
基于 python+face_recognition+opencv+pyqt5+ 百度 AI 实现的人脸识别、语音播报、语音合成、模拟签到系统
简单介绍
使用 python 3+ 写的,使用 face_recognition(python 开源的人脸识别库)进行人脸识别 ,使用 opencv 2 进行打开显示摄像头图片等,使用 pyqt5 是 ui 界面,使用百度 AI 中的百度语音合成实现语音播报和语音合成,使用对 Excel 的操作以及人脸识别实现模拟签到。
只需要把一张具有人脸信息的图片按名字命名放到相应的文件夹中,在 text.txt 文本中输入详细信息,即可使用。
GitHub 上有演示视频,详细演示了所能实现的功能
学习 python 不久,很多知识都是网上找的,做的也比较匆忙,所以配置什么的直接使用我当时参考的链接。
需要的配置
windows 下
1.首先安装 python3+
然后装 pycharm (推荐) 设置 字体 风格
https://blog.csdn.net/vernice/article/details/50934869 https://www.cnblogs.com/Will-guo/p/6321828.html 对 pycharm 的一些配置
2.安装 opencv
https://jingyan.baidu.com/article/e75aca8503c548142fdac660.html 按链接的操作做 就行
确保电脑有 pip(python3 会预装) pip install opencv-python 会自己安装 cv2 和 numpy 模块 可以使用 cmd 中 python-import cv2 再次 import numpy 没提示错误就说明装好了
3.安装 face_recognition
使用 pip install 下载不了需要安装 dlib
https://my.oschina.net/u/2428854/blog/1797473 使用这个链接 按照步骤操作
首先要装 vs2015 然后装 boost、 cmake 、 dlib、最后再装 face_recognition
比较费时间 电脑上有下载好的 D:\张文豪\资源\软件 vs2015 E:\人脸识别\文件\安装 face_recognition 这里面是需要用到的 boost cmake dlib
https://blog.csdn.net/qq_15192373/article/details/78623741 可以参考这个 python3.6 以上安装 face_recogntion 就会很简单
4.安装 pyqt5
对 pyqt5 和 pycharm 进行连接
https://blog.csdn.net/u013044310/article/details/80777840 安装 Anaconda 我装 的是 3-4.40 版本 里面有很多关于 python 的库 其中就包括 pyqt5 和 qtdesigner
然后需要将他们配置到 pycharm 中 便于使用
5.使用百度语音合成模块
申请百度账号进入百度 ai 创建应用 获取 appid API key 等 语音合成代码里面要用到
https://ai.baidu.com/tech/speech/tts 百度 ai
6.pip install XXX
有些库需要用到 可能 anaconda 上面并没有 需要自己使用 pip isntall 进行安装 这是主函数里面用到的一些库
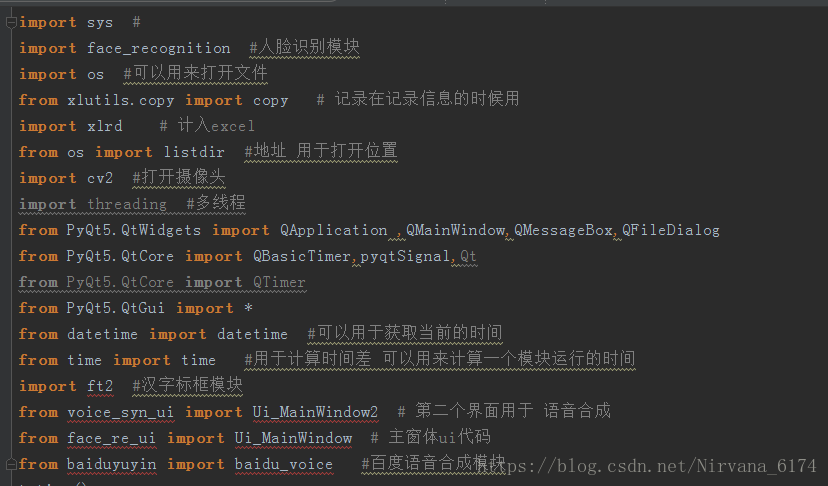
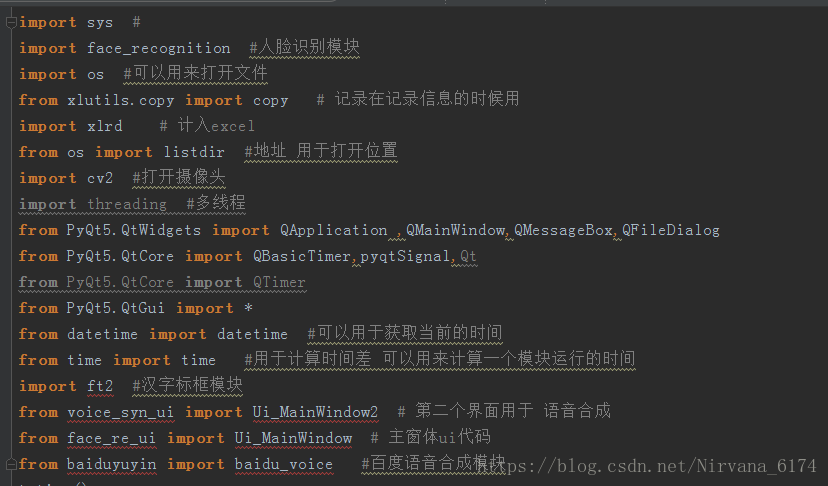
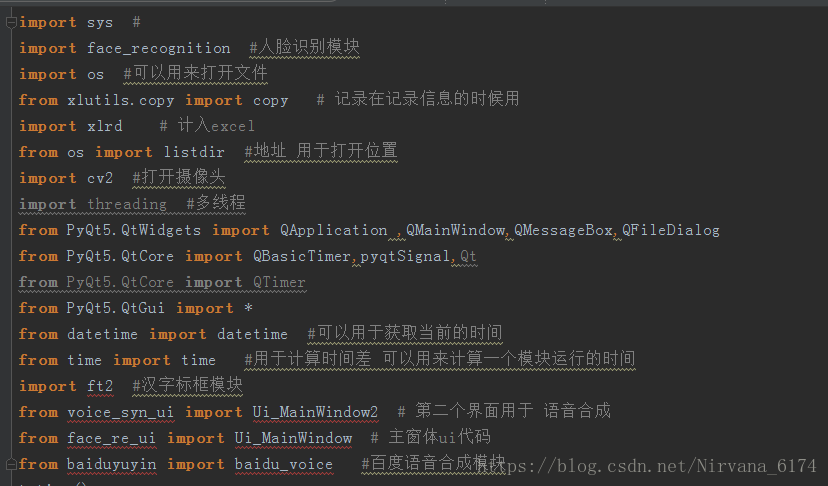
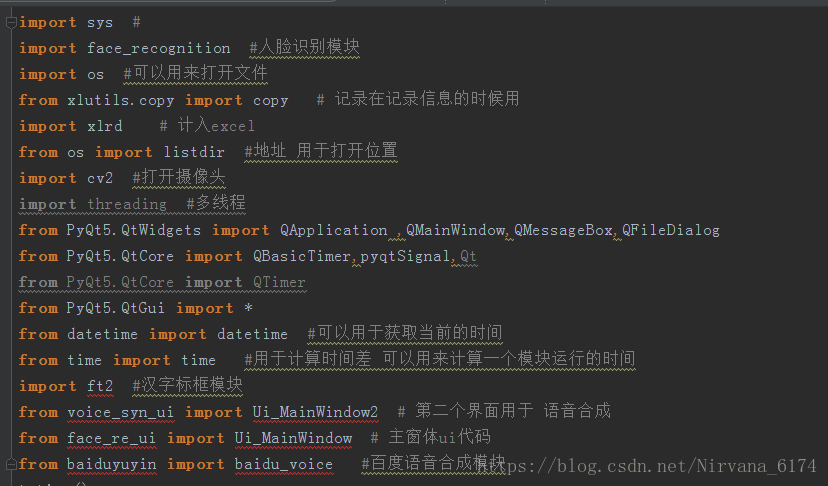
以下几个库需要试一下电脑上是否有 可以使用 win+r--cmd--python--import XXX 如果没有提示错误就说明已经安装了 XXX
baidu-aip 百度 AI 的模块 语音合成需要用
xlrd,xlwt,xlutils (三个是分开的)操作 Excel 读 写 结合读写
threading 使用多线程
time 时间库
datatime 关于时间的库
后三个不一定需要安装 安装之前试一试
功能介绍
文件
ft2.py (对汉字实现转码 opencv 的 puttxt 不支持汉字需要转码)
baiduyuyin.py 这个是语音合成模块使用的是百度 ai 的语音合成其中的 API-KEY 等信息需要去百度注册获得
voice_syn_ui.py 是语音合成的一个界面,只是一个小框
face_re_ui.py 是主界面 里面包括一些按钮和 lable 进度条等主界面信息
openui.py 是主程序 几乎所有这个项目能实现的功能都在这里 photo 文件夹用来放需要照片(需注意照片清晰度太低会识别不出人脸会报错)
video_screenshot 是用来放拍照的照片
Amg.jpg 是头像 face3.jpg 是背景
mysh.ttf 是一个字体文件 ft2.py 需要用到
text.txt 是用来放个人的详细信息*(需要注意这里个人信息的格式按照原格式放,不然会读不出来)
data.xls 是用来记录被摄像头识别出的人(有时间 事件可以按需求修改)
1.主界面
使用 pyqt5 构建,9 个按钮 一个进度条 还有隐藏的 7 个 lable 显示信息 里面多次使用布局 为更加美观多次很多的矩形都使用黄金比例构建
实现添加背景 添加头像 改变按钮颜色等功能
详细代码看 face_re_ui.py
2 打开摄像头
由于这个项目是基于实验室需要所做,所以在打开摄像头按钮处有三个,我所使用的摄像头是海康威视的,与我电脑在同一局域网使用的是 rtsp 地址进行访问,对于摄像头也需要一些配置,为处理更快需要降低帧率分辨率 等。如果是在笔记本上使用把 self.source 改成 0, 同时下面使用到 source 的人脸识别 语音播报 录入信息到 Excel 模块也需要把对 source 的判断删掉 到主界面把按钮改一下就好 (修改中如有问题可以联系)打开摄像头会有两到三秒的延迟(不同电脑可能会不同)
使用 video_source(self,num) 该函数用于连接按钮并根据按钮提供 source 即摄像头的 rtsp 地址 里面进行判断之后
传入下一个函数 btn_open_cam_click(self,num) 这个函数用来判断摄像头的状态,这个函数里面还有一些对摄像头是否打开的判断来修改按钮,如果没被打开就执行下一个函数 show_camera(self) 这个是打开摄像头显示画面的函数,里面也包含了进行人脸识别的函数
其中由于这个是在 ui 上的 lable 显示摄像头画面,opencv 读取图片的样式,不能通过 Qlabel 进行显示,需要转换为 Qimage QImage(uchar * data, int width,在代码 140 行左右。
3 拍照
拍照时打开摄像头以及进行人脸识别时都可以进行的,会弹出一个确定的提示框,由于学 python 不是太好多线程还没学好,这里并不是多线程,点击拍照的时候视频会停。(有时间去好好学学多线程再进行修改)照片会以时间命名,放到 video_screenshot 文件夹中。
代码在 photo_face(self) 函数中,前提是摄像头打开的状况下。把当前的一帧图像获取出来并以时间命名(获取时间转换成字符串)
4 人脸识别
语音播报和记录人脸信息都是基于人脸识别进行的,首先有个进度条 progressbarr_move(self);timerEvent(self, e)两个函数,其次使用的是 python 的一个库 face_recognition 进行识别,使用 opencv 打开,人脸识别模块中,首先加载图像,图像在一个 photo 文件夹中,获取 face_encoding 脸部信息,如果图像没有人脸信息此时会报错,然后会进入处理视频画面的 while 循环 对每帧图像进行处理,当找到人脸的时候开始进行匹配,会把每帧图像找到的人记录下来,放到一个集合中去,调用这个函数 show_picture(self)在人脸识别的右边显示 识别出来人的详细信息姓名年龄等,这些信息是提前录入的,再使用 write_record(self):函数,进行对每次获取的人处理记录到一个 Excel 中去,然后再进行对人脸进行标框显示汉字 226 行左右,这部分是核心功能,代码量比较大,涉及到的东西用到的知识也是比较多,也有部分原因是我 python 学的不是很精,一些代码处理的不够短小。
进度条是一个假的进度条并不是能够显示真正的进度,而是对时间的处理对值的一些限定判断从而实现类似进度条的效果。
获取文件夹中人脸信息部分,使用对字符串的处理能够实现,自己提取出名字放入集合,使用循环遍历文件夹中的照片人脸信息。
show_picture(self)函数中从 text.txt 文件中提取出来每个人的信息,进行和从图像中找到的人脸进行匹配,匹配成功的会在右侧 lable 显示那个人的照片和详细信息,显示信息和显示图片的 lable 是独立的但是在调用的时候是一块调用显示,结束之后有一个 qingping()函数进行清屏,但是此处有个 bug,当存在多个人脸时显示详细信息关闭人脸识别会存在一张或两张照片还没能解决。
write_record(self):函数能够把摄像头看到的人脸都记录到表格中去,从而能够达到模拟签到,由于每帧获取到的人脸可能会不同,所以需要对集合 元祖的处理达到记录的人脸不重复不遗漏。然后还有对 Excel 的操作,打开读写的操作使用 xlutils.copy 库,具体对 Excel 的写入看代码。
人脸标框汉字显示,人脸标框是使用 opencv 实现,汉字显示名字是使用了 ft2 这个转码的文件实现,因为 opencv 的 puttxt 不支持汉字输入,然后再进行 opencv 呈现到 lable 的一些转换.
5 语音合成 语音播报
语音合成代码在 baiduyuyin.py 使用的是百度 ai 的语音合成模块。这个需要到百度 AI 上面注册创建一个活动,获取 APP-ID 等信息用于验证,这个地方电脑需要联网,用于验证信息的正确性。
Openui.py 中语音合成是第二个 ui 界面,一个输入框两个按钮,输入信息到输入框点击合成,会获取到输入的信息并调用语音合成模块生成音频打开音频,点击关闭,会关闭页面同时结束播放音频的软件。(播放音频我这里使用的是系统打开音频,推荐软件 potplayer)
语音播报是一个单独的按钮,会把出现过摄像头的人的姓名都以语音合成的形式播放出来,使用到的集合跟录入到 Excel 中的集合类似。
6 录入信息
这里点击录入信息按钮,会打开文件打开框,直接打开的是照片的文件夹,返回上一级找到 text.txt 是放详细信息的文本。该项目录入信息只要放入该人的照片到 photo 文件夹中以人名命名图片后缀为 jpg,详细信息放到 text.txt 文本,并按原格式放入(当时学的 python 还没学到文件处理那块,所以用的是一种很麻烦的方法放信息)
7 查看记录
在人脸识别模块中记录下来的识别出的人的信息放集合中,write_record(self)函数中有详细的代码,对集合的处理保证获取到的信息不会重复,不会遗漏。里面有对 Excel 的操作实现写入数据,实际使用的不是直接在原文件上面写而是把原文件的信息复制下来新建一个文件名一样的文件复制到里面,再向这个新文件里面写入数据。
目前存在的漏洞:记录信息那块不是很完善,逻辑错误会尽快改掉;显示详细信息那块 lable 上的照片删不掉目前还没找到解决办法,应该尝试换种清理 lable 的方法;代码里面如果操作失误没有相关的提示信息(因为这个很多地方都需要完善需要去考虑)
写这个代码的时候 python 学的还不是很好,使用到的一些语句以及方法都不是很好,需要去完善,还会更新,下一步可能会使用 face++ 的人脸识别模块,face_recognition 不是很稳定
参考文献
- 基于人脸识别的相册管理系统(上海交通大学·田华伟)
- 智能外呼平台系统的设计与实现(北京交通大学·何怡家)
- 人才招聘系统的设计与实现(南昌大学·周新卫)
- 基于身份认证的呼叫中心系统的设计与实现(电子科技大学·朱建奇)
- 基于人脸聚类的图片管理系统的设计与实现(首都经济贸易大学·王子涛)
- 手语合成系统的研究与实现(北京邮电大学·陶然)
- 基于稀疏表示的人脸识别研究(五邑大学·王勇)
- 基于web的人脸识别登陆和管理系统设计与实现(郑州大学·王哲)
- 基于人脸跟踪的视频共享网站的设计与实现(中山大学·曾旭华)
- 人脸识别算法及其在视频剪切中的应用研究(辽宁科技大学·刘旭)
- 人才招聘系统的设计与实现(南昌大学·周新卫)
- 基于人脸识别的摄影协会综合管理系统设计与实现(哈尔滨工程大学·李世强)
- 基于语音的位置服务系统的设计与实现(东北大学·李想)
- 人脸识别算法及其在视频剪切中的应用研究(辽宁科技大学·刘旭)
- 面向微服务架构的会议管理系统的设计与实现(华中科技大学·王晴)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈 ,原文地址:https://bishedaima.com/yuanma/35712.html









