预测商品销售数据
实验目的
通过使用一个具有挑战性的时间序列数据集,该数据集由每日销售数据,由俄罗斯最大的软件公司之一 1C 公司提供。
数据集中提供了 2013 年 1 月到 2015 年 10 月每日每个店铺中的商品历史销售数据。任务是为测试集预测每家商店销售的产品总量。请注意,商店和产品列表每个月都会略有变化。创建可以处理此类情况的强大模型是挑战的一部分。
要求:预测下个月(也就是 2015 年 11 月)一整个月每个商店中对应产品的的总销售额。
数据集分析
所有的数据都存储在/data 文件夹下,文件夹中共有六个文件,分别是
sales_train.csv- 训练数据集,包含了从 2013 年 1 月到 2015 年 10 月的销售历史数据。
test.csv- 测试数据集,该任务需要用训练集中的数据来预测 2015 年 11 月的销售数据。
sample_submission.csv- 一个提交样例。
items.csv- 关于商品的补充信息。
item_categories.csv - 关于商品类别的补充信息。
shops.csv- 关于店铺的补充信息。
文件中会包含以下条目:
ID-在测试集中表示(店铺,商品)的 id。
shop_id- 店铺的唯一标识符。
item_id-商品的唯一标识符。
item_category_id-商品类别的唯一标识符。
item_cnt_day- 商品的销售数量,需要预测商品的月销量。
item_price- 商品的现价。
date-以 dd/mm/yyyy 为格式的日期
date_block_num- 按照顺序的月份简写,期中 2013 年 1 月为 0,2013 年 2 月为 1,....,2015 年 10 月为 33。
item_name- 商品的名称。
shop_name- 店铺的名称。
item_category_name- 类别的名称。
在了解了各个条目的含义之后,我们需要对数据进行分析,来确定如何处理和使用这些数据,根据题目中对数据的介绍,我们需要训练的文件主要是 sales_train.csv,该 CSV 文件中包含了日期、月份、商店序号、商品序号、商品价格和每日的销售数量信息。
既然题目中要求我们预测 2015 年 11 月的销售数据,我们可以先将所有的训练数据按照店铺进行分类,在针对每个店铺按照不同商品进行分割,最后根据时间顺序训练出相关的预测模型。模型的预测可以按照月份进行预测,也可以根据每一天的预测数据进行累加。
因此整个实验的具体步骤为:
读取数据
按照商店序号对数据进行分割
按照商品序号对每个店铺中的商品进行分割
针对每个商品的销售数据进行拟合
预测每个商品的销售量
按照要求进行输出
实验内容
整个实验主要分为数据处理(数据分析、数据清洗)和模型搭建两个部分。
其中数据处理部分主要用于了解各类数据的分布情况,在通过对数据有一定的掌握之后,通过对数据集的调整操作来获取适合用于训练的训练数据。
模型搭建部分则需要根据数据的特点来选择适合的训练模型,并且对参数进行适当的调整,以获取最好的实验结果。
读取并分析数据
操作概述:通过 pandas 库读取 CSV 文件,使用 matplotlib 画出各类元素的分布情况,再根据分布图进行分析。
商品价格分布:
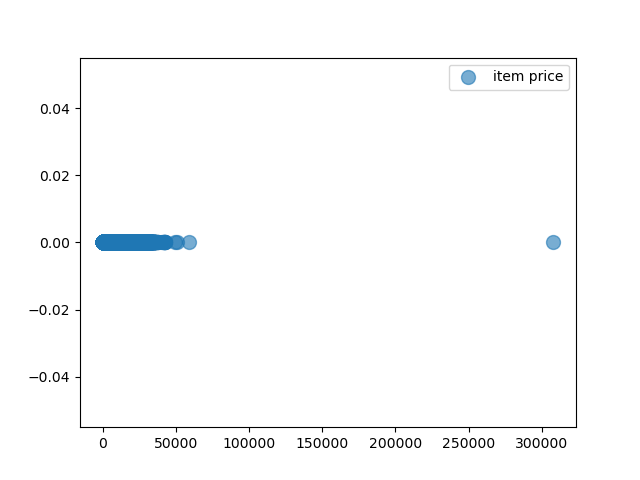
分析:存在一些数值较大的干扰值,在清洗数据时应将 item price 限制在 10,000 以下。
商品销量分布:
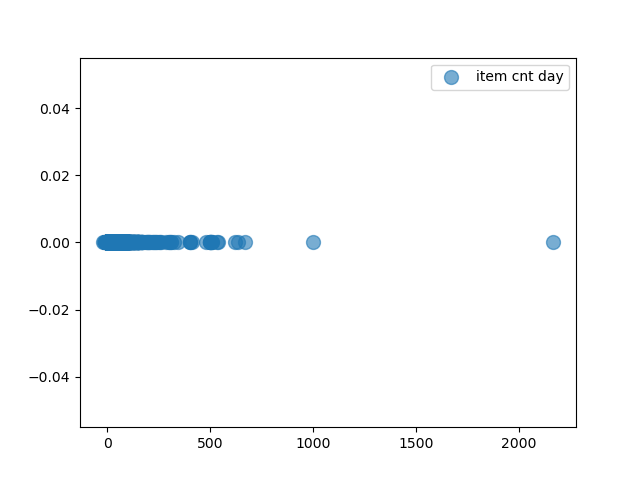
分析:存在一些数值较大的干扰值,在清洗数据时应将 item cnt day 限制在 1,000 以下。
月份分布:
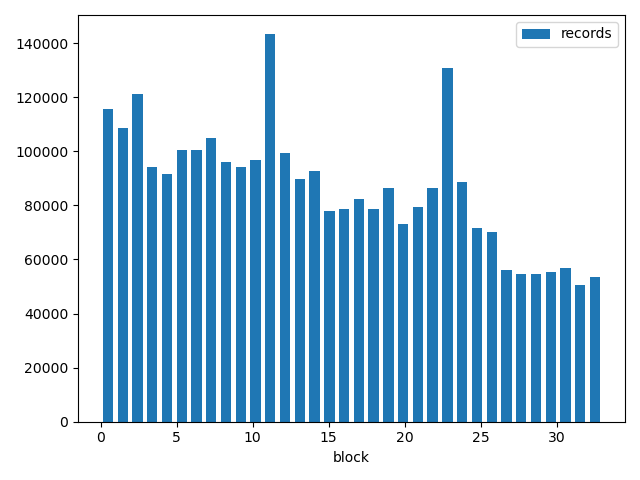
分析:每个月份均有售卖的商品,无需进行特别的处理。
在对商品价格和商品的月份销量进行分析之后,我还对比了每月销售数据的和与均值信息。
销售数据月度分布:
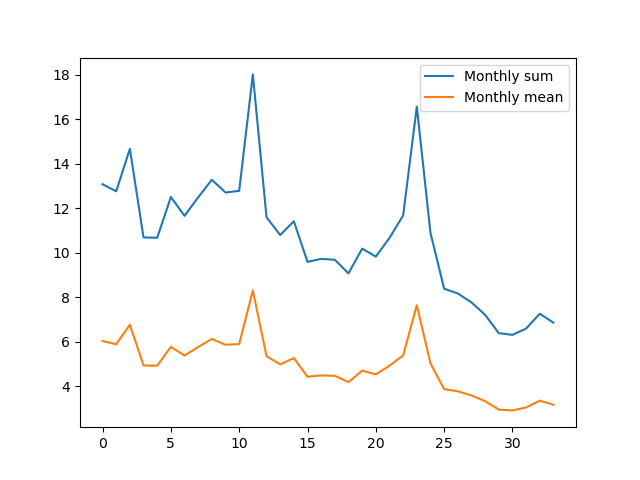
分析:月均值与月销量和的走势基本保持一致。
数据内容分析
在对数据的整体分布进行分析之后,我通过观察数据表格发现,有一些商品在售卖几个月后就再也不售卖了。同时,有一些商品是在距离统计时间前几个月才开始售卖,我认为应该要对这些商品销售信息进行处理,不然会影响到预测的结果。
对于商品信息,我选择以最后六个月没有销售数据作为商品过期(outdated)的标准,通过按照商品编号统计商品在最后六个月的销售数据之和来判断商品的状态,根据统计,共有 12347 件商品属于过期状态。
除了商品会有销售数据的中断,店铺的销售数据也会中断。因此,我设计了两个集合,分别为 not_exist 和 outdated,not_exist 集合用来存放那些在前 k 个月份中没有售卖数据的店铺;outdated 集合用来存放那些在第 k 个月后没有售卖数据的店铺。在具体分析时需要使用到这些店铺信息。
数据的提取
在对数据集进行分析后,我发现,判断一个商品的销售情况,不仅需要考虑其商品编号,还要考虑其所在出售的店铺的信息,因此在进行统计的时候,应该采用(shop_id, item_id)的元组对来进行表示。
于是在数据处理之后,我首先按照日期的顺序对整个数据集进行排序,将 shop_id 和 item_id 两个列作为主键,让数据按照这两列进行排列,并且在排列完成后删去这两列元素,使用完全是按月结算的销售数据来进行模型的输入。
在训练时,训练数据应为数据集的前 n-1 列,而每行数据的标签应该就是改行的最后一个数值。在数据提取的操作中需要提前将训练集进行分割,提取到训练数据和训练标签。
建立模型
根据数据提取阶段获得的数据,可以非常直接明了地看出这是一个时序模型,数据间的转换是和时间高度相关的,第 n 天的销售数据会与前 n-1 天的销售数据有直接的影响,因此可以选择常用的用于处理时序数据的深度学习模型 LSTM(Long-Short Term Model)来对数据集进行训练,学习出商品销量间的关系,并用学习到的模型对验证集中的数据进行处理。
获取结果
通过以上几步,就可以获得对应的销售数据预测模型,根据这个模型以及题目中给出的测试集,可以很简单的生成出最终的提交结果“submission.csv”。
实验步骤和结果
读取数据
通过调用 pandas 库中的 read_csv 方法读取数据集文件。
分析数据分布
依次分析商品价格、商品销售数量、月份销售数量的分布情况
```c++ print("-----AnalyzeItemPrice")
analyzethedistributionofprices
all_prices=[x[4]forxintqdm(sales_train_data_np)] y=[0]*len(all_prices) plt.scatter(all_prices,y,alpha=0.6,s=100) plt.legend(["itemprice",""]) plt.savefig("distributionofitemprice") print("-----AnalyzeItemCntDay")
analyzethesalesofitem
all_cnt=[x[5]forxintqdm(sales_train_data_np)] y=[0]*len(all_cnt) plt.scatter(all_cnt,y,alpha=0.6,s=100) plt.legend(["itemcntday",""]) plt.savefig("distributionofitemcntday") plt.show() print("-----AnalyzeDateBlock")
analyzethedistributionindateblocks
all_blocks=[x[1]forxintqdm(sales_train_data_np)] plt.hist(all_blocks,bins=max(all_blocks)+1,rwidth=0.7) plt.xlabel("block") plt.legend(["records"]) plt.savefig("./analysisresult/distributionofdateblock") plt.show() ```
根据数据分布情况对数据进行清洗
这里主要是获取销售价格在 0-10000 元以内的商品,以及日销量小于 1000 的商品,超出上述范围则可被认为是“脏数据”。
参考文献
- C4.5算法优化及其在工业品销售中应用研究(东华大学·谢颂天)
- 营促销场景下电商平台销量预测研究(南京大学·应舟丹)
- 电商平台的用户消费行为分析预测模型(重庆大学·张丽)
- 基于JSP的销售管理系统的设计(吉林大学·许玉娟)
- 商业智能的电商应用研究——以YPY油画公司精准营销为例(厦门大学·尤佳)
- 集采系统客户关系管理子系统设计与实现(大连理工大学·潘佩琦)
- 铁煤集团煤炭销售分析预测系统的设计与实现(东北大学·李洪霖)
- 电商平台的用户消费行为分析预测模型(重庆大学·张丽)
- 基于JSP的销售管理系统的设计(吉林大学·许玉娟)
- 样品出入库及销售预测分析系统的设计与实现(东华大学·袁琐云)
- 基于BS架构网络销售系统的设计与实现(吉林大学·赵彦龙)
- 超市商品销售管理系统的设计与实现(电子科技大学·刘华平)
- 手机销量预测系统的设计与实现(华中科技大学·马春来)
- 基于JSP的销售管理系统的设计(吉林大学·许玉娟)
- 集采系统客户关系管理子系统设计与实现(大连理工大学·潘佩琦)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设工坊 ,原文地址:https://bishedaima.com/yuanma/36115.html