基于python实现的图像分类
1.项目简介
这篇文章主要介绍了 图像分类的 inference,其中会着重介绍
ResNet
。
2.模型概览
在
torchvision.model
中,有很多封装好的模型。
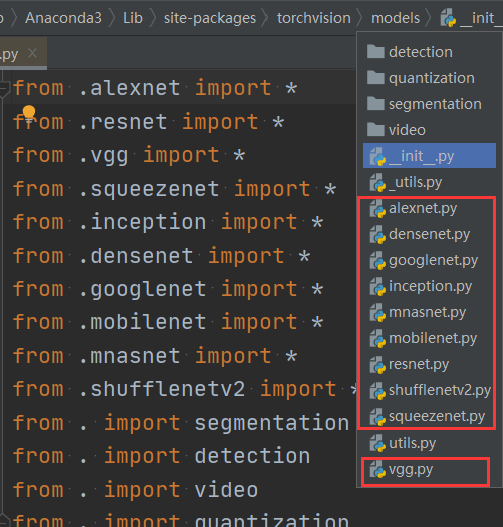
可以分类 3 类:
- 经典网络
- alexnet
- vgg
- resnet
- inception
- densenet
- googlenet
- 轻量化网络
- squeezenet
- mobilenet
- shufflenetv2
- 自动神经结构搜索方法的网络
- mnasnet
3.ResNet18 使用
以
ResNet 18
为例。
首先加载训练好的模型参数:
``` resnet18 = models.resnet18()
修改全连接层的输出
num_ftrs = resnet18.fc.in_features resnet18.fc = nn.Linear(num_ftrs, 2)
加载模型参数
checkpoint = torch.load(m_path) resnet18.load_state_dict(checkpoint['model_state_dict']) ```
然后比较重要的是把模型放到 GPU 上,并且转换到
eval
模式:
resnet18.to(device)
resnet18.eval()
在 inference 时,主要流程如下:
-
代码要放在
with torch.no_grad():下。torch.no_grad()会关闭反向传播,可以减少内存、加快速度。 -
根据路径读取图片,把图片转换为 tensor,然后使用
unsqueeze_(0)方法把形状扩大为 $B \times C \times H \times W$,再把 tensor 放到 GPU 上 。 -
模型的输出数据
outputs的形状是 $1 \times 2$,表示batch_size为 1,分类数量为 2。torch.max(outputs,0)是返回outputs中 每一列 最大的元素和索引,torch.max(outputs,1)是返回outputs中 每一行 最大的元素和索引。
这里使用
_, pred_int = torch.max(outputs.data, 1)
返回最大元素的索引,然后根据索引获得 label:
pred_str = classes[int(pred_int)]
。
关键代码如下:
``` with torch.no_grad(): for idx, img_name in enumerate(img_names):
path_img = os.path.join(img_dir, img_name)
# step 1/4 : path --> img
img_rgb = Image.open(path_img).convert('RGB')
# step 2/4 : img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(device)
# step 3/4 : tensor --> vector
outputs = resnet18(img_tensor)
# step 4/4 : get label
_, pred_int = torch.max(outputs.data, 1)
pred_str = classes[int(pred_int)]
```
全部代码如下所示:
``` import os import time import torch.nn as nn import torch import torchvision.transforms as transforms from PIL import Image from matplotlib import pyplot as plt import torchvision.models as models import enviroments BASE_DIR = os.path.dirname(os.path.abspath( file ))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
config
vis = True
vis = False
vis_row = 4
norm_mean = [0.485, 0.456, 0.406] norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std), ])
classes = ["ants", "bees"]
def img_transform(img_rgb, transform=None): """ 将数据转换为模型读取的形式 :param img_rgb: PIL Image :param transform: torchvision.transform :return: tensor """
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def get_img_name(img_dir, format="jpg"): """ 获取文件夹下format格式的文件名 :param img_dir: str :param format: str :return: list """ file_names = os.listdir(img_dir) # 使用 list(filter(lambda())) 筛选出 jpg 后缀的文件 img_names = list(filter(lambda x: x.endswith(format), file_names))
if len(img_names) < 1:
raise ValueError("{}下找不到{}格式数据".format(img_dir, format))
return img_names
def get_model(m_path, vis_model=False):
resnet18 = models.resnet18()
# 修改全连接层的输出
num_ftrs = resnet18.fc.in_features
resnet18.fc = nn.Linear(num_ftrs, 2)
# 加载模型参数
checkpoint = torch.load(m_path)
resnet18.load_state_dict(checkpoint['model_state_dict'])
if vis_model:
from torchsummary import summary
summary(resnet18, input_size=(3, 224, 224), device="cpu")
return resnet18
if name == " main ":
img_dir = os.path.join(enviroments.hymenoptera_data_dir,"val/bees")
model_path = "./checkpoint_14_epoch.pkl"
time_total = 0
img_list, img_pred = list(), list()
# 1. data
img_names = get_img_name(img_dir)
num_img = len(img_names)
# 2. model
resnet18 = get_model(model_path, True)
resnet18.to(device)
resnet18.eval()
with torch.no_grad():
for idx, img_name in enumerate(img_names):
path_img = os.path.join(img_dir, img_name)
# step 1/4 : path --> img
img_rgb = Image.open(path_img).convert('RGB')
# step 2/4 : img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(device)
# step 3/4 : tensor --> vector
time_tic = time.time()
outputs = resnet18(img_tensor)
time_toc = time.time()
# step 4/4 : visualization
_, pred_int = torch.max(outputs.data, 1)
pred_str = classes[int(pred_int)]
if vis:
img_list.append(img_rgb)
img_pred.append(pred_str)
if (idx+1) % (vis_row*vis_row) == 0 or num_img == idx+1:
for i in range(len(img_list)):
plt.subplot(vis_row, vis_row, i+1).imshow(img_list[i])
plt.title("predict:{}".format(img_pred[i]))
plt.show()
plt.close()
img_list, img_pred = list(), list()
time_s = time_toc-time_tic
time_total += time_s
print('{:d}/{:d}: {} {:.3f}s '.format(idx + 1, num_img, img_name, time_s))
print("\ndevice:{} total time:{:.1f}s mean:{:.3f}s".
format(device, time_total, time_total/num_img))
if torch.cuda.is_available():
print("GPU name:{}".format(torch.cuda.get_device_name()))
```
总结一下 inference 阶段需要注意的事项:
- 确保 model 处于 eval 状态,而非 trainning 状态
- 设置 torch.no_grad(),减少内存消耗,加快运算速度
- 数据预处理需要保持一致,比如 RGB 或者 rBGR
4.残差连接
以 ResNet 为例:
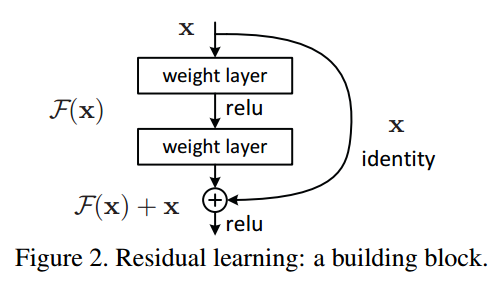
一个残差块有2条路径 $F(x)$ 和 $x$,$F(x)$ 路径拟合残差,不妨称之为残差路径;$x$ 路径为
identity mapping
恒等映射,称之为
shortcut
。图中的⊕为
element-wise addition
,要求参与运算的 $F(x)$ 和 $x$ 的尺寸要相同。
shortcut
路径大致可以分成 2 种,取决于残差路径是否改变了
feature map
数量和尺寸。
-
一种是将输入
x原封不动地输出。 -
另一种则需要经过 $1×1$ 卷积来升维或者降采样,主要作用是将输出与 $F(x)$ 路径的输出保持
shape一致,对网络性能的提升并不明显。
两种结构如下图所示:
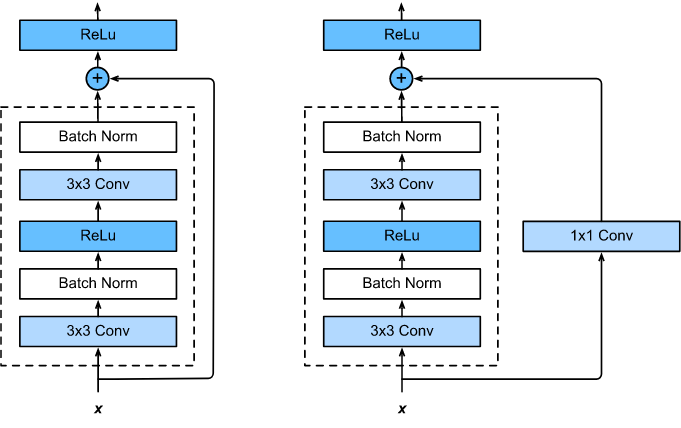
ResNet
中,使用了上面 2 种
shortcut
。
5.网络结构
ResNet 有很多变种,包括
ResNet 18
、
ResNet 34
、
ResNet 50
、
ResNet 101
、
ResNet 152
,网络结构对比如下:
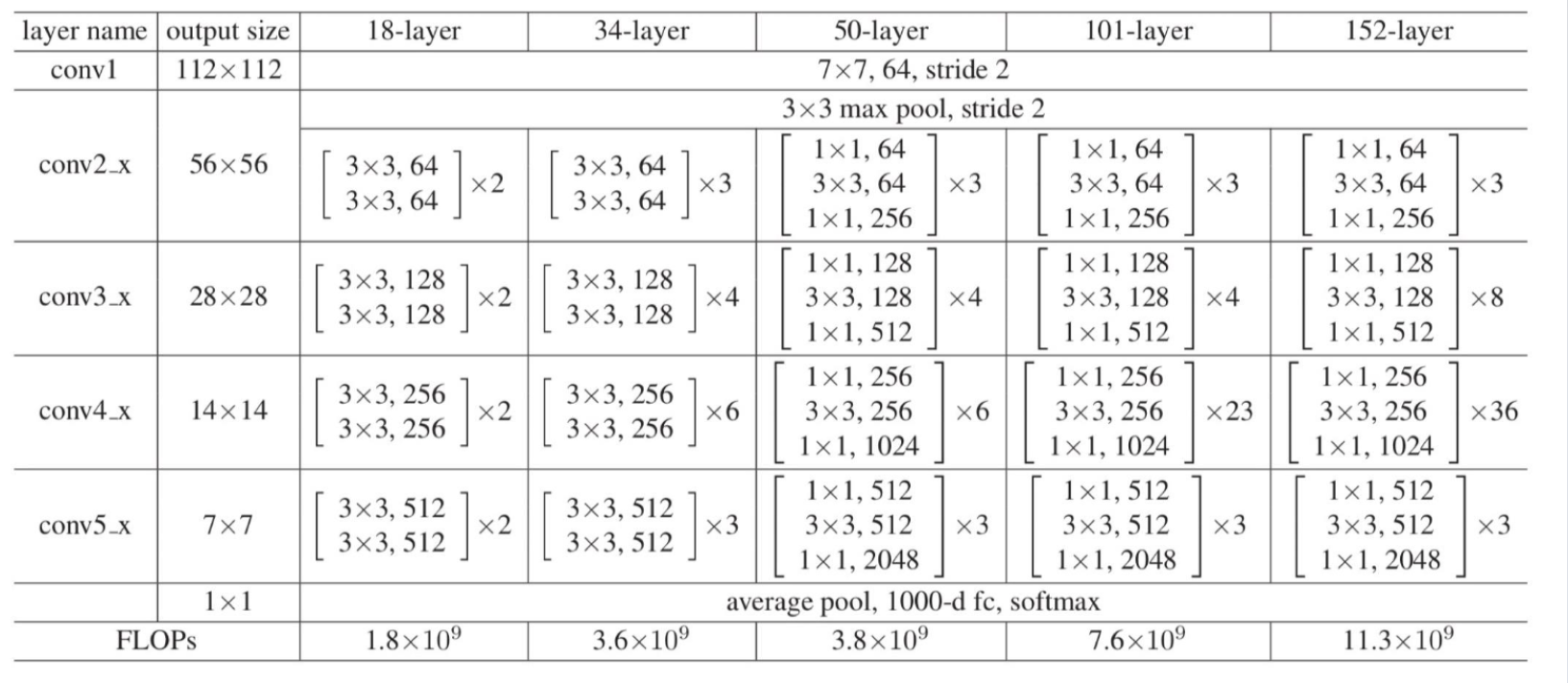
ResNet
的各个变种,数据处理大致流程如下:
- 输入的图片形状是 $3 \times 224 \times 224$。
-
图片经过
conv1层,输出图片大小为 $ 64 \times 112 \times 112$。 -
图片经过
max pool层,输出图片大小为 $ 64 \times 56 \times 56 $。 -
图片经过
conv2层,输出图片大小为 $ 64 \times 56 \times 56$。 (注意,图片经过这个layer, 大小是不变的) -
图片经过
conv3层,输出图片大小为 $ 128 \times 28 \times 28$。 -
图片经过
conv4层,输出图片大小为 $ 256 \times 14 \times 14$。 -
图片经过
conv5层,输出图片大小为 $ 512 \times 7 \times 7$。 -
图片经过
avg pool层,输出大小为 $ 512 \times 1 \times 1$。 -
图片经过
fc层,输出维度为 $ num_classes$,表示每个分类的logits。
下面,我们称每个
conv
层为一个
layer
(第一个
conv
层就是一个卷积层,因此第一个
conv
层除外)。
其中
ResNet 18
、
ResNet 34
的每个
layer
由多个
BasicBlock
组成,只是每个
layer
里堆叠的
BasicBlock
数量不一样。
而
ResNet 50
、
ResNet 101
、
ResNet 152
的每个
layer
由多个
Bottleneck
组成,只是每个
layer
里堆叠的
Bottleneck
数量不一样。
6.源码分析
我们来看看各个
ResNet
的源码,首先从构造函数开始。
6.1ResNet
ResNet 18
构造函数
resnet18
的构造函数如下。
[2, 2, 2, 2]
表示有 4 个
layer
,每个 layer 中有 2 个
BasicBlock
。
conv1
为 1 层,
conv2
、
conv3
、
conv4
、
conv5
均为 4 层(每个
layer
有 2 个
BasicBlock
,每个
BasicBlock
有 2 个卷积层),总共为 16 层,最后一层全连接层,$ 总层数 = 1+ 4 \times 4 + 1 = 18$,依此类推。
``python
def resnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
"Deep Residual Learning for Image Recognition"
https://arxiv.org/pdf/1512.03385.pdf
`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
```
ResNet 34
resnet 34
的构造函数如下。
[3, 4, 6, 3]
表示有 4 个
layer
,每个
layer
的
BasicBlock
数量分别为 3, 4, 6, 3。
``python
def resnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
"Deep Residual Learning for Image Recognition"
https://arxiv.org/pdf/1512.03385.pdf
`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
```
ResNet 50
resnet 34
的构造函数如下。
[3, 4, 6, 3]
表示有 4 个
layer
,每个
layer
的
Bottleneck
数量分别为 3, 4, 6, 3。
``python
def resnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
"Deep Residual Learning for Image Recognition"
https://arxiv.org/pdf/1512.03385.pdf
`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
```
依此类推,
ResNet 101
和
ResNet 152
也是由多个
layer
组成的。
_resnet()
上面所有的构造函数中,都调用了
_resnet()
方法来创建网络,下面来看看
_resnet()
方法。
python
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
# 加载预训练好的模型参数
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
可以看到,在
_resnet()
方法中,又调用了
ResNet()
方法创建模型,然后加载训练好的模型参数。
ResNet()
首先来看
ResNet()
方法的构造函数。
构造函数
构造函数的重要参数如下:
-
block:每个
layer里面使用的block,可以是BasicBlockBottleneck。 - num_classes:分类数量,用于构建最后的全连接层。
-
layers:一个 list,表示每个
layer中block的数量。
构造函数的主要流程如下:
-
判断是否传入
norm_layer,没有传入,则使用BatchNorm2d。 -
判断是否传入孔洞卷积参数
replace_stride_with_dilation,如果不指定,则赋值为[False, False, False],表示不使用孔洞卷积。 -
读取分组卷积的参数
groups,width_per_group。 -
然后真正开始构造网络。
-
conv1层的结构是Conv2d -> norm_layer -> ReLU。
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
-
conv2层的代码如下,对应于layer1,这个layer的参数没有指定stride,默认stride=1,因此这个layer不会改变图片大小:
self.layer1 = self._make_layer(block, 64, layers[0])
-
conv3层的代码如下,对应于layer2(注意这个layer指定stride=2,会降采样,详情看下面_make_layer的讲解):
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
-
conv4层的代码如下,对应于layer3(注意这个layer指定stride=2,会降采样,详情看下面_make_layer的讲解):
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
-
conv5层的代码如下,对应于layer4(注意这个layer指定stride=2,会降采样,详情看下面_make_layer的讲解):
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
-
接着是
AdaptiveAvgPool2d层和fc层。 -
最后是网络参数的初始:
-
卷积层采用
kaiming_normal_()初始化方法。 -
bn层和GroupNorm层初始化为weight=1,bias=0。 -
其中每个
BasicBlock和Bottleneck的最后一层bn的weight=0,可以提升准确率 0.2~0.3%。
完整的构造函数代码如下:
```python def init (self, block, layers, num_classes=1000, zero_init_residual=False, groups=1, width_per_group=64, replace_stride_with_dilation=None, norm_layer=None): super(ResNet, self). init () # 使用 bn 层 if norm_layer is None: norm_layer = nn.BatchNorm2d self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
# 对应于 conv1
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
# 对应于 conv2
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
# 对应于 conv3
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
对应于 conv4
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
对应于 conv5
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
```
forward()
在
ResNet
中,网络经过层层封装,因此
forward()
方法非常简洁。
数据变换大致流程如下:
- 输入的图片形状是 $3 \times 224 \times 224$。
-
图片经过
conv1层,输出图片大小为 $ 64 \times 112 \times 112$。 -
图片经过
max pool层,输出图片大小为 $ 64 \times 56 \times 56 $。 - 对于ResNet 18、ResNet 34(使用BasicBlock):
-
图片经过
conv2层,对应于layer1,输出图片大小为 $ 64 \times 56 \times 56$。 (注意,图片经过这个layer, 大小是不变的) -
图片经过
conv3层,对应于layer2,输出图片大小为 $ 128 \times 28 \times 28$。 -
图片经过
conv4层,对应于layer3,输出图片大小为 $ 256 \times 14 \times 14$。 -
图片经过
conv5层,对应于layer4,输出图片大小为 $ 512 \times 7 \times 7$。 -
图片经过
avg pool层,输出大小为 $ 512 \times 1 \times 1$。 - 对于ResNet 50、ResNet 101、ResNet 152(使用Bottleneck):
-
图片经过
conv2层,对应于layer1,输出图片大小为 $ 256 \times 56 \times 56$。 (注意,图片经过这个layer, 大小是不变的) -
图片经过
conv3层,对应于layer2,输出图片大小为 $ 512 \times 28 \times 28$。 -
图片经过
conv4层,对应于layer3,输出图片大小为 $ 1024 \times 14 \times 14$。 -
图片经过
conv5层,对应于layer4,输出图片大小为 $ 2048 \times 7 \times 7$。 -
图片经过
avg pool层,输出大小为 $ 2048 \times 1 \times 1$。 -
图片经过
fc层,输出维度为 $ num_classes$,表示每个分类的logits。
```python def _forward_impl(self, x): # See note [TorchScript super()]
# conv1
# x: [3, 224, 224] -> [64, 112, 112]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# conv2
# x: [64, 112, 112] -> [64, 56, 56]
x = self.maxpool(x)
# x: [64, 56, 56] -> [64, 56, 56]
# x 经过第一个 layer, 大小是不变的
x = self.layer1(x)
# conv3
# x: [64, 56, 56] -> [128, 28, 28]
x = self.layer2(x)
# conv4
# x: [128, 28, 28] -> [256, 14, 14]
x = self.layer3(x)
# conv5
# x: [256, 14, 14] -> [512, 7, 7]
x = self.layer4(x)
# x: [512, 7, 7] -> [512, 1, 1]
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
```
在构造函数中可以看到,上面每个
layer
都是使用
_make_layer()
方法来创建层的,下面来看下
_make_layer()
方法。
_make_layer()
_make_layer()
方法的参数如下:
-
block:每个
layer里面使用的block,可以是BasicBlock,Bottleneck。 - planes:输出的通道数
-
blocks:一个整数,表示该层
layer有多少个block。 -
stride:第一个
block的卷积层的stride,默认为 1。注意,只有在每个layer的第一个block的第一个卷积层使用该参数。 - dilate:是否使用孔洞卷积。
主要流程如下:
-
判断孔洞卷积,计算
previous_dilation参数。 -
判断
stride是否为 1,输入通道和输出通道是否相等。如果这两个条件都不成立,那么表明需要建立一个 1 X 1 的卷积层,来 改变通道数和改变图片大小 。具体是建立downsample层,包括conv1x1 -> norm_layer。 -
建立第一个
block,把downsample传给block作为降采样的层,并且stride也使用传入的stride(stride=2)。 后面我们会分析downsample层在BasicBlock和Bottleneck中,具体是怎么用的 。 -
改变通道数
self.inplanes = planes * block.expansion。 -
在
BasicBlock里,expansion=1,因此这一步 不会改变通道数 。 -
在
Bottleneck里,expansion=4,因此这一步 会改变通道数 。 -
图片经过第一个
block后,就会改变通道数和图片大小。接下来 for 循环添加剩下的block。从第 2 个block起,输入和输出通道数是相等的,因此就不用传入downsample和stride(那么block的stride默认使用 1,下面我们会分析BasicBlock和Bottleneck的源码)。
``` def _make_layer(self, block, planes, blocks, stride=1, dilate=False): norm_layer = self._norm_layer downsample = None previous_dilation = self.dilation if dilate: self.dilation *= stride stride = 1 # 首先判断 stride 是否为1,输入通道和输出通道是否相等。不相等则使用 1 X 1 的卷积改变大小和通道 #作为 downsample # 在 Resnet 中,每层 layer 传入的 stride =2 if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( conv1x1(self.inplanes, planes * block.expansion, stride), norm_layer(planes * block.expansion), )
layers = []
# 然后添加第一个 basic block,把 downsample 传给 BasicBlock 作为降采样的层。
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
# 修改输出的通道数
self.inplanes = planes * block.expansion
# 继续添加这个 layer 里接下来的 BasicBlock
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
```
下面来看
BasicBlock
和
Bottleneck
的源码。
6.2BasicBlock
构造函数
BasicBlock
构造函数的主要参数如下:
- inplanes:输入通道数。
- planes:输出通道数。
-
stride:第一个卷积层的
stride。 -
downsample:从
layer中传入的downsample层。 - groups:分组卷积的分组数,使用 1
- base_width:每组卷积的通道数,使用 64
- dilation:孔洞卷积,为 1,表示不使用 孔洞卷积
主要流程如下:
-
首先判断是否传入了
norm_layer层,如果没有,则使用BatchNorm2d。 -
校验参数:
groups == 1,base_width == 64,dilation == 1。也就是说,在BasicBlock中,不使用孔洞卷积和分组卷积。 -
定义第 1 组
conv3x3 -> norm_layer -> relu,这里使用传入的stride和inplanes。( 如果是layer2,layer3,layer4里的第一个BasicBlock,那么stride=2,这里会降采样和改变通道数 )。 -
定义第 2 组
conv3x3 -> norm_layer -> relu,这里不使用传入的stride(默认为 1),输入通道数和输出通道数使用planes,也就是 不需要降采样和改变通道数 。
```python class BasicBlock(nn.Module): expansion = 1 constants = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
```
forward()
forward()
方法的主要流程如下:
-
x赋值给identity,用于后面的shortcut连接。 -
x经过第 1 组conv3x3 -> norm_layer -> relu,如果是layer2,layer3,layer4里的第一个BasicBlock,那么stride=2,第一个卷积层会降采样。 -
x经过第 1 组conv3x3 -> norm_layer,得到out。 -
如果是
layer2,layer3,layer4里的第一个BasicBlock,那么downsample不为空,会经过downsample层,得到identity。 -
最后将
identity和out相加,经过relu,得到输出。
注意,2 个卷积层都需要经过
relu层,但它们使用的是同一个relu层。
```python def forward(self, x): identity = x # 如果是 layer2,layer3,layer4 里的第一个 BasicBlock,第一个卷积层会降采样 out = self.conv1(x) out = self.bn1(out) out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
```
Bottleneck
构造函数
参数如下:
- inplanes:输入通道数。
- planes:输出通道数。
-
stride:第一个卷积层的
stride。 -
downsample:从
layer中传入的downsample层。 - groups:分组卷积的分组数,使用 1
- base_width:每组卷积的通道数,使用 64
- dilation:孔洞卷积,为 1,表示不使用 孔洞卷积
主要流程如下:
-
首先判断是否传入了
norm_layer层,如果没有,则使用BatchNorm2d。 -
计算
width,等于传入的planes,用于中间的 $ 3 \times 3 $ 卷积。 -
定义第 1 组
conv1x1 -> norm_layer,这里不使用传入的stride,使用width,作用是进行降维,减少通道数。 -
定义第 2 组
conv3x3 -> norm_layer,这里使用传入的stride,输入通道数和输出通道数使用width。( 如果是layer2,layer3,layer4里的第一个Bottleneck,那么stride=2,这里会降采样 )。 -
定义第 3 组
conv1x1 -> norm_layer,这里不使用传入的stride,使用planes * self.expansion,作用是进行升维,增加通道数。
``` class Bottleneck(nn.Module): expansion = 4 constants = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# base_width = 64
# groups =1
# width = planes
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
# 1x1 的卷积是为了降维,减少通道数
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
# 3x3 的卷积是为了改变图片大小,不改变通道数
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
# 1x1 的卷积是为了升维,增加通道数,增加到 planes * 4
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
```
forward()
forward()
方法的主要流程如下:
-
x赋值给identity,用于后面的shortcut连接。 -
x经过第 1 组conv1x1 -> norm_layer -> relu,作用是进行降维,减少通道数。 -
x经过第 2 组conv3x3 -> norm_layer -> relu。如果是layer2,layer3,layer4里的第一个Bottleneck,那么stride=2,第一个卷积层会降采样。 -
x经过第 1 组conv1x1 -> norm_layer -> relu,作用是进行降维,减少通道数。 -
如果是
layer2,layer3,layer4里的第一个Bottleneck,那么downsample不为空,会经过downsample层,得到identity。 -
最后将
identity和out相加,经过relu,得到输出。
注意,3 个卷积层都需要经过
relu层,但它们使用的是同一个relu层。
``` def forward(self, x): identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
```
7.总结
最后,总结一下。
-
BasicBlock中有 1 个 $3 \times 3 $ 卷积层,如果是layer的第一个BasicBlock,那么第一个卷积层的stride=2,作用是进行降采样。 -
Bottleneck中有 2 个 $1 \times 1 $ 卷积层, 1 个 $3 \times 3 $ 卷积层。先经过第 1 个 $1 \times 1 $ 卷积层,进行降维,然后经过 $3 \times 3 $ 卷积层(如果是layer的第一个Bottleneck,那么 $3 \times 3 $ 卷积层的stride=2,作用是进行降采样),最后经过 $1 \times 1 $ 卷积层,进行升维 。
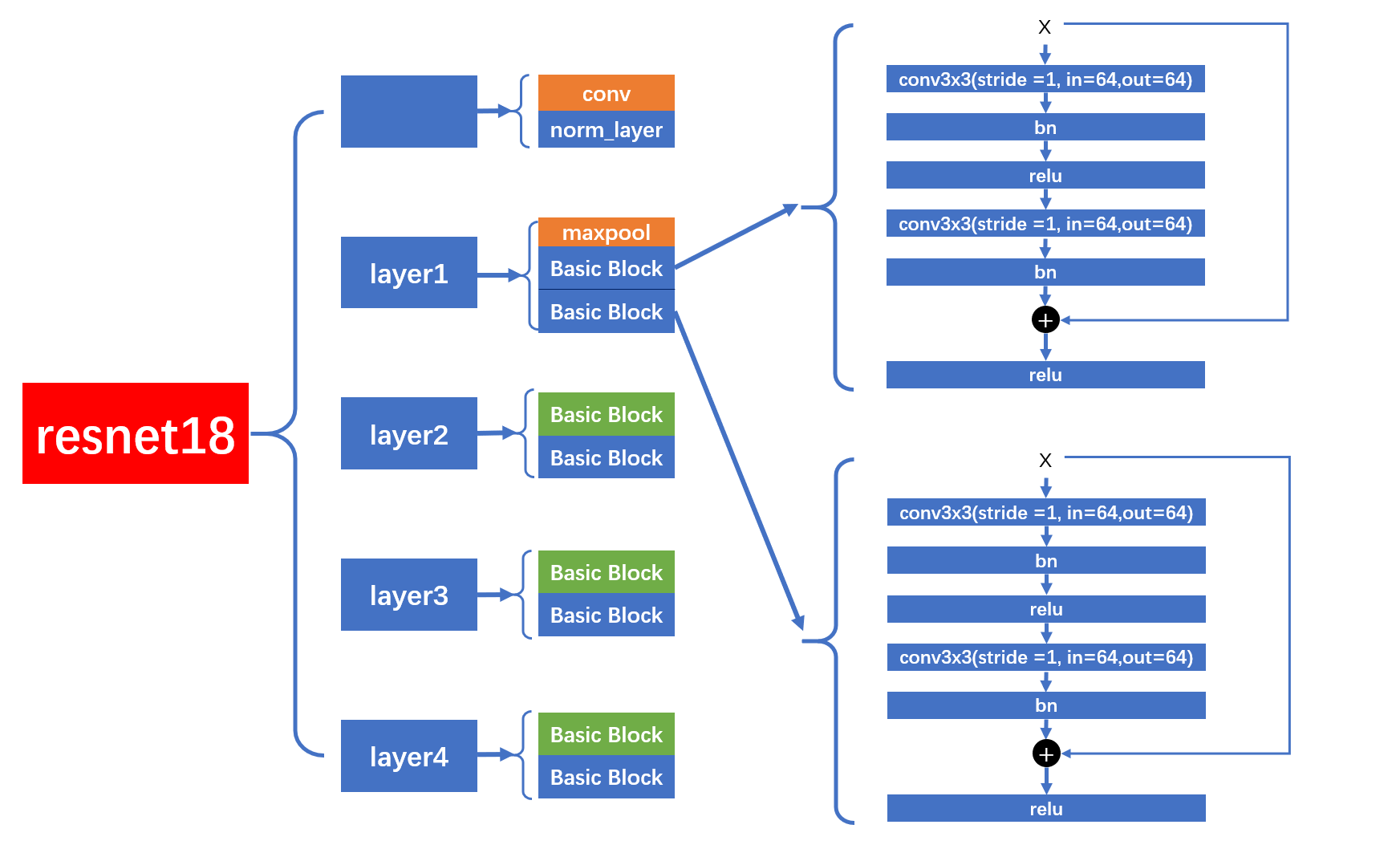
7.1ResNet 18 图解
layer1
下面是
ResNet 18
,使用的是
BasicBlock
的
layer1
,特点是没有进行降采样,卷积层的
stride = 1
,不会降采样。在进行
shortcut
连接时,也没有经过
downsample
层。
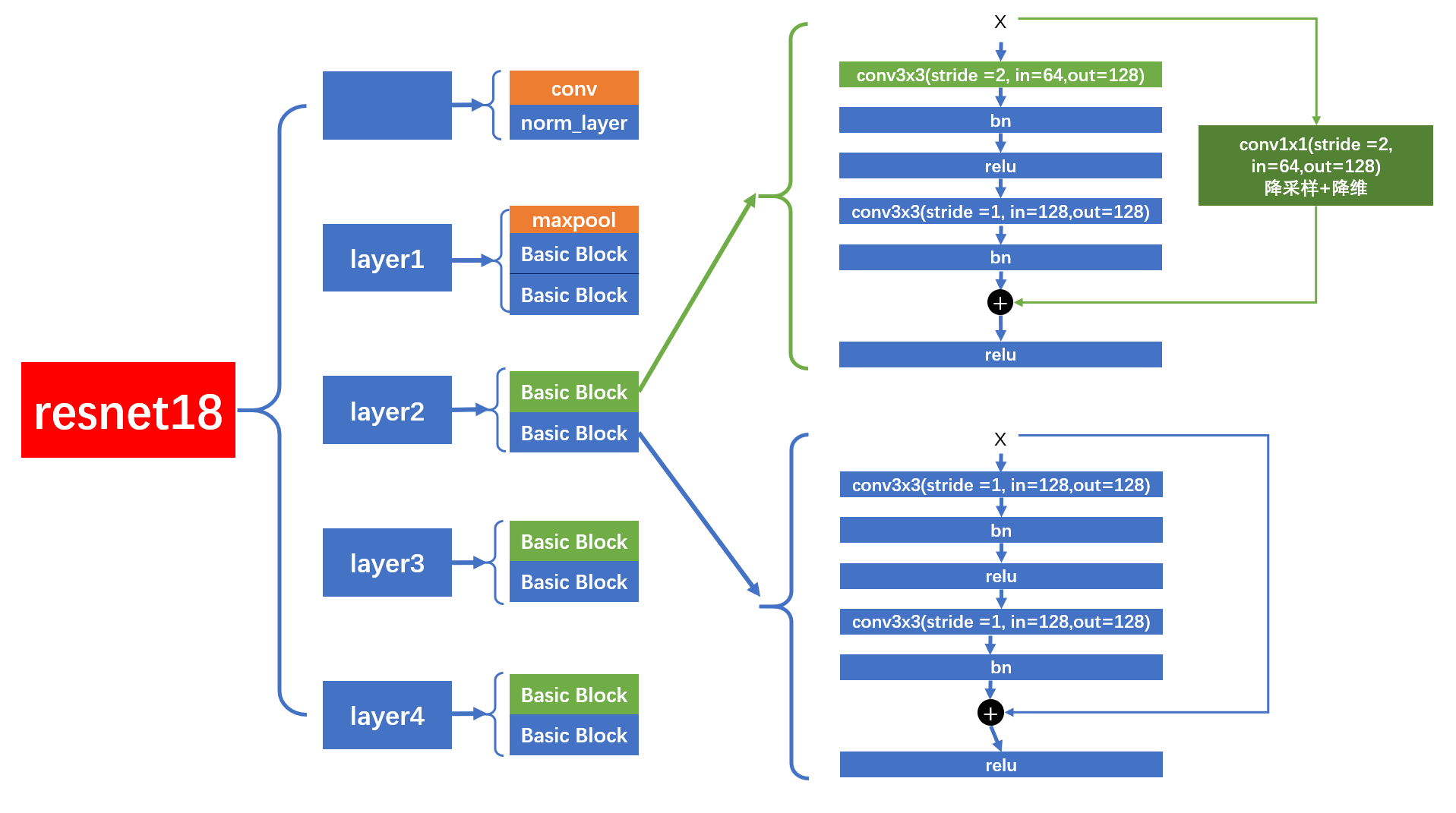
layer2,layer3,layer4
而
layer2
,
layer3
,
layer4
的结构图如下,每个
layer
包含 2 个
BasicBlock
,但是第 1 个
BasicBlock
的第 1 个卷积层的
stride = 2
,会进行降采样。
在进行
shortcut
连接时,会经过
downsample
层,进行降采样和降维
。
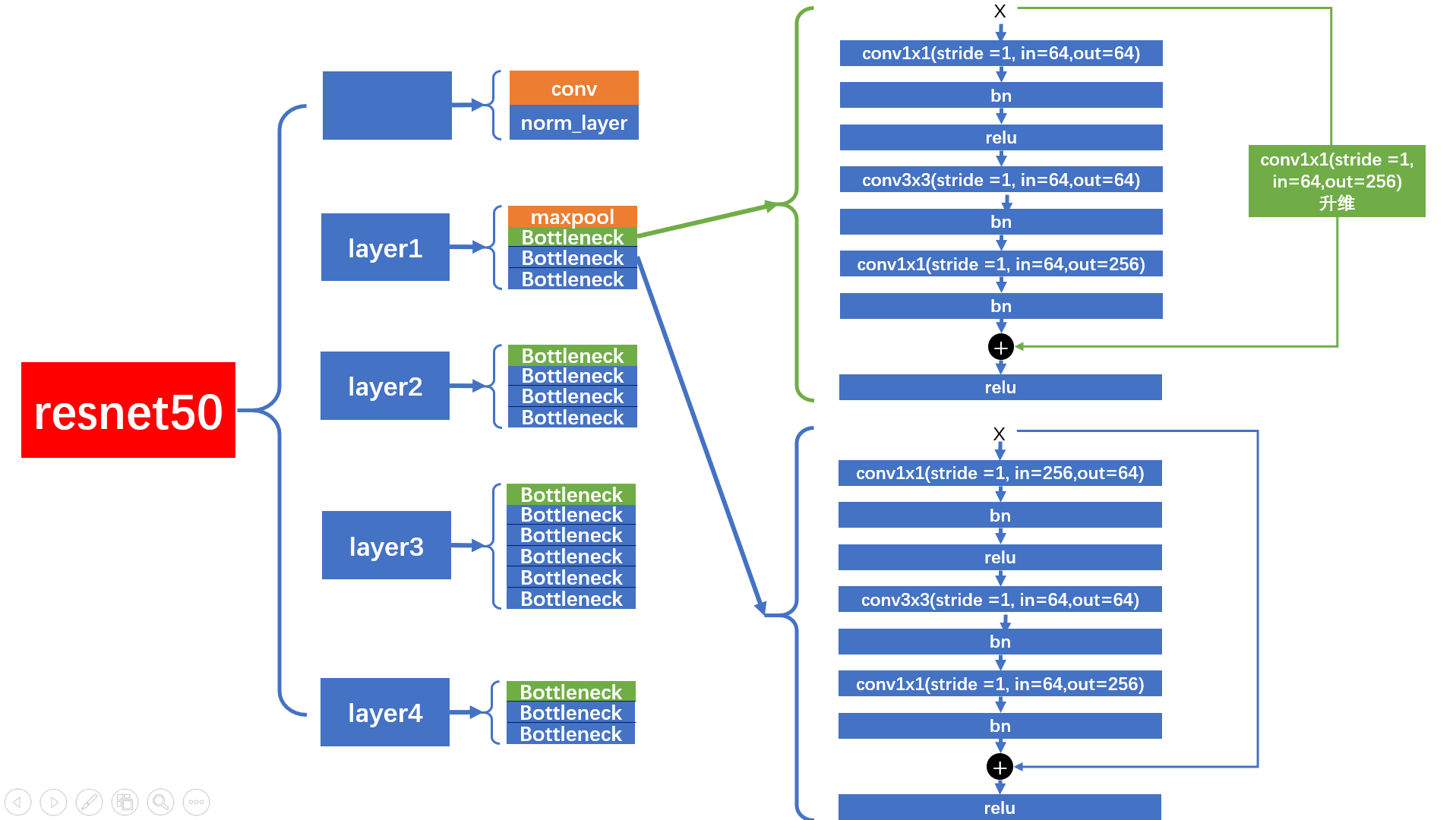
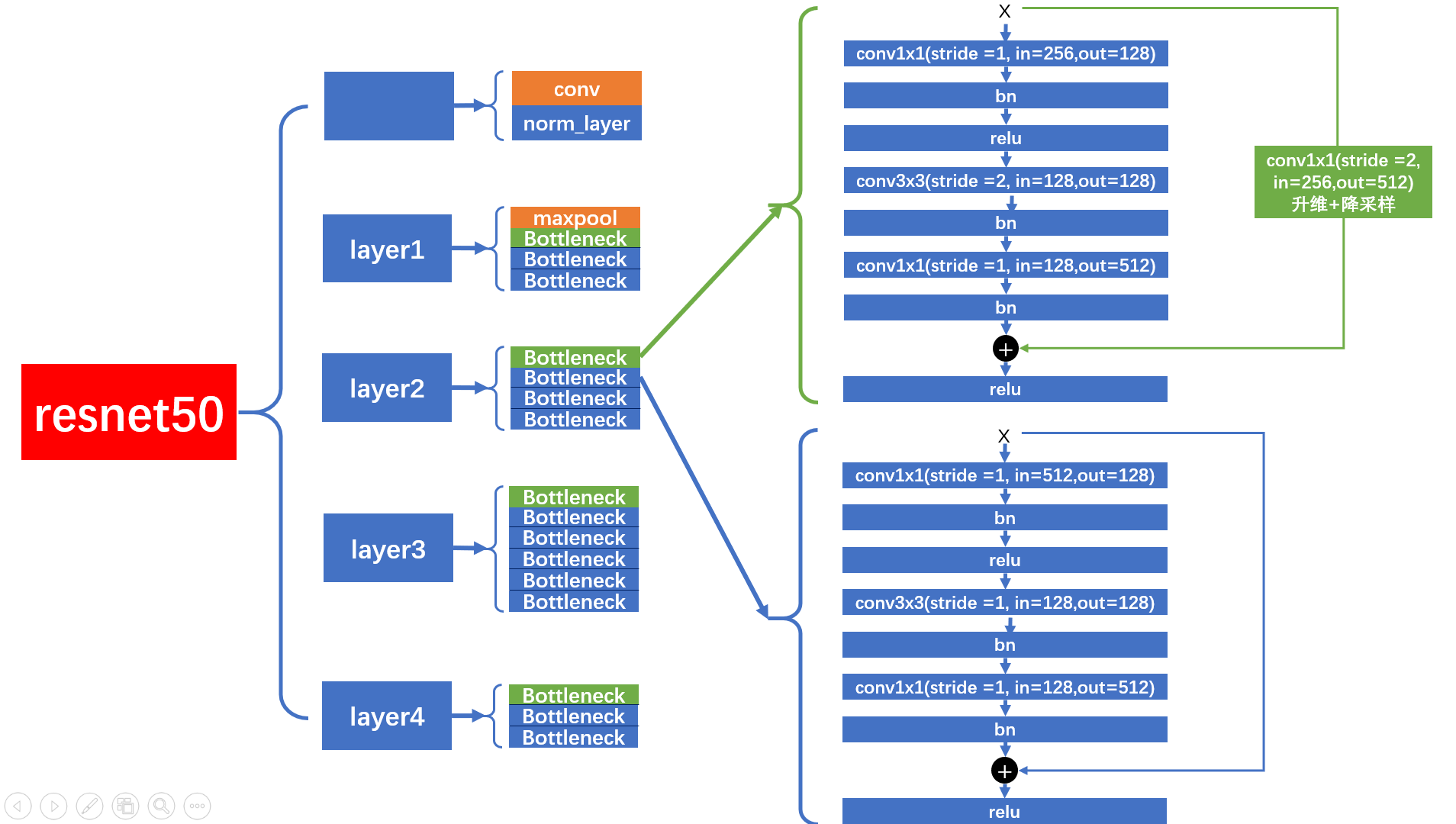
7.2ResNet 50 图解
layer1
在
layer1
中,首先第一个
Bottleneck
只会进行升维,不会降采样。
shortcut
连接前,会经过
downsample
层升维处理。第二个
Bottleneck
的
shortcut
连接不会经过
downsample
层。
layer2,layer3,layer4
而
layer2
,
layer3
,
layer4
的结构图如下,每个
layer
包含多个
Bottleneck
,但是第 1 个
Bottleneck
的 $ 3 \times 3 $ 卷积层的
stride = 2
,会进行降采样。
在进行
shortcut
连接时,会经过
downsample
层,进行降采样和降维
。
参考文献
- 中学python课程知识图谱构建及应用研究(华中师范大学·黄健)
- 基于深度学习的抽象画推荐系统(北方民族大学·唐延辉)
- 基于深度学习的垃圾分类系统的设计与开发(浙江大学·徐丽)
- 基于深度学习的定制化图像识别系统的设计与实现(贵州大学·姜建勇)
- 中学python课程知识图谱构建及应用研究(华中师范大学·黄健)
- 基于人脸聚类的图片管理系统的设计与实现(首都经济贸易大学·王子涛)
- 基于人脸聚类的图片管理系统的设计与实现(首都经济贸易大学·王子涛)
- 基于SSH框架的图像检索系统的设计与实现(内蒙古大学·高凌超)
- 中学python课程知识图谱构建及应用研究(华中师范大学·黄健)
- 基于深度模型迁移学习的花卉图像分类方法(河南师范大学·郜翔)
- 基于深度模型迁移学习的花卉图像分类方法(河南师范大学·郜翔)
- 小样本图像分类与目标检测研究(长安大学·董杨洋)
- 基于文本挖掘的视频标签生成及视频分类研究(上海交通大学·吴雨希)
- 基于知识图谱的图像描述改进(云南大学·王雁鹏)
- 基于SSH框架的图像检索系统的设计与实现(内蒙古大学·高凌超)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设项目助手 ,原文地址:https://bishedaima.com/yuanma/35711.html