n', '') proxies = {'https': 'http://' + tmp} main
启动程序,创造pyqt实例
if __name__ == '__main__':
page = QApplication(sys.argv)
实例登录界面
window = LoginPage()
if not window.auto_login.isChecked():
window.show()
sys.exit(page.exec())
```
说明
具体的算法由程序员决定。
单元测试在程序员完成模块代码后由程序员交换执行,要求做到代码覆盖。
附录五
六、测试说明书
概述
依据用户需求,设计测试用例,对软件进行系统级测试。并根据测试结果填写测试表格的测试结果栏。
测试环境
测试的重点是音乐播放器的各项功能
测试过程及结果
根据需求分析文档,设计测试用例,填写预期结果。
在测试时,填写实际结果。
| 测试用例 | 预期结果 | 实际结果 |
|---|---|---|
| 运行 douban.py | GUI 登录界面弹出 | GUI 登录界面弹出 |
| 点击注册,进入注册对话框,按要求提示注册用户 | 提示注册成功并进入登录窗口 | 提示注册成功并进入登录窗口 |
| 输入用户名登录 | 进入主窗口界面 | 进入主窗口界面 |
| 登录时勾选保存用户名/保存密码/自动登录 | 下次登录时用户名保存/密码保存/自动登录到主窗口界面 | 下次登录时用户名保存/密码保存/自动登录到主窗口界面 |
| 用户名或密码错误 | 显示“密码错误,请重新输入” | 显示“密码错误,请重新输入” |
| 主窗口界面,点击“加载豆瓣电影信息”; | Console 输出爬取内容 | Console 输出爬取内容 |
| 测试用例 | 预期结果 | 实际结果 |
| 主窗口界面,点击“导出数据构建知识图谱” | 生成 movie_data.xls;movie_data.csv 文件,本地 neo4j 数据库生成知识图谱 | 生成 movie_data.xls;movie_data.csv 文件,本地 neo4j 数据库生成知识图谱示 |
| 主窗口界面,点击“获取词频统计” | 出现词频统计界面 | 出现词频统计界面 |
| 词频统计界面,分别点击各选项 | 对应选项出现图表结果或词云图 | 对应选项出现图表结果或词云图 |
| 主窗口界面,点击“获取情感分析” | 出现情感分析界面 | 出现情感分析界面 |
| 情感分析界面,输入电影名称“霸王别姬”,回车或点击搜索按钮 | 情感分析界面显示该电影热门评论 10 条及其情感程度,作出情感程度折线图 | 情感分析界面显示该电影热门评论 10 条及其情感程度,作出情感程度折线图 |
| 点击各个窗口界面的退出/返回按钮 | 退出当前窗口或返回上一级窗口 | 退出当前窗口或返回上一级窗口 |
参考文献
- 基于网络爬虫的电影集成搜索系统设计与实现(江西农业大学·江沛)
- 基于知识图谱的个性化推荐系统研究与应用(哈尔滨师范大学·吕刚)
- 基于知识图谱的协同过滤算法的研究与应用(南昌大学·田玉梅)
- 基于知识图谱的推荐系统的研究与应用(南京邮电大学·程诚)
- 基于知识图谱的电影知识问答系统设计与实现(北京邮电大学·吕英振)
- 基于知识图谱的电影个性化推荐关键技术研究(北华航天工业学院·孙程程)
- 影评情感分析知识图谱构建研究(河北工业大学·于子琪)
- 基于知识图谱的个性化推荐系统研究与应用(哈尔滨师范大学·吕刚)
- 基于知识图谱的电影个性化推荐关键技术研究(北华航天工业学院·孙程程)
- 基于混合算法的电影推荐系统研究(南京邮电大学·韩文杰)
- 基于知识图谱的个性化推荐系统研究与应用(哈尔滨师范大学·吕刚)
- 基于用户上网数据的电影个性化推荐系统研究(北京邮电大学·赵鹏程)
- 基于知识图谱的影视知识问答系统研究与实现(新疆大学·王文磊)
- 基于知识图谱的个性化电影推荐系统的研究与实现(石河子大学·牛妍辉)
- 面向特定领域的知识图谱构建与实现(北京邮电大学·陈剑冲)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计工坊 ,原文地址:https://bishedaima.com/yuanma/35973.html









