基于Python实现的搜索和推荐系统
一、引言
伴随着科技的不断进步,互联网,万维网的不断发展。我们越来越热爱万维网,也欣赏他的发展方式。20世纪90年代初,万维网还只是一个将文档联系起来的简单网络。如今,他已经成为了全球信息的框架。显然,如何表达万维网上的数据是下一步需要解决的问题。但这个问题并不简单。
关联数据是万维网上表示和连接结构化数据的一系列技术。通过关联数据将万维网转换为一个全球性的数据空,我们称之为数据网(Web of Data)。通过关联数据SPARQL查询语言同时查询多个信息源的关联数据,并动态合并并查询结果,这样的方法是传统数据管理技术很难实现的或根本无法做到的。
籍由关联数据技术,我们更容易和他人共享数据。理论上说,可以采用关联数据描述任何内容。万维网上的关联数据可以被发现,共享并与其他用户的数据进行合并。与传统的数据管理系统不同,关联数据将信息从专有容器中(proprietary container)中释放出来,任何人都可以使用这些信息。与其他数据一样,关联数据的质量和效用由数据使用者来负责评估。人们只信任可靠的数据。
我们正是基于这样一个数据可靠、安全、数据之间可关联的关联数据技术,来实现我们对于搜索服务和基于语义的推荐服务。
二、准备
2.1 软件工程语言选择
世界上有非常多的软件编译语言,主流的有C、C++、JAVA、PYTHON、C#等等。每一种编译语言都有他们自己的特点,每一种编译语言都有他们自己的库和相关的编译工具。用什么样的语言来实现我们搜索和推荐服务是首先要考虑的。
搜索和推荐服务是一个对互联网信息资源进行搜索整理、分类,并储存在网络数据库中供用户查询的系统,包括信息收集,信息分类,和目标查询三个部分组成。
从使用者的角度看,搜索和推荐服务提供一个包含搜索输入框的页面,在搜索框中输入词汇,通过浏览器提交给搜索后台服务引擎后,搜索后台服务引擎就会返回跟用户输入的内容相关的信息列表。其实这样的搜索后台服务引擎涉及到很多领域的理论和技术:数字图书馆,数据库,信息检索,信息提取,人工智能,机器学习,自然语言处理,计算机语言学,统计数据分析,数据挖掘,计算机网络,分布式处理等等,具有综合性和挑战性。
在世界范围内,百度,GOOGLE,搜狗就是非常好的搜索引擎。通过学习这些搜索服务,我们发现他们都是通过Web来进行搜索服务的。
因此我们确定我们的搜索和推荐服务也应当是通过TCP方式,HTTP协议,以Web的方式进行搜索和推荐服务,通过Web来实现搜索和推荐的交互功能。
在实现Web这样的B/S架构时,我们发现两种语言适用于开发这样的服务程序。一个是Java语言,一个是Python语言。
在Java语言中有Tomcat服务来实现网页与后台的相互传参,运算;在Python语言中有Callimachus和Django来实现网页与后台逻辑的通讯。
通过对比Java和Python开发我们发现:
-
Java开发所需要的JDK版本一旦安装完成,在同一台PC机上是需要通过卸载重新安装来实现 ;在Python中对于Python2.7和Python3,我们通过virtualenv和anaconda等虚拟容易来盛放不同的python版本只需要通过cmd(windows下)命令就可以实现
-
Java中的库主要都是对于类型转换,和网页servlet方式的库 ;在python中不仅包含于网页的相关库,他更强大的是有很多算法库,由于python属于脚本语言,所有他所支持和库所涉及的功能范围比java库要更加多
-
在Java中进行相关的SPARQL查询,需要安装jena,并将安装好的jena文件进行相应的环境变量配置 ;但是在python中对于sparqlwrapper,只需要通过cmd命令(pip install xxx)就可以静待电脑自动安装相应文件,而不需要配置相应的环境变量
因此基于以上分析,我们最终选用python来作为我们的软件开发语言。
2.2 服务器的选取
一个好的关联数据开发平台有助于提高开发效率。Callimachus和Django都是这样的一种平台。
2.2.1 Callimachus
尽管Callimachus的开发者们将其定义为关联数据管理系统,但是将其视为关联数据的应用服务器更加合适。Callichus主要具备以下特征:
-
模板系统能自动为OWL类(OWL class)的所有成员生成网页。严格来说,OWL类与RDF schema类本身或其子类并无二致(取决于所用的OWL配置文件)。简单起见,我们认为OWL类与RDF Schema类是等价的
-
在运行时检索数据,并将其转换为RDF格式
-
将SPARQL查询与URL关联起来,对查询进行参数化,并使用带有图标库(charting library)的查询结果
-
PURL(持久化URL)实现
基于DocBook的结构化书写系统(structured writing system)包括可视化编辑环境。
简而言之,Callimachus支持使用关联数据进行导航,可视化,构建应用程序等操作。数据既可以保存在本地,也可以从万维网上采集,甚至可以在载入Callimachus时被转换为RDF。
2.2.2 Django
而Django是一个开放源代码的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,模板T和视图V。
Django 项目是一个Python定制框架,它源自一个在线新闻 Web 站点,于 2005 年以开源的形式被释放出来。Django 框架的核心优势有:
-
用于创建模型的对象关系映射
-
为最终用户设计的完美管理界面
-
一流的 URL 设计
-
设计者友好的模板语言
-
缓存系统
Django是一个基于MVC构造的框架。但是在Django中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为 MTV模式。它们各自的职责如下:
-
模型(Model),即数据存取层 :处理与数据相关的所有事务:如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等
-
模板(Template),即业务逻辑层 :处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。一般将网页html和js文件存放在此层中
-
视图(View),即表现层 :存取模型及调取恰当模板的相关逻辑。模型与模板的桥梁。在view里面进行python后台处理,他将网页的响应数据拿到,同时也为网页发送请求
从以上表述可以看出Django 视图不处理用户输入,而仅仅决定要展现哪些数据给用户,而Django 模板 仅仅决定如何展现Django视图指定的数据。或者说, Django将MVC中的视图进一步分解为 Django视图 和 Django模板两个部分,分别决定 “展现哪些数据” 和 “如何展现”,使得Django的模板可以根据需要随时替换,而不仅仅限制于内置的模板。
2.2.3 对比
通过使用Callimachus和Django两种服务器我们发现:
-
Django在后台可以植入各种py文件来作为算法和逻辑基础 ;在Callimachus所有的sparql操作统一下xhtml上div块中进行书写,也就是Callimachus将业务逻辑基本集成在网页上面编写
-
系统稳定性 :Django早在2005年的时候就已经开始使用,网上对于Djano开发时所遇到的问题都有全面的回答,维护起来非常方便;Callimachus是在近几年才推出来的关联数据管理器,他虽然针对关联数据有很好的执行能力,但是在网上不止是关于他运行时的一些解决问题,就连关于他的介绍都微乎其微,在Callimachus运行的时候所遇到的维护问题只能靠自己解决,稳定性不确定,属于试验阶段
-
开发周期 :Django因为有越来越多的人在使用,而且出来较早,对于Django的查询和学习资料较为广泛,开发时间短;Callimachus因为网上资料确实太少,仅有的介绍只是Callimachus的官网说明,因此开发难度较大,学习周期长
基于以上分析,我们最终选用Django服务器来实现我们的搜索和推荐服务。
三、搜索服务
3.1 搜索服务软件目录结构
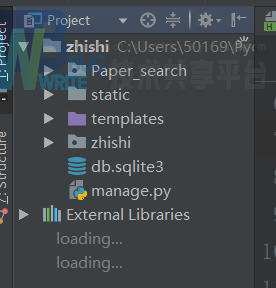
该路径为项目目录的根文件夹。
其中Paper_search文件作为Django生成的APP文件,在该文件内来实现网页的请求和响应,以及sparql查询功能。
Statica文件用于存放javascript文件和css文件,用于增强网页效果。
Templates文件用于存放html文件,来作为网页html的存放文件夹.
Zhishi文件用于存放该项目文件中的一些配置文件,主要是其中的settings.py文件用于项目承认Paper_search这个APP,用于指定static文件为静态文件路径;另外该文件夹下的urls.py文件用于绑定方法与html路径。
最后是manage.py文件,该文件作为Django运行的起始文件,整个项目的运行开端为manage.py文件。
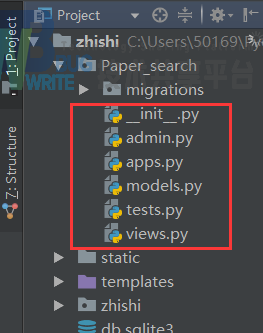
在app文件里面,我们主要的逻辑程序都在views.py文件中,其中的方法主要是sparql的查询,正则化处理,网页的请求和相应。
3.2 搜索服务功能
本搜索服务主要是通过在网页上输入一本书的名字,通过书名正则匹配的方式,检索出完整的书名、作者名字、书籍资源的url。
首先(windows下)通过打开cmd,在命令行cd 到该项目路径:

在项目路径下执行该命令:

上一行workon bayou是virtualenv技术,workon来执行我项目所配置到的env环境中,通过让baoyu的env环境工作,使得当前环境为我需要的Python2.7环境。
进入到环境后通过下一行执行manager.py文件,并指定端口号为9000。开启服务器后,网页输入以下网页来实现搜索的效果。
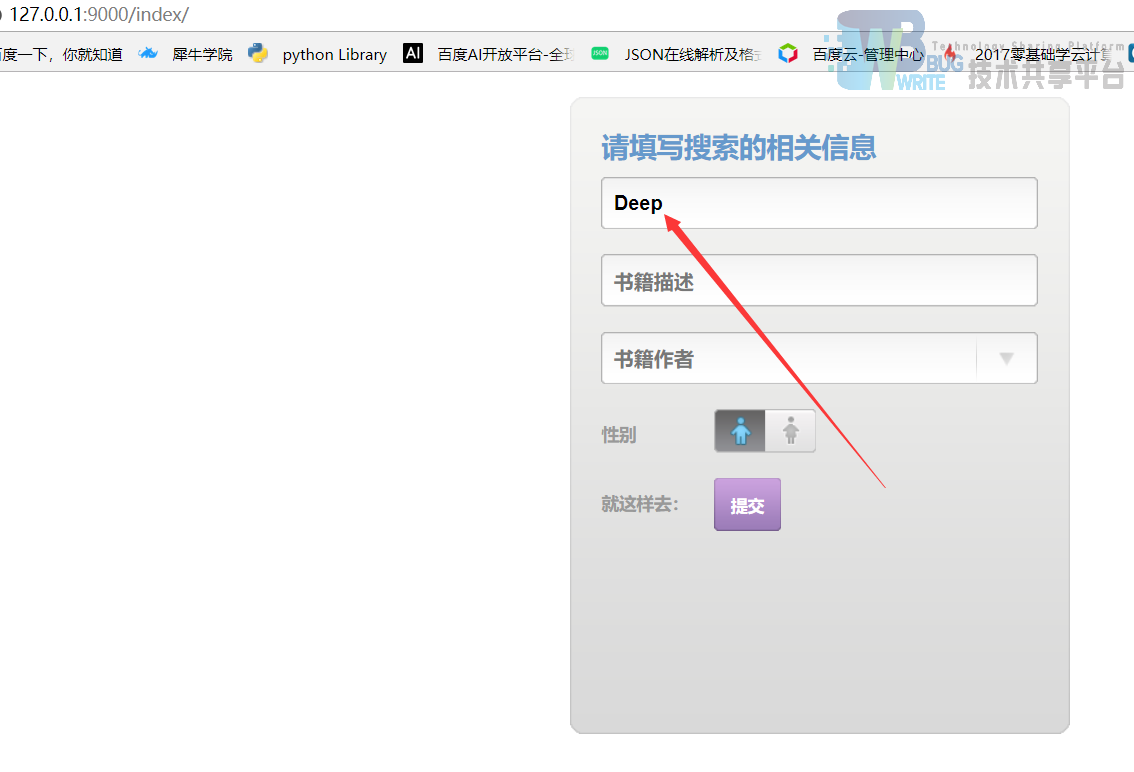
通过在网页端输入你想输入的书籍名字,可以是大概名字,点击下面的“提交”按钮。然后经过后台检索,跳转到另一个HTML页面显示该搜索结果。
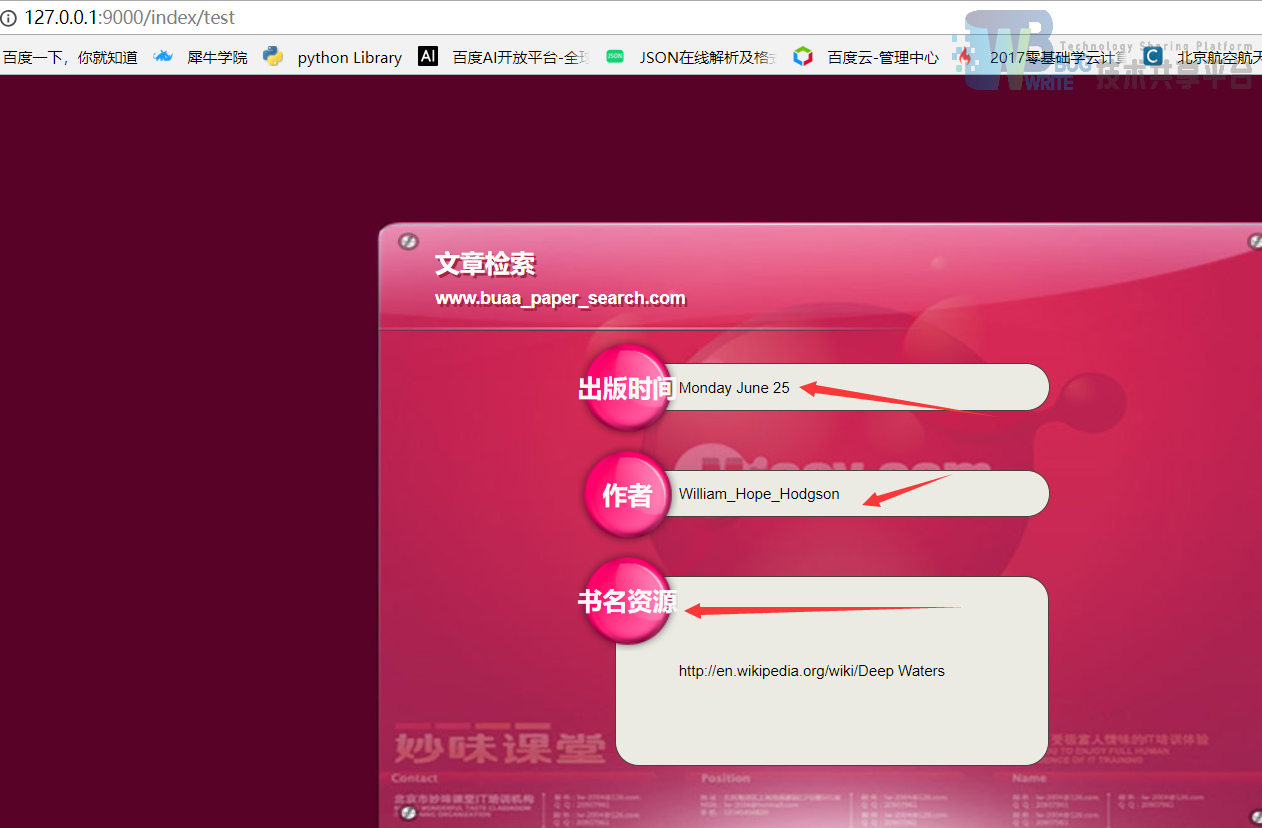
跳转到的界面,输出该书的出版时间,作者,和书籍的资源路径
3.3 SPARQL语句分析
在搜索服务软件中,我们通过导入SPARQLWrapper,来实现通过SPARQL来基于DBpedia数据来进行的搜索:
``` sparql.setQuery(""" PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# PREFIX dbo: http://dbpedia.org/ontology/ PREFIX rdfs: http://www.w3.org/2000/01/rdf-schema# PREFIX onto: http://dbpedia.org/ontology/
select ?BookName,?Author,?Country,?Subject,?Label,?ReleaseDate,?Publisher WHERE{
?book a dbo:Book.
?book foaf:name ?BookName.
?book dbo:author ?Author.
?book dbo:country ?Country.
?book dct:subject ?Subject.
?book rdfs:label ?Label.
?book dbp:releaseDate ?ReleaseDate.
?book dc:publisher ?Publisher.
FILTER regex(?BookName,"%s","i")
}
""" % name)
```
以上为我们所采用的SPARQL语句,通过定义?book是一个BOOK书来实现的相关查找,对于查找我们在最后加入FILTER 来进行正则化过滤,确保我们查询的书籍跟网页上的书籍对应。由于在SPARQL中我们要传递的是一个变量,所以在这里我们采用%s的格式化标识来传参。
3.4 经验与收获
在通过该搜索功能的实现中,首先我们训练了基于Django实现的网页交互功能。主要熟悉了Django软件的请求与响应流程:网页的参数通过urls.py文件绑定到响应的APP下的viwe.PY文件中的响应方法,通过该方法拿到参数后,传递给相应的查询语句并返回结果,后通过urls.py文件传结果参数给相应的html文件进行前端显示。
练习了SPARQL怎么作为查询语句在现目中实现,通过SPARQLWrapper库提供的功能,将查询语句写入,通过调用其相应的方法执行查询、格式化输出等操作。
另外为了实现网页的参数在SPARQL查询语句里也依然是个参数,我们通过多方的探究,独立想出了使用格式化符的方法。在原来的实验中,我们尝试”””+变量+”””这样的拼接方式进行传入变量但是不成功,但是通过这样独立的思考,对于实现SPARQL接收其他类或方法下的变量,有了很好的印象。
3.5 不足
在搜索功能的中,我们对目标的检索只停留在对单一的,比如说单书本名字,单电影名字或者单游戏名字。我们应当将书籍,电影,游戏的名字与其他相关基本信息联系起来。比如通过电影名字仅仅提供单个字符,然后基于电影的导演名字配合来查找到相关目标。
3.6 所需配置的环境与包
-
Python2.7环境
-
Django库(通过pip install django)或者在pycharm里面setting中添加也行
-
SPARQLWapper
四、推荐功能服务
4.1 功能介绍
基于B/S架构的推荐功能服务。通过在网页上输入相应的书籍名称,和你知道的书籍描述。通过书籍名字和描述来确定与书籍相同主题上的一部电影,并通过推荐算法来推荐与这部电影最相近的10部电影。
首先进入到本地9000端口下的index界面:

在书籍名字和书籍描述上一定要填上。这里以一千零一夜为例: 通过填入一千零一页这本书,和该书的主题(在dbpedia中为该单词)one_thousand主题。通过提交按钮,在后台查询到与之主题最匹配的一个电影(Aladding(1992)film) 将Aladding(1992)film这个结果返回给我们机器学习算法使用交叉回归的方式来实现与这部电影最相近的10部电影(推荐的方式都是基于用户对电影的评价和评分,通过评价和评分综合推荐相似的电影)。返回出结果
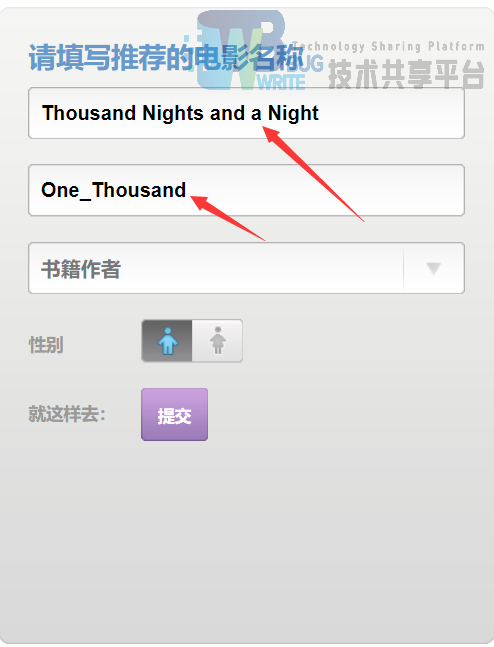
通过填入一千零一页这本书,和该书的主题(在dbpedia中为该单词)one_thousand主题。通过提交按钮,在后台查询到与之主题最匹配的一个电影(Aladding(1992)film)。
将Aladding(1992)film这个结果返回给我们机器学习算法使用交叉回归的方式来实现与这部电影最相近的10部电影(推荐的方式都是基于用户对电影的评价和评分,通过评价和评分综合推荐相似的电影)。返回出结果。

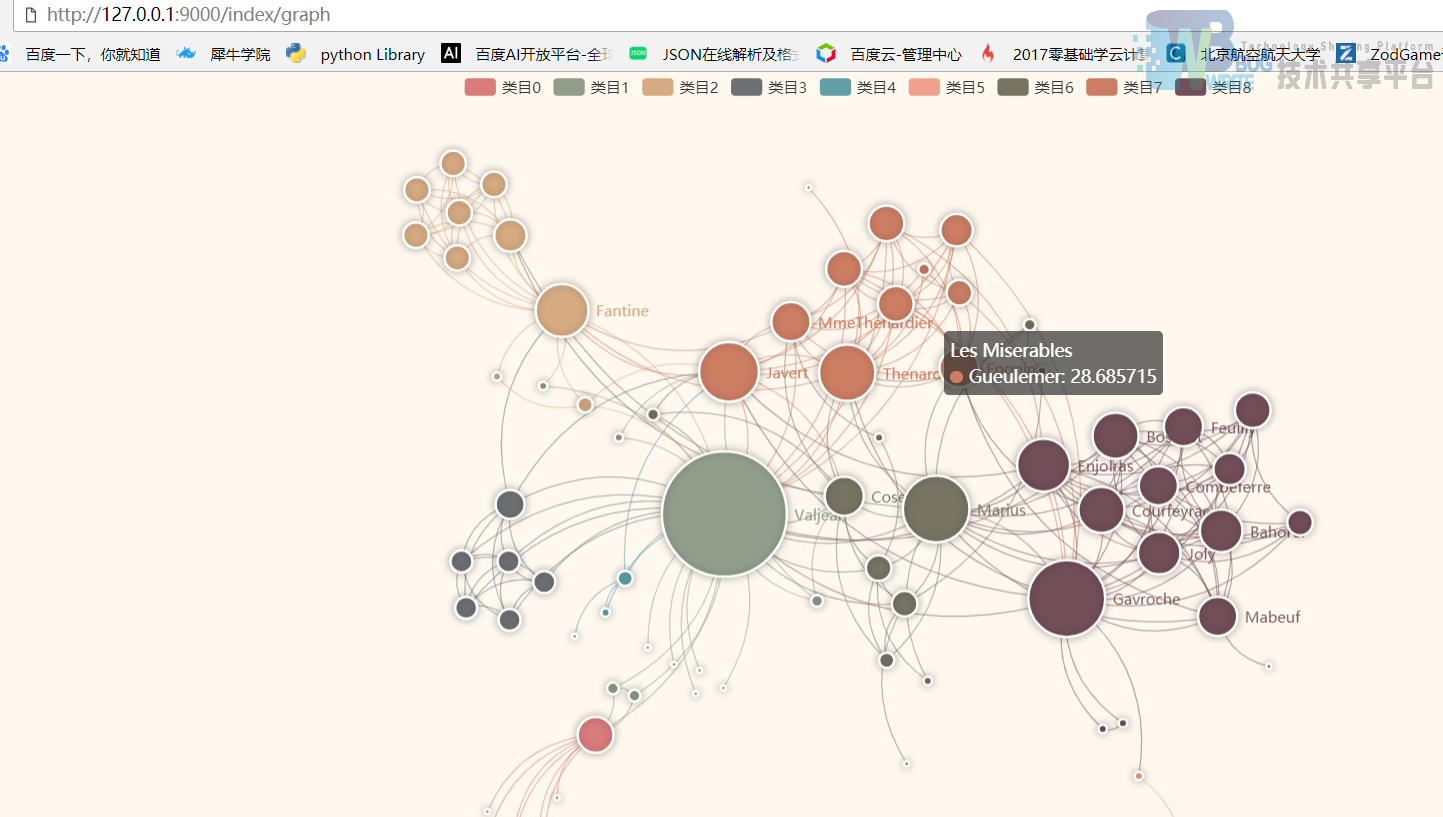
通过点击提交按钮,跳转到可视化界面,在这里可视化界面需要在打开的chrome右键属性进行相应的目标文件配置。
``` 在目标那栏: "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
末尾空一行添加: --allow-file-access-from-files
效果即为: "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --allow-file-access-from-files ```
4.2 推荐服务的目录结构
该路径为项目目录的根文件夹。
其中Paper_search文件作为Django生成的APP文件,在该文件内来实现网页的请求和响应,以及sparql查询功能。
Statica文件用于存放javascript文件和css文件,用于增强网页效果。
Templates文件用于存放html文件,来作为网页html的存放文件夹。
Zhishi文件用于存放该项目文件中的一些配置文件,主要是其中的settings.py文件用于项目承认Paper_search这个APP,用于指定static文件为静态文件路径;另外该文件夹下的urls.py文件用于绑定方法与html路径。
最后是manage.py文件,该文件作为Django运行的起始文件,整个项目的运行开端为manage.py文件。
4.3 推荐服务的逻辑流程
4.3.1 方法目录
所有的处理逻辑都集中在Paper_rearch文件夹下的view.py文件中:
-
Def query_fun作为sparql查询方法,返回一个电影名称
-
def read_item_names():电影名与电影id,电影id与电影名绑定映射
-
def clearContentWithSpecialCharacter(content):正则化方法,用于对电影名字进行文字格式处理
-
def receive_data(request):处理页面响应,并向页面发送请求
4.3.2 执行逻辑
首先通过网页上输入的书籍名字和书籍主题,通过receive_data(request):来接收书籍名字和书籍主题,将这两个参数传入给:query_fun(书籍名字,书籍主题)。
query_fun找到电影名字,在query_fun配有相应的正则化方法来输出我们所需要的格式下的电影名字film_name。
执行read_item_names()方法来输出“电影名与电影id”,“电影id与电影名”映射模型film_name与电影id相绑定,输入到surprise提供的交叉熵算法来求得,人们对该电影评价与评分最相近的10部电影,然后传递给网页显示。
4.4 SPARQL分析
sparql.setQuery("""
PREFIX onto: <http://dbpedia.org/ontology/>
select ?b WHERE{
?a dct:subject ?subject_a.
FILTER regex(?subject_a,"characters").
FILTER regex(?subject_a,?subject).
?b dct:subject ?subject_a.
?b a dbo:film.
{
select ?a,?subject WHERE{
?a dct:subject ?subject.
FILTER regex(?a,"characters").
{
select ?subject,?BookName,?book WHERE{
?book dct:subject ?subject.
?book a dbo:Book.
?book foaf:name ?BookName.
?book rdfs:comment ?a.
?book dbp:author ?b.
FILTER regex(?BookName,"%s").
FILTER regex(?subject,"%s").}
}
}
}
}
""" % (name,subject))
本查询语句使用了3层的子查询结构。在第一层查询中:
select ?subject,?BookName,?book WHERE{
?book dct:subject ?subject.
?book a dbo:Book.
?book foaf:name ?BookName.
?book rdfs:comment ?a.
?book dbp:author ?b.
FILTER regex(?BookName,"%s").
FILTER regex(?subject,"%s").}
我们来找到网页上输入的书籍名字和主题最契合的书和主题。主要将输出的主题提供给父查询来使用。在第二层查询中:
select ?a,?subject WHERE{
?a dct:subject ?subject.
FILTER regex(?a,"characters").
{
select ?subject,?BookName,?book WHERE{
?book dct:subject ?subject.
?book a dbo:Book.
?book foaf:name ?BookName.
?book rdfs:comment ?a.
?book dbp:author ?b.
FILTER regex(?BookName,"%s").
FILTER regex(?subject,"%s").}
}
}
我们根据第一层查询到的主题,来找到一个大类,这个类与这个主题是一样的。同时输出这个类和主题供父查询来使用。
在最外圈的查询,我们查找与?a类和?a的主题一样的电影,查询出来输出。把这个查询结构进行正则化处理后,交给推荐算法来进行电影推荐。
4.5 经验与收获
为了实现通过书籍来查询电影功能,我们通过w3c官网来查找相关文档学习SPARQL的相关查询方法,并总计了相关查询语句,写成了相应的博客文档:
-
https://blog.csdn.net/qq_28666313/article/details/80782827
-
https://blog.csdn.net/qq_28666313/article/details/80777155
为了实现推荐功能,我们通过相关资料的查找,确定了Item-base算法,这种算法通过纵向(观众的评分)和横向(观众的评价)来交叉考虑得到与之最近的分类从而实现基于一个电影推荐其相关电影的功能。
由于Item-base算法中对电影名字有严格的命名匹配,所以我们在处理python中的正则化方法的时候,进行了思考,对正则处理有了一定的经验
4.6 不足
在基于SPARQL中,电影与图书在相同谓语,相同宾语上的联系,不是那么方便。我们通常通过图书找到与子匹配的大主语,再通过大主语下是否有相应的小主语(电影类别)来进行的语义的查找。但是这样的匹配成功率不高,有很多图书并没相关电影;也有很多图书相关的电影太多了(但是匹配的主题很宽泛比如都是属于英国出版,都是表述爱情)。而且再DBpedia上这样的语义描述还是太少了,只是一些关键上的描述。对于这样的语义关联查询,在描述上越多越好查询。
本次查询就是经过不断的尝试,发现了Thousand Nights and a Night(一千零一夜书籍)与Aladding(大类)有共同的subject(One_Thousand_and_One_Nights_characters),这个共同的主题就是他们的联系。通过Aladding(大类)再来找到Aladding_film(1992)年的电影,但这样的实例不太容易发掘,其主要原因还是SPARQL语句的不理解,和对基于语义的相关查询操作不深。
4.7 环境组件
-
Python2.7
-
Django
-
SPARQLWrapper
-
Cpython
-
Surprise
如果是windows环境在安装surprise包会出现缺乏microsoft C++9.0组件,这需要去微软官网下载(MAC和linux 不存在这样的问题)。
五、基于机器学习的推荐算法分析
5.1 基于机器学习的推荐算法分析
推荐系统应用数据分析技术,找出用户最可能喜欢的东西推荐给用户,现在很多电子商务网站都有这个应用。目前用的比较多、比较成熟的推荐算法是协同过滤(Collaborative Filtering,简称CF)推荐算法,CF的基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
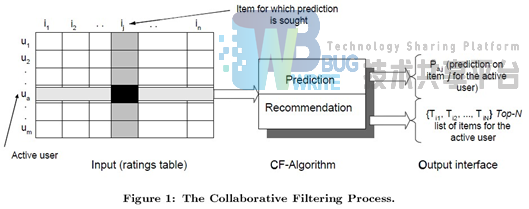
如图1所示,在CF中,用m×n的矩阵表示用户对物品的喜好情况,一般用打分表示用户对物品的喜好程度,分数越高表示越喜欢这个物品,0表示没有买过该物品。图中行表示一个用户,列表示一个物品,Uij表示用户i对物品j的打分情况。CF分为两个过程,一个为预测过程,另一个为推荐过程。预测过程是预测用户对没有购买过的物品的可能打分值,推荐是根据预测阶段的结果推荐用户最可能喜欢的一个或Top-N个物品。
5.2 User-based算法与Iter-based算法对比
CF算法分为两大类,一类为基于memory的(Memory-based),另一类为基于Model的(Model-based),User-based和Item-based算法均属于Memory-based类型,具体细分类可以参考wikipedia的说明。
User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
User-based算法存在两个重大问题:
-
数据稀疏性 :一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户
-
算法扩展性 :最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用
Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。还是以之前的例子为例,可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。
因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。
5.3 Item-based算法详细过程
5.3.1 相似度计算
Item-based算法首选计算物品之间的相似度,计算相似度的方法有以下几种:
基于余弦(Cosine-based)的相似度计算 ,通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,公式如下:
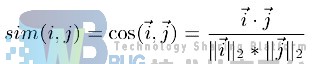
其中分子为两个向量的内积,即两个向量相同位置的数字相乘。
基于关联(Correlation-based)的相似度计算 ,计算两个向量之间的Pearson-r关联度,公式如下:
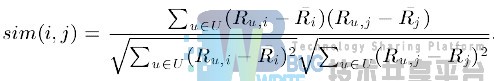
其中Ru,i表示用户u对物品i的打分,Ri表示第i个物品打分的平均值。
调整的余弦(Adjusted Cosine)相似度计算 ,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
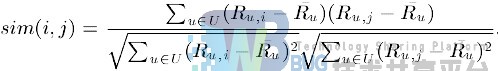
其中Ru表示用户u打分的平均值。
5.3.2 预测值计算
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
加权求和
用过对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分,公式如下:

其中Si,N为物品i与物品N的相似度,Ru,N为用户u对物品N的打分。
回归
和上面加权求和的方法类似,但回归的方法不直接使用相似物品N的打分值Ru,N,因为用余弦法或Pearson关联法计算相似度时存在一个误区,即两个打分向量可能相距比较远(欧氏距离),但有可能有很高的相似度。因为不同用户的打分习惯不同,有的偏向打高分,有的偏向打低分。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度。在这种情况下用户原始的相似物品的打分值进行计算会造成糟糕的预测结果。通过用线性回归的方式重新估算一个新的Ru,N值,运用上面同样的方法进行预测。重新计算Ru,N的方法如下:
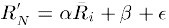
其中物品N是物品i的相似物品,alpha和beta通过对物品N和i的打分向量进行线性回归计算得到,E为回归模型的误差。
5.4 Surprise库的介绍
在推荐系统的建模过程中,我们用到python库是 Surprise(Simple Python RecommendatIon System Engine),是scikit系列中的一个(很多同学用过scikit-learn和scikit-image等库)。所使用的数据库是MovieLens 100k,该数据集包括6040个用户对大概3900部电影的1000209条评分数据。(该数据集的链接是:https://grouplens.org/datasets/movielens/100k/ )。surprise库同时支持多种推荐算法:
-
基础算法/baseline algorithms
-
基于近邻方法(协同过滤)/neighborhood methods
-
矩阵分解方法/matrix factorization-based (SVD, PMF, SVD++, NMF)

其中基于近邻的方法(协同过滤)可以设定不同的度量准则:

支持不同的评定标准:
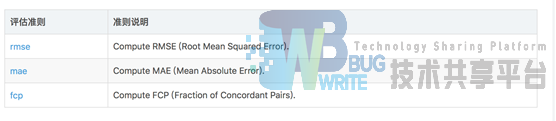
参考文献
- 个性化资讯推荐系统的设计与实现(山东大学·仵贇)
- 一种网页推荐系统的设计与实现(北京邮电大学·李德颀)
- 基于数据挖掘的电视节目个性化推荐研究及实现(曲阜师范大学·徐晟杰)
- 基于用户偏好混合推荐系统Rblog设计与实现(大连理工大学·李瑾)
- 在线推荐系统的算法研究及其应用(电子科技大学·黄海波)
- 基于协同过滤的推荐算法比较研究(重庆大学·高寒)
- 基于Mongodb推荐系统的研究与应用(华中科技大学·和慧)
- 基于Django的课程推荐系统的设计与实现(华中科技大学·羊雪玲)
- 基于Hadoop的电子商务推荐系统的设计与实现(闽南师范大学·彭兴)
- 基于Hadoop的电子商务推荐系统的设计与实现(闽南师范大学·彭兴)
- 中小学教育资源个性化推荐系统研究与实现(东北师范大学·刘荣橙)
- 出版物作者推荐系统的研究与实现(北京印刷学院·张莉婧)
- 推荐系统协同过滤算法的改进(云南大学·石婷)
- 基于网络用户行为分析的用户推荐反馈系统的设计(北京化工大学·石钊)
- 基于协同过滤的推荐算法比较研究(重庆大学·高寒)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码项目助手 ,原文地址:https://bishedaima.com/yuanma/35590.html