
基于 YOLOv3 的目标检测模型
1. 项目简述
本项目主要面向华为 Atlas 500 进行开发,
在了解本模型前,在理论方面,需对 CNN 等基础神经网络理论有一定了解,同时建议按顺序阅读 YOLO 系列三篇论文:
【1】 You Only Look Once: Unified, Real-Time Object Detection
【2】 YOLO9000: Better, Faster, Stronger
【3】 YOLOv3: An Incremental Improvement
在环境方面,需要安装:
- tensorflow1.x 版本(atlas 500 不支持 2.x 版本, 强烈建议使用 tensorflow1.11,该版本对算子支持度最高,如果使用其他版本的 tensorflow 运行本项目在利用 omg 转化模型时会报错 )
- Atlas 500 DDK,详情可参考《Atlas 500 DDK 安装指南》
华为官方也有提供一些值得阅读参考的文档:
- 《api-matrix-atlas500app》
- 《Atlas 500 应用软件开发指南 01》
- 《Atlas 500 软件开发指导书 02》
- 《Atlas 500 模型转换指导 02》
- 《Atlas 500 用户指南 04》
- 《Atlas 500 算子清单 02》
- 《Atlas 智能边缘管理系统 用户指南 05》
- 《华为 Atlas 500 智能小站 技术白皮书(型号 3000 3010)02》
2. 代码说明
2.1 数据准备及预处理
目标检测对图像的标注主要是标注边界框的信息,可以是边界框的左上角坐标和边界框的宽高长度,而本模型则标记边界框的左上角和右下角坐标,工具是 BBox-Label-Tool,可在 GitHub 下载
下载的时候需要注意,如果需要进行多目标的标注,需要在 branch 选择 multi-class。
下载后,把需要标记的图像放在“image/001”,运行 main.py,在 image Dir 输入 1,点击 load,即可显示图片,通过点击目标的左上角和右下角得到边界框坐标数据,点击下方的 next,即可继续标注下一张图片,要注意的是,图片的后缀必须是 JPEG。
标注完成后,在“labels/001”得到标注信息。
到这里就完成了图像数据的标注,项目中已经提供了少量 VOC 数据集。
接下来就是把标注的数据和原图像整合在一起,利用 tensorflow 进行处理。
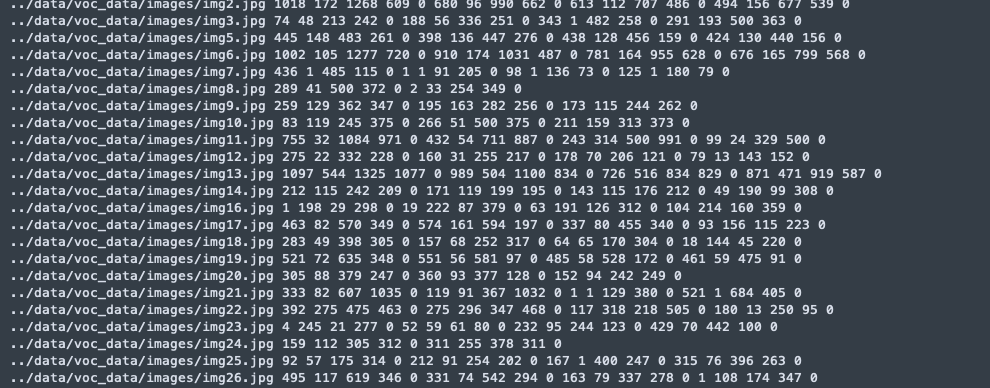
标注完成后,可把图像存放在“data/voc_data/images”,把标注文件放在“data/voc_data/Annotations”(当然你也可以新建一个文件夹放你的数据,因为我这里用的是 voc 数据集所以才命名为 voc_data),然后运行 data/voc_data/readXML.py,得到我们需要的训练集和测试集。这里的目的是把图片在项目中的位置、边界框坐标、分类结果整合在一个 txt 文件里,从而让 tensorflow 做进一步的处理。
因为数据量较大,每次训练都直接读取的话效率就很低,所以 tensorflow 就提供了一种较为高效的数据读取方式 tfrecord,可通过 train/convert_tfrecord.py 基于图像数据生成 tfrecord,注意,这个代码需要运行两遍,第一次是生成 trainset,第二次是生成 testset,通过修改代码中的文件名实现。
到目前为止,我们就完成了数据的预处理,可通过运行“train/show_images_from_tfrecord.py”查看效果,如果看到图片已经包含了边界框、分类名,那就说明预处理成功。
2.2 训练模型
在训练之前,还要检查一下 train/quick_train.py、train/convert_weight.py 中的类别数是否符合你的数据。
另一方面,因为我们其实是在 yolov3 的基础上做 fine tuning,所以需要下载预训练模型,也就是 yolov3.weights,
可直接运行“train/quick_train.py”训练模型,训练之前可修改部分参数,如 shuffle_size、steps、训练集测试集的 batch size 等等。
2.3 训练结果
以下是用一张 Nvidia T4 对大小为 400 的训练集训练了 10000 次后的结果:

主要包括四个部分,第一个是分类的损失,第二个是置信度损失,第三个是边界框坐标损失,第四个是边界框宽高损失,可以看出,模型在分类方面做得不错,但是对于边界框回归就较差了,目前认为原因在于数据不足,且数据多数来自于同一个监控视频,训练场景单一,导致模型泛化能力不足。
除此之外,再来看看模型的召回率(recall)和准确率(precision):

这是训练过程中的截图,主要想说明的是,在训练后期训练集的召回率和准确率都可以接近 1,而对于测试集的准确率也可以接近 1,但召回率却变化很大,通俗来说,假如我们的测试集有 20 个样本,其中有 10 个样本包含目标,我们的模型有时候可以预测出其中的 3 个,有时候可预测出其中的 8 个,但是,它预测的目标 80% 以上都是准确的,很少会把不包含目标的样本预测成包含目标的样本。
从另一个角度来说,可以认为目前的模型特征提取能力较强,可是泛化能力较弱,增大数据量应该可以改善这个现象。
2.4 模型转化
训练好模型,再次运行 train/convert_weight.py,但这次要注意,需要注释掉读取 yolov3.weights 的代码,因为我们需要从已经训练好的 ckpt 文件中读取模型结构和参数,从而转化为 pb 格式:
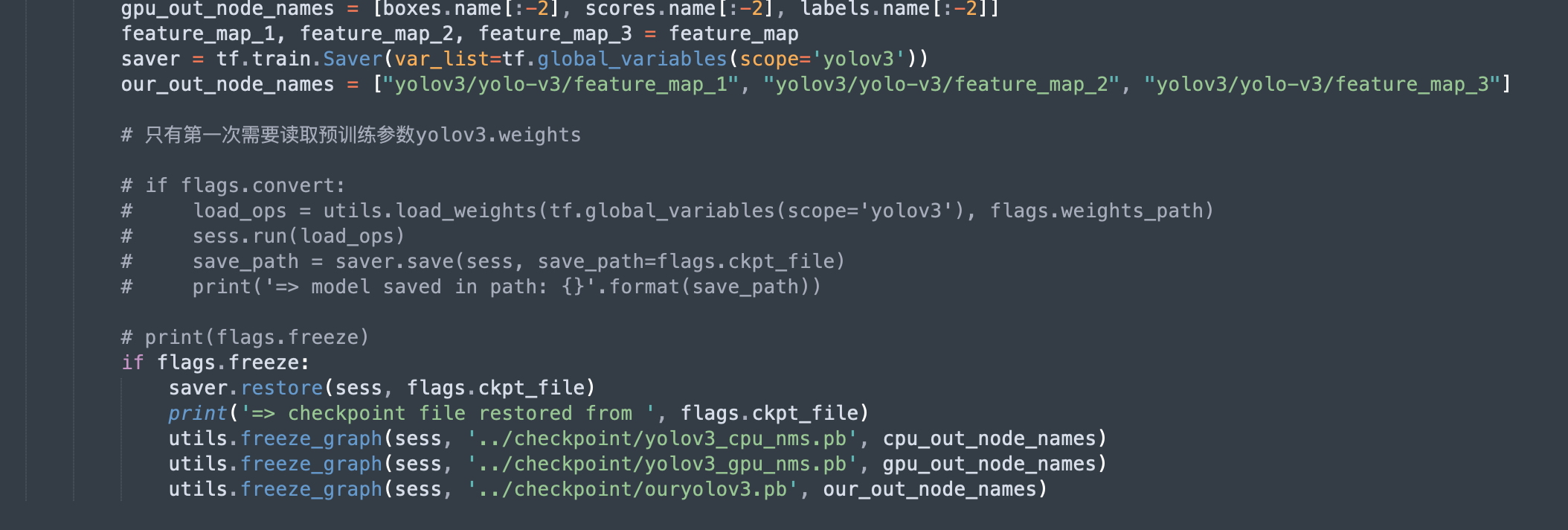
这里保存了三个 pb 文件,前两个是原本有的,最后一个是我自定义输出节点的,这里简单说一下三者的区别,第一个 cpu.pb 是指推理的时候,GPU 通过调用 pb 输出初步结果(边界框坐标、置信度、分类结果),但是不进行 NMS 删除重复的边界框,而是交给 CPU 实现,而 gpu.pb 则是指 GPU 把 NMS 的过程也一并计算了,至于我自己定义的 our.pb,则是只需要 GPU 把 feature map 计算出来就好,后面所有的后处理都交给 CPU 计算。
具体选择在推理时让 GPU 和 CPU 分别计算什么内容,需要根据实际情况判断。
得到 pb 文件之后,我们就可以利用 Atlas500DDK 的 omg 工具转化为 om 格式的模型文件
2.5 编译与运行
得到了 om 文件之后,还需要基于华为的 matrix 框架,对模型进行编译和部署,编译可参考华为的 Sample:
最后附一个在 Atlas500 上运行时的画面

参考文献
- 基于高层次综合的YOLOv3-tiny硬件加速设计与研究(西安电子科技大学·李伟琦)
- 基于跨阶段局部模型及YOLO深度神经网络的目标检测算法(南昌大学·吴文贤)
- 基于改进YOLOv5的航拍图像小目标检测系统的设计与实现(河北科技大学·张艺严)
- 融入坐标注意力的多尺度Logo检测方法研究(西安理工大学·范亚臣)
- 面向自动驾驶场景车路协同的超视距感知验证平台设计与开发(北京邮电大学·刘莹)
- 基于改进YOLOv5的航拍图像小目标检测系统的设计与实现(河北科技大学·张艺严)
- 基于深度学习的线上数据集标注系统设计与实现(河北科技大学·周艺佳)
- 基于改进YOLOv4模型的无人机目标检测算法(辽宁工程技术大学·潘森)
- 面向小样本的目标检测技术研究(桂林电子科技大学·胡振辉)
- 基于深度学习的海上人体目标检测技术研究(天津大学·李东锦)
- 基于Python的非结构化数据检索系统的设计与实现(南京邮电大学·董海兰)
- 基于卷积神经网络的电缆巡检图片目标检测方法研究与应用(上海交通大学·孙鸣赫)
- 基于深度学习的工件检测和定位系统的研究与实现(中国科学院大学(中国科学院沈阳计算技术研究所)·柴斌)
- 基于深度学习的垃圾分类算法研究与应用(浙江理工大学·孙奥)
- 基于高层次综合的YOLOv3-tiny硬件加速设计与研究(西安电子科技大学·李伟琦)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码海岸 ,原文地址:https://bishedaima.com/yuanma/35764.html









