
基于 TensorFlow 框架的手写数字识别系统
摘要
时下人工智能蔚然成风,作为新型生产要素,在各个领域都极大地推动了经济发展,预示着社会经济将取得巨大增长和和人类潜能将得到深度开发。实现人工智能的手段即为机器学习,而机器学习领域中的一个重要问题就是手写字符的识别。手写数字识别的应用包括邮件分拣,银行支票处理,表格数据输入等。问题的核心在于开发能够识别手写数字的有效算法的能力,并且用户通过该方式提交扫描仪,平板电脑和其他数字设备来完成手写数字的识别。但因个人手写数字特征的千差万别,造成了现有手写数字识别系统的识别准确率普遍较低。
本文旨在通过使用 Google 研发的 Tensorflow 人工智能框架,分别搭建 Softmax 回归模型和卷积神经网络模型,并比较两者的识别率高低。本系统使用的手写数字数据集是 MNIST 数据集,该数据集分为三部分:55000 行训练数据集、10000 行测试数据集、以及 5000 行的验证数据集。每个测试集的图像的长和宽各为 28 个像素点,测试集的标签表示该图像是哪个数字。经过搭建、训练、使用两个模型,Softmax 回归模型和卷积神经网络模型对手写数字的识别率分别为 91.92% 和 99.13%,卷积神经网络的识别率已经达到了可以实际应用的程度。本文为人工智能的手写数字识别的发展提供了一定的理论价值和科研依据。
关键词 :机器学习,手写数字识别,TensorFlow,Softmax,CNN
详细介绍请看文档论文
一、绪论
1.1 课题研究背景及意义
自从 AlphaZero 击败人类顶尖围棋高手后,人们关于人工智能的讨论就喋喋不休,从而出现了人工智能有益论和人工智能有害论两派。有许多人人认为人工智能会使一大批人失去他们所从事的行业,无情的被机器人取代。而更多人则认为,人工智能可以帮助我们创造更多的财富,创造更美好的明天。而目前我所能接触到的人工智能技术,都为人类的发展做出了极大的贡献,人类不能因噎废食。例如在图像识别领域,使用 Google 的 TensorFlow 人工智能框架可以很方便的搭建一个卷积神经网络,并且立即投入使用。
手写数字识别重大研究价值意义在于人机交互方向,提高人机交互的流畅性、方便性以及似人性。在于数字信息自动处理领域,提高处理效率,节省物力财力,加快信息传输,创造出无数的财富。手写体是人类在交流中使用的最常见的标准和常规媒介。即使引入了诸如键盘,声音命令等新技术,它也是一种有效且高效的信息记录方式。通常,手写识别系统是一种用于识别人类手写的任何语言的机制,无论是扫描的手写图像或者在电子设备上使用手写笔进行实时手写,也可以分别称为离线和在线手写[1]。此外,该系统的应用可分为数字,字符和英文字母三种。它广泛用于许多应用,如语言翻译,银行支票和关键字定位。手写数字识别系统的理论价值如下:
阿拉伯数字官方符号,被世界各国通用,且应用于生活的方方面面。因此研究手写数字识别具有很高的应用价值。
相较于汉字、英文单词等常用字符,数字识别的类型数较小,有助于做深入分析以及验证一些新的理论。
虽然人们已经对模式识别的手写数字领域进行了相当长时间的研究,但是手写数字识别系统仍然有很多不足,在某些情况下,还无法与人类的识别能力相提并论,人工智能还有很长的路要走。
手写数字识别与许多领域都有关联性,尤其是中英文拼音的识别。事实上,很多研究人员就是同时研究这两者的,由于相似性较强,结合在一起研究更易取得研究成果。
银行、表格、证券是手写数字识别可以大放异彩的又一个领域。随着我国经济的迅速发展,无时无刻不产生大量的账单、支票、税务报表等等手写数据[3]。与上面提到的统计报表[4]处理相比,在这个领域的应用难度更大,因为对识别的精度要求更高,处理的表格种类更多等,这样对识别及预处理的核心算法要求也大大提高了。如果在这个方向上都能做到机器自动识别的话,就能够取得巨大的经济效益。
1.2 研究状况
模式识别是二十世纪五十年代初迅速蓬勃发展起来的一门学科。模式识别研究的是如何用机器来实现高等动物对事物的学习、判断和识别能力,因而受到了国内外众多科研人员的关注,成为人工智能研究的一个重要方面。一个模式识别系统的基本功能是对系统所要处理的模式归属于哪一类做出判断,从该系统的模式输入到系统做出判别之间,主要包括数据检测、图像预处理、特征值的提取和分类四大环节。
字符识别又是模式识别领域中的一个极受关注的问题。问题本身的难度使之成为一个兼具趣味和挑战性的课题;另一方面,因为字符识别不是一项单独的应用技术,其中包含的模式识别领域中其他分支都会遇到的一些基本和共性的问题。
从 19 世纪九十年代末期到目前为止,世界各国的科学家发表了很多关于 MNIST 手写数字识别的文章。从新闻上也可以经常看到这个领域的研究进展。而识别率和识别速度是衡量识别方法优劣的两个关键指标。可以看出,在线性分类器,KNN,SVM,NN 和 CNN 中,目前识别率最高的模型是 CNN。且针对 MNIST 数据集,没有特征提取方面的最优解。直接用 LeNet-5 结构的 CNN,就能得到比较好的结果。
1.3 研究内容
本课题主要实现了两种手写数字识别模型:Softmax 回归模型核卷积神经网络模型,并运用 Flask 框架展示在网页当中,Softmax 回归模型和卷积神经网络模型对手写数字的识别率分别为 91.92% 和 99.13%。本文的研究内容可总结如下所示:
- 搭建 TensorFlow 框架,配置 Python 环境,下载 MNIST 手写数字数据集。
- 学习 Softmax 回归算法,实现 Softmax 回归模型,并进行训练和评估。
- 学习卷积神经网络的基本原理,搭建共计七层的卷积神经网络模型,不断优化模型参数,训练 CNN 模型,并进行评估。
- 运用 Flask 框架,通过网页交互,将输入的数据传入后台处理,并返回两个模型的识别结果,最终显示在网页中。
1.4 研究方法
实验研究表明,若手写体数字没有限制,几乎可以肯定没有一劳永逸的方法能同时达到 90% 以上的识别率和较快的识别速度。因此,这方面的研究向着更复杂更综合的方向发展。例如人工智能中的专家系统、人工神经网络已经开始应用于手写体数字识别的研究当中。在手写数字识别的发展中,神经网络和多种专家系统的结合是值得探究的方向。模式特征的不同,其决策方式也会不同。可将模式识别的方法大致分为 5 大类[8]。这五类方法各有各自的特点,各有各自的适用条件,最后都能实现手写数字的识别。这五类方法分别为:
- 句法结构方法
- 统计模式法
- 逻辑特征法
- 模糊模式方法
- 神经网络方法
二、相关技术介绍
本章介绍了本课题所使用的相关技术,并介绍了相关技术的工作原理、优缺点等。相关技术包括 TensorFlow 框架、Python 语言、Tkinter 相关控件及特性以及 MNIST 数据集等。
2.1 TensorFlow 框架
2.1.1 TensorFlow 框架介绍
TensorFlow 是一个用于机器学习的端到端开源平台。它拥有全面,灵活的工具,库和社区资源生态系统,可让研究人员推动 ML 的最新技术,开发人员可轻松构建和部署 ML(Machine Learning)驱动的应用程序。它还是一个开源软件库,用于语义理解和感知方向的机器学习。TensorFlow 框架是由谷歌人工智能团队开发,用于 Google 相关产品及功能的开发与研制。如语音识别、谷歌邮件、谷歌地图和谷歌搜索引擎。
2.1.2 TensorFlow 工作原理
TensorFlow 是一个采用数据流图用于数值计算的开源软件库。节点一般在图中表示数学操作,图中的线则表示在节点间的输入/输出关系,也就是张量。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因[10]。
2.2 Python 语言
2.2.1 Python 介绍
Python 是一种广泛使用的通用高级编程语言。它最初由 Guido van Rossum 于 1991 年设计,由 Python Software Foundation 开发。它主要是为了强调代码可读性而开发的,其语法允许程序员用更少的代码行表述概念。 Python 有两个主要的 Python 版本:Python 2.x 和 Python 3.x。两者差别较大,本文使用的是 Python3.x。
起初,自动化脚本常用 Python 来编写。之后随着 Python 版本的不断升级以及功能的不断完善,它越来越多被用于大型的、独立的项目开发。Python 除了极少数事情不能完成之外,其他基本上可以说全能。多媒体应用、机器学习、人工智能、系统运维、黑客编程、图形处理、爬虫编写、数据库编程、pymo 引擎、文本处理等等都可以用 Python 来实现。Python 常见应用如图 2.1 所示:
2.3 Tkinter
2.3.1 Tkinter 介绍
Tkinter 模块是 GUI 工具包的标准 Python 接口。Tk 和 Tkinter 都可以在大多数 Unix 平台上以及 Windows 和 MAC 操作系统上使用。从 8.0 版开始,Tk 在所有平台上都提供原生外观。Tkinter 包含着许多模块,Tk 接口由名为_tkinter 的二进制扩展模块提供。它通常是一个共享库(或 DLL),但在某些情况下可能与 Python 解释器静态链接。公共接口通过许多 Python 模块提供。最重要的接口模块是 Tkinter 模块本身。要使用 Tkinter,所需要做的就是导入 Tkinter 模块:
c++
import Tkinter
或者更常用的是:
c++
from Tkinter import *
2.3.2 Tkinter 模块的 GUI
在 Python 中,常用 tkinter 来开发图形用户界面。Tk 是一个工具包,它提供了跨平台的 GUI 控件,开发图形用户界面十分方便快捷。基本上使用 tkinter 来开发 GUI 应用需要以下 5 个步骤
- 将需要的 tkinter 模块导入进开发环境中
- 创建顶层窗口,并在这个顶层窗口开发 GUI
- 添加 GUI 组件,并将组件放在合适的位置
- 编写响应函数,将函数与需要响应的按钮绑定
- 进入 main loop。
2.4 MNIST 数据集介绍
MNIST(Mixed National Institute of Standards and Technology database)是一个非常庞大的手写数字数据库. MNIST 数据集的官网是 YannLeCun website[11]。该网站提供了一份 Python 源代码用于自动下载和安装这个数据集。可以直接复制粘贴到代码文件里面,用于导入 MNIST 手写数据集。
import inputs_data
mnists = inputs_data.read_datas_sets("MNISTS_datas/", one_hots=True)
下载下来的数据集可被分为三部分:55000 个训练数据集(mnist.train),10000 个测试数据集 (mnist.test),以及 5000 个验证数据集(mnist.validation)。MNIST 数据集的划分很重要,因为在机器学习模型设计时,必须提供一个单独的测试数据集,不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上。这个数据集不需要很大,能体现出训练的成果即可。
MNIST 数据集的每一个单元都由两部分构成:第一部分是手写数字的图片,命名为“images”。第二部分是该单元的手写数字图片对应的标签,命名为“labels”。训练集和测试集都由这两部分组成。例如训练集的图片时 mnist.train.images,而训练数据集的标签则为 mnist.train.labels。图片的长和宽均为 28 像素点,每张图片总共 28*28=784 个像素,可以用长度为 784 的数字数组表示这张图片。标签总共有 10 种可能(0~9),因此可以使用长度为 10 的数组表示标签。例如:MNIST 数据集中某图片矩阵图如图 2.2 所示:
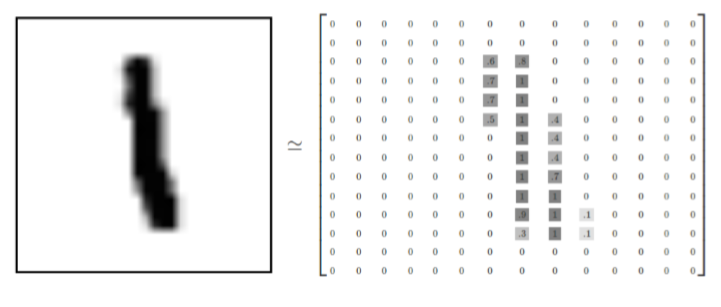
图 2.1 数字“1”矩阵图
将这个数组展开成向量(Vector),在展开时不需要考虑展开的行列顺序,只要保持各个图片采用相同的方式展开即可。从上图可以观察得出:MNIST 数据集的图片就是展开在 784 维向量空间里面的点, 结构并不复杂。
但是展开图片成为一维数组后,会丢失掉图片的二位平面信息,并不是很理想。但好在本文介绍的 Softmax 回归模型和卷积神经网络模型比较简单,并不会利用这些二维信息。因此,在手写数字训练集中,MNIST.train.images 是一个形状为[55000,784]的二维张量。第一维度表示共有 55000 张图片以备训练,这一维的数字就是图片的序列号,可以用第一维数组来索引图片。第二位度表示每个图片有 784 个像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于 0 和 1 之间。
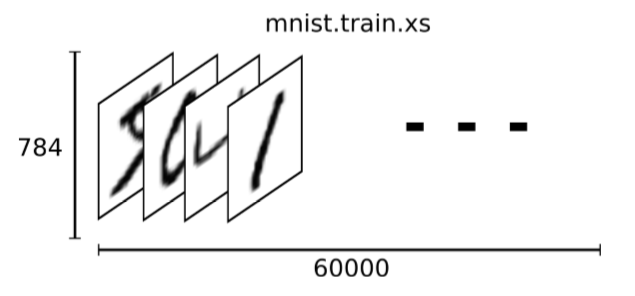
图 2.2 MNIST 数据集的训练图片
相对应的 MNIST 数据集的标签是一个介于 0~9 的数字,用来描述给定图片里表示的数字。除了某一位的数字是 1 以外其余各维度数字都是 0。所以数字 n 将表示成一个只有在第 n+1 维度(因为标签数组是从 0 开始的)数字为 1 的 10 维数组。因此 train.labels 是一个[55000, 10]的二维数组[12]。例如,标签 0 将表示成[1,0,0,0,0,0,0,0,0,0,0]。如下图所示:
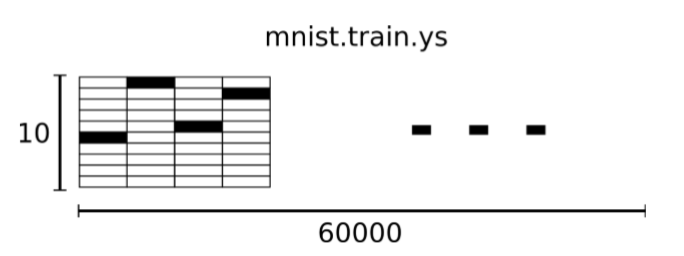
图 2.3 MNIST 数据集的训练标签
三、系统的设计与实现
本章将详细的讲述本文所设计的基于 TensorFlow 框架的手写数字识别系统中所设计的关键技术进行阐述。主要包括 SoftMax Regression 模型的设计与实现、CNN 模型的设计与实现、Web 网页设计、Flask 框架的引用等等。
3.1 Softmax Regression 算法介绍
Softmax Regression 算法原理[13]简单介绍如下:
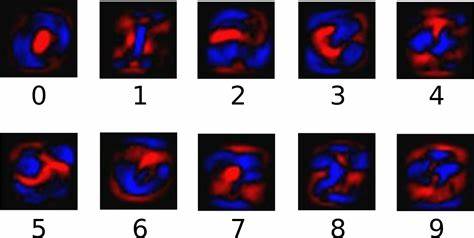
对于输入的手写体数字图像对于不同数字的“证据”加权求和,并将加权求和的结果转为对应数字的概率。如果手写体数字图像中像素很像某个数字,则对该数字求和的权值为正数,越像这个数字,则权值越大。如不像这个数字,则权值为负数,越不像这个数字,则权值的绝对值越大。下图显示了 Softmax Regression 模型学习到的手写体数字图像对于 0~9 共 10 个数字类的权值。蓝色权值为正数,红色权值为负数,颜色越深,权值绝对值越大,如图所示:
3.2 Convolutional Neural Networks 模型模型介绍
深度学习其目的在于建立一个神经网络,用于模拟人脑进行分析学习。机器学习的许多研究成果,都和对大脑认知原理的研究有着密切的联系,尤其是对视听原理方向的研究。日本一个神经生物学家发现了人类视觉器官的分级信息传输方式,也就是说可视皮层是分级的。人类的视觉视觉从原始的自然信号输入开始,像素点透过视网膜,映射到视觉神经,最后大脑皮层的某些感光细胞会判断出所看到的事物的颜色和形状等,最后抽象出眼前的物体是为何物[15]。
因此根据大脑分层逐级认知的这个特点,法国科学家 Yann LeCun 提出卷积神经网络(Convolutional Neural Networ, 以下简称为 CNN)并应用在手写字体识别上。CNN 是一种多层复合的一种神经网络[16],此神经网络使用滤波器提取事物的特征值,再使用卷积核作为特征抽取器,并自动训练特征抽取器。也就是说,神经网络层数、阈值大小、卷积核等参数都需要由卷积神经网络去学习,通过大量的训练数据来不断优化提升。此外,有一个便捷之处在于图像可以直接作为卷积神经网络的输入,不再需要传统图像识别那些复杂的特征提取和数据重建过程。
CNN 的基本架构包含三个主要的层——卷积层、池化层和全连接层[17]。卷积层用来学习输入数据的特征,由很多的卷积核组成。池化层用来降低卷积层输出的特征向量,常用的池化方法有最大池化核平均池化,本文选用的是最大池化。而全连接层将前两层叠加起来后,就可以形成 1 层或者 n 层全连接层,拥有更优的推理能力。卷积神经网络很适用于图像处理方向的机器学习问题。CNN 可以通过一步一步的训练、学习、优化,将数据量庞大的图像识别问题不断降低难度,最终训练这庞大的数据量。
在手写数字识别的应用中,卷积神经网络应用极为广泛,且性能也较为优良。常用的卷积神经网络模型就是 LeNet5 模型,LeNet5 特征能够总结为如下几点:
- 卷积神经网络使用三个层作为一个集合:卷积层,池化层,全连接层
- 使用卷积提取空间特征
- 使用映射到空间均值下采样(subsample)
- 双曲线(tang)或 S 型(sigmoid)形式的非线性
- 使用多层神经网络作为最后一个分类容器
- 为减少运算成本,采用层与层之间的稀疏连接矩阵
本文选用的卷积神经网络就由卷积层(Convolutional layer)、池化层(Pooling layer)和全连接层(Fully connected layer)组成。首先由卷积层和池化层相互配合,组成若干个卷积核,并逐层提取特征值,最终通过若干个全连接层完成手写体数字的分类。
总而言之,卷积神经网络通过卷积操作来模拟特征值的区分,最后通过卷积核的权值共用及池化,来降低卷积神经网络参数的数量级,最后通过传统的神经网络模型完成模式匹配等任务。下面就来介绍一下 CNN 的结构以及 CNN 模型如何进行训练。
3.3 Flask 框架
3.3.1 JSON 介绍
JSON 是一种基于 JavaScript 编程语言的数据交换格式。它可以在 Python 和其他语言中使用。主要用于在服务器和 Web 应用程序之间传输数据。
3.3.2 JSON in API
JSON 的主要应用之一是在 Web 应用程序中构建 API。这非常有用,因为它允许开发人员使用支持 JSON 的任何语言在我们的 API 之上构建。大多数现代编程语言都支持 JSON。Flask 提供了 jsonify 模块,使我们能够实现在 Python 中构建 Flask 应用程序时返回 JSON 这一目标。
3.3.3 序列化 JSON
计算机处理大量信息后需要进行数据转储。因此,JSON 库公开了 dump()方法,用于将数据写入文件。还有一个 dumps()方法,用于写入 Python 字符串。 根据相当直观的转换,简单的 Python 对象被转换为 JSON。
四、系统测试
为保证手写数字识别系统的正常使用,因此本章节对系统的各个方面进行测试,力求做到运行无误。通过系统测试环节可以直接从用户的角度体验该系统,有助于系统进行更好的完善。
4.1 软件测试介绍
软件测试在程序员开发之后确定软件的质量。此过程涉及评估与产品相关的信息。企业在实施软件测试程序时,可以更有效地执行日常活动。软件测试可帮助企业查明软件中的缺陷并进行适当的更正。软件测试还可以帮助企业发现错误和错误,从而提高整体系统容量和准确性
当应用程序质量良好时,即使按下最大容量,它也会持续更长时间并且能够有效地执行。此外,可以对软件进行配置,使其即使在条件不理想的情况下也能正常运行。系统测试还可以提高整体安全性,但系统测试并不是一个简单的过程。每天都会遇到涉及编码和解码的困难挑战。测试过程是软件开发过程中的一个极其重要的阶段,因为必须对每个小模块进行测试以确保其准确性和有效性。
4.2 QA 介绍
质量保证或质量保证测试是软件开发过程中的重要一步。通过在开发周期的早期发现缺陷,QA 测试将节省时间和金钱。适当的 QA 测试揭示了新开发的软件中的不一致,错误和冗余。这个过程对于确保正在开发的产品能够在现实世界中生存并且在未来几年内具有长寿命至关重要。 QA 测试人员与软件开发生命周期(SDLC)的所有利益相关者和成员进行交互和培养关系,其中包括项目总经理、数据库管理员、软件开发工程师、客户等等。通过这种方式,QA 测试人员可以帮助将所有内容连接在一起,并确保每个阶段都按计划进行。
4.3 系统测试
质量测试是系统开发中极其重要的一个环节,不可或缺。现对本手写数字识别系统测试如下:
- 系统启动测试
打开浏览器,输入网址 http://localhost:5000 或 http://127.0.0.1/ 并回车,即可看到手写数字识别系统的总界面。本系统使用了 Flask 框架,将 HTML 页面放在本地服务器的 5000 窗口中(Flask 默认为 5000 号窗口,运行端口可修改),系统启动界面如图 5.1 所示:
图 5.1 系统启动界面
- 手写数字测试
在左侧的 Canvas 画布的中央部分进行数字绘制,画笔粗为 16px,画布中每一个小方格均为 16px,而手写数字训练集为 28px,因此将画布的长和宽均设定为 16*28=448px。手写数字绘制后,只需将画布的长和宽分别缩小为之前的 1/16 即可。
在画布上绘制数字后,即可在右上方的输入框中看到刚刚绘制的手写数字缩略图,并在右下方给出两种模型的识别率。例如:绘制数字 3 之后,在起笔时打印输出结果,两种模型的识别率分别如下所示。Softmax Regression 模型的对数字 3 的识别率为 0.56,是 10 个数字中的最高概率,对数字 2 的识别概率为 0.314,因此 Softmax Regression 模型认为该手写数字为 3。反观 CNN 模型,对数字 3 的识别概率为 1.00,而其余数字均为 0.00,由此可见,CNN 模型在本次数字识别中,识别率要远远高于 SoftMax Regression 模型。

图 5.2 手写数字测试
- 初始化测试
在识别完一次手写数字之后,点击左下角的 CLEAR 按钮,会调用与该按钮绑定的 main.initialize()函数,对本网页进行初始化操作。初始化操作会将画布、输入框以及结果框全部清零,等待下次手写数字绘制。
图 5.3 初始化操作结果
- 识别失败测试
SoftMax Regression 模型的识别率较低,对 1、8、9 这三个数字的识别率尤其更低。因此,在书写不规范的情况下,很可能会识别出错误的结果。此外,运行的 TensorFlow 版本、数据训练的模型量、还有 Canvas 的转换都对识别率有一定的影响,因此一定概率的识别失败是在所难免的。识别失败的测试如下图所示:

图 5.4 识别失败界面
五、展望与总结
智能图像分析是人工智能领域的一个有吸引力的研究领域,也是目前各种开放研究难题的关键。手写数字识别是该领域内经过充分研究的子区域,涉及学习模型用于区分预先分割的手写数字。手写数字识别是机器学习,模式识别以及人工智能的许多其他学科中最重要的问题之一。过去十年中机器学习方法的主要应用已经确定了有效的符合竞争的决定性系统对于人类的表现而言,其成就远远超过了手工编写的经典人工智能系统,这些系统在光学字符识别技术的开始使用。但是,并非先前已检查过这些特定型号的所有功能。
研究人员在机器学习和数据挖掘方面的一次次伟大尝试已被设计用于实现从数据中近似识别的有效方法。在二十一世纪,手写数字通信有其自己的标准,并且日常生活中的大多数时间被用作对话手段并记录要与个人共享的信息。手写字符识别的挑战之一完全在于手写字符集的变化和失真,因为不同的社区可以使用不同的手写风格,并且控制绘制其识别的脚本的字符的相似模式。
识别可以提取最佳区分特征的数字是数字识别系统领域的主要任务之一。为了定位这些区域,在模式识别中使用了不同类型的区域采样技术。手写字符识别的挑战主要是由于个体写作风格的大变化。因此,鲁棒特征提取对于改善手写字符识别系统的性能非常重要。如今手写数字识别在模式识别系统领域得到了广泛的关注,并在各个领域得到应用。在接下来的日子里,字符识别系统可以作为通过数字化和处理现有纸质文档来开启无纸化环境[18]。
手写数字数据集本质上是模糊的,因为可能并不总是有尖锐而完美的直线。数字识别的主要目标是特征提取是从数据中去除冗余并通过一组数字属性获得单词图像的更有效的实施例。它涉及从图像原始数据中提取大部分基本信息。此外,曲线不一定像印刷字符一样平滑。此外,目标数据集可以绘制成不同的大小和方向,这些方向总是应该以直接或间接的方式写在使用说明书上。因此,通过考虑这些限制,可以开发出有效的手写识别系统。
参考文献
- 基于SSH的手机网站的设计与实现(东北大学 ·陶志刚)
- 手语合成系统的研究与实现(北京邮电大学·陶然)
- 基于CNN的票据手写数字识别系统设计与实现(哈尔滨工程大学·冯涛)
- 门把手式人手生物特征识别系统设计与开发(哈尔滨工业大学·孙伟)
- 基于Django框架的浮云笔记系统的设计与实现(华中科技大学·罗丹)
- 网络流量统计分析系统(吉林大学·石景龙)
- 基于网络爬虫的信息采集分类系统设计与实现(厦门大学·周茜)
- 基于Web的人脸识别系统的研究与实现(中南民族大学·范忠)
- 基于CNN的票据手写数字识别系统设计与实现(哈尔滨工程大学·冯涛)
- 作文句子错误识别系统的设计与实现(北京邮电大学·高甲伟)
- 个性化汉字笔顺智能教学研究及系统开发(湖州师范学院·张彩凤)
- 中学python课程知识图谱构建及应用研究(华中师范大学·黄健)
- 基于文本识别的手写汉字识别平台的设计与实现(中国科学院大学(中国科学院沈阳计算技术研究所)·董春生)
- 基于数字校园的可自动填写表单生成器的设计与实现(东北师范大学·刘鹏)
- 基于Django框架的浮云笔记系统的设计与实现(华中科技大学·罗丹)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头网 ,原文地址:https://bishedaima.com/yuanma/35808.html









