
Python opencv 车牌识别
原理简介
- 车牌字符识别使用的算法是 opencv 的 SVM
- opencv 的 SVM 使用代码来自于 opencv 附带的 sample,StatModel 类和 SVM 类都是 sample 中的代码
-
训练数据文件
svm.dat和svmchinese.dat -
使用
图像边缘和车牌颜色定位车牌,再识别字符

```bash
主函数中初始化车牌识别需要的算法函数,并加载训练数据文件
self.predictor = predict.CardPredictor() self.predictor.train_svm()
lib下算法函数加载训练数据文件
class CardPredictor: def init (self): pass # 加载训练数据文件 def train_svm(self): # 识别英文字母和数字 self.model = SVM(C=1, gamma=0.5) # 识别中文 self.modelchinese = SVM(C=1, gamma=0.5) if os.path.exists("lib/svm.dat"): self.model.load("lib/svm.dat") if os.path.exists("lib/svmchinese.dat"): self.modelchinese.load("lib/svmchinese.dat")
```
```bash
main.py 主函数中车牌识别函数
def pic(self, pic_path):
# 以uint8方式读取 pic_path 放入 img_bgr 中,cv2.IMREAD_COLOR读取彩色照片
img_bgr = img_math.img_read(pic_path)
# 缩小图片 转化成灰度图像 创建20*20的元素为1的矩阵 开操作,并和img重合 基于OTSU的二值化处理 找到图像边缘
# first_img, oldimg 已经处理好的图像文件 原图像文件
first_img, oldimg = self.predictor.img_first_pre(img_bgr)
# 未开启摄像头时显示经过resize的图片
if not self.cameraflag:
self.imgtk = self.get_imgtk(img_bgr)
self.image_ctl.configure(image=self.imgtk)
# 开始进行识别
# img_color_contours形状定位识别 输入 预处理好的图像 原图像
# 排除面积最小的点 进行矩形矫正 转换 分隔字符 分离车牌字符
# return 识别到的字符、定位的车牌图像、车牌颜色
# img_only_color颜色定位识别 输入 预处理好的图像 原图像
# 根据阈值找到对应颜色 认为水平方向,最大的波峰为车牌区域 查找垂直直方图波峰 去掉车牌上下边缘1个像素,避免白边影响阈值判断 分隔字符 分离车牌字符
# return 识别到的字符、定位的车牌图像、车牌颜色
th1 = ThreadWithReturnValue(target=self.predictor.img_color_contours, args=(first_img, oldimg))
th2 = ThreadWithReturnValue(target=self.predictor.img_only_color, args=(oldimg, oldimg, first_img))
th1.start()
th2.start()
r_c, roi_c, color_c = th1.join()
r_color, roi_color, color_color = th2.join()
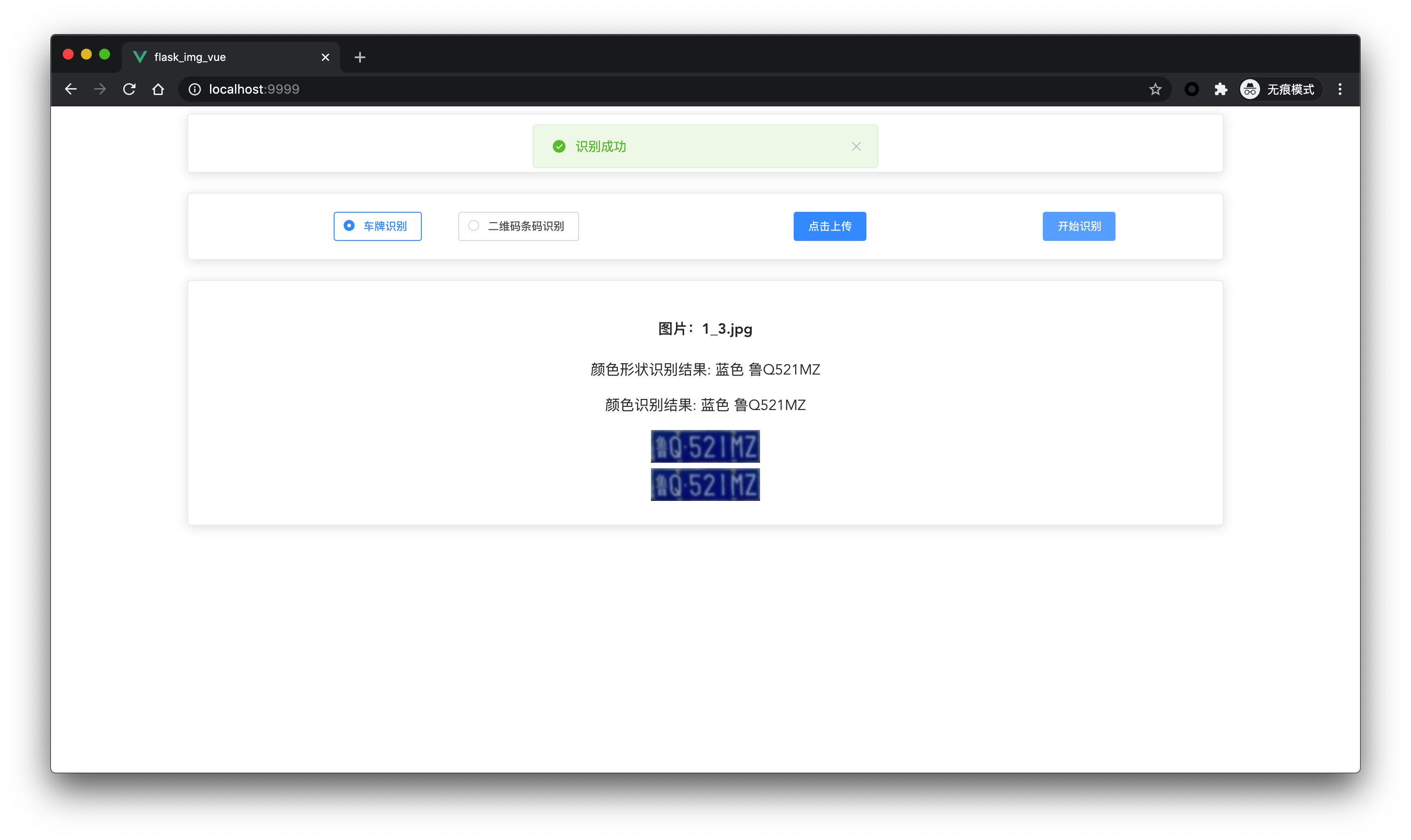
# 显示 识别到的字符、定位的车牌图像、车牌颜色
self.show_roi2(r_color, roi_color, color_color)
self.show_roi1(r_c, roi_c, color_c)
```
一. 车牌图像预处理
- 1.将彩色图像转化为灰度图
- 2.采用 20*20 模版对图像进行高斯模糊来缓解由照相机或其他环境噪声(如果不这么做,我们会得到很多垂直边缘,导致错误检测。)
- 3.使用 Otsu 自适应阈值算法获得图像二值化的阈值,并得到一副二值化图片
- 4.采用闭操作,去除每个垂直边缘线之间的空白空格,并连接所有包含 大量边缘的区域(这步过后,我们将有许多包含车牌的候选区域)
- 5.由于大多数区域并不包含车牌,我们使用轮廓外接矩形的纵横比和区域面积,对这些区域进行区分。
- a.首先使用 findContours 找到外部轮廓
- b.使用 minAreaRect 获得这些轮廓的最小外接矩形,存储在 vector 向量中
- c.使用面积和长宽比阈值,作基本的验证
二. 车牌图像定位
车牌定位的主要工作是从摄入的汽车图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来,供字符分割使用。 因此,牌照区域的确定是影响系统性能的重要因素之一,牌照的定位与否直接影响到字符分割和字符识别的准确率。 目前车牌定位的方法很多,但总的来说可以分为以下 4 类:
- (1)基于颜色的分割方法,这种方法主要利用颜色空间的信息,实现车牌分割,包括彩色边缘算法、颜色距离和相似度算法等;
- (2)基于纹理的分割方法,这种方法主要利用车牌区域水平方向的纹理特征进行分割,包括小波纹理、水平梯度差分纹理等;
- (3)基于边缘检测的分割方法;
- (4)基于数学形态法的分割方法。
为了代码实现上的方便,我采用的是基于边缘检测的分割方法和基于颜色的分割方法。
- 车牌中有大量的垂直边缘,这个特征可以定位车牌。
- 根据阈值找到对应颜色来定位车牌。
三. 车牌图像矩形矫正
因为摄像头和车辆车牌之间的角度有不同的变化, 一般所拍摄的车牌图像都不是理想状态下的矩形, 如果这样将会给后面的字符分割带来不利的影响, 增加了字符分割的难度, 更增加了后续的字符识别的困难, 造成识别率下降。因此, 在字符分割之前, 我们需要进行对倾斜的矩形车牌进行校正。
四. 车牌图像字符分割
要识别车牌字符,前提是先进行车牌字符的正确分割与提取。字符分割的任务是把多列或多行字符图像中的每个字符从整个图像中切割出来成为单个字符。车牌字符的正确分割对字符的识别是很关键的。传统的字符分割算法可以归纳为以下三类:直接分割法、基于识别基础上的分割法、自适应分割线类聚法。直接分割法简单,但它的局限是分割点的确定需要较高的准确性;基于识别基础上的分割法是把识别和分割结合起来,但是需要识别的高准确性,它根据分类和识别的耦合程度又有不同的划分;自适应分割线聚类法是要建立一个分类器,用它来判断图像的每一列是否是分割线,它是根据训练样本来进行自适应学习的神经网络分类器,但对于粘连字符训练困难。也有直接把字符组成的单词当作一个整体来识别的,诸如运用马尔科夫数学模型等方法进行处理,这些算法主要应用于印刷体文本识别。已经定位好的车牌图像
五. 车牌图像字符识别
- 去除固定车牌的铆钉
- 对字符分割的图块使用训练好的 svm 模型进行识别
- 判断最后一个数是否是车牌边缘,假设车牌边缘被认为是 1,1 太细,认为是边缘
参考文献
- 基于J2EE的智能交通信息查询平台的设计与实现(浙江工业大学·赵言)
- 基于J2EE的智能交通信息查询平台的设计与实现(浙江工业大学·赵言)
- 面向汽车热冲压件生产企业的仓储管理系统(华中科技大学·许月元)
- 基于卡口监控数据的车辆轨迹判定系统的设计与实现(华中科技大学·胡玉玲)
- 军队营门智能出入管理系统的设计与实现(华中科技大学·杨强)
- 军队营门智能出入管理系统的设计与实现(华中科技大学·杨强)
- 基于车牌识别的智能矿区车辆管理系统的设计与实现(内蒙古大学·于勤操)
- 基于车牌识别的智能矿区车辆管理系统的设计与实现(内蒙古大学·于勤操)
- 二维码管理系统的设计与实现(西安电子科技大学·李鹏飞)
- 基于车全脸特征的车辆身份识别的设计与实现(西安电子科技大学·杨仕琴)
- 基于J2EE的智能交通信息查询平台的设计与实现(浙江工业大学·赵言)
- 交通违规信息管理系统设计和实现(电子科技大学·吴杉)
- 基于云技术的QR码安全应用体系研究及系统设计(武汉理工大学·王俊杰)
- 小区智能车辆管理系统的设计与实现(华东师范大学·任杰)
- 基于J2EE的智能交通信息查询平台的设计与实现(浙江工业大学·赵言)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头网 ,原文地址:https://bishedaima.com/yuanma/35799.html









