期刊管理系统
实验主题
本实验旨在开发出带 GUI 的期刊管理系统,系统记录和检索各种期刊信息,可生成统计报表用于期刊信息的统计。期刊的初始数据集来源于 2008 年中国百种杰出学术期刊,所有数据存放于关系型数据库 MySQL 中。期刊信息可包含:期刊名称,英文刊名,CN,ISSN,主编, 主办单位,地址,邮编,电话,传真,电子信箱,出版周期,创刊时间。为了更好地管理数据和查阅数据,使用系统需要账号登陆,账号分为管理员级别和普通用户级别。管理员可对期刊进行任何操作;普通用户只能查阅期刊信息,打印报表等。
实验设计
设计思路
ER 图设计
浏览 2008 年中国百种杰出学术期刊后,得出以下结论:
电话,传真,电子信箱是可以为空的。
主编,主办单位与期刊是多对多关系。
期刊和电子信箱是一对多关系。
创刊时间大于 1800 年故 ER 图设计如下:

账户注册逻辑
考虑到功能的完整性与便于管理,只需要提供用户名、邮箱和密码进行注册。用户名和邮箱是唯一的,并且用户的密码以加密的形式存储于数据库中,保证账户安全性。
账户登录逻辑
考虑项目便于使用,登录时使用邮箱、密码验证。若不存在该邮箱,则返回账户不存在消息。若密码错误,则提示密码有误信息。
增添期刊逻辑
设计表单,管理员填写好必要的期刊信息后,点击提交。客户端取得表单数据,检查数据格式是否有误,检查数据是否与现有数据重复,如果一切正常,才插入期刊数据至数据库。
删除期刊逻辑
删除期刊按钮位于期刊详情界面内,流程可通过查询期刊-> 期刊详情-> 删除期刊来进行期刊的删除操作。删除前,先判断当前用户是否具备删除权限,若有,则根据期刊信息操作数据库进行删除操作。
查询期刊逻辑
设计三种不同的查询方式,一个是以中文刊名进行查询,另一个是以 ISSN 号进行查询,后一个是以 CN 号进行查询。所有的查询都要求模糊匹配。
修改期刊逻辑
修改期刊按钮位于期刊详情界面内,流程可通过查询期刊-> 期刊详情-> 修改期刊来进行期刊的修改操作。删除前,先判断当前用户是否具备修改权限,若有,则根据期刊信息生成表单,用户修改表单内容再提交至客户端,客户端会判断数据的正确性和冗余性判断期刊的修改是否成功。
架构图

软件实现
项目主要用 Python/Javascript 开发。分别使用了 Flask 和 Electron 两大框架构建服务端与客户端。客户端发送操作请求,服务端相应请求进行操作。
先介绍 Flask 和 Electron 所担任的角色:
c++
Flask
Flask 是一个用 Python 编写的微 Web 框架。Flask 自动帮我们解析来自客户端的 Http 请求信息,我们只需编写相应 URL 的响应函数即可。Flask 之所以被称为微框架,因为它做的工作也仅限于此。对于 POST 的表单处理,数据库操作,登录认证等功能都需要自己编写,这样的好处就是自由度很高,可以用自己喜欢的方式实现。缺点就是开发周期较长。
c++
Electron
Electron 让我们可以使用 JavaScript,HTML 和 CSS 构建跨平台的桌面应用程序。大名鼎鼎的 Visual Studio Code 和 Atom 就是基于 Electron 开发的。简单来说,Electron 内置了 Chromium 渲染引擎和 NodeJS 运行时。Chromium 渲染引擎负责渲染接收到的 HTML 和 CSS 文件。NodeJS 运行时使得 JavaScript 可以操作桌面级交互,比如通知栏提醒,构建原生菜单栏等。
服务端 Server
服务器绑定至本地 IP:127.0.0.1,端口为 5000。服务器持续监听来自客户端的请求,解析客户端请求资源路径,调用对应资源路径相应方法。比如:
这段代码指明,服务端解析 http 请求得到资源路径”/index”后,自动调用对应 index() 方法,服务器获取期刊表所有数据,并动态生成 HTML 文件,返回至客户端,Electron 的
Chromium 渲染引擎就会渲染 HTML 文件进行显示。
客户端界面设计
由于我们使用 HTML+CSS 的技术来设计 GUI,我们的 GUI 设计的自由性比较强,可以根据自己的想法设计。传统的 GUI 设计如 C++ 的 QT,Java 的 Swing 和 JavaFX,这些都是基于操作系统提供的内置 GUI 组件进行 GUI 设计,因此设计出来的 GUI 比较符合原操作系统的风格。
出于方便和观赏性,我参考了 Bootstrap 官网的几个示例页面,在这些页面的基础上修改得到适合我们项目的 GUI。
客户端 Client
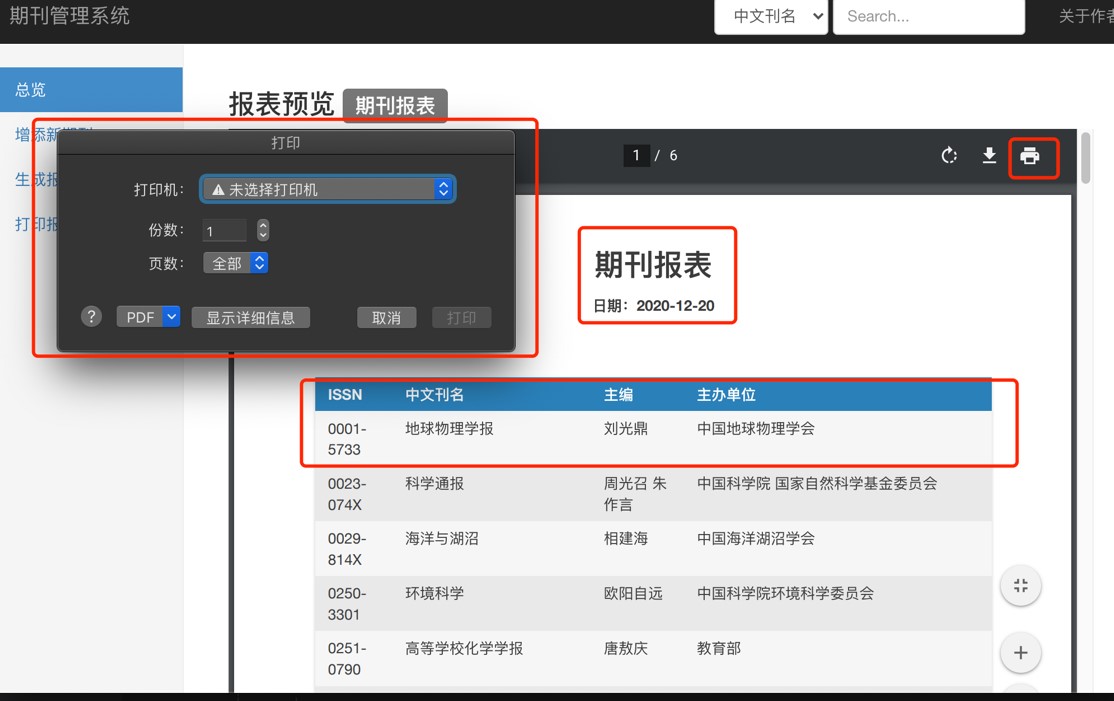
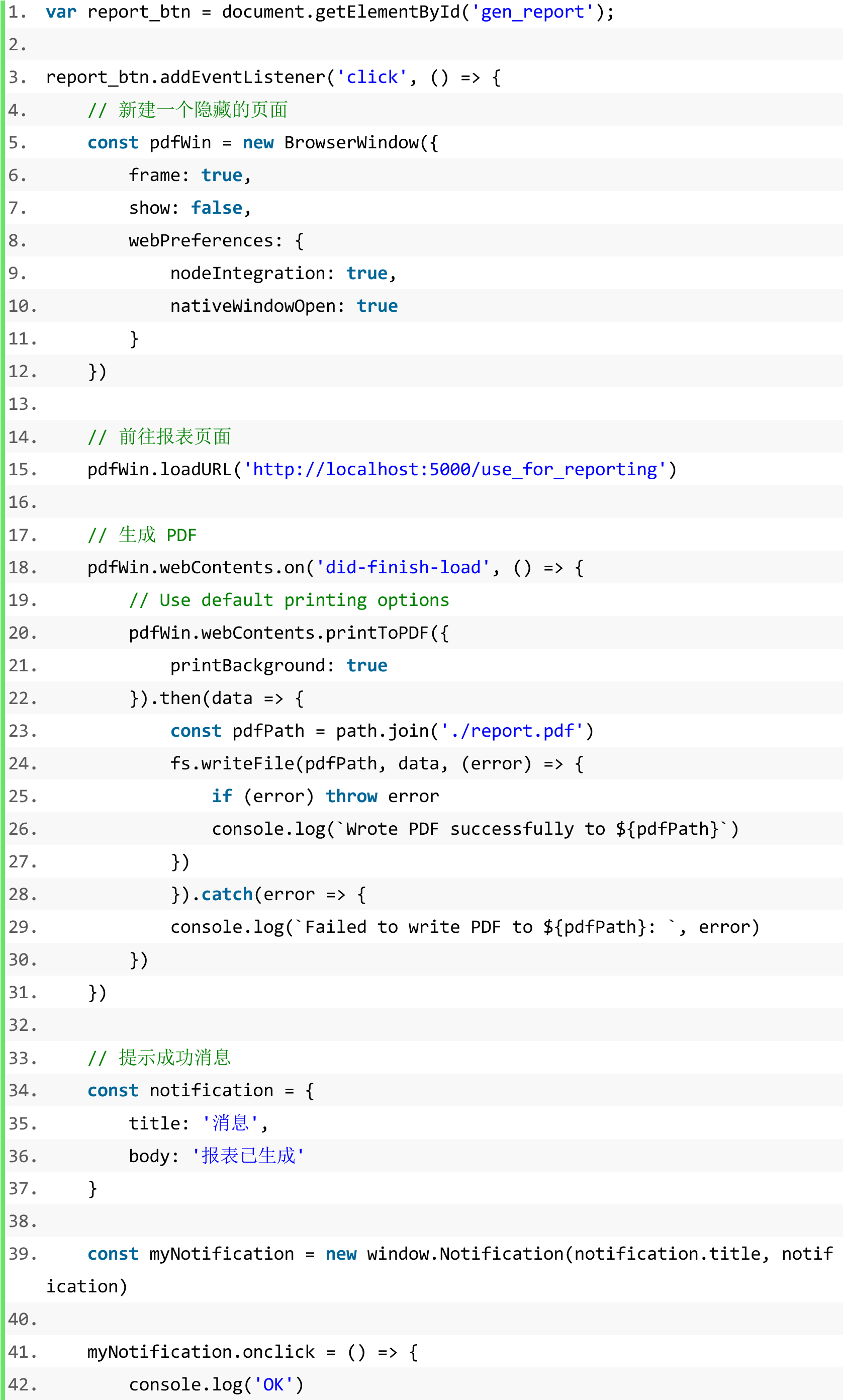
客户端核心的功能就是制作报表。客户端首先点击“生成报表”,此时客户端就会发送报表 HTML 请求,服务器返回报表 HTML 至客户端,客户端接收到 HTML 的内容后本地转成
PDF。此时 PDF 还未标注页码。于是,使用 reportLab 对生成的 PDF 进行加工,添加上页码,现在报表制作成功。再在客户端点击“报表预览”即可进行对 PDF 的预览。
数据集录入由于老师提供的数据集是以 PDF 的形式记录,并且数据量大,总共 100 个期刊,每个期刊至少都有 10 个属性字段,人工录入非常的耗时耗力。因此我用了 Python 的 tika 模块,将 PDF 中的文字提取出来,现在就可以用 Python 的 re 库分割出每个期刊和期刊的每个属性。
软件 demo
本软件基于跨平台开发,Windows/MacOS/Linux 均可使用,但使用前需安装:
c++
Python3
Node.js
MySQL8
Java1.8(Python tika库需要使用Java)环境配置文档及源代码参见:https://github.com/astzls213/database-HW
Demo 环境:(MacOS10.14.5/Python3.7.2/MySQL8.0.17/NodeJS12.18.4)
Login 界面
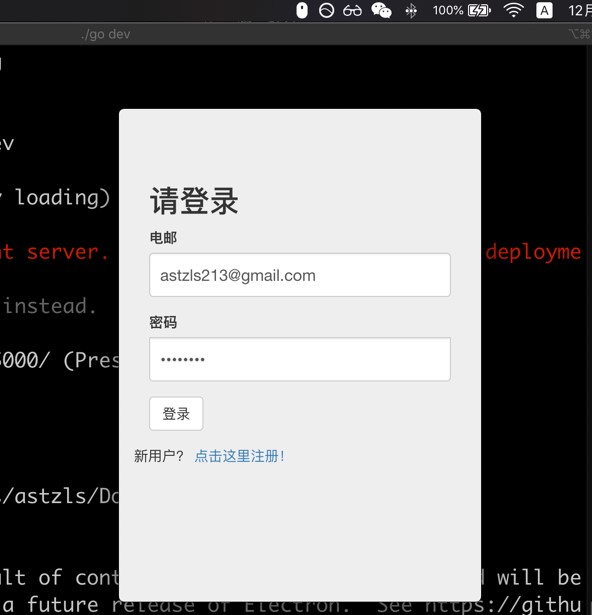
Regiter 界面
主界面

期刊详情演示

增添期刊演示
插入期刊信息:
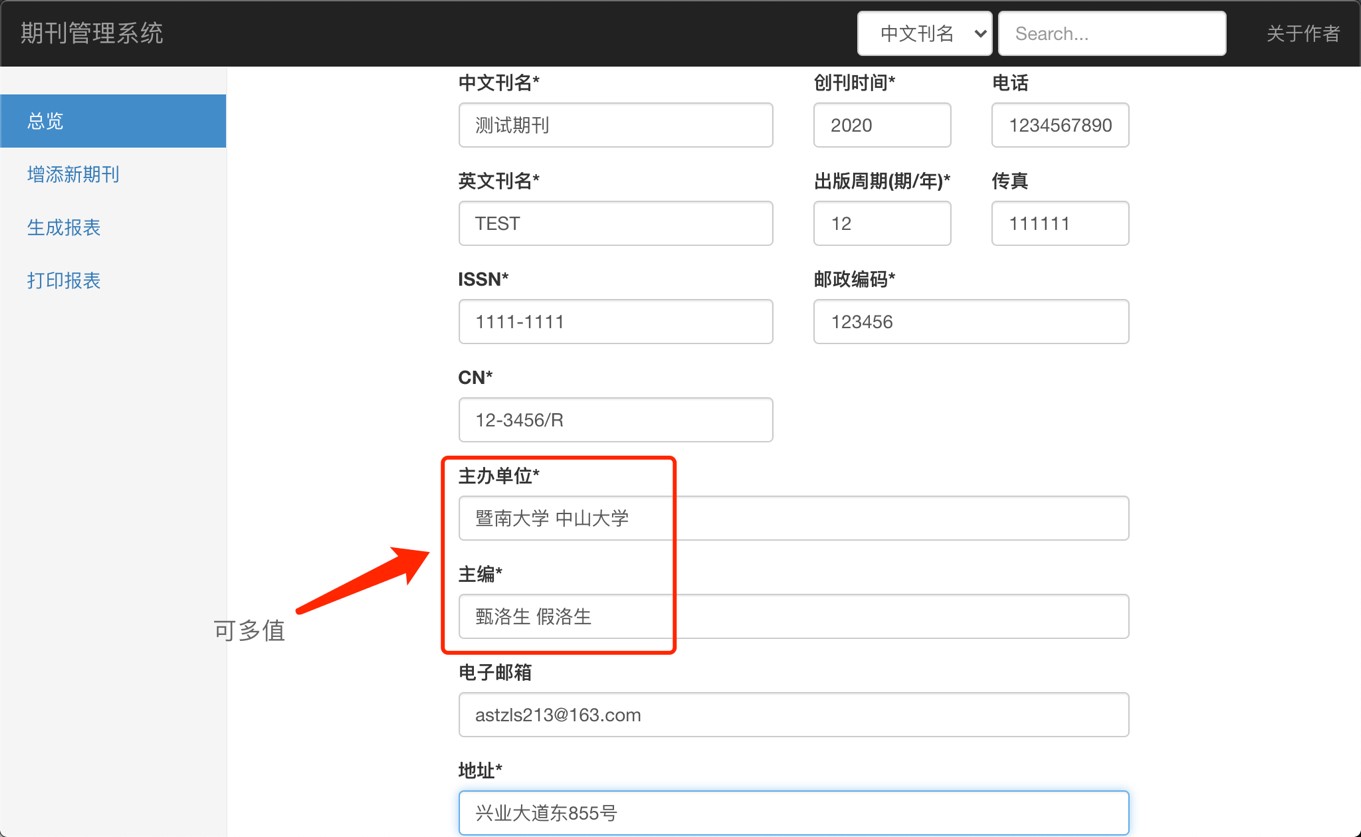
插入结果:
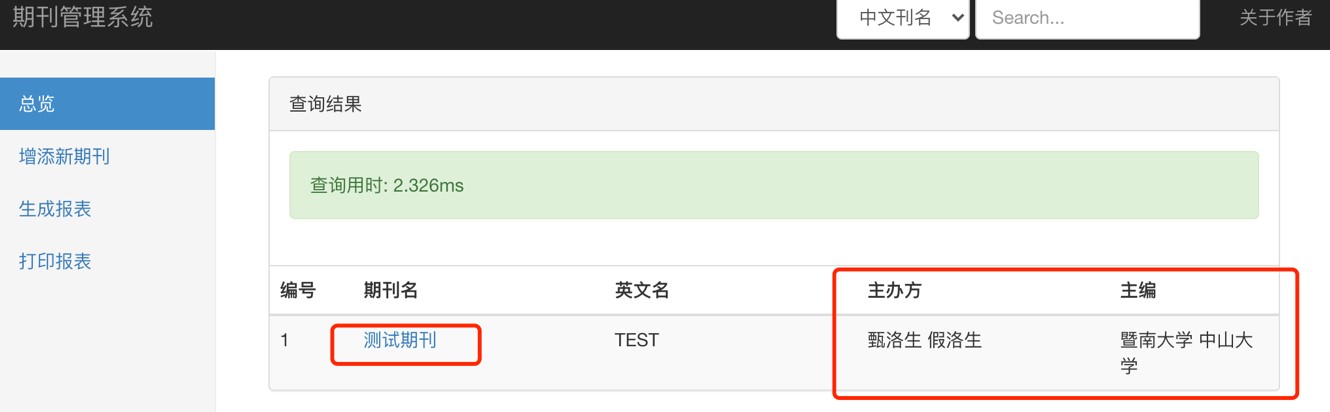
删除期刊演示
删除刚刚的测试期刊:

删除成功:
修改期刊信息演示


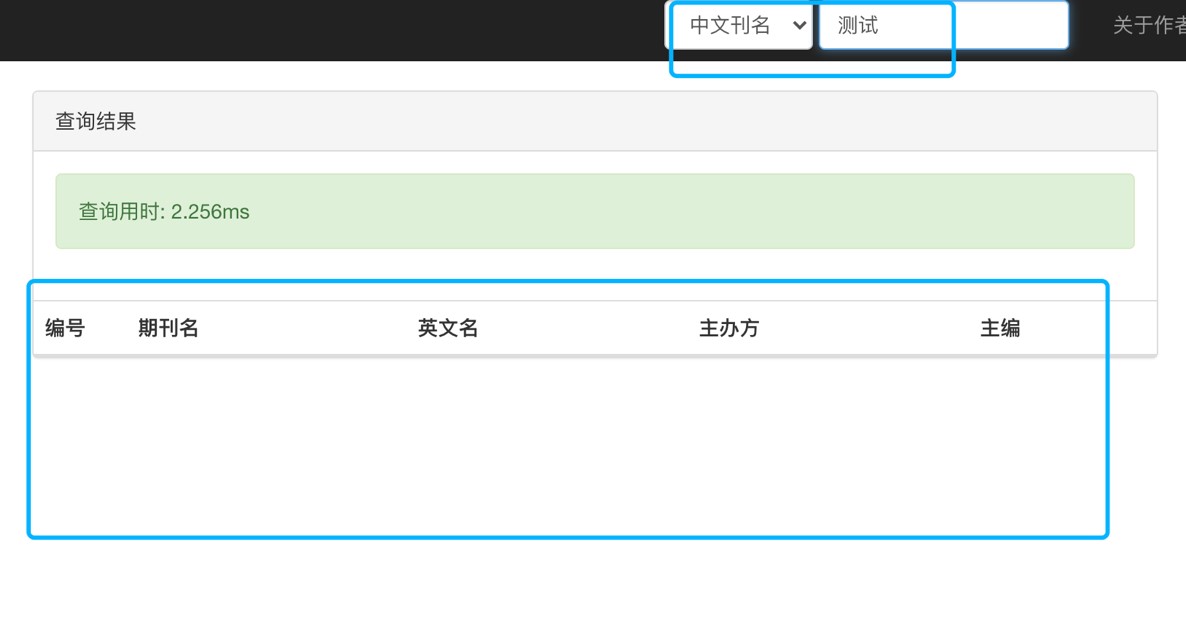
查询期刊演示
模糊匹配结果:

制作报表演示

实验总结
通过本次实验,我 大的收获就是了解到前后端是如何协作处理的。所谓前端,就是指客户端部分的业务逻辑,使用 html/css/javascript 来构建网页。而后端要做的工作就是解析处理来自客户端的请求,比如客户端想增添一个期刊,那么前端就会向后端发送请求信息 D,D 也就是所谓的 HTTP 协议信息。后端通过网络适配器接收到了 D,进行解析。解析得知客户端想要增添期刊,跳转至增添期刊响应函数 F。函数 F 从解析后的 D 获得期刊信息 I,再分析 I 中数据与数据库是否冗余?是否不符合格式要求?若不符合就返回错误信息至客户端。若符合,则注入响应 SQL 语句至数据库执行,增添期刊。数据库 insert 成功返回消息至后端,后端得知增添成功后,再返回消息至客户端。
其次,了解到后端是如何与数据库进行交互的。对于 Java 后端,一般就是使用 JDBC 连接数据库。而对于 Python 后端,一般通过 PyMySQL 模块连接 MySQL 进行操作。并且,操纵数据库不一定非要使用原生 SQL 语句进行编程,还可使用 ORM 对象关系映射数据库的表。当开发项目的时候,如果不使用 ORM,可能会写 SQL 的代码,用来从数据库保存、删除、读取对象信息等等,而这些代码写起来很多重复,并且有 SQL 注入的危险。ORM 解决的主要问题是对象关系的映射。一般情况下,一个持久化类和一个表对应,类的每个实例对应表中的一条记录,类的每个属性对应表的每个字段。使用 ORM 大大提高了开发效率。ORM 提供了对数据库的映射,不用写 SQL 语句编程,就能够像操作对象一样与数据库进行交互。在本实验中,使用的 ORM 框架是 Flask-SQLAlchemy。
暨南大学本科实验报告专用纸(附页)
附录:主要功能的源代码清单:
登录界面: login.html:
blueprint.py(部分):
更新功能:
blueprint.py(部分):
```python
@main.route('/update/
检查当前用户是否有权限
if current_user.type == False:
flash('此操作无权限对于当前用户。', 'danger')
return redirect(url_for('main.index'))
journal = Journal.query.filter_by(issn=issn).first()
POST
if update_form.insert_submit.data and update_form.validate():
start = datetime.now()
检查 issn/cn 是否重复
sanity_check = []
sanity_check.append(Journal.query.filter_by(issn=update_form.issn.da ta).first())
sanity_check.append(Journal.query.filter_by(cn=update_form.cn.data). first())
if sanity_check[0] is not None:
if sanity_check[0].issn != journal.issn:
flash('ISSN: {} 已存在数据库中!请仔细检查。 '.format(journal.issn), 'danger')
return redirect(url_for('main.insert'))
if sanity_check[1] is not None:
if sanity_check[1].cn != journal.cn:
flash('CN: {} 已存在数据库中!请仔细检查。
'.format(journal.cn), 'danger')
return redirect(url_for('main.insert'))
替换 '' 为 None
if update_form.tel.data == '':
update_form.tel.data = None
if update_form.fax.data == '':
update_form.fax.data = None
先删除之前的信息
for tmp in journal.emails:
db.session.delete(tmp)
for tmp in journal.editors:
journal.editors.remove(tmp)
for tmp in journal.organizers:
journal.organizers.remove(tmp)
先提交删除 否则后面外键不统一
db.session.commit()
基本字段的修改
journal.cn_name = update_form.cn_name.data
journal.en_name = update_form.en_name.data
journal.issn = update_form.issn.data
journal.cn = update_form.cn.data
journal.address = update_form.address.data
journal.tel = update_form.tel.data
journal.fax = update_form.fax.data
journal.public_year = update_form.public_year.data
journal.public_cycle = update_form.public_cycle.data
journal.zipcode = update_form.zipcode.data
一对多 多对多关系修改
emails = update_form.emails.data.split('/')
editors = update_form.editors.data.split('/') 53. organs = update_form.organizers.data.split('/')
54.
for loop_item in emails:
if loop_item == '': # 跳过空项
continue
if Email.query.filter_by(email=loop_item).first() is None:
db.session.add(Email(loop_item, journal))
else:
flash('此邮箱已经存在,请仔细检查!', 'danger')
return redirect(url_for('main.insert'))
63.
for loop_item in editors:
if loop_item == '': # 跳过空项
continue
tmp = Editor.query.filter_by(name=loop_item).first()
if tmp is None: # 如果此前没出现过这个主编 69. journal.editors.append(Editor(loop_item))
else:
tmp.journals.append(journal)
for loop_item in organs:
if loop_item == '': # 跳过空项
continue
tmp = Organizer.query.filter_by(name=loop_item).first()
if tmp is None: # 如果此前没出现过这个主办方
journal.organizers.append(Organizer(loop_item))
else:
tmp.journals.append(journal)
# 提交
db.session.commit()
# 返回总览 并给出插入成功提示
end = datetime.now()
msg = '修改用时: %.3fms' % ((end-start).total_seconds()*1000,)
flash('期刊信息修改成功!' + msg, 'success')
return redirect(url_for('main.index'))
# GET 自动填充原先字段
update_form.cn_name.data = journal.cn_name
update_form.en_name.data = journal.en_name
update_form.issn.data = journal.issn
update_form.cn.data = journal.cn
update_form.public_year.data = journal.public_year
update_form.public_cycle.data = journal.public_cycle
update_form.address.data = journal.address
update_form.zipcode.data = journal.zipcode
update_form.tel.data = journal.tel
update_form.fax.data = journal.fax
# Email/主编/主办单位的填充稍微麻烦些
padding = ''
for tmp in journal.emails:
padding = padding + tmp.email + '/'
update_form.emails.data = padding[:-1] # 丢弃末尾 '/'
padding = ''
for tmp in journal.editors:
padding = padding + tmp.name + '/'
update_form.editors.data = padding[:-1] # 丢弃末尾 '/'
padding = ''
for tmp in journal.organizers:
padding = padding + tmp.name + '/'
update_form.organizers.data = padding[:-1] # 丢弃末尾 '/'
flash('1. *为必填项', 'info')
flash('2. 电子邮箱/主编/主办单位多个时请用 / 隔开','info')
return render_template('jour_form.html', form=update_form)
```
查询功能:
blueprint.py(部分):
```python @main.route('/search', methods=['POST']) @login_required def search():
获取 POST 数据
option = request.form.get('option', None)
found = request.form.get('search', '')
检查输入栏是否为空
if found is '':
flash('输入栏为空!','info')
return redirect(url_for('main.index'))
else:
start = datetime.now() # 记录开始时间点 13. # 根据 Option 查找与 found 模糊匹配的数据库
if option == 'cn_name':
found = Journal.cn_name.like('%{}%'.format(found))
results = Journal.query.filter(found).all()
elif option == 'issn':
found = Journal.issn.like('{}%'.format(found))
results = Journal.query.filter(found).all()
elif option == 'cn':
found = Journal.cn.like('{}%'.format(found))
results = Journal.query.filter(found).all()
end = datetime.now() # 记录结束时间点
msg = '查询用时: %.3fms' % ((end-start).total_seconds()*1000,)
flash(msg,'success')
渲染结果
return render_template('sear_result.html', results=results)
```
报表功能:
blueprint.py(部分):
```
output = PdfFileWriter()
with open(path, 'rb') as f:
pdf = PdfFileReader(f,strict=False)
n = pdf.getNumPages()
if batch == 0:
batch = -n
createPagePdf(n,tmp)
with open(tmp, 'rb') as ftmp:
numberPdf = PdfFileReader(ftmp)
for p in range(n):
if not p%batch and p:
newpath = path.replace(base, base[:-4] + '
page
%d'%(p// batch) + path[-4:])
with open(newpath, 'wb') as f:
output.write(f)
output = PdfFileWriter()
page = pdf.getPage(p)
numberLayer = numberPdf.getPage(p)
page.mergePage(numberLayer)
output.addPage(page)
if output.getNumPages():
newpath = path.replace(base, 'final.pdf')
with open(newpath, 'wb') as f:
output.write(f)
os.remove(tmp)
return send_file('../final.pdf')
# 打印报表视图
@main.route('/print_report')
@login_required
def print_report():
return render_template('print_report.html')
# 报表视图 请勿添加 login_required
# 否则 electron 打不开页面
@main.route('/use_for_reporting')
def report_table():
journals = Journal.query.all()
today = str(datetime.now()).split()[0]
return render_template('report.html', journals=journals, current_date=to day)
```
renderer.js(部分):
参考文献
- 老干部之家期刊编审管理系统的设计与实现(山东大学·谭林)
- 出版社图书出版管理系统的设计与实现(山东大学·刘彤)
- 成都新潮传媒集团采编流程管理系统的设计与实现(电子科技大学·张迪莎)
- 基于Web的期刊在线审稿系统设计与实现(西华大学·时冰陵)
- 网络环境下数字化期刊的研究(河北农业大学·汪涛)
- 网络环境下数字化期刊的研究(河北农业大学·汪涛)
- 老干部之家期刊编审管理系统的设计与实现(山东大学·谭林)
- 高职院校毕业论文管理系统的设计与实现(燕山大学·崔亮)
- 基于.NET平台的期刊在线采编管理信息系统的设计与实现(厦门大学·肖晶)
- 基于SH架构的编辑部管理系统的设计与实现(吉林大学·崔婉依)
- 老干部之家期刊编审管理系统的设计与实现(山东大学·谭林)
- 基于.NET平台的期刊在线采编管理信息系统的设计与实现(厦门大学·肖晶)
- 基于.NET平台的期刊在线采编管理信息系统的设计与实现(厦门大学·肖晶)
- 老干部之家期刊编审管理系统的设计与实现(山东大学·谭林)
- 农业期刊采编系统的设计与实现(安徽农业大学·江珊)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设助手 ,原文地址:https://bishedaima.com/yuanma/35972.html