
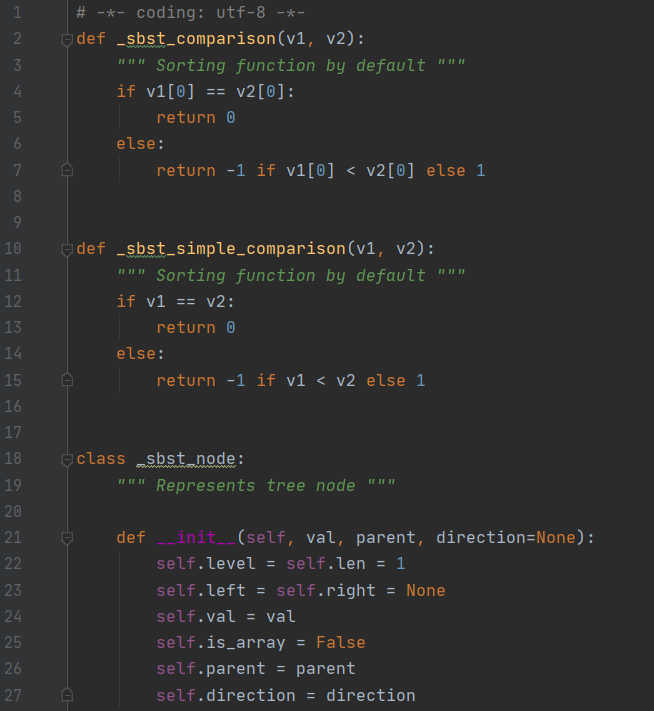
基于Python设计的信息检索系统
【实验目的】:
开发一款针对英文文本的信息检索系统,可以实现建立索引表、布尔查询、通配符查询、
短语查询等功能,并通过开发过程达到以下目的:
-
复习本学期所学信息检索知识;
-
掌握基本的信息检索方法,了解检索系统的搭建;
-
具备实现、维护与优化信息检索系统的能力。
目前实现的功能有:
-
自动获取某英文小说网站的文本作为数据源;
-
建立查询表;
-
计算指定词的 TF-IDF值;
-
进行布尔查询;
-
进行通配符查询;
-
进行短语查询。
-
所有功能都可以通过—hit参数限制输出的结果数量。
【实验环境】:
处理器:
c++
Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz 2.40 GHz
操作系统环境:
Windows 10 家庭中文版 x64 21H1 19043.1052
编程语言:
c++
Python 3.8
IDE 及包管理器:
JetBrains PyCharm 2020.1 x64,anaconda 3 for Windows(conda 4.9.0)
使用的第三方库:
见附件 requirements.txt
【参考文献】:
美]克里斯托夫·曼宁,[美]普拉巴卡尔·拉格万,[德]欣里希·舒策 著.王斌,李鹏 译.信息检索导论(修订版).人民邮电出版社,2019.7.
实验内容
【实验方案设计】:
本部分将围绕以下 8 个模块,就原理和实现层面分别予以介绍:用户交互的实现、数据获取、查询表的建立、布尔查询、TF-IDF 值的计算、通配符查询、短语查询、结果数目更改。
用户交互的实现:
考虑到信息检索更像是一个具有一些功能的集成系统而非寥寥数个特定的功能,因此决定在开发时采用交互式设计。
原理上,考虑采用 python 中的 cmd 模块。cmd 模块是 python 中包含的一个公共模块,是一个用于交互式 shell 和其它命令解释器等的基类。因此可以考虑基于 cmd 模块自定义一个子类,实现我们自己的交互式 shell。
cmd 模块的执行流程十分简单。输入行包括两个部分:命令和参数,使用命令行解释器循环读取输入的所有行并对其进行解析,然后把解析后的输入行交给命令处理器来处理。通过继承和子类方法重载父类方法的特性,命令行处理器就可以找到适合处理该命令的子类方法。
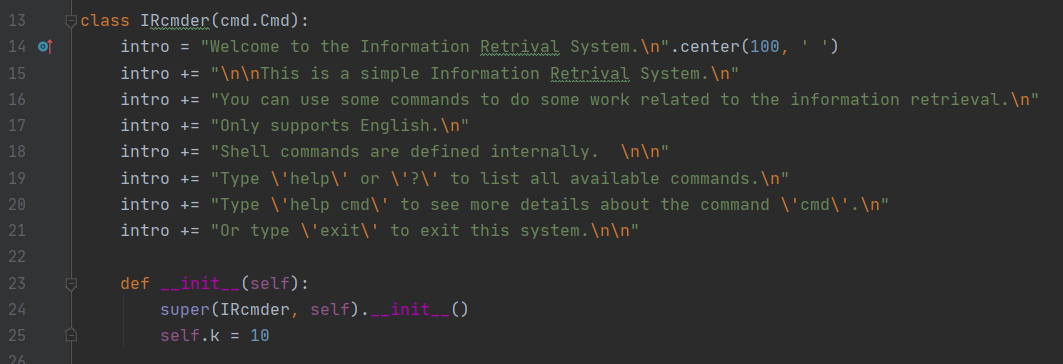
具体实现上,首先构建一个 IRcmder 类,让它继承自 python 中的 cmd 模块:
随后再定义一些解析方式和处理逻辑:
继承自 cmd 的 IRcmder 就可以提供一个类似命令行的环境,这样用户在使用时就可以达到运行一个脚本、使用多个功能的目的。
数据的获取:
数据可以由用户自己提供,也可以由本系统自行抓取。如果由用户自行提供,则用户须将所有的 txt文本放置于某个文件夹下,并在之后的操作中将文件夹路径作为参数传入系统。
若由本系统自行抓取,则需输入 get_data 命令,随后系统会从某小说网站上爬取一定数量的英文短篇小说作为数据源。该网站的架构为静态页面,比较好爬取。
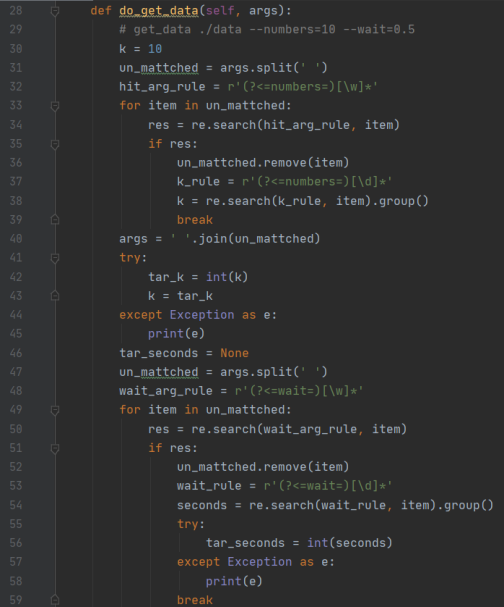
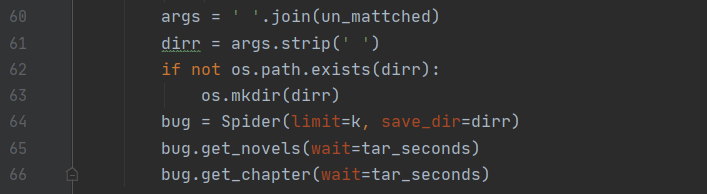
关于爬虫部分,首先会对用户传进来的参数进行解析,以获取用户想要的文章数、停等时间、存放目录等信息:
该部分通过两个正后发断言正则表达式构成,通过两个正则匹配以获取用户想要存放文章的文件集以及停等时间参数。随后通过调用一个 Spider 类实现爬取流程。Spider 其实主要是对网页的请求、解析以及对数据的保存,通过 request 库和 beautiful soup库实现。
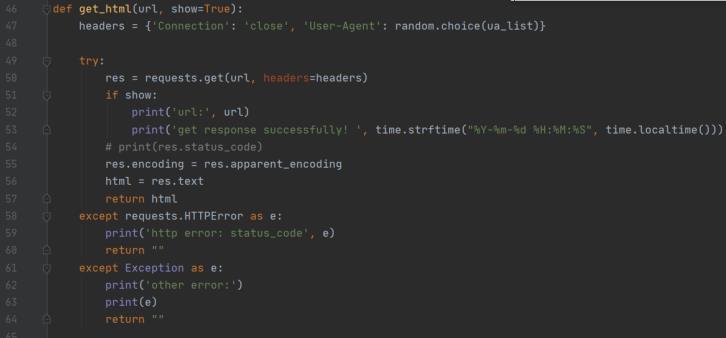
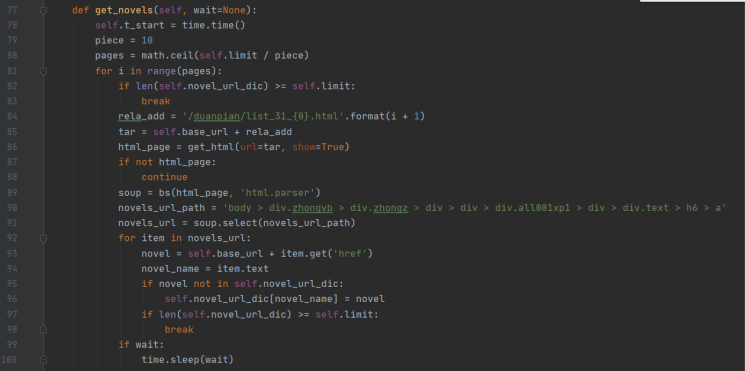
爬虫在爬取时会随机选择一个 UA 作为浏览器头,然后对目标链接进行访问。访问成功后会根据目的进行解析,比如解析章节列表或解析文本内容:
爬虫部分的处理工作大同小异,故不再赘述,仍以信息检索相关工作为重点进行介绍。
查询表的建立
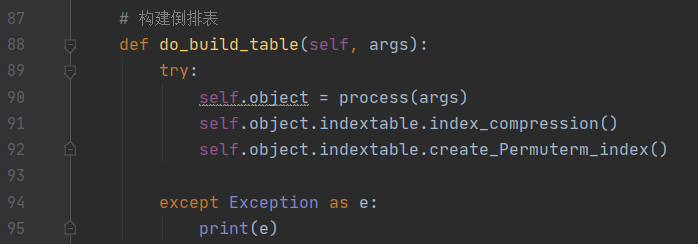
在使用整个系统进行信息检索相关工作之前需要先构建查询表,该部分通过命令build_table 实现。构建完查询表之后才能进行布尔检索模型、通配符查询模型、短语查询模型等的工作。该部分的工作主要由四部分构成:预处理、倒排表构建、倒排表压缩、轮排索引构建。
预处理
预处理主要包括切词、词条化、词归一化等操作:
在对用户输入的文本语言进行解析后,process 通过 readfiles 方法读取文件:
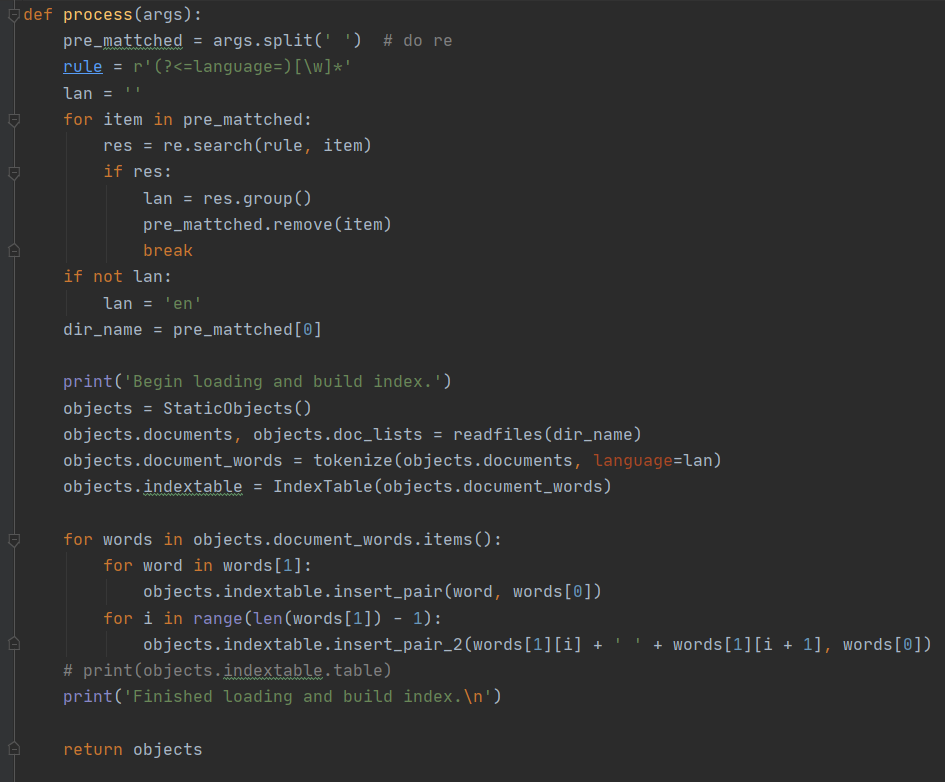
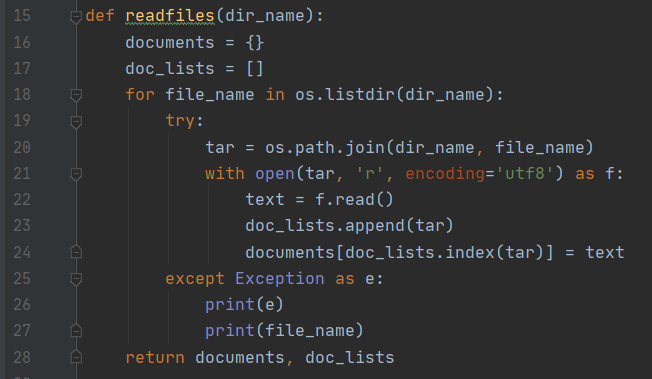
该方法会将文件名映射为文档 ID,并读取文档内容。除了输出结果时会用到文档名之外,之后所有涉及到文档名的操作都会通过文档 ID 来替代,以达到节省内存和提高性能的目的。process随后调用 tokenize 方法对其进行词条化处理:
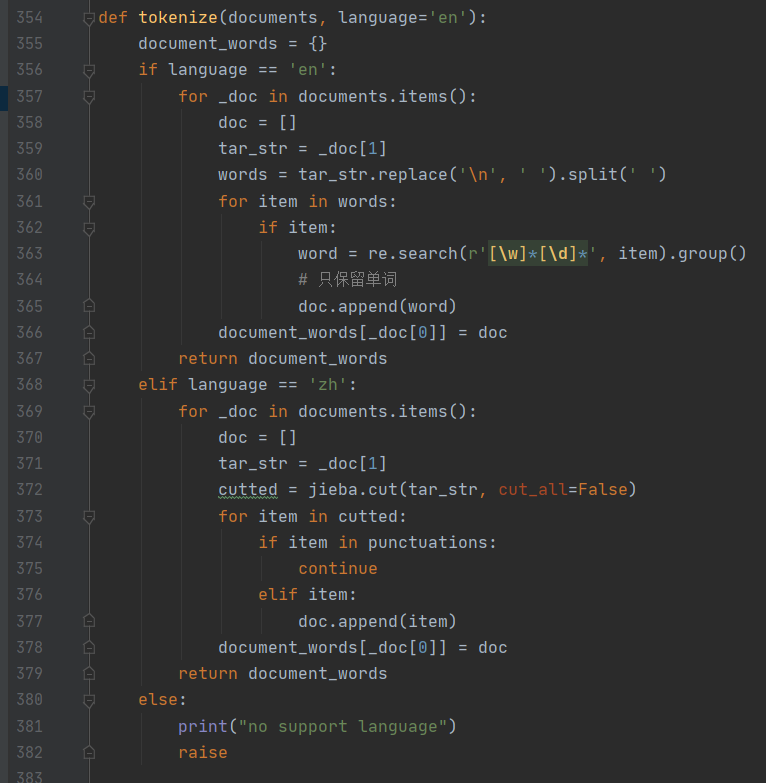
tokenize会根据用户传进来的参数分别用对英文的方法和对中文的方法对文本进行词条化处理,其中针对中文主要用到 jieba 库,针对英文则通过简单的分割以及正则匹配实现切词。虽然这里有针对中文的解析,但实际上系统目前是不支持对中文的信息检索工作的,因为中文处理起来稍有些麻烦且被时间所迫,所以后续的工作中并不支持对中文的检索操作。

倒排表的构建
切词完成后会将切好的结果以{文档:词列表}的格式存储到一个字典对象中,随后process 将其传入 IndexTable 类中初始化。
IndexTable 类是索引表的集合类,包括索引表的定义以及各种操作方法:
此时仅得到了一片片文档以及文档中的每一个词,并没有进行任何统计工作。之后process 会将结果中的词频等数量信息进行统计,得到一个{词项:文档 ID 列表}的统计结果。
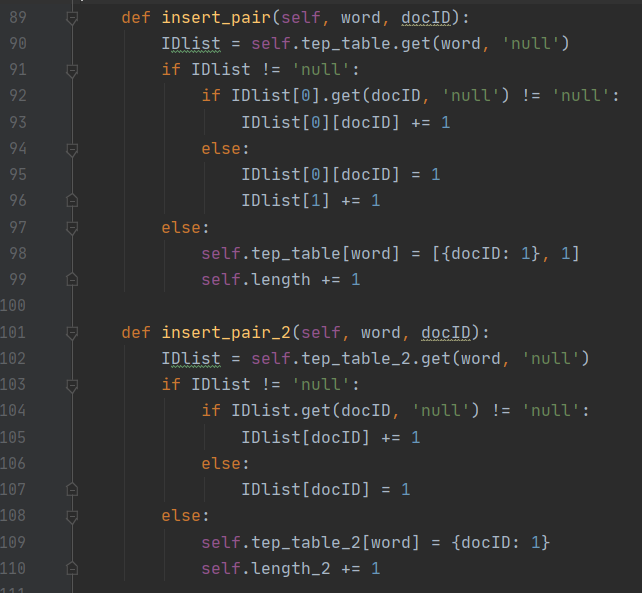
在统计完成后 process 通过调用 IndexTable 的 insert_pair 和 insert_pair_2 的方法完成索引表的构建。insert_pair和 insert_pair_2 的方法如下图所示:
这两个函数的逻辑是一样的,只是会根据不同的使用目的将结果存储到不同的对象中。这两个函数会将统计结果的词按字母序进行排序,然后将同一词项合并,最后将词项和文档ID 分开的同时统计词频信息。最终将词项连通其文档频率一起存储在词典中,每个词项都有一个指针指向自己的倒排记录表(此处借用 python 中的字典对象实现),倒排表存储了词项出现的文档列表及词项在对应文档中出现的次数。在所有的词项及文档都被遍历完后,一个全体倒排记录表也就构建完成了,其结构类似下图所示:
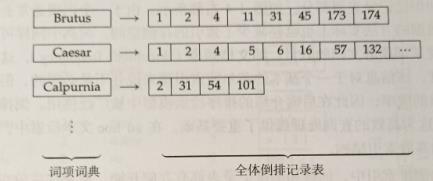

摘自《信息检索导论》第 1章第 2节
倒排表的压缩
考虑到当文档数目很大时,系统的性能可能有一定程度的下降,同时内存开销也会有一定程度的增大。因此,为了获得较好的查询性能,有必要对倒排表采用一定的压缩算法。这里采用《信息检索导论》第 5 章第 3 节第 1 小节所提到的 VB 编码对其进行压缩。
VB(Variable byte, 可变字节)编码利用整数个字节来对间距编码。字节的后 7 位是间距的有效编码区,而第 1 位是延续位(continuation bit)。如果该位为 1,则表明本字节是某个间距编码的最后一个字节,否则不是。要对一个可变字节编码进行解码,可以读入一段字节序列,其中前面的字节的延续位都为 0,而最后一个字节的延续位为 1。根据上述标识可以把每个字节的 7 位部分抽取出来并连接在一起形成编码。下表给出了一个采用 VB 编码的例子:
摘自《信息检索导论》5.3.1 表 5-4
下图给出了 VB 编码和解码的伪代码:
摘自《信息检索导论》5.3.1 图 5-8

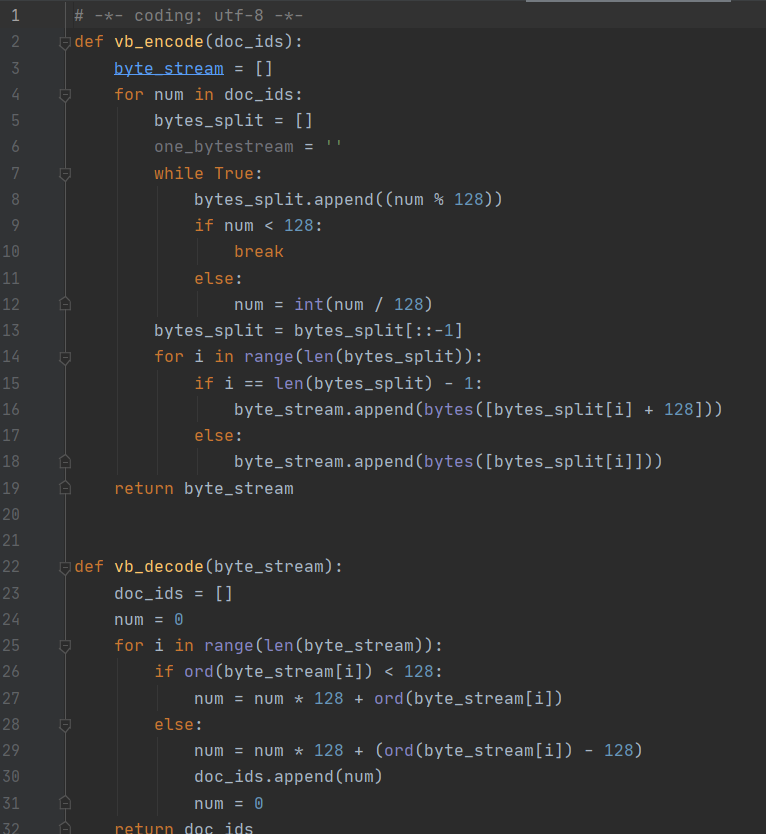
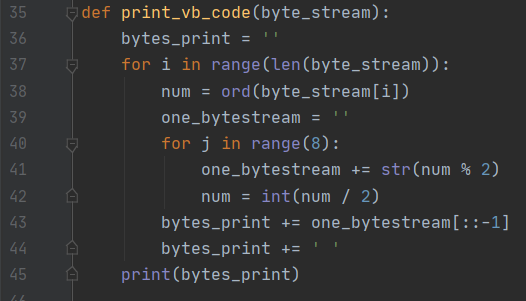
据此写出 VB 压缩编码的代码实现如下图所示:
可以通过命令 show_index word 来查看指定词的压缩编码:
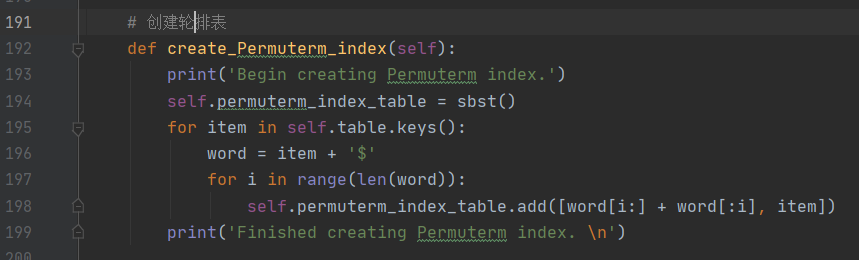
构建轮排索引
为了进行通配符查询,有必要建立一个轮排索引表。通配符查询有以下一些种类:1、尾通配符查询 mon :找出所有包含以 mon 开头的词项的文档首通配符查询 mon:找出所有包含以 mon 结尾的词项的文档
中间通配符查询 m*cine:找出所有包含以 m开头并以 cine 结尾的词项的文档轮排索引表是倒排索引的一种特殊形式。在构建时,先在字符集中引入一个符号'$'以标识词项的结束。对于词项 hello,(hello$, ello$h, llo$he,lo$hel,和 o$hell )是其轮排词汇集,每个扩展词都指向原始词项。
在该部分仅需构建轮排索引表即可,不涉及查询的步骤。构建轮排索引表时,为便于操作,采用 B-树(159 行)的数据结构,其部分内容如下图所示:
直接使用网络上现成的实现。至此,查询表已经建立完毕。
布尔查询
在倒排索引表建立完成后就可以编写布尔查询的相关代码:
change_k 函数将检查用户是否更改目标输出数量,以及如果有更改的话用户想要将其更改为多少。

布尔查询主要包括 AND、NOT、OR 操作。其中 AND 相当于是求交集、OR 相当于求并集、NOT 相当于去重叠。
以 AND 操作为例,求交集时相当于对 AND 前后的两个词的倒排记录表做合并操作,其伪码如下所示:
两个倒排记录表的合并算法,摘自《信息检索导论》1.3 图 1-6
当然,实际上不必这么麻烦,python 可以很方便地对两个列表进行与或非的操作。最差的布尔查询是依次对每个操作进行处理,然而实际上不同操作符之间通过一定的优先级定义就可以达到优化效率的效果。同时考虑到用户可能会任意组合三种操作,且可能用“(”和“)”来提高部分操作的优先级,因此采用栈结构来进行布尔查询的操作:
定义两个栈:stack 和 op,其中 stack 用于存取单词,op 用于存取操作。从左到右依次扫描,扫描到“(”时直接添加,扫描到“)”时则将 op 中的操作依次出栈对 stack 做操作,扫描到操作符时,如果当前操作符的优先级比栈顶操作符的优先级更高,则将 op 中的操作符出栈并对 stack 做操作。通过这样的规则来使得操作倒排表一点点减小,直到最后剩下一个最终结果。
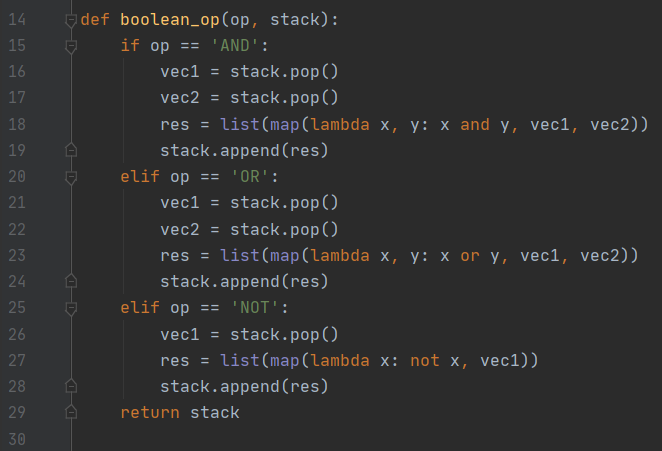
对表的与或非操作的代码由 boolean_op 函数实现,其中定义了一系列匿名函数来实现与或非的操作:
在所有栈清空且检查后发现输入无误后即可进行解码返回结果操作(281 行)。由于之前得到的结果是若干个二级列表,通过解码将其返回为一个一级列表。
至此,布尔查询模块结束。
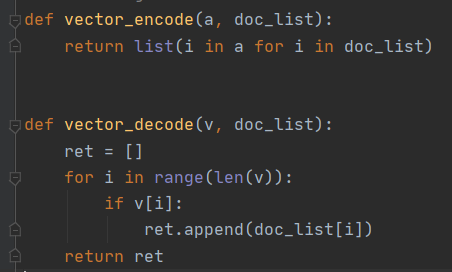
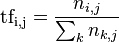



TF-IDF 值的计算
TF-IDF 是常用的加权技术,TF 是词频(Term Frequency),表示词条(关键字)在文本中出现的频率;IDF是逆文本频率指数(Inverse Document Frequency),某一特定词语的 IDF可以由总文件数目除以包含该词语的文件的数目(一般会将分母+1 以做平滑),再将得到的商取对数得到。
如果包含词条 t 的文档越少, IDF 越大,则说明词条具有很好的类别区分能力。其计算公式分别如下图所示:
TF-IDF的值就是 TF与 IDF的乘积。
原理很简单,代码实现也很简单:
通配符查询
前面提到,查询需要有一个轮排索引表,所以该模块会自动检查轮排索引表是否存在,若不存在则自动进行建立。建立的过程如前所述。
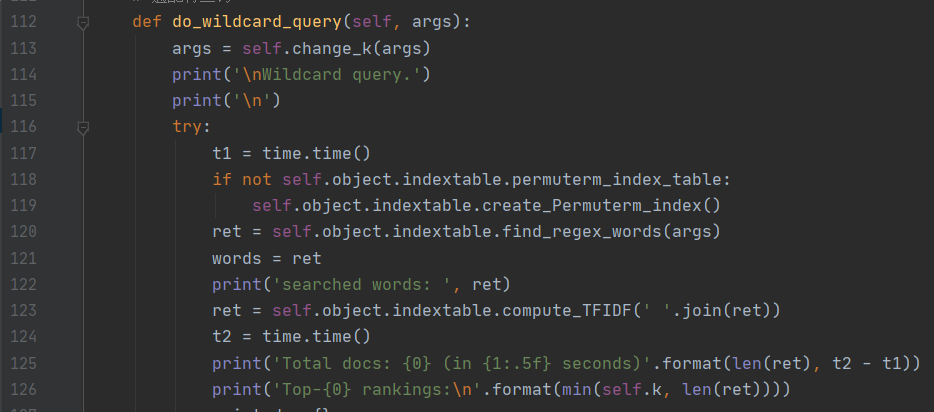
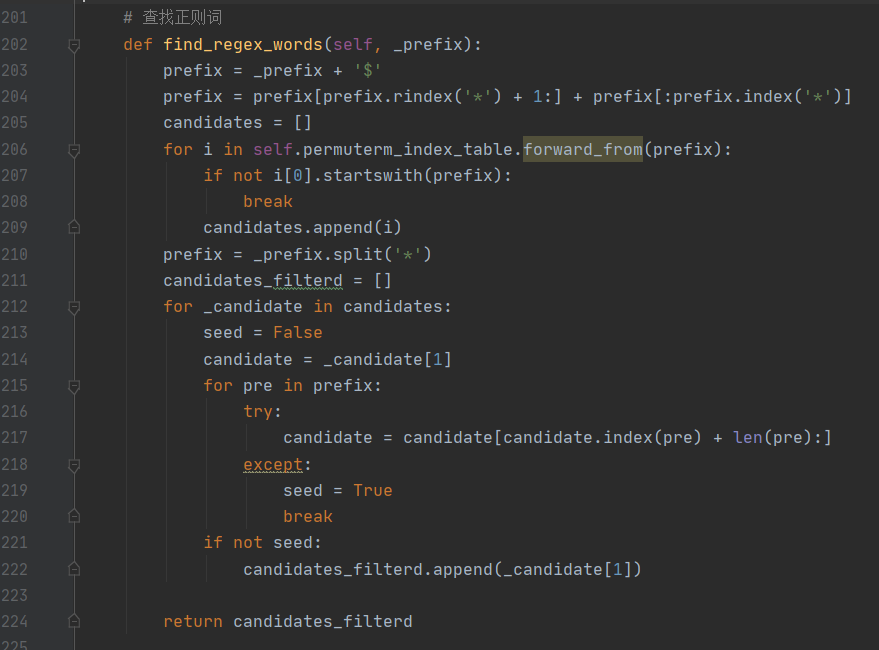
在轮排索引表建立完成后就要查找正则词,前面提到了用$做词结束标识和用 B-树做轮排操作,基于此,在做通配符查询时,首先将每个通配查询词项进行旋转,使*出现在末尾,然后在轮排索引的 B-树中搜索,最后将搜索结果映射到常规词项。例如:
-
对于 X,查询 X$ ;
-
对于 X ,查询 X*;
-
对于 X Y,查询 Y$X 。
例如,对于 hel o,查询 o$hel ;对于 fi mo er,先查 er$fi*,再除去不包含 mo 的词项。基于以上思想先做旋转操作,再将旋转后的结果与词典进行匹配,然后返回符合要求的候选词作为待查询结果。
之后就只需要根据候选测的倒排表查询对应文档及摘要信息即可。
短语查询
短语查询通过 phrase_query部分实现,总体流程如下图所示:
其中 phrase_query部分的代码如下图所示:
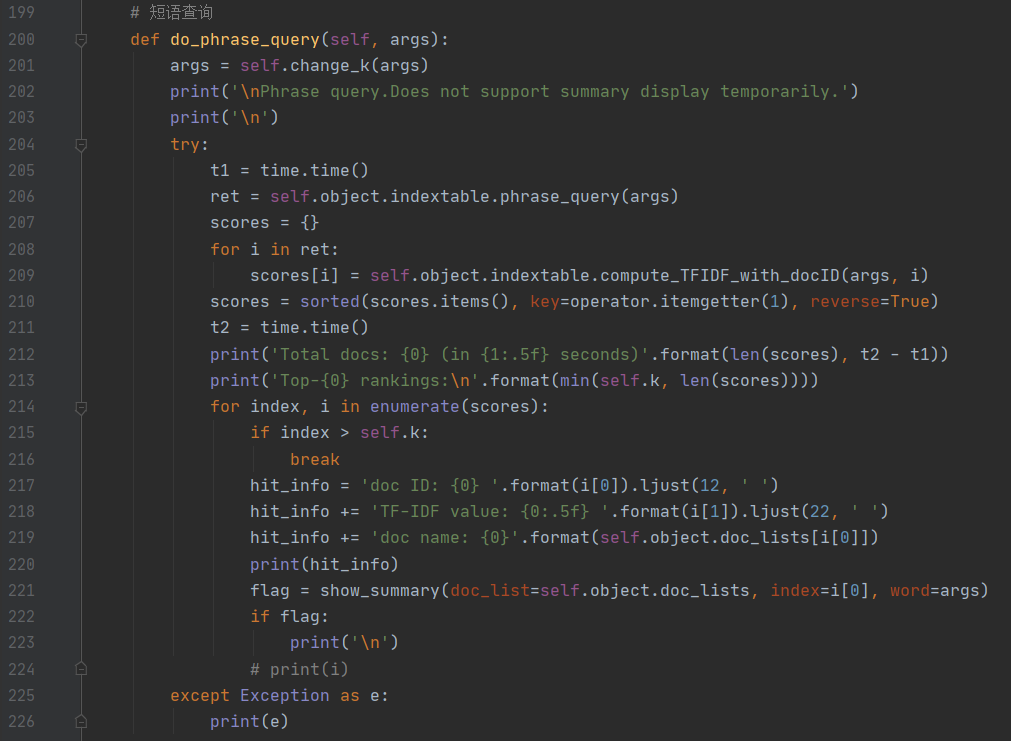
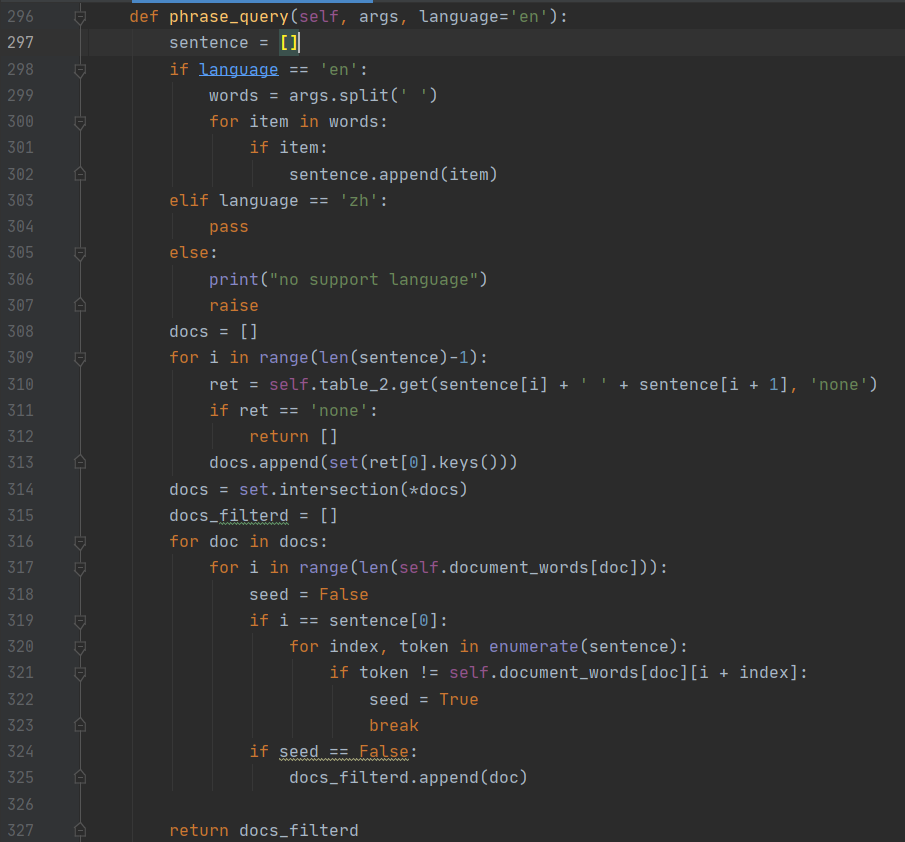
其实很简单,就是把短语做一下切词操作,然后对每个词的索引表做一次合并,如果存在未登录词则将其忽略掉,然后返回结果并对指定文档和指定词组中的每一个词求 TF-IDF以获得相关性分数,并以此作为评级标准。
结果数目更改
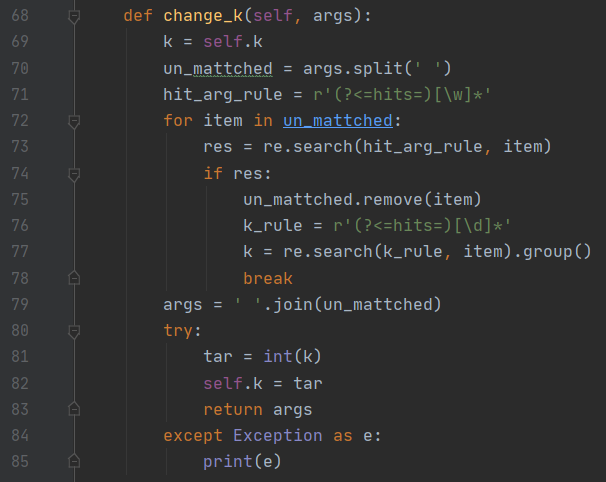
用户通过—hits 参数可以更改结果的输出数目,通过自定义一个 change_k 函数来检测用户是否选择更改结果的输出数目(默认是 10):
这部分代码实现很简单,通过一个正后发断言检测用户是否键入了—hits 参数,再通过另一个正后发断言来获取数字部分,最后将其转化为整数即可。
【实验结果分析】:
本查询系统目前仅支持对英文 txt 文本的信息检索工作。本部分将围绕以下 7 个模块依次予以解释和分析:用户交互、数据获取、查询表的建立、VB 编码查询、布尔查询、通配符查询、短语查询。
用户交互:
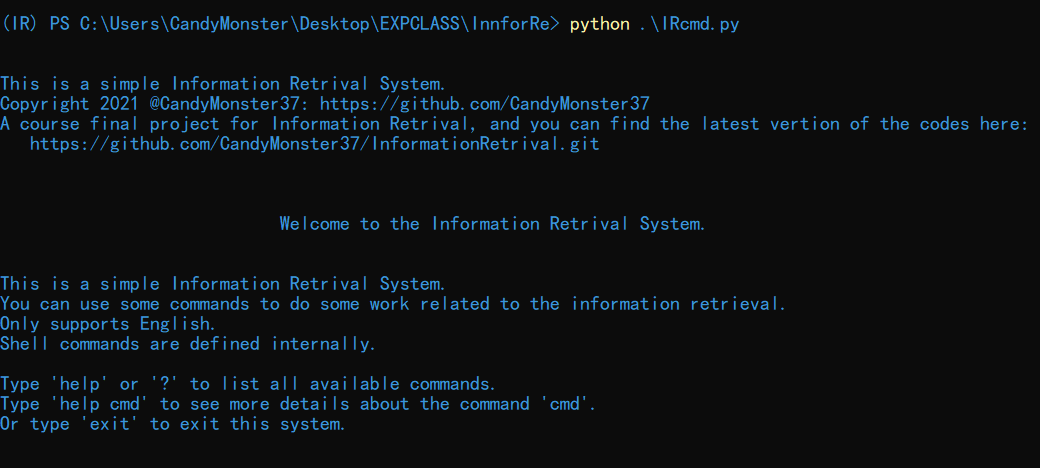
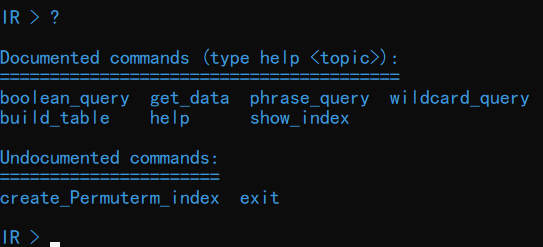
在命令行输入命令:python ./IRcmder.py,可以看到初始界面如下图所示:
初始时会输出一些提示信息,包括代码所存储的 GitHub 仓库地址、关于本系统的一些简短的介绍,以及初始命令。输入 help 或者?可以查看命令列表:
输入 exit 可以退出运行:


可以输入 help command 查看更详细的命令介绍,这一点在之后的部分依次予以展示。2、数据获取:
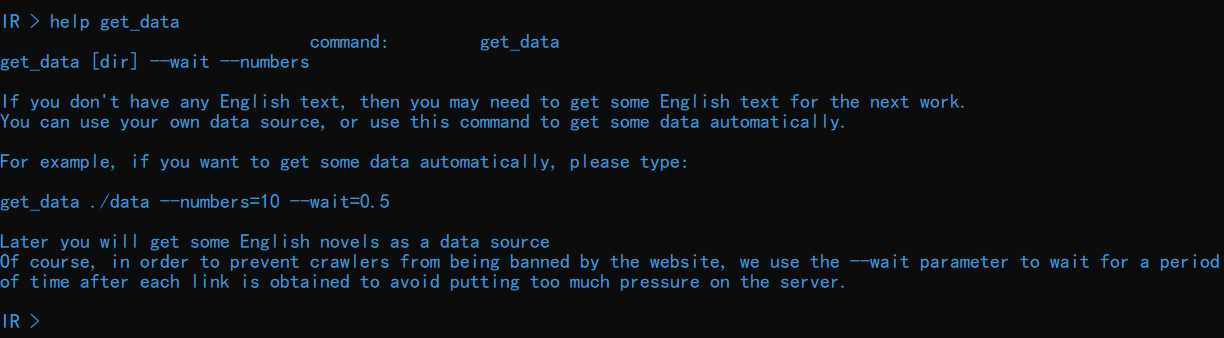
该部分功能通过 get_data 命令实现。输入 help get_data 查看关于该命令的详细介绍:
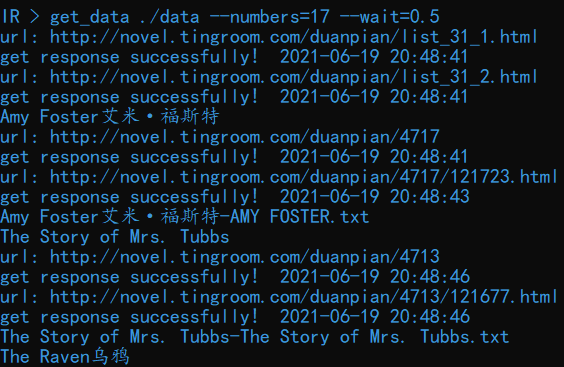
输入命令get_data ./data –numbers=17 –wait=0.5可以从内置的某英文小说网站获取17篇短篇小说并保存到./data 目录下。每获取一个链接,爬虫都会等待 0.5s,以防止被服务器封停。爬取结果如下图所示:
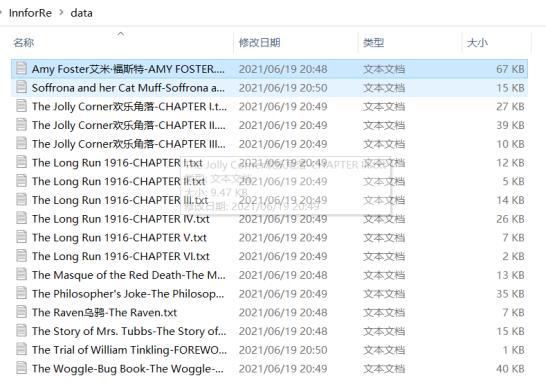
部分内容如下图所示:


可以看到爬虫的运行花费了较长的时间,这是因为爬虫实际访问的链接数大于保存的文本数。在爬取过程中,可能由于网络问题也可能由于服务器的问题等,可能会出现资源访问失败的情况(如下图所示):
因此耽误了一些时间。
查询表的建立
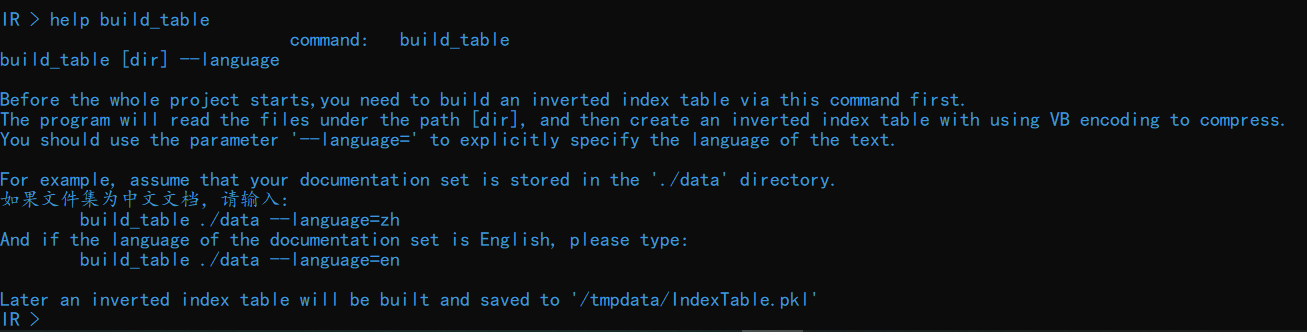
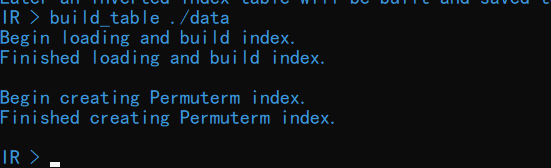
查询表部分的功能通过 build_table 命令实现。输入 help build_table 查看关于该命令的详细介绍:
输入命令 build_table ./data可以从./data 目录下读取文件并建立查询表。
整个过程并不会花费太多时间。


查看指定词的 VB 编码
可以使用命令 show_index 查看指定词的 VB 压缩码。输入 help show_index 查看关于该命令的详细介绍:
输入命令 show_index we 可以查看单词 we 的 VB 压缩码:
这里分别测试了单词 we、he、what。
布尔查询
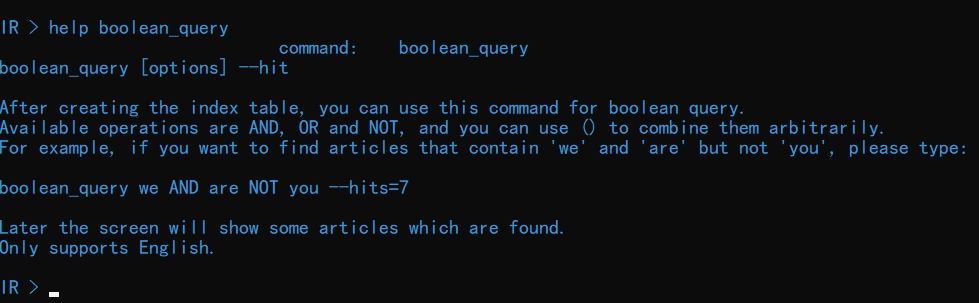
可以使用命令 boolean_query对指定操作进行布尔查询。输入 help boolean_query查看关于该命令的详细介绍:
输入命令 boolean_query (we OR you) AND (he OR she) AND NOT( kill OR dead)可以查看包含 we 或者 you、且包含 he 或者 she、且不包含 kill 或者 dead的文档:
速度还是比较快的,小数点后 5 位都捕捉不到时间的变化。加入—hits 参数可以限制结果的展示数量,如输入命令 boolean_query (we OR you) AND (he OR she) AND NOT( kill OR
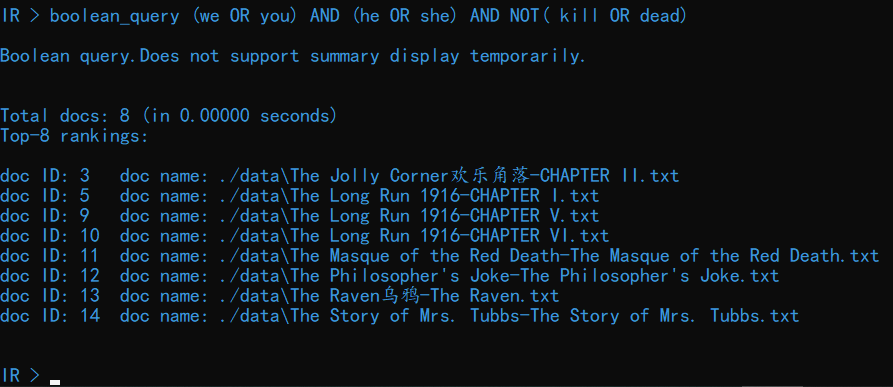

–hits=5:
可以看到共有 8 篇文档满足要求,只展示了前 5 篇文档。
通配符查询
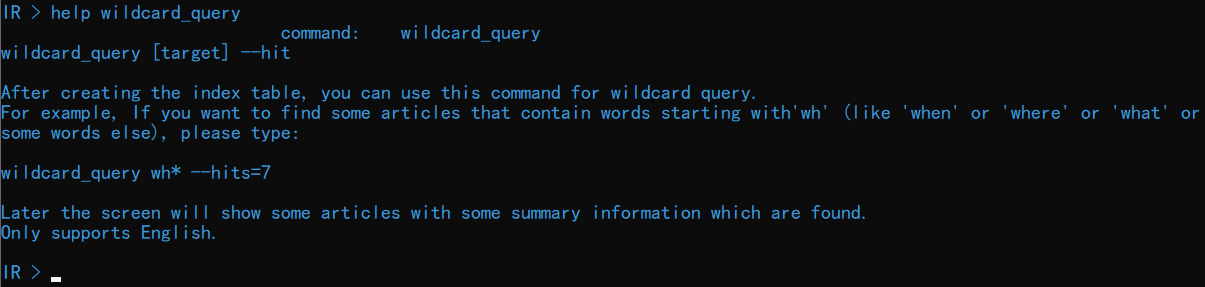
使用命令 wildcard_query 对指定缺省词进行通配符查询,输入 help wildcard_query查看关于该命令的详细介绍:
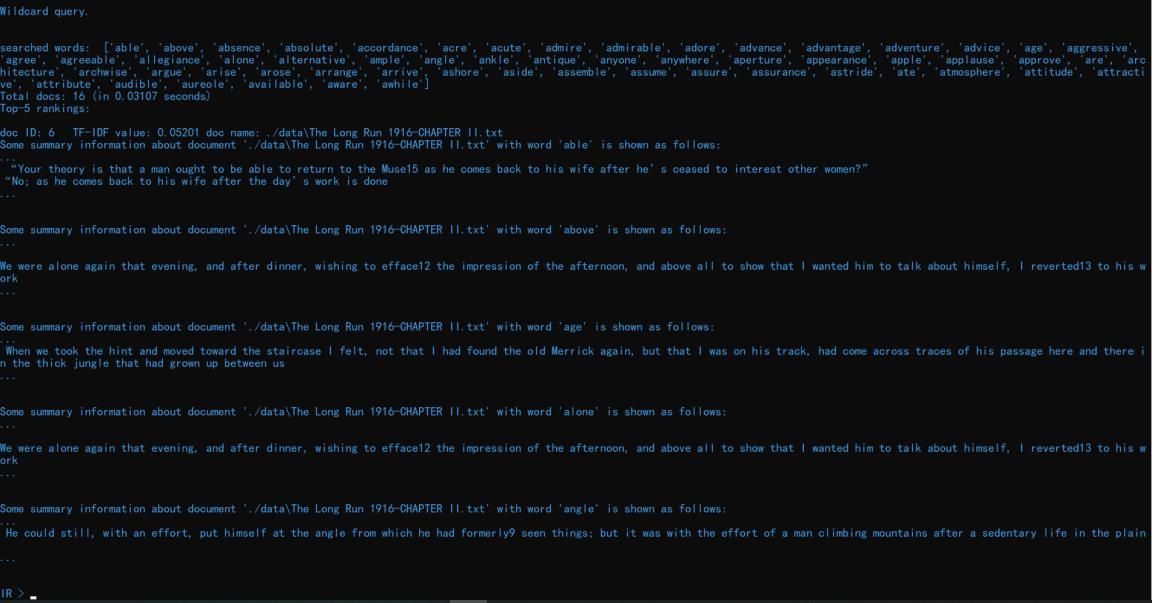
输入命令 wildcard_query a*e 可以查看包含以 a 开头以 e 结尾的单词的文档:
可以看到其候选词有很多,如'able', 'above', 'absence', 'absolute'等。总共找到了 16 篇符合要求的文档,这里输出了前 5 篇(这里是以输出的文档个数为标准计数的,同一篇文档、不同词汇也会累加)。
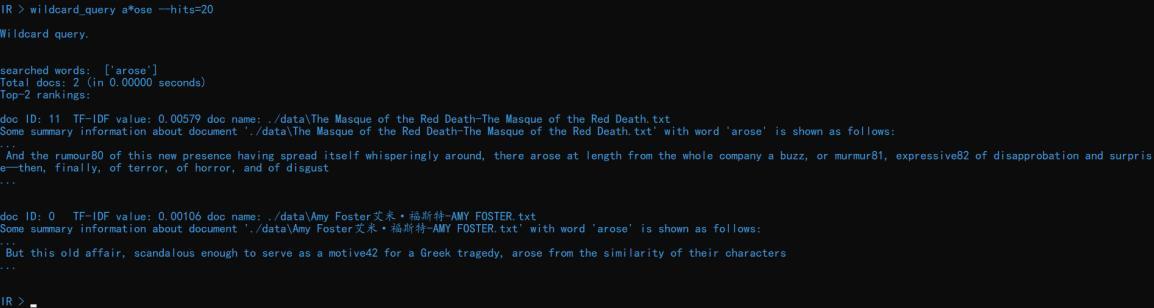
加入—hits 参数可以改变结果的显示数量,如 wildcard_query a ose --hits=20 就可以显示包含 a ose 单词的前 20 份结果:
当然,如果文档没有那么多的话只会显示找到的文档。
短语查询
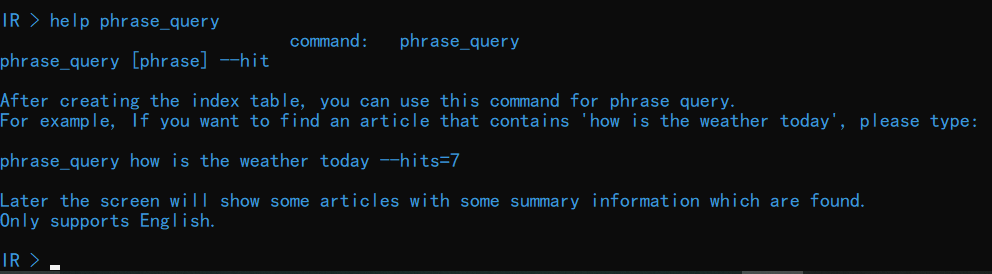
短语查询需要使用命令 phrase_query,从而对指定短语进行查询,输入 help phrase_query查看关于该命令的详细介绍:
输入 phrase_query New York 可以查看包含 New York 的文档及摘要信息:
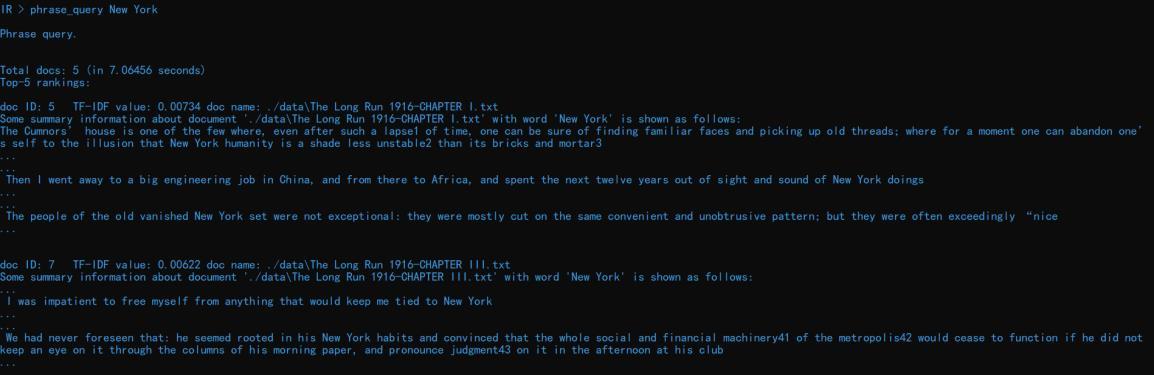

同样地可以通过—hits 参数限制输出的结果数目,如输入命令 phrase_query I loved her--hits=3 可以显示最多 3 篇包含短语 I loved her 的文档:
当然,同样会受到实际文档数目的限制。
【实验总结】:
总体来讲,本项目已经基本实现了针对文档的布尔查询、通配符查询、词组查询等功能,
然而还是略有改进之处:
不支持单个词查找。这部分是我的疏忽,因为一直觉得是一个很简单的功能所以一直就没有做,直到写实验报告的时候才发现忘了实现这个功能,然而时间上已经来不及了。
其实实现很简单,只需要直接查倒排表中的指定词项即可获取对应的文档 ID,然后依次输出即可。
文档摘要输出不够美观。这部分我一直在调试,尝试更换不同的输出格式,仍然没办法做到整齐、简约,这是我自己审美有一点点问题。
目前仅支持对英文文档的操作。其实我在做的时候有考虑对中文文档做检索,想到jieba 可以很容易地分词,进而也应该可以做信息检索工作。然而实际在实现的时候仍然有些理不清楚,中文的词与词之间、词与字之间的界限并不像英文那样明晰,做到什么样的截取能卡到一个刚好的边界,我实在是拿捏不准,因此暂时将其放弃,也希望能得到更好的指导。
未设计评价算法。一般而言,对于一个信息检索系统,需要有一个评价算法来评价其好坏,也需要一个标准测试集去验证它的好坏,这部分测试我迫于时间原因还未来得及做。
除去以上需要改进的地方,本项目也有一定的可圈可点之处,如:在英文文本上做检索的准确率较高、处理性能较好、能自动批量化获取数据、交互性强等。
此外,通过本次项目,我也明白了信息检索工作中的一些基本方法和基本原理,也提高了自己的代码能力和资料查找能力。信息检索是一门涉及面很广的学科,我目前所掌握的仅如海滩上的一湾小水坑,我仍有很多需要学习的地方。
参考文献
- 基于Lucene.NET的网络信息搜索系统的设计与实现(吉林大学·杜宁宁)
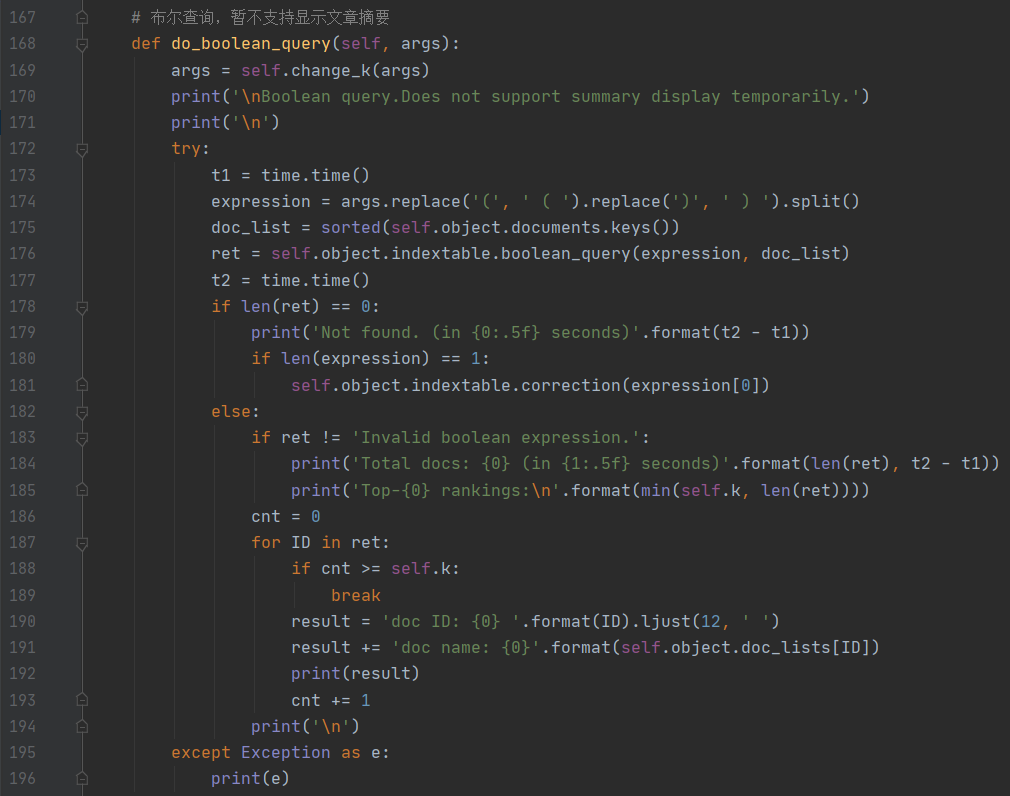
- 基于某军用信息系统数据库系统的设计与实现(华北工学院·马巧梅)
- 分布式网络爬虫在农产品搜索系统中的应用与研究(南昌大学·袁龙涛)
- 基于Lucene.NET的网络信息搜索系统的设计与实现(吉林大学·杜宁宁)
- 基于知识的计算机软件技术转移平台的设计与实现(北京邮电大学·李兴华)
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- 基于JADE平台的网络信息搜索与集成系统(天津大学·旭日)
- 基于J2EE的多语种元搜索引擎的研究与实现(电子科技大学·冯刚)
- 面向特定网页的Web爬虫的设计与实现(吉林大学·马慧)
- 分布式网络爬虫在农产品搜索系统中的应用与研究(南昌大学·袁龙涛)
- 基于网络爬虫的电影集成搜索系统设计与实现(江西农业大学·江沛)
- 基于Lucene的网页抓取与检索系统(东北大学·席齐)
- 基于Lucene的商品垂直搜索引擎研究与实现(东华大学·潘磊宁)
- 基于网络爬虫的信息采集分类系统设计与实现(厦门大学·周茜)
- 电子商务平台中搜索系统的设计与实现(郑州大学·刘海泽)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码项目助手 ,原文地址:https://bishedaima.com/yuanma/36170.html









