图书管理系统
数据库 finalproject 实验报告
数据库设计
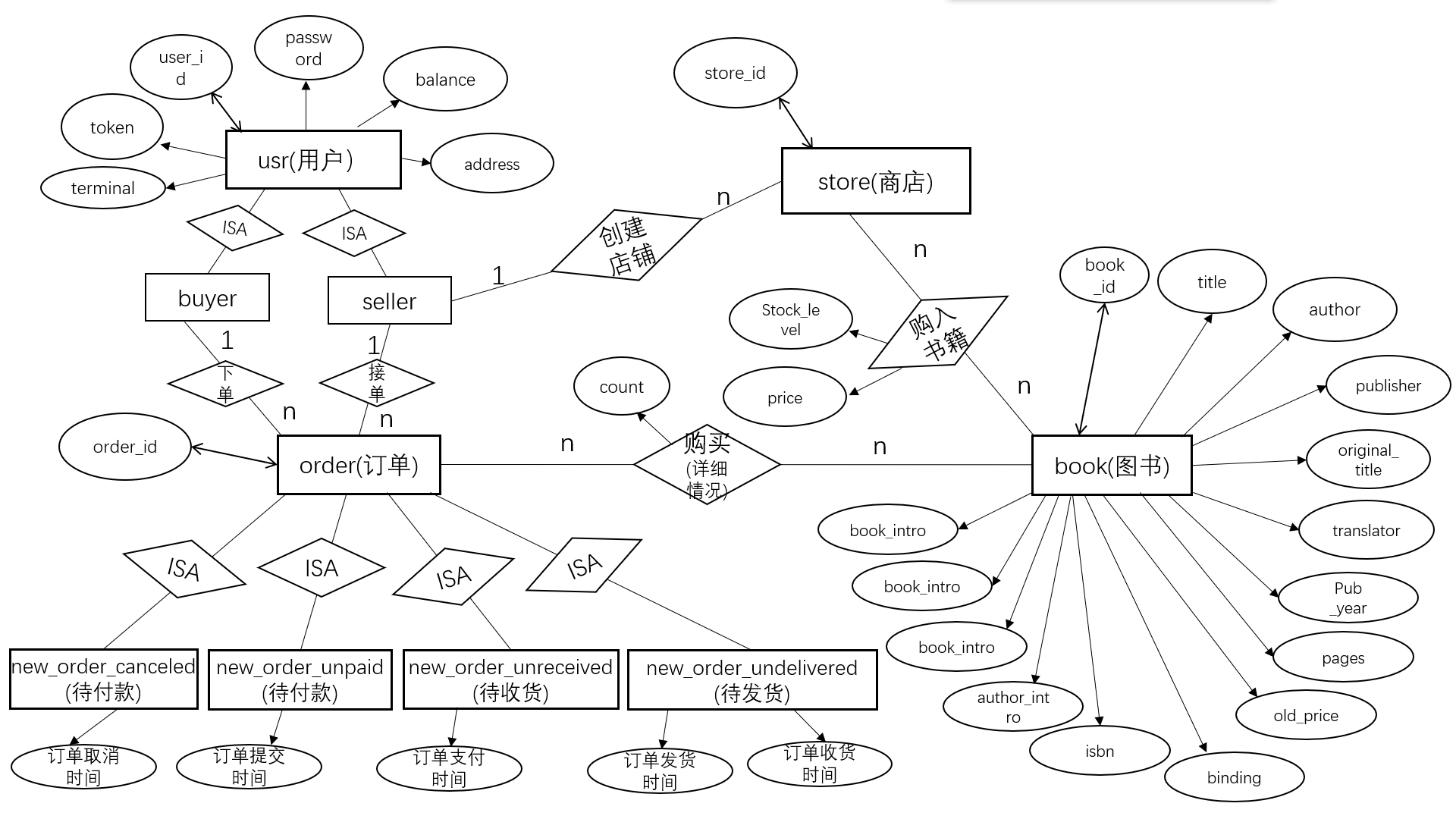
ER 图和导出的关系模型
- ER 图
 - 导出的关系模型
- 导出的关系模型

具体表的结构设计
用户/商店表
用户表
| FIELD | User_id | Password | Balance | Token | Terminal | Address |
|---|---|---|---|---|---|---|
| 类型 | String | String | Integer | String | String | String |
| 主键;唯一键 | 非空 | 非空 | 非空 | 非空 |
调整了原有用户表的结构,为收货发货做准备。当一个用户有多个收货地址时,可以考虑新增
user-address
表,满足一对多的关系。
用户-商店关系表
| FIELD | User_id | store_id |
|---|---|---|
| 类型 | String | String |
| 外键 | 唯一,非空 |
在数据库设计之初,我们在用户表中新增一列
username
,但是为了后面与 test 测试接口统一,将其删去。
username
和
user_id
的两个字段更符合真实场景中的设计逻辑,
user_id
可以是用户注册是的邮箱,手机号等,而
username
才是用户昵称等用户名。
store_id
也同理;
商店表(商店-图书)关系表
| FIELD | Store_id | Book_id | Stock_level | Price |
|---|---|---|---|---|
| 类型 | String | String | Integer | Integer |
| 外键 | 外键 | 非空 | 非空 |
订单总表
- 我们没有选择使用 status_code:0,1,2,去将待发货订单,已发货待收货订单,已收获订单进行区分,而是新增了 purchase_time 和三张不同的订单类型的表,更好的支持用户查看交易时间,发货时间和收获时间。
- 逻辑上,订单表中的 price 与(商店-图书)关系表中的 price 字段的含义一致,都是具有时间变化性的价格,即不同的商家针对不同的书目有着自己的定价和折扣,更好的模拟淘宝真实的交易过程(如建议零售价,原价和购物券的叠加等)
待付款订单
当用户下单之后,订单会按照这个格式插入该表中。order_id 为主码,区别不同的订单,buyer_id,store_id,price 是为了方面查找订单数据。commit_time 是为了记录提交订单时间和用于判断订单是否超时使用。
| FIELD | Order_id | buyer_id | Store_id | Price | commit_time |
|---|---|---|---|---|---|
| 类型 | String | String | String | Integer | DateTime |
| 主键 | 外键 | 外键 | 订单提交时间 |
待发货订单
当用户付款之后,订单会按照这个格式插入该表中。order_id 为主码,区别不同的订单,buyer_id,store_id,price 是为了方面查找订单数据。purchase_time 是为了记录付款订单时间。
| FIELD | Order_id | buyer_id | Store_id | Price | Purchase_time |
|---|---|---|---|---|---|
| 类型 | String | String | String | Integer | DateTime |
| 主键 | 外键 | 外键 | 订单付款时间 |
待收货订单
当卖家发货之后后,订单会按照这个格式插入该表中。order_id 为主码,区别不同的订单,buyer_id,store_id,price 是为了方面查找订单数据。send_time 是为卖家发货时间,receive_time 是记录买家的收货时间。
| FIELD | Order_id | buyer_id | Store_id | Price | send_time | Receive_time |
|---|---|---|---|---|---|---|
| 类型 | String | String | String | Integer | DateTime | DateTime |
| 主键 | 外键 | 外键 | 订单发货时间 | 订单收货时间 |
这里新增一个收货时间字段。这样加的目的由于我们功能中不涉及对收货订单的评价,不需要另外增加待评价订单。通过 receive_time 区分已发货订单和未发货订单,并在查询用户订单功能中支持查询已收货和已发货未收货订单。
已取消订单
淘宝应用中 new_order_detail 包括用户的所有订单,也应包含 new_order_cancel。new_order_cancel 与 new_order_undelivered 等的并集为 new_order。这样的添加使得订单的结构更加完善。对应需要修改手动删除,自动删除以及查询订单历史的函数。手动删除订单和自动删除后将对应订单插入该表。
| FIELD | Order_id | buyer_id | Store_id | Price | CANCEL_time |
|---|---|---|---|---|---|
| 类型 | String | String | String | Integer | DateTime |
| 主键 | 外键 | 外键 |
订单明细表
对于订单类型区分有订单总表和订单明细表的原因:
1.0 版本
| FIELD | order_id | Book_id | Count | Price |
|---|---|---|---|---|
| 类型 | String | String | Integre | Integer |
| 主键 | 外键 |
针对查询优化的 2.0 版本 --应用驱动优化
由于在查询用户历史订单的功能应用中遇到之前的表结构查询效率较慢的问题,需要查询一个 buyer 的所有订单时,要在 usr_store 里查 user 买过的 store 的 store_id, 再在 store 查买过的 book_id 再在 new_order_detail 查 book_id 对应的具体信息。
故在 new_order_detail 中添加冗余属性 store_id 和 buyer_id。
这样的修改方便用户查询所有订单信息,也方便卖家查自己店铺的所有订单信息。
| FIELD | order_id | Book_id | user_id | store_id | Count | Price |
|---|---|---|---|---|---|---|
| 类型 | String | String | String | String | Integer | Integer |
| 主键 | 外键 |
Book 表(与 book.db 的 schema 基本保持一致)
- 在这里,书的概念要做详细说明,book_id 不是表示的每一本书,而是每一类同名的书,如 A 店的《当代数据库管理系统》的 book_id 是 1,B 店的《当代数据库管理系统》这本书的 book_id 也是 1,他们的 book_id 相同,但是不同店,甚至是同一个店不同的交易定价,这些书可以拥有属于自己的不同的价格。比如 11.11 那天 0 点 A 店的《当代数据库管理系统》这本书可以是 30 元,11.11 日 0 点 B 店为 29.99 元。
- 在后续的进一步完善中,还可以使 A 店的《当代数据库管理系统》拥有不同的价格,在这里暂未实现
- 字段的 text 类型是为了全文索引功能的支持。
| FIELD | book_id | Title | Author | Publisher | Original_title | translator | Pub_year | Pages | Original_price | Binding | Isbn | Author_intro | book_intro | cont ent | tags |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 类型 | Integer | Text | Text | Text | Text | Text | Text | Text | Integer | Text | Text | Text | Text | Text | Text |
| 主键,自增 | 非空 |
功能实现与性能分析
所有功能实现的数据库增删改查操作使用 ORM 包装,避免 SQL 注入,保障安全性,且实现了事务处理。
user 功能
1.用户注册 register
功能实现:
- 根据 user_id 判断该用户名是否已经存在。若已存在通 error.error_exist_user_id(user_id)返回错误信息
- 插入 user_id、password、balance、token、termial 信息至 usr 表。其中 terminal 由 terminal_当前时间表示。token 由 jwt_encode 生成。
性能分析: usr 表一次根据 user_id 主键查询,一次插入。
2.用户注销 unregister
功能实现:
- 根据 user_id 查询该 user 是否存在。若不存在由 error.error_authorization_fail()返回错误信息
- 判断用户输入密码是否正确。若不正确由 error.error_authorization_fail()返回错误信息
- 删除根据 user_id 对应 usr 表中条目。
性能分析: usr 表一次根据 user_id 主键查询,一次删除。
3.用户登录 login
功能实现:
- 根据 user_id 获取用户密码。
- 与用户输入密码对比。若比对失败返回错误信息
- 密码对比成功,更新 usr 中的 token,terminal。
性能分析: usr 表一次根据 user_id 主键查询,一次更新。
4.用户登出 logout
功能实现:
- 根据 user_id 调用 check_token 查询该 user 是否处于登陆状态。
- 如果处于登陆状态则更新 token。
性能分析: usr 表一次根据 user_id 主键查询,一次更新。
5.更改密码 change_password
功能实现:
- 根据 user_id 获取用户原有密码,与用户输入的旧密码对比
- 若比对成功,更新用户密码为当前输入的密码。
性能分析: usr 表一次根据 user_id 主键查询,一次更新。
buyer 功能
1.下单 new_order
功能实现:
- 首先保证用户 id 和 storeid 存在,若不存在返回对应用户信息
- 通过 user_id,store_id,和唯一标识符相连生成 uid
- 根据订单信息在 store 表中查找商户中是否存在对应书籍和足够的库存。
- 若满足对应条件,则在 store 中的库存减去下单的数量,并向 new_order_detail 表插入 order_id,book_id,buyer_id,store_id,count,price 属性信息
- 记录下单时间,将订单信息插入 new_order_unpaid
性能分析:
store表k次根据主键查询,k次更新,new_order_detail表k次插入,(k为订单中购买的书本数)new_order_unpaid表一次插入。
2.支付 payment
功能实现:
- 查询在 new_order_unpaid 表中是否存在属于用户的待付订单,获取订单总价,商户 id。
- 若存在,根据 user_id 获取用户密码。并与用户输入密码对比。
- 比对成功,且用户余额大于待付价格,则付款成功,否则失败,返回对应错误信息。
- 若付款成功,在 usr 表中给给买家减少余额,根据卖家 id 给增加卖家的余额
- 在 new_order_unpaid 表中删除对应的待付订单信息
- 记录当前时间,在待发货表 new_order_undelivered 表中加入订单信息和付款时间。
性能分析: new_order_unpaid 表一次根据主键 order_id 查询,一次删除,user 表两次根据主键 user_id 查询,两次更新(其中一次买家、一次卖家)new_order_undelivered 表一次插入。
3.买家充值 add_funds
功能实现:
- 根据 user_id 获取用户信息,若记录不存在,返回 error_authorization_fail()
- 将密码与用户输入密码比对
- 若密码正确,在 usr 表中更新用户余额。否则返回相应报错
性能分析:
usr表一次根据主键user_id查询,一次更新。
4.买家收货 receive_book
功能实现:
-
根据传入的参数 user_id 获取用户信息,若记录不存在,返回
error.error_non_exist_user_id() -
根据传入的参数 order_id 判断待收货的表里是否存在该记录,如果不存在,就返回
error_invalid_order_id(order_id) -
判断订单中的买家和传入的 buyer_id 是否一致,如果不一致就返回
error_authorization_fail() - 若订单存在,买家存在且匹配,在待收货表 new_order_unreceived 中添加买家收货的时间。
性能分析:
``` usr表一次查询;
new_order_unreceived表一次查询,一次更新。
```
测试用例:
- 买家 user_id 不存在;
- 订单 order_id 不存在;
- 买家 id 存在但不匹配;
- 买家和订单都存在,且相互匹配。
5.查询历史订单信息
为支持不同的查询订单需求,函数接口中除buyer_id另增加flag。类似淘宝查询界面,支持查询用户所有订单,待付款订单,已付款待发货订单,已发货待收货订单,已收货订单,已取消订单。通过flag进行区分。
功能实现:
查所有订单
- 若用户不存在返回对应错误信息
- 根据 buyer_id 查询 new_order_detail
- 查询成功,返回订单 order_id,buyer_id,store_id,book_id,count 和 price 信息。
查待待付款订单
- 根据 buyer_id 和下单时间不为空在 new_order_unpaid 表中筛选记录
- 对每一条记录,根 order_id 查询 New_order_detail 表,获取订单 id,所购书籍列表(每本书的书名,价格,数量),下单时间,订单状态。
- 将获取的记录包装成 JSON 对象,每个 order 下包含由订单 id,下单时间,订单状态,所购书籍列表(书名,价格,数量)构成的数组。
查询已付款待发货订单,已发货待收货订单,已收货订单,已取消订单与查待待付款订单过程类似。只是返回订单状态不同,不再赘述。
性能分析:
``` 查所有订单:new_order_unpaid表一次查询
查询待付款订单:new_order_unpaid表一次查询,对应new_order_detail表k次根据主键查询(k为new_order_unpaid的该用户待付记录数)
查询已付款待发货订单:new_order_undelivered表一次查询,对应new_order_undelivered表k次根据主键查询(k为new_order_undelivered的该用户待发货记录数)
查询已发货待收货订单:new_order_unreceived表一次查询,对应new_order_detail表k次根据主键查询(k为new_order_unreceived的该用户待收货记录数)
查询已取消订单:new_order_canceled表一次查询,对应new_order_canceled表k次根据主键查询(k为new_order_canceled的该用户已取消记录数) ```
测试用例:
- 正常情况(包括所有订单,待付款订单,已付款待发货订单,已发货待收货订单,已收货订单,已取消订单能否正常返回)
- user_id 不存在的情况
- 用户无购买记录
6.手动取消订单
根据淘宝,如果卖家已发货需要申请售后来取消订单,这里我们只允许在未发货或未付款情况下才能取消订单
功能实现:
- 根据 order_id 和 buyer_id 在 new_order_unpaid 中判断是否为待付款订单
- 若是,在 new_order_unpaid 中删除对应订单
- 根据 order_id 和 buyer_id 在 new_order_undeliverd 中判断是否为待发货订单
- 确定订单未发货后。在 usr 表中更新买家余额增加该订单对应款项。
- 在 usr 表中更新卖家余额减少该订单对应款项。
- 在待发货表中删除对应记录。
- 记录当前时间并将订单信息加入 new_order_cancel 表中。
- 判断 New_order_detail 中的 order_id 是否为用户输入 order_id,book_id 是否与 store 对应,在 new_order_detail 表中筛选记录,在 store 表中将对应的书籍的库存加回。
- 若不是上述两种情况,返回无法取消订单
性能分析:
new_order_unpaid表一次查询,一次删除,new_order_undelivered表一次查询,一次删除,new_order_cancel表一次插入,new_order_detail表一次查询,store表k次更新(k为购买书籍数),user表两次根据user_id主键查询,两次更新(一次买家、一次卖家)。
测试用例:
- 已付款待发货
- 未付款情况
- user_id 不存在情况
- 已发货
7.自动取消订单
使用技术:
Redis 键空间通知(过期回调)用户下单之后将订单 id 作为 key,任意值作为值存入 Redis 中,给这条数据设置过期时间,也就是订单超时的时间。
1,下载安装 Redis(电脑中和 python 中)
(以下方法仅针对 windows 电脑)
-
在 Redis 文件中使用
redis-server.exe redis.windows.conf启动 Redis -
设置
redis.windows.conf中的notify-keyspace-events "EX"(为了保证可以发出过期数据的数据)
我们会收到关键事件通知,在 keyevent 频道中,我们会收到 key 作为消息。
- 可使用
redis-cli.exe --csv psubscribe '*'
测试服务是否打开
2,在 python 中使用 Redis,配置回调函数
注册回调函数来处理已发布的消息。消息处理程序只接受一个参数即消息。要使用消息处理程序订阅通道或模式,请将通道或模式名称作为关键字参数传递,其值为回调函数。当使用消息处理程序在通道或模式上读取消息时,将创建消息字典并将其传递给消息处理程序。在这种情况下,从 get_message() 返回 None 值,因为消息已经处理完毕。
功能实现:
- 在 buyer()中的 new_order 函数中将订单号存入 Redis 数据库中,并设置超时时间
- 在回调函数 auto_cancel_order 中设置死循环,每当接收到一个过期数据,就将 order_id 解析出来。
- 通过这个 order_id 判断能否找到未支付订单 new_order_unpaid 中的数据,
- 如果存在,将其删除,在已取消订单 new_order_canceled 中添加该 order 和取消时间。
- 如果不存在,说明该订单已被支付或者买家主动取消订单,则什么都不用处理。
```python
连接redis数据库
r=redis.StrictRedis(host='localhost',port=6379,db=0,decode_responses=True)
创建pubsub对象,该对象订阅一个频道并侦听新消息:
pubsub=r.pubsub()
收到消息的处理函数
def event_hander(msg): # print('Handler',msg) order_id=str(msg['data']) print(order_id) #如果能找到订单,就删除未支付订单 #添加到已删除订单中 #将商店中的书籍书加回去
订阅过期数据
pubsub.psubscribe(**{' keyevent@0 :expired':event_hander})
死循环,当有数据过期时,调用函数event_hander处理过期数据
while True: # print("监控超时订单") #获得事件信息,有结果就会回调函数 message=pubsub.get_message() time.sleep(0.1) ```
性能分析:
``` redis数据库一次更新(插入数据)。
当接收到数据时,对new_order_unpaid一次查找;
当数据存在,对new_order_unpaid一次更新;对new_order_canceled一次更新。
```
测试用例:
- 未支付订单中超时
- 未支付订单未超时
使用方法:
单独开一个进程运行自动取消订单的程序,然后再运行服务器 app.py,可实现自动取消订单。测试也能够通过
- 如果不测试自动取消订单,将 model1 中带注释的代码注掉,然后再把 test 文件中的 test_auto_model.py 文件注掉,方便测试(因测试自动取消订单需要等待 20s,如果不测试自动取消就没有必要)
seller 功能
1.上架图书 add_book
实现两种版本可支持只上架图书,或可将书籍添加到 book 表中并上架图书(该版本可以不运行 book.py 导入数据,通过 add_book 函数插入书籍)
这里传参接口增加 price 属性,需要商家自己定价,而不是传入书籍的零售价。
版本 1:
- 检查 user_id,store_id 以及 book_id 是否已存在。若不存在返回对应错误信息
- 将 store_id, book_id, 出售价格插入 store 表。
性能分析: usr 表一次根据主键 user_id 查询,store 表一次根据主键 store_id 查询,book 表一次根据主键 book_id 查询,store 表一次插入。
版本 2:
- 在版本一的基础上增加根据 book_id 从 book 表查询判断书是否已经在 book 表中
- 如果不在,插入书籍的所有信息
注意该版本事务 add_book 是包括添加图书,将书籍添加到商店这两步
我们初始代码是两步结束后才 commit,就导致第一步的图书还没添加进去,就在做第二步的将书籍添加到商店,而因为 store 里面的 book_id 必须存在在 book 表中,在重建数据库测试时会出现问题。在添加完图书(做完第一步)之后添加 self.session.commit()即可解决
性能分析:
usr表一次根据主键user_id查询,store表一次根据主键store_id查询,book表一次根据主键book_id查询,一次插入,store表一次插入。
2.创建店铺 create_store
- 检查 user_id 和 store_id 是否已存在。若不存在返回对应错误信息
- 插入用户 id,新建店铺 store_id 至 user_store 表。
性能分析: usr 表一次根据主键 user_id 查询,store 表一次根据主键 store_id 查询,user_store 表一次插入。
3.添加库存 add_stock_level
- 检查 user_id、store_id 和 book_id 是否已存在。若不存在返回对应错误信息
- 根据 store_id, book_id 对 store 表查询卖家商店中的书籍库存量,并在 store 表中更新库存,加上传入的库存数。
性能分析: usr 表一次根据主键 user_id 查询,store 表一次根据 store_id 主键查询,一次更新。
4.卖家发货 deliver_book(额外功能)
-
功能实现:
-
根据传入的参数 user_id 获取用户信息,若记录不存在,返回
error.error_non_exist_user_id() -
根据传入的参数 order_id 判断待发货的表里是否存在该记录,如果不存在,就返回
error_invalid_order_id(order_id) -
判断订单中的卖家和传入的 seller_id 是否一致,如果不一致就返回
error_authorization_fail() - 若订单存在,卖家存在且匹配,在待发货表 new_order_undelivered 删除该订单,在待收货表 new_order_unreceived 中添加该订单和发货时间。
性能分析:
``` usr表一次查询;
new_order_undelivered表一次查询,一次更新。
new_order_unreceived表一次更新。
```
测试用例:
- 买家 user_id 不存在;
- 订单 order_id 不存在;
- 卖家 id 存在但不匹配;
- 卖家和订单都存在,且相互匹配。
实验过程中遇到的问题和解决方法
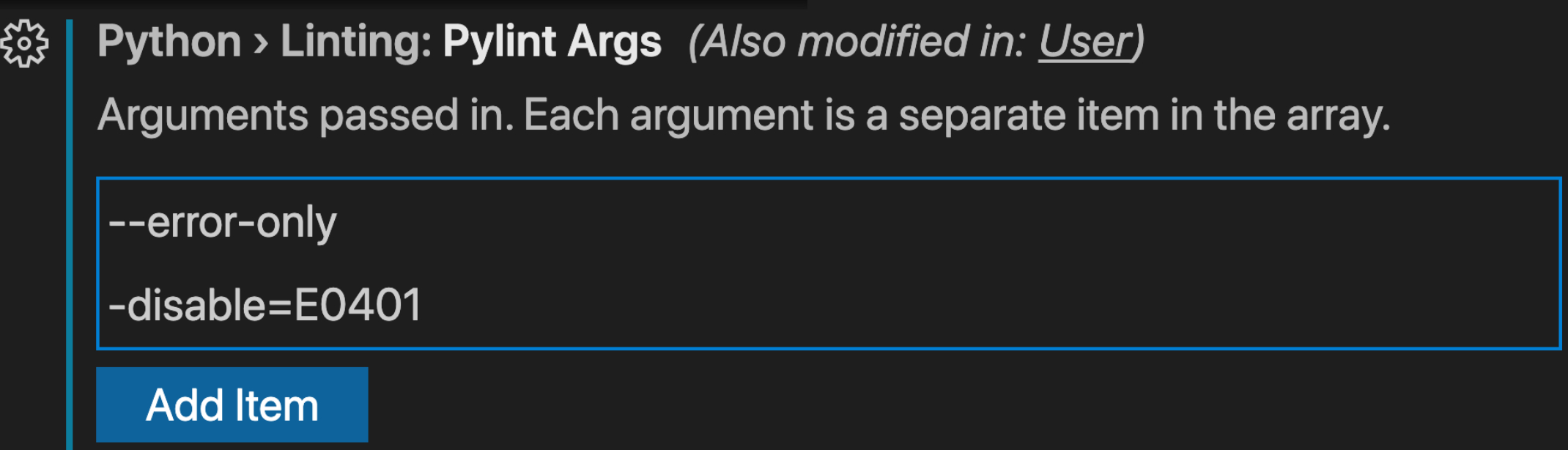
1.VScode 中误报(import-error)解决
在 vscode 中点击文件-> 首选项-> 设置,在搜索框中输入:pylintArgs
在搜索的结果 Python>Linting:Pylint Args 中点击添加项,分别添加—errors-only 已及—disable=E0401,保存,退出设置,重启 vscode 既可解决
2.user_id = request.json.get("user_id", "")AttributeError: 'NoneType' object has no attribute 'get'
postman 测试的 body 没有设置为 JSON 格式导致前端无法解析
3."'tuple' object has no attribute 'keys'"

由于数据库语句书写格式错误,如应该应该是 set xx,xx 写出 set xx and xx 等
"UPDATE usr set token= '%s' , terminal = '%s' where user_id = '%s'"
4.init_db 文件夹中的 book.py 是插入书籍信息,但在 vscode 无法访问路径。
将
self.book_db
改为绝对路径
5.当运行测试时会报 530error,发现无法插入数据
将所有表中的
user_id,store_id,buy_id
改为 256 的 str,
order_id
改为 512 的 str(因为测试过程中生成的用户名和店铺名为长度为 159 的 str,生成的订单是买家名和店铺名的 join,因此需要设置长一点的 str)
6.运行 init_database.py 文件导入数据时会报错,键值不存在
将每个表中的插入都 commit,以免出现键值不存在的情况
python
session.add_all([
Users(user_id = 'search',
password = '123456',
balance = 9000,
token = '***',
terminal='Edge'),
])
session.commit()
session.add(User_store(user_id = 'search',
store_id = 'Kadokawa'))
#store_id相当于商店名)
session.commit()
session.add_all([
Store(store_id = 'Kadokawa',
book_id = 50,
stock_level=10,
price=2599)
])
session.commit()
额外功能:Search 功能实现
search 索引构建
要求
搜索图书 用户可以通过关键字搜索,参数化的搜索方式; 如搜索范围包括,题目,标签,目录,内容;全站搜索或是当前店铺搜索。 如果显示结果较大,需要分页 (使用全文索引优化查找)
searchDB 数据库的构建
在 book 表中,显然在 4w 条数据的大数据情况下,外加 picture 的 BLOB 类型字段,author_intro 和 book_intro 中的 TEXT 类型字段内容过长的问题,如果单纯的在 book 表中进行关键字搜索,及时是使用了索引,也会导致搜索速度过慢而用户难以忍受的问题,所以决定将 book 表中的字段的一部分,分表对应 author,title,tags,book_intro 四列新建表格,以小部分的冗余存储为代价,建立数据库高效搜索效率。
searchDB schema
具体建表代码见
init_db/search.py
,全文索引构建见
search-index.sql
,全文索引构建需要中文分词器
zhparser
初始建表代码以 search_title 表为例子
python
class SearchTitle(Base):
__tablename__ = 'search_title'
search_id=Column(Integer,autoincrement=True,primary_key=True)
title = Column(Text, nullable=False,primary_key=True)
book_id = Column(Integer, ForeignKey('book.book_id'), nullable=False)
Basic-Tables
seach_author
:

search_tags:
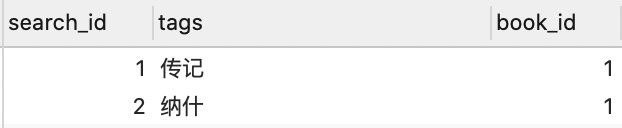
search_title:
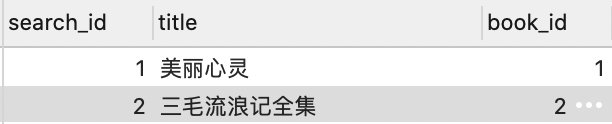
search_book_intro

可以看出,在 searchDB 的每一张 Table,我们只寻找一种高效的检索方式需要把 book_id 选出来即可。
关键字搜索实现
模糊和通配查询实现
在搜索功能实现的第一阶段,我最先想到的使用
like
进行通配查询,在相应的搜索字段中构建主键 B-树索引,对应的 SQL 查询为
SELECT * from search_book_author where author like '%杨红%';
模糊查询的缺点
事实证明,对于这种用户输入字段的前后部分都是用了
%
的情况,尤其是相当于搜索
%s
时,即后缀匹配的情况时,我们建立在主键上默认的 B 树索引即失去了范围查询中的效率。所以,这种模糊查询的方式是不佳的。
使用
EXPLAIN ANAYLYZE
语句查看这种模糊匹配
后缀匹配时会导致我们的索引失效,最终还是全表扫描,在信息检索系统中,通过构建 轮排索引 可以避免这种全表扫描。
全文索引--postgresql 全文索引 Gin 索引
PostgreSQL 全文搜索:to_tsvector()和 to_tsquery()
- to_tsvector 实际上把语句转换成了 tsvector(文档格式-包含文档值和角标)
如:
SELECT * FROM to_tsvector('parser_name',TEXT)
Input:SELECT * FROM to_tsvector('parser_name','小明今天去上学')
Output:'上学':3 '去':2 '小明':1
通过 output,我们可以看到“上学”对应位置 3,“小明”对应语句的位置 1,我们记住这种格式就行,后续会用到。 2. to_tsquery(),实际上就是一个传递的参数格式,可以搭配中文分词规则,把一句话拆成多个词传递过去
Input:SELECT * FROM to_tsvector('parser_name','小明今天去上学')
Output:'上学'& '去'& '小明'
3. 结合
to_tsvector()
和
to_tsquery()
,即可完成本次数据库的关键字全文搜索功能。
全文搜索技术:分词
PSQL 本身是不支持全文索引的,所以在分词解释器没有构建的情况下,
SELECT * FROM to_tsvector('parser_name','小明今天去上学')
的结果还是
'小明今天去上学':1
,这样我在整个字段上创建索引也不能达到用户输入模糊查询的效果,所以需要引入中文分词解释器
zhparser
所以,在什么字段上构建索引是很重要的一件事。
在搜索系统中,分词很大的影响了了搜索系统的召回率和准确率,一起我们的 4 个基础 table 表的大小。
- 分词粒度越精细,4 个基础 table 表的大小越大,消耗的空间也越大,搜索的表格也越大。
- 如果直接使用 PostgreSQL 数据库内分词,如果以数据库能解决就不用其他外部工具甚至代码解决而不是先用外部程序进行分词新增列和行,会降低数据库全文搜索的效率,同时,也会有 PostgreSQL 的程序执行效率很低,导致文章最后的分词函数占用大量 CPU 的问题。
- 当然,当原始数据集过多,存储了外部分词结果的修改后的数据集就会成线性倍数的增长,消耗存储空间。这里有一个搜索效率和存储的 trade-off
最终全文搜索功能实现
外部中文分词程序
Search_author
在对 author 字段进行分词初步索引的构建的时候,我尝试了 3 种分词方式,当然这 3 种分词方式本身也受:
- 模拟用户输入的最长前缀:
杨;杨红;杨红樱
python
for k in range(1, to_string_len + 1):
row_to_insert=SearchAuthor()
if to_string[k - 1] == '':
continue
if to_string[k - 1] == '美' or to_string[k - 1] == '英':
continue
j = to_string[:k]
row_to_insert.author=j
row_to_insert.book_id=row.book_id
session.add(row_to
2. 2-gram 模型:
杨红,红樱;(但仍把作者的姓加进去提高召回率,符合中文作者姓名和中文读者的搜索习惯) 3. 不提前分割,仅依赖 zh-parser 的预先分割功能生成新列。
python
if len(to_string)==0:
to_string=row.author
row_to_insert.author=to_string
row_to_insert.book_id=row.book_id
session.add(row_to_insert)
session.commit()
最后的分词方式:
2-gram+ 存储作者姓和全称字段(如果全称字段被 zh-parser 自动分割,也仍然无法提高召回)
Search_book_intro
因为 book_intro 都是大量的文本,通过对文本提取关键词的方式进行分割,提取关键词的方法有很多,有 TF-IDF,TextRank 等。
这里使用基于图的 TextRank 方法提取关键词,限制关键词最多不超过 20 个,即修改后的 search_book_intro 表最大为原表的 20 倍。
Search_tags
tags 是已提取好的标签,直接把 tags 拆开插入的修改后的表中。
Search_title
title 字段和 author 字段都是短文本,他们最显著的区别是,姓名字段的字与字之间没有明显强烈的上下文关系,如杨红樱三个字与《一个狗娘养的自白》这个标题相比,显然是标题的字与字之间更具有上下文的关系,所以在 search_title 部分我没有采用形如 search_author 一样的粒度划分,而是直接采用了 zh-parser 本身分词功能对与 search_title 表格的修改。
最终的修改表的语句如下:
详见
search-index.sql
sql
ALTER TABLE search_author ADD COLUMN tsv_column tsvector;
UPDATE search_author SET tsv_column = to_tsvector('zh', coalesce(author,''));
CREATE INDEX idx_gin_author ON search_author USING GIN(tsv_column); //
CREATE TRIGGER trigger_name BEFORE INSERT OR UPDATE ON search_author FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(tsv_column, 'zh', author);
我自己测试 4w 条书的 book_intro 分词后的库初始化
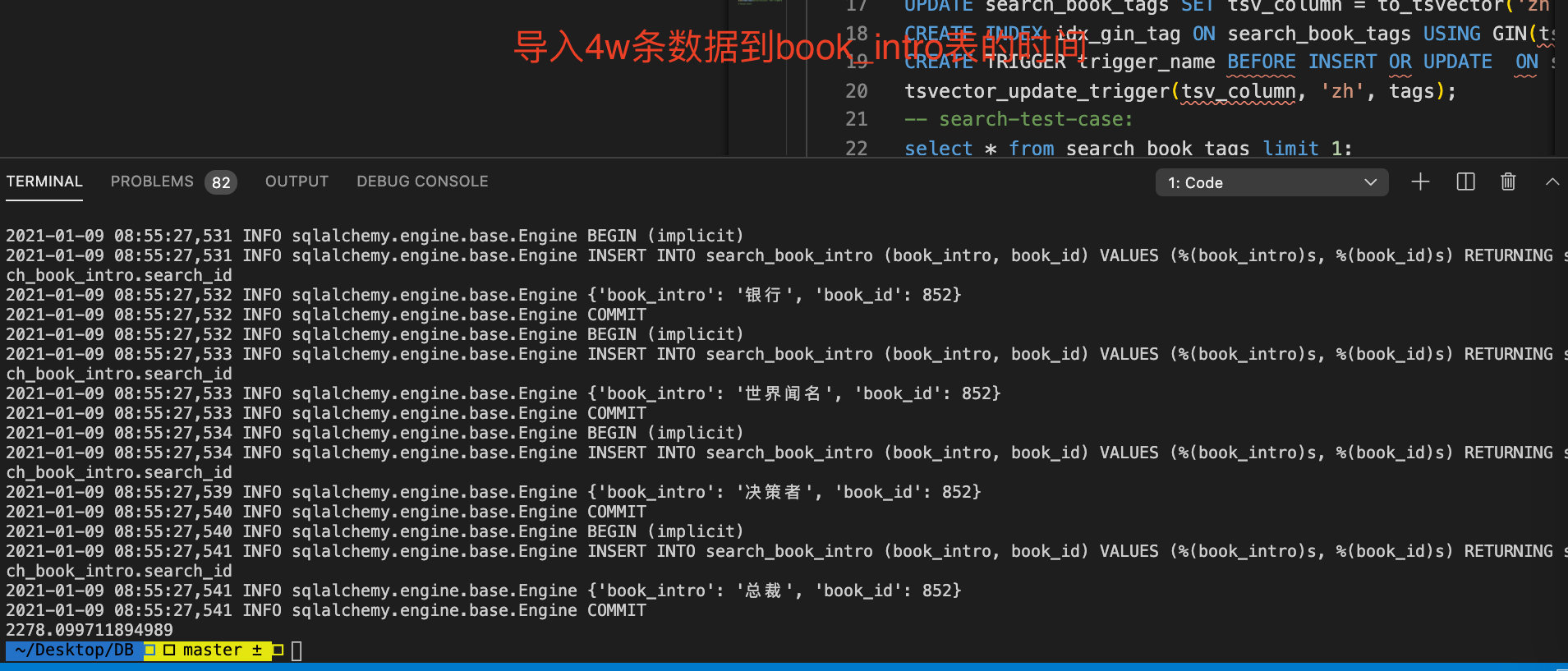
我自己测试 4w 条书的其它分词初始化大致时间总体还是在可接受的范围内。

索引构建--GIN
使用索引可以提高全文检索的效率,在 PostgreSQL 官方文档中,官方推荐
GIN
通用倒排索引。而 Gin 索引的构建,根据 PostgreSQL 官方的要求,必须指定分词规则。
CREATE INDEX idx_gin_zh ON search_book_intro USING GIN(tsv_column);
GINindex 构建时间
PotsgreSQL 提供的 pg_trgm 的扩展中有两种索引类型,一个是
gin
,一个是
gist
这两个选择的不同从使用上主要是
gist
构建速度比较快,搜索速度比
gin
慢,而
gin
相反,搜索速度很快,构建速度非常慢,而我在 278549 条数据上构建 Gin 索引大概只需要 1.5s,还是可以在本次实验的数据规模上接受的,所以我直接使用了 GIN-index。

TABLE search_author
的行数如下(使用代码解决分词后)

搜索性能比较
以数据量最大的
TABLE search_book_intro
为例子

由上图可见数据量为 70w 行数据
在 tsv_column 上构建 Gin 索引

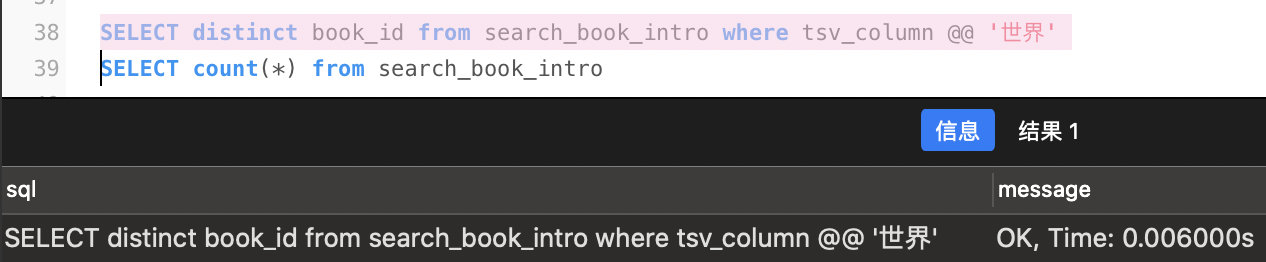
第一次搜索
search_book_intro
关键词
世界
,用时为
0.529S
第二次搜索
search_book_intro
关键词
世界
,用时为
0.006S
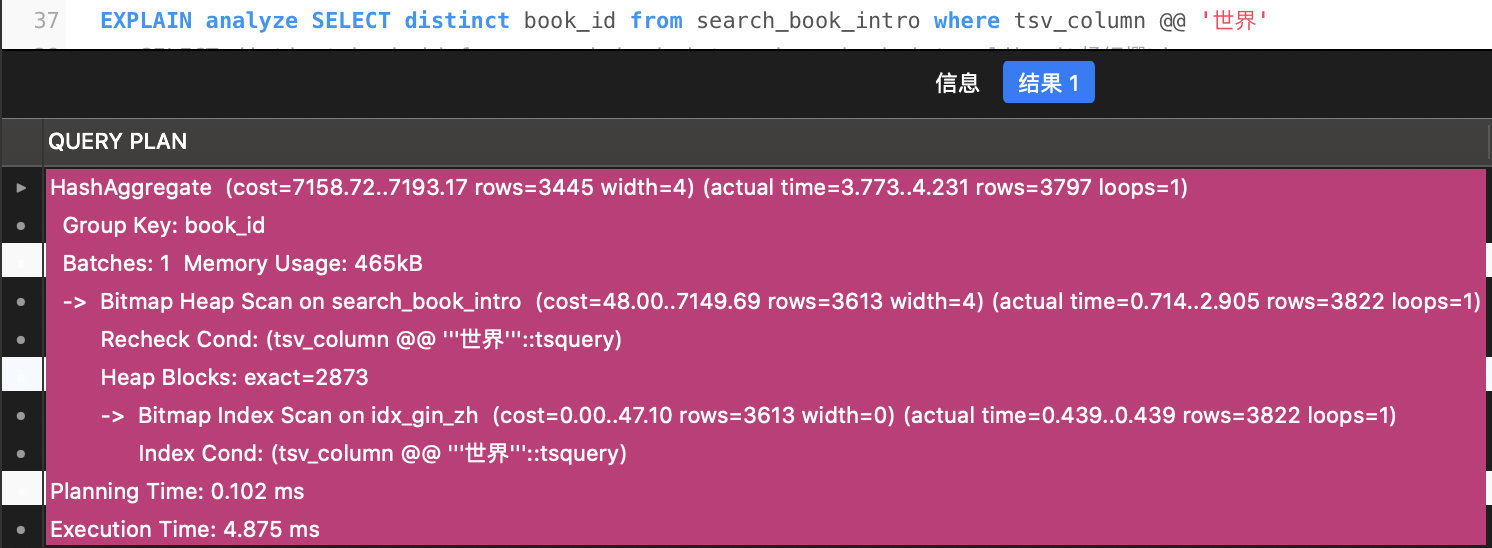
因为提前进行了外部分词,利用主键索引进行搜索
可以通过
EXPLAIN ANALYZE
命令查看两种搜索方式的对比
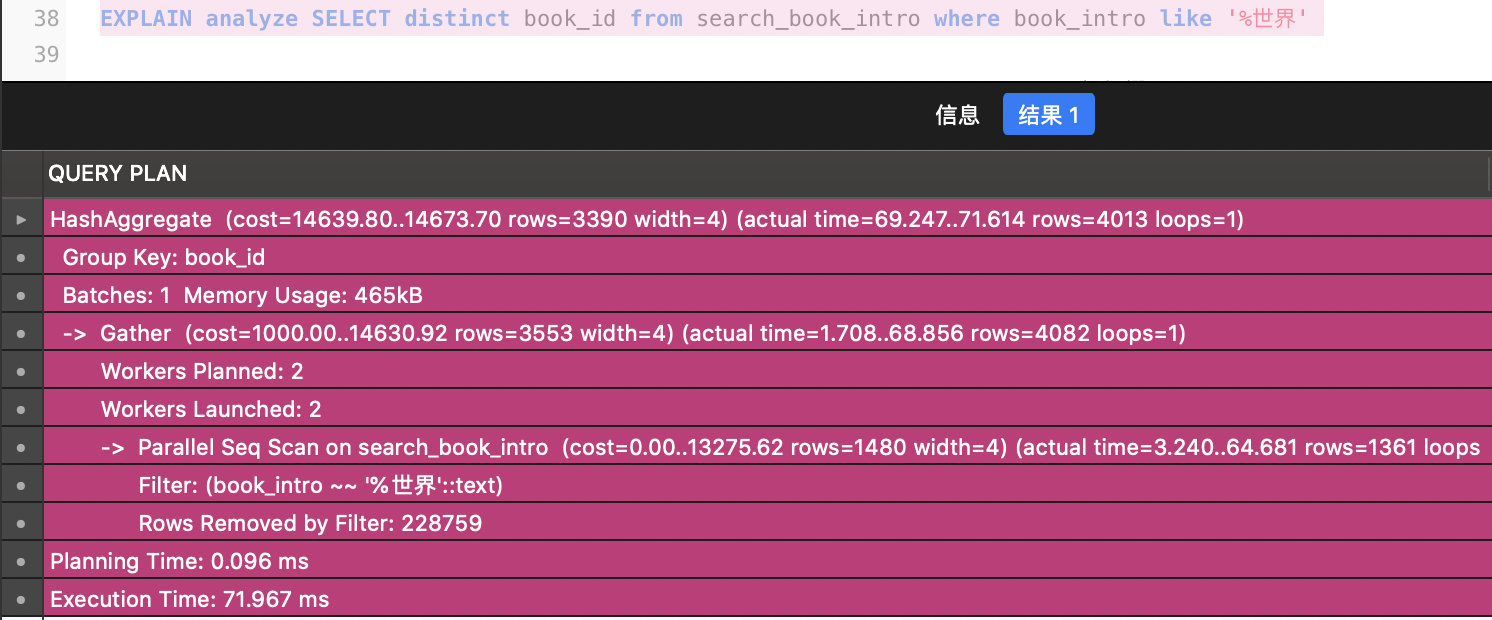
没有提前进行外部分词,直接使用模糊查询的前后缀匹配
在没有进行分词的 4w 条数据上,直接进行前后缀匹配的模糊查询:
SELECT * FROM book WHERE book_intro like '%生活%'

SELECT * FROM book WHERE book_intro like '生活%'

SELECT * FROM book WHERE book_intro like '%生活'

可以很明显的看出,无论是前缀匹配还是后缀匹配中,即使是在 book_intro 字段建立了索引,这个执行时间也很可怕。是用户难以忍受的。

分页查询
基本分页查询
一般性分页 使用 limit [offset,] rows 偏移量的问题在于如下两种:
如果偏移量固定,返回记录量对执行时间有什么影响?如分别比较
select * from user limit 10000,1
;
select * from user limit 10000,10;
select * from user limit 10000,100;
select * from user limit 10000,1000
;
select * from user limit 10000,10000;
这种分页查询机制,每次都会从数据库第一条记录开始扫描,越往后查询越慢,而 且查询的数据越多,也会拖慢总查询速度
引入 search-id 的分页查询优化与直接使用 Gin INDEX+LIMIT 的分页查询优化
利用覆盖索引优化 select * from user limit 10000,100; select id from user limit 10000,100;
利用子查询优化 select * from user limit 10000,100; select * from user where id>= (select id from user limit 10000,1) limit 100;(使用了索引 id 做主键比较(id>=),并且子查询使用了覆盖索引进行优化。)
通过这种思路,可以引入 search_id 进行分页查询的优化
最终分页查询功能的实现
sql
EXPLAIN ANALYZE SELECT DISTINCT book_id FROM search_book_intro WHERE book_id in (SELECT book_id FROM search_book_intro WHERE tsv_column @@ '美丽') LIMIT 100
- 在本次project中我使用的分页查询:
Limit (cost=4719.78..4720.78 rows=100 width=4) (actual time=36.313..36.343 rows=100 loops=1)
-> HashAggregate (cost=4719.78..4737.73 rows=1795 width=4) (actual time=36.312..36.331 rows=100 loops=1)
Group Key: search_book_intro.book_id
Batches: 1 Memory Usage: 73kB
-> Hash Join (cost=341.50..4715.30 rows=1795 width=4) (actual time=1.014..35.925 rows=1976 loops=1)
Hash Cond: (search_book_intro.book_id = search_book_intro_1.book_id)
-> Seq Scan on search_book_intro (cost=0.00..3925.55 rows=163155 width=4) (actual time=0.649..15.253 rows=163155 loops=1)
-> Hash (cost=340.28..340.28 rows=97 width=4) (actual time=0.232..0.234 rows=104 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 12kB
-> HashAggregate (cost=339.31..340.28 rows=97 width=4) (actual time=0.200..0.215 rows=104 loops=1)
Group Key: search_book_intro_1.book_id
Batches: 1 Memory Usage: 24kB
-> Bitmap Heap Scan on search_book_intro search_book_intro_1 (cost=12.76..339.07 rows=98 width=4) (actual time=0.063..0.171 rows=104 loops=1)
Recheck Cond: (tsv_column @@ '''美丽'''::tsquery)
Heap Blocks: exact=100
-> Bitmap Index Scan on idx_gin_zh (cost=0.00..12.73 rows=98 width=0) (actual time=0.045..0.045 rows=104 loops=1)
Index Cond: (tsv_column @@ '''美丽'''::tsquery)
Planning Time: 0.223 ms
Execution Time: 36.407 ms
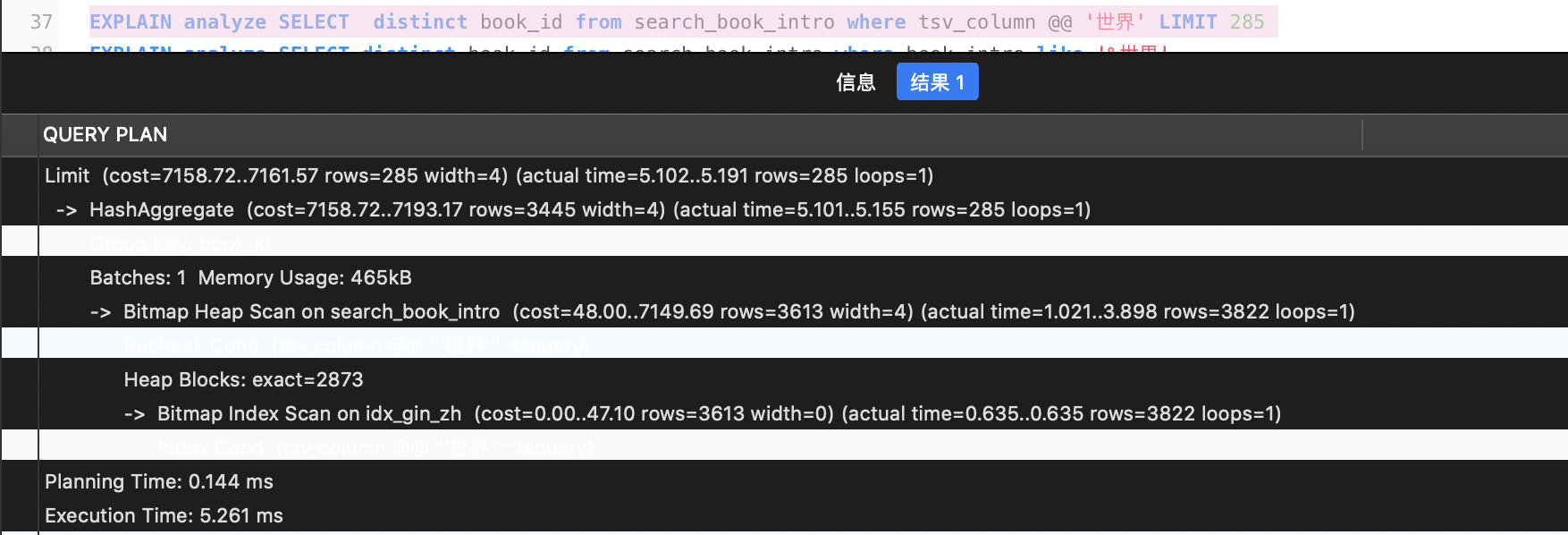
使用 GIN-index,限制是 285 条(其实这个限制了全局,比 search_id 的扫描范围要广一些)
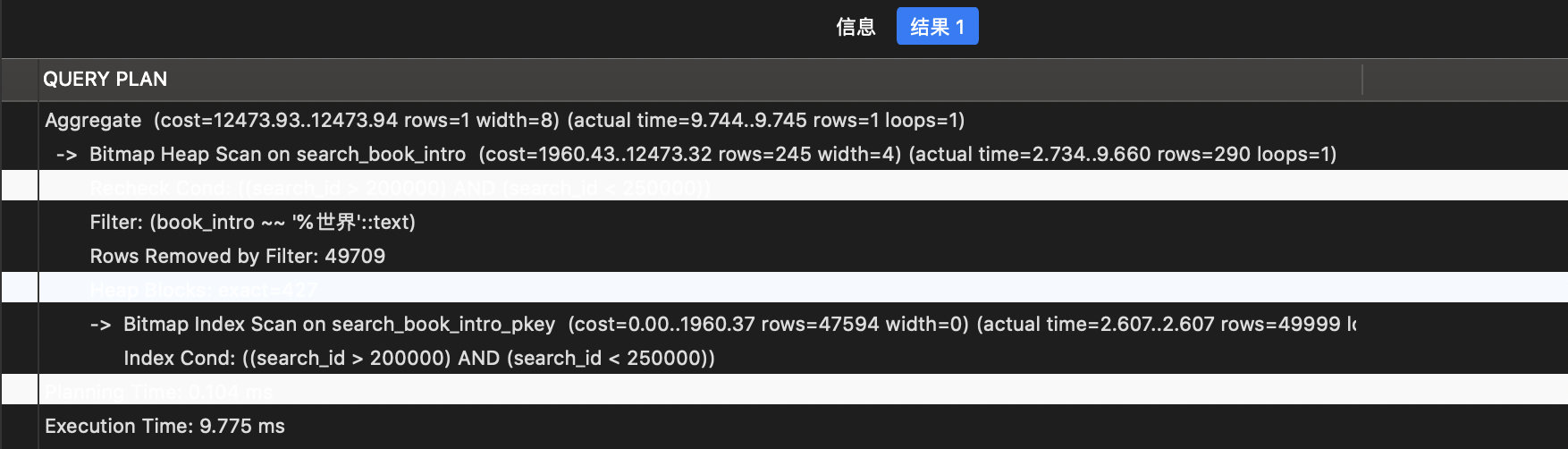
使用 GIN-index,限制是 285 条(使用 search_id 的主键 B 树索引的 285 条数据)

后端代码实现
逻辑上来讲,任何一家书店拥有的书的数量,跟整个图书商城,比如当当,淘宝整个全站搜索库里的书的数量相比是很少的,所以,seachDB 的四张表中的都是针对全部 book 库中的数据,对于每一个店家,没有额外进行建表的必要。
所以,在
SQL
查询语句确定了以后,后端实现的逻辑如下:
-
首先获得 book_db 库中符合全局搜索的
book_id - 对于全局搜索直接返回
-
对于本店搜索,则使用子查询,搜索本店和全局检索出的
book_id重复的部分。
为了节省篇幅,在此即不附后端实现的代码了,具体可以见
be/model1/buyer.py
下面的
search_functions_limit
函数。
总结与提升
SELECT * FROM search_author WHERE tsv_column @@'杨红'
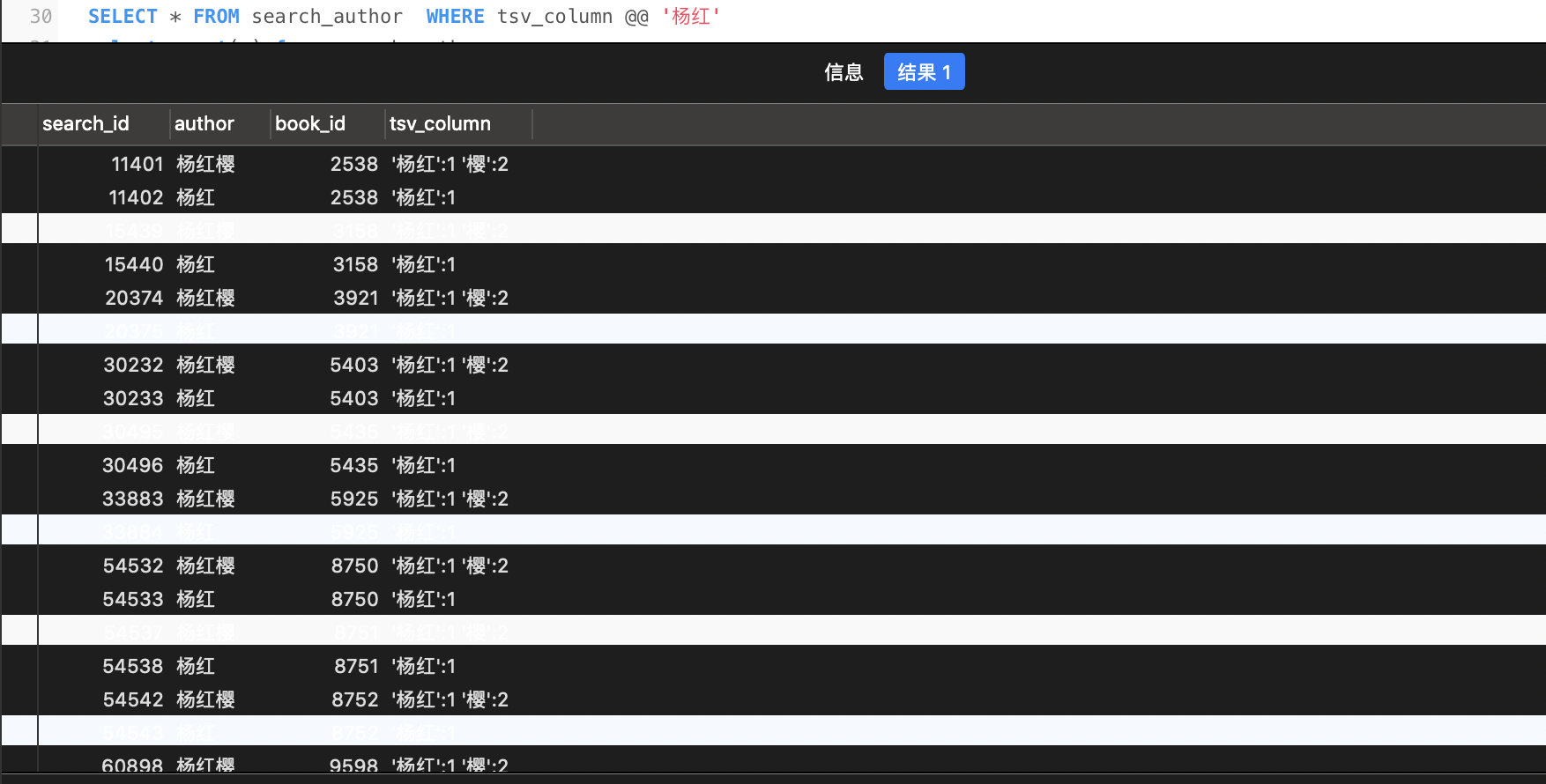
SELECT * FROM search_author WHERE tsv_column @@'红樱'

SELECT * FROM search_author WHERE tsv_column @@'樱'
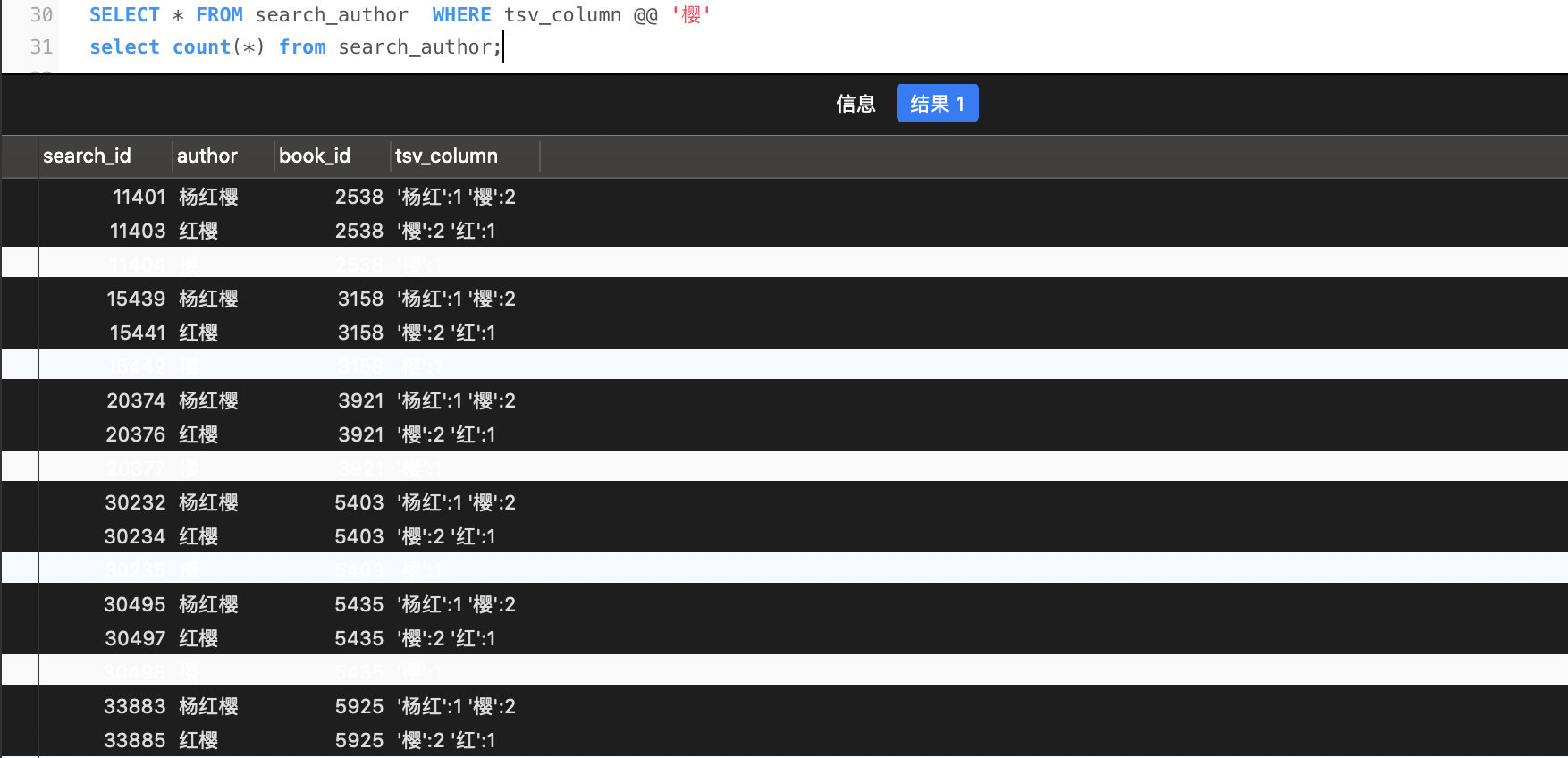
从上面这三个很简单的例子可以看出,搜索系统中最关注的准确率和召回率的提升,应更多的从分词规则的角度进行考虑,在数据库 + 信息检索的方面有待提升。
一般的,在检索系统中,人们倾向于接受不那么相关的结果,而不是返回一个 0 结果值的检索系统。
理论 reference
- PostgreSQL 全文检索简介
- MacOS 系统上 Postgresql 中文全文搜索配置
- PostgreSQL 关于中文搜索的简单尝试
- 不要头大!基于 PostgreSQL 的全文搜索干货!
- PostgreSQL、MySQL 高效分页方法探讨
开发流程
1.版本控制
以下是本次项目版本控制的部分截图:
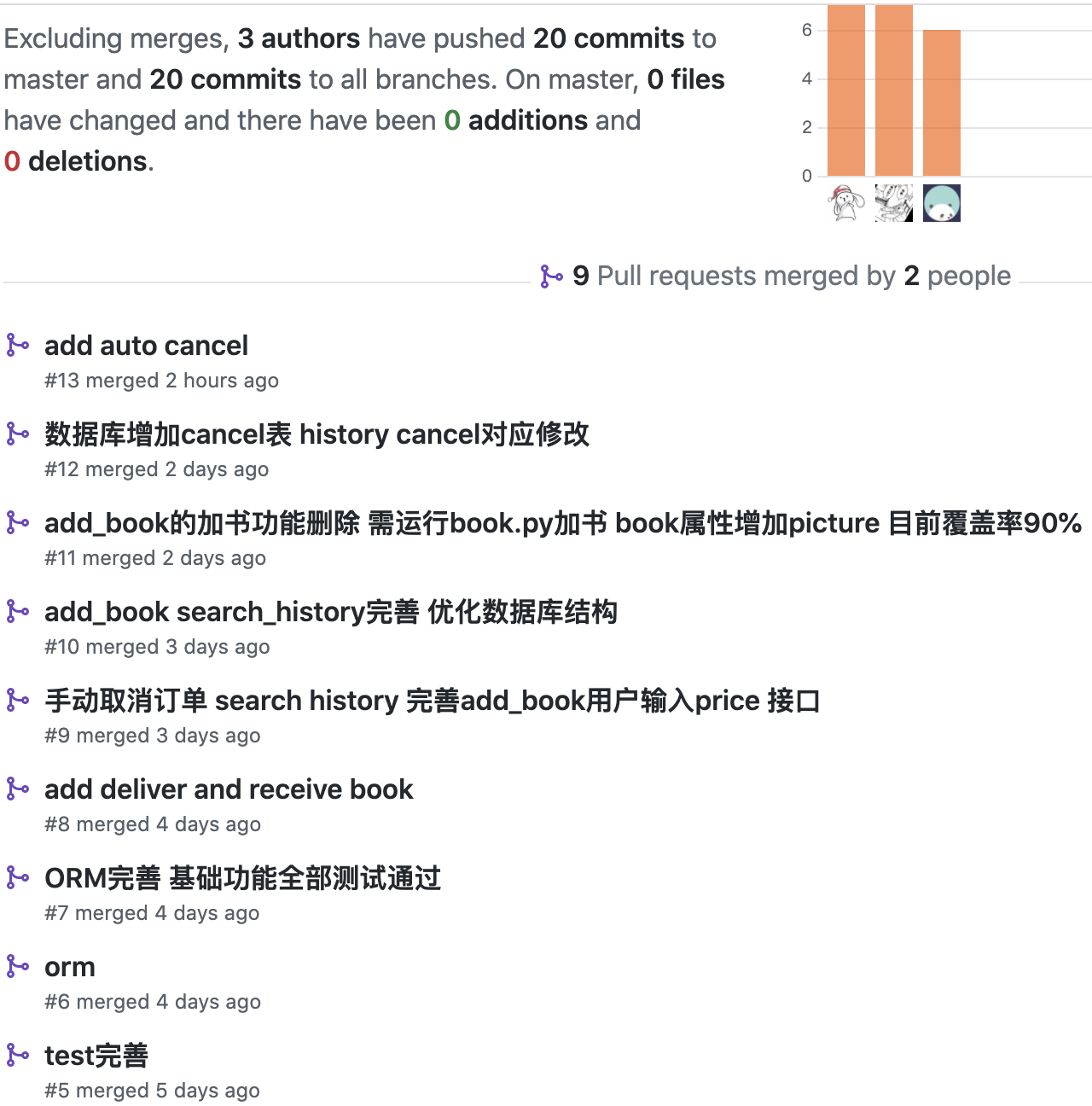
池欣宁在 GitHub 中建仓库并添加合作者,直接 fork 原始数据库项目,另两位组员 fork 到自己的仓库并向该仓库发起 pull request 请求,所有合作者都可以 merge request。

GitHub 首页 commit 书截图如下

2.测试驱动开发(TDD)
在所有测试功能实现时,我们首先编写 test_case 再对对应的后端功能进行编写完善。通过测试来推动整个开发的进行。这有助于编写简洁可用和高质量的代码,并项目整体的加速开发过程,提高了代码效率和覆盖率。
3.应用驱动优化
在功能实现的过程中发现初始表结构查询效率较低,故做了相应的修改和调整。在故在 new_order_detail 中添加冗余属性 store_id 和 buyer_id。这样的修改方便用户查询所有订单信息,也方便卖家查自己店铺的所有订单信息。
同时在实现取消订单的过程中,考虑表结构的完整性另添加 new_order_cancel 表。
实验结果
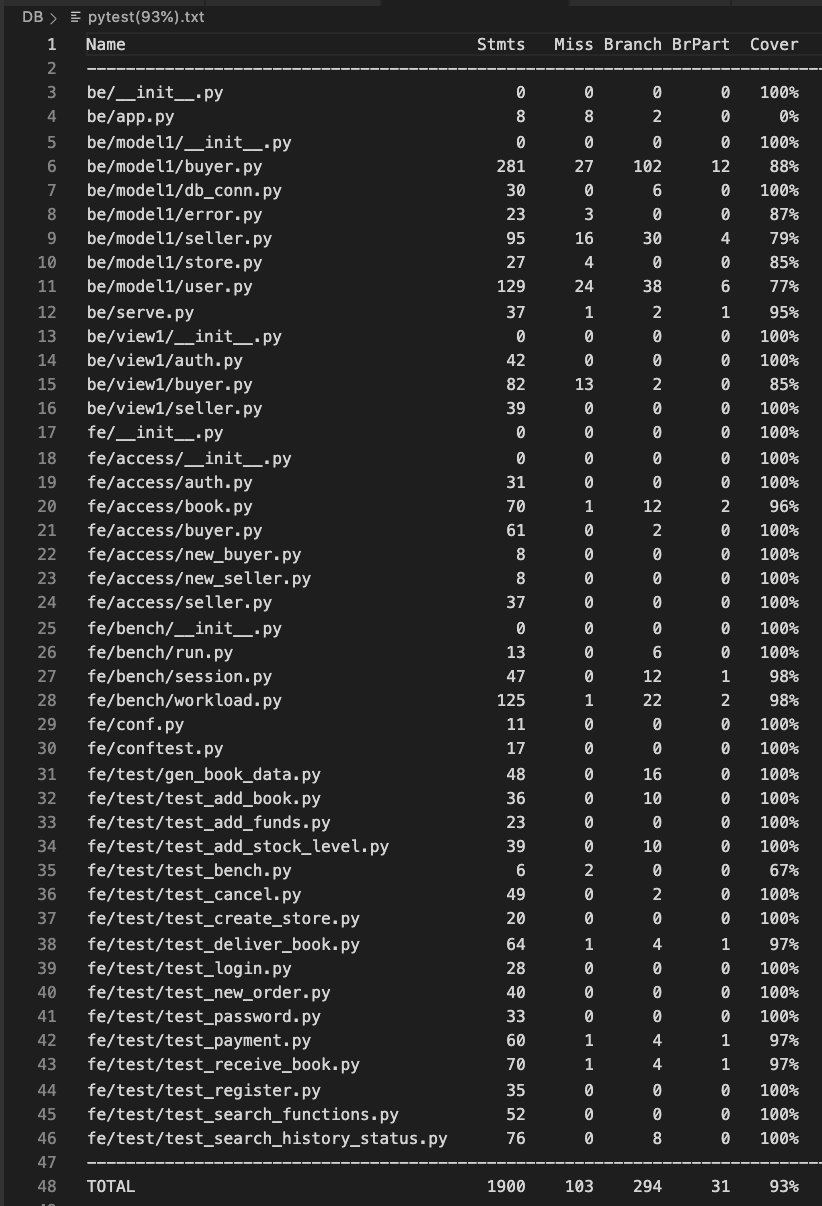
1.共计 50 个 test case,全部测试通过!
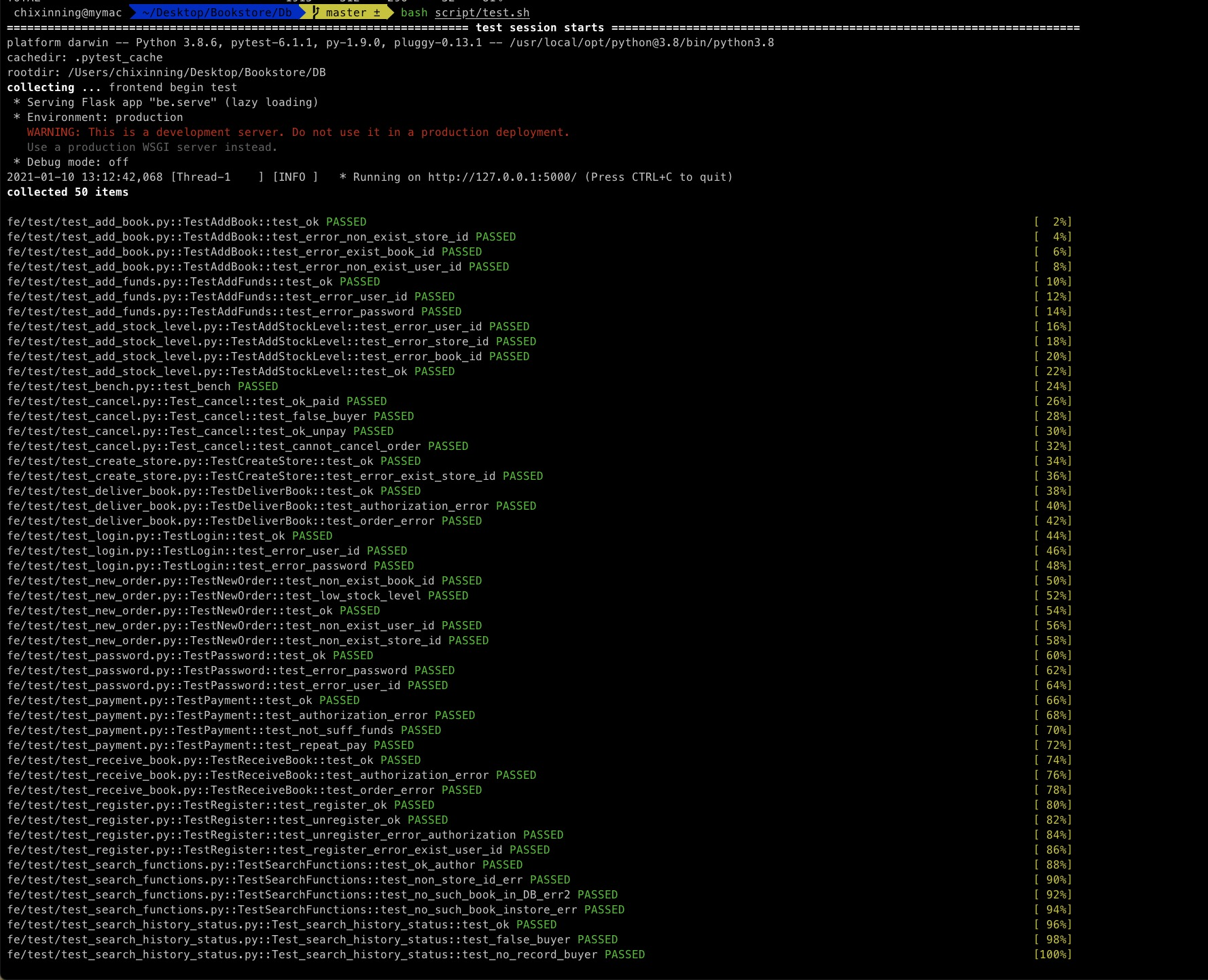
2.覆盖率达 93%
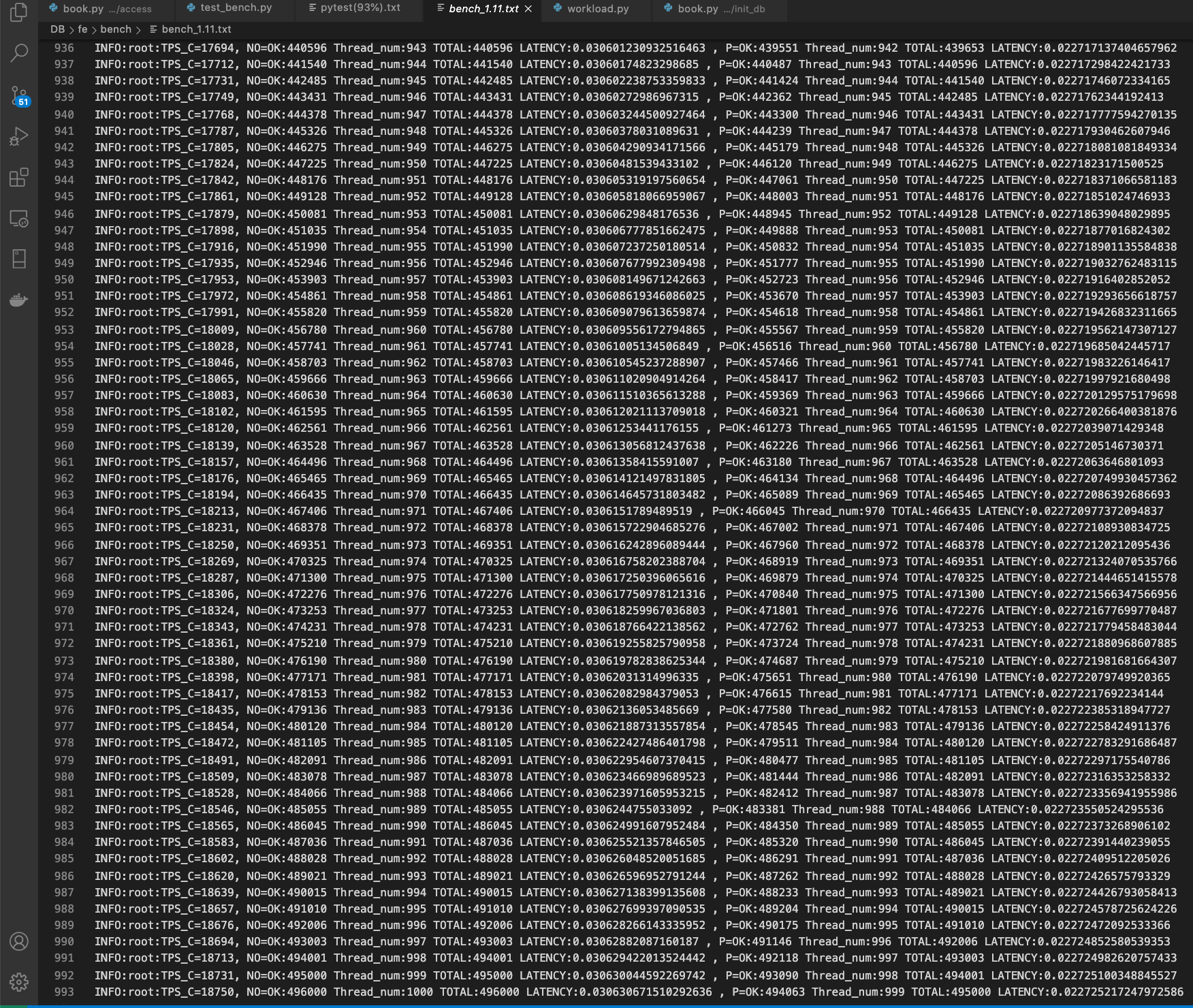
3.吞吐量与延迟
mac 测试吞吐量达 18750 笔/秒 平均下单延迟 0.03 秒 平均付款延迟 0.022 秒
小组分工
池欣宁:数据库初始设计,搜索图书功能设计,搜索功能实现,吞吐量测试,Git 版本控制,PPT 制作,报告撰写
何诗雨:add_book 优化,扩展功能的发货收货、自动取消订单,吞吐量测试,ER 图制作,测试完善,Git 协作,PPT 制作,报告撰写
王文清:基础功能实现,扩展功能的查询历史订单、手动取消订单,吞吐量测试,数据库结构优化,Git 协作,PPT 制作,报告撰写
实验总结
善于利用 postman 测试代码中的问题
善于使用测试文件检验代码是否具有高可用性(测试驱动开发)
参考文献
- 基于Apriori算法的图书馆管理系统的设计与实现(青岛大学·刘玉静)
- 基于SSH框架的图书馆管理系统的设计与实现(山东大学·檀雪姣)
- 图书综合管理系统(吉林大学·王宇)
- 宁波职业技术学院图书管理系统分析与设计(云南大学·赵顺勇)
- 基于SSH框架的图书馆管理系统分析与设计(云南大学·郑晨)
- 基于B/S架构的图书管理系统(山东大学·彭鹏)
- 山西电大图书管理信息系统的设计与实现(北京工业大学·李莹)
- 基于Apriori算法的图书馆管理系统的设计与实现(青岛大学·刘玉静)
- 高校图书管理系统的设计与实现(东北大学·黄鑫)
- 高校图书馆管理系统的分析与设计(云南大学·杜思思)
- 基于.NET技术的高校图书管理系统的设计与实现(吉林大学·李敏琪)
- 基于B/S模式的社区图书馆管理系统的设计与实现(大连理工大学·丁娟娟)
- 基于WEB的图书管理系统的设计与开发(大连理工大学·邬金池)
- 图书馆管理信息系统的设计与实现(华东师范大学·朱瑞)
- 基于ASP.NET技术的中山图书Web管理系统的设计与实现(江西财经大学·陈宇)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设小屋 ,原文地址:https://bishedaima.com/yuanma/36003.html