
1 运行环境:
Kaggle kernel,Tesla P100
2 操作过程示例(在 notebook 中输入 shell 指令)
-
!git clone https://github.com/CT2001/image-to-latex.git
-
%cd image-to-latex
-
!chmod +x ./kaggle.sh
-
!./kaggle.sh
-
!python scripts/run_experiment.py project_path.path=
'/kaggle/working/image-to-latex' trainer.gpus=1
data.batch_size=16 trainer.max_epochs=5
保存运行记录并下载(示例)
使用 tensorboard 查看运行数据
-
进入 tb_logs 所在目录
-
在该目录内打开 terminal,输入命令:
tensorboard --logdir tb_logs

点击链接

- 查看运行数据

3 数据预处理
- 筛除含多行公式和 error mathix
- 根据词表进行分词,筛除含中文的 lable
- 对齐过滤后的数据
- 根据 image-to-latex 项目的输入输出格式对数据进行调整,生成可用于生成 JSON 词表、划分数据集的 lst 文件
- 对图片进行裁剪,去除图片多余的空白,只保留公式
- 生成 JSON 词表
- 根据 lst 文件将预处理后的数据集划分成训练集、验证集与测试集;然后载入数据集,分 batch。对于每一个 batch,填充图片,使得图片尺寸统一为原图片中的最大图片的尺寸;同时将每一个标签转换成索引向量,向量长度统一为原标签中最大标签的长度(max_length)+2。
4 模型
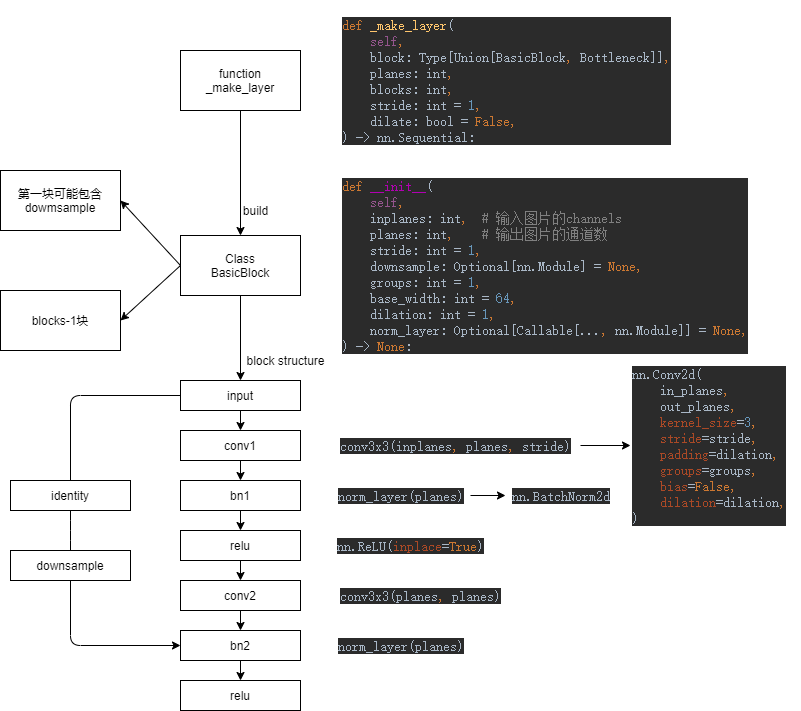
1)Resnet18(Fig.1)
Resnet18 的结构组成如下。
第一个卷积块。
四个 Layers:每个 Layer 包含两个 BasicBlocks(每个 BasicBlock 是一个残差学习单元,通过引入 identity shortcut 来解决不断加深网络的退化问题),后三个 Layers 的第一个 BasicBlock 会在恒等映射过程中进行 downsample 操作(Projection Shortcut),以此来应对输入输出维度不同的情况,并在一定程度上提高训练精度(Fig.2)。
adaptive average pool 层。
全连接层。
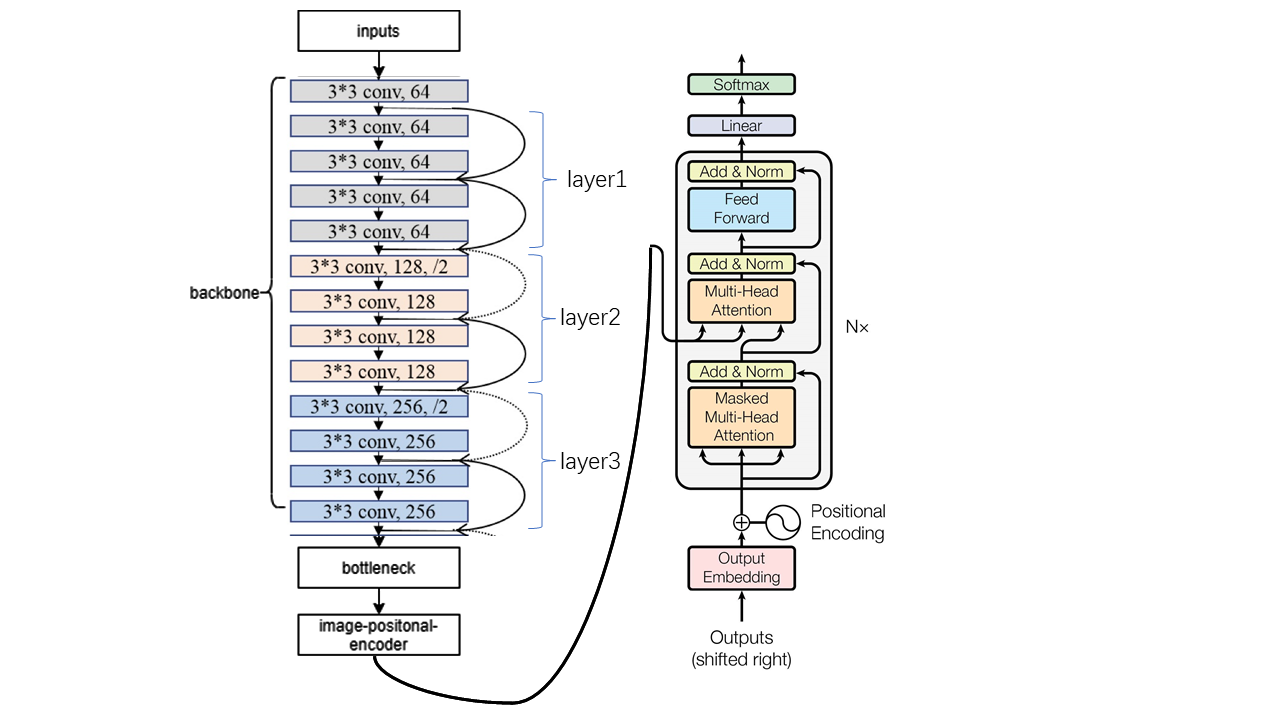
2)Encoder(Fig.3)
本模型的 Encoder 的结构组成如下。
Resnet18 中第一个卷积块与前三个 Layers。
BottleNeck(1*1 卷积核):特征降维,节省计算量;增加模型的非线性表达能力。
Positional Encoding:使得模型具有捕捉顺序序列的能力,能够学习顺序序列中元素的相对位置关系[1]。
3)TransformerDecoderLayer
Self-attention:无视序列中元素之间的距离直接计算依赖关系,能够学习一个序列的内部结构,实现较为简单并且可以并行计算。如果是 RNN 或者 LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是 Self-attention 在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的路径被极大缩短,有利于有效地利用这些特征
Multi-Head Attention:并行化 self-attention 机制——利用多个查询,来平行地计算从输入信息中选取多个信息,每个注意力关注输入信息的不同部分,然后再进行拼接;另外,多个 head 学习到的 Attention 侧重点可能略有不同,这样给了模型更大的容量。
Mask:保证顺序序列中某一个元素只能获取位于该元素之前的元素的信息,不能获取位于其后的元素的信息。
恒等映射与标准化。
4)Decoder
本模型的 Decoder 部分主要 TransformerDecoderLayer 接口与 TransformerDecoder 接口。先建立词嵌入表,对每个公式对应的 label 构建词向量,并对词向量进行 positional encoding。将 Encoder 的输出、经过上述处理得到的词向量以及 mask 传入 TransformerDecoder,将输出 TransformerDecoder 的输出结果传入全连接层,得到本模型的最终输出(Fig.4)。


5 运行结果分析——数学公式训练集
超参数



1)训练
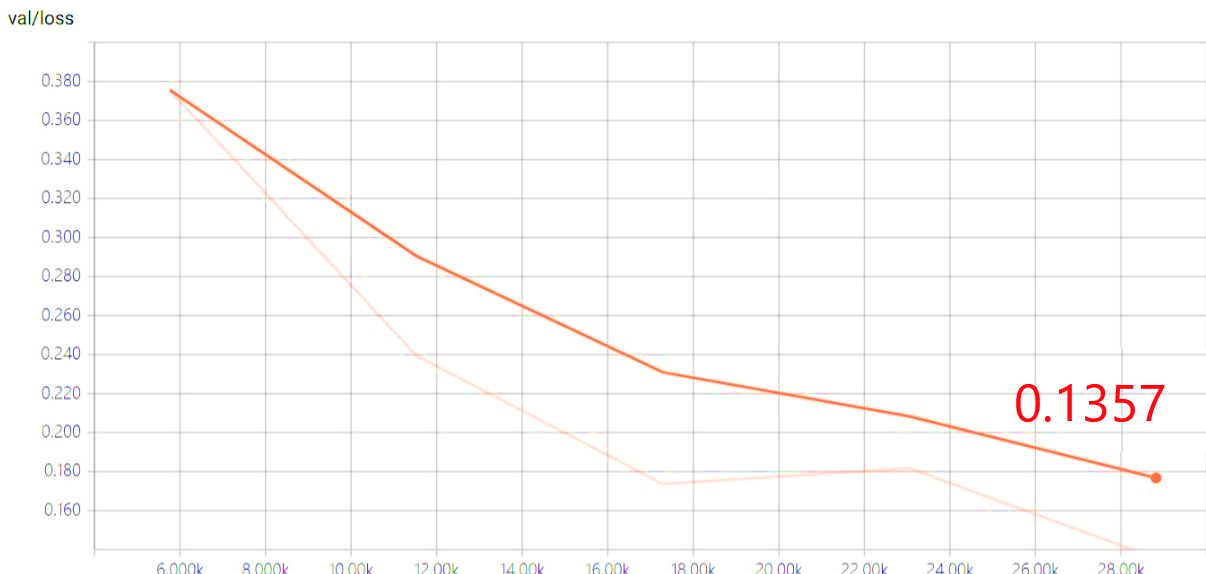
训练过程中,loss 逐渐下降收敛

2)验证
损失和错误率逐步下降,未出现欠拟合、过拟合现象。

3)测试

6 运行结果分析——生物数据集
超参数

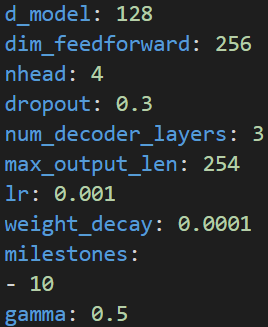

- 训练
- 训练过程中,loss 逐渐下降收敛

- 验证
- 损失和错误率逐步下降,未出现欠拟合、过拟合现象。

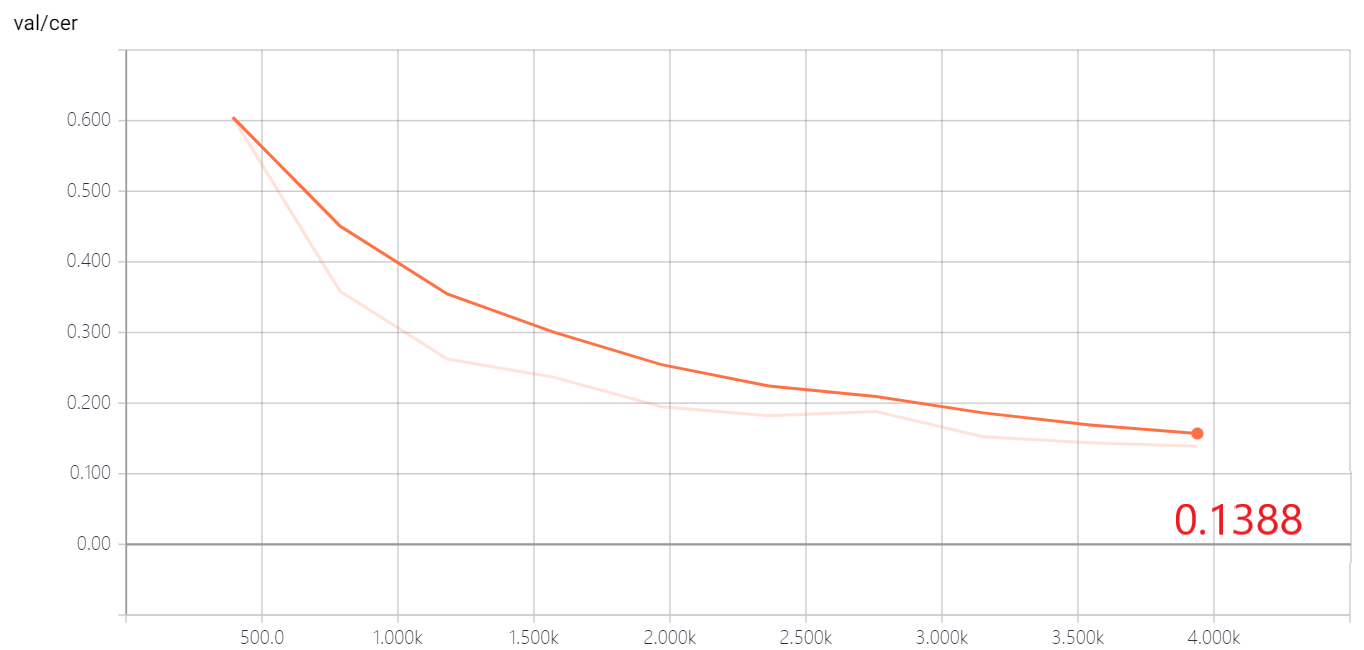
- 测试
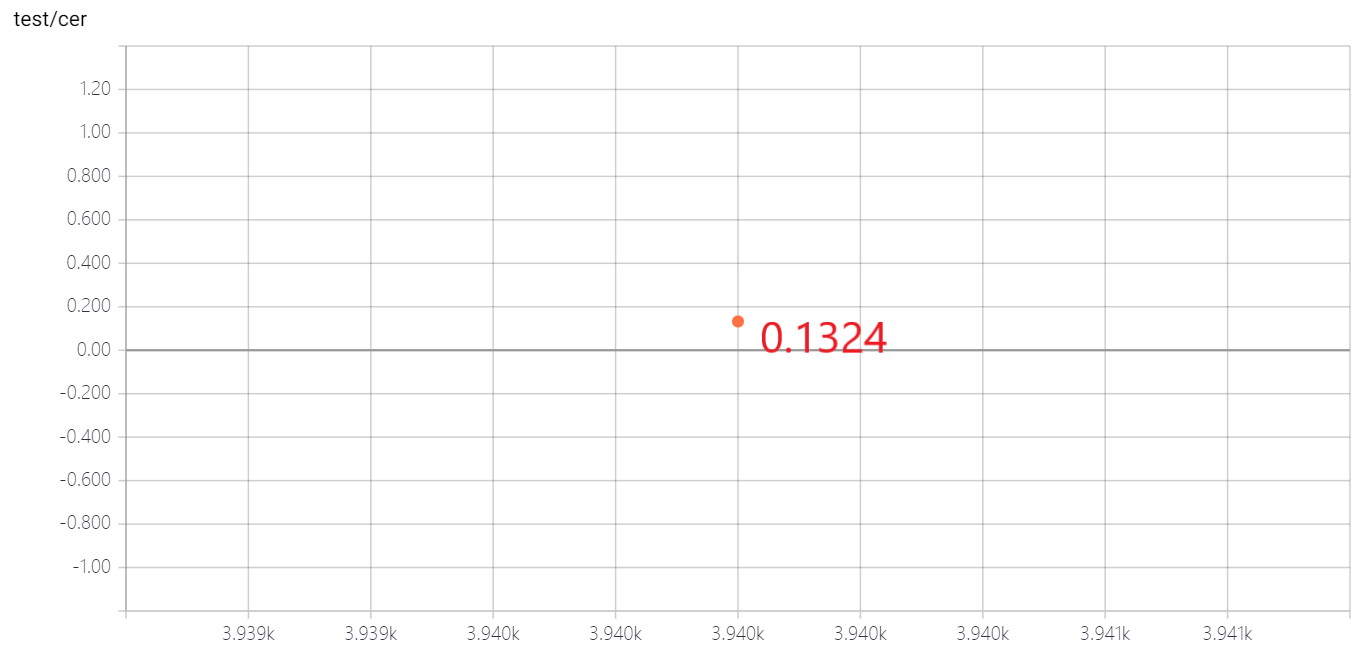
综合分析:生物比数学准确率低原因可能是生物数据少(经预处理后数据量为 35990),数学数据多(预处理后数据量为 131736)
参考文献
- 智能课程管理平台的设计与实现(北京交通大学·吴格)
- 基于设计型学习的初中Python编程课例设计与应用研究(佛山科学技术学院·王颖)
- 基于信息化服务的湖南电大课程教学系统的设计与实现(电子科技大学·龙昱)
- 互动网络课堂的研究及平台设计实现(沈阳建筑大学·吴宇玲)
- 在线教学系统的设计与实现(吉林大学·李正德)
- 基于J2EE的远程网络教育系统研究与实现(电子科技大学·陈南荪)
- 在线教学系统的设计与实现(吉林大学·李正德)
- 基于云的在线学习平台教师子系统的设计与实现(哈尔滨工业大学·王闯磊)
- 在线教学系统的设计与实现(吉林大学·李正德)
- 基于应用场景的初中Python项目式学习课例开发与应用研究(佛山科学技术学院·赵健如)
- 基于深度学习的前端代码智能生成算法(东莞理工学院·张志航)
- 《多媒体课件制作》网络课程中“问题”部分的设计与开发(内蒙古师范大学·孙崇霞)
- 互动网络课堂的研究及平台设计实现(沈阳建筑大学·吴宇玲)
- 互动网络课堂的研究及平台设计实现(沈阳建筑大学·吴宇玲)
- MOOC服务平台的设计与实现(齐鲁工业大学·宫琳琳)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码港湾 ,原文地址:https://bishedaima.com/yuanma/35859.html









