
开源软件基础大作业
NBA 历年 MVP 表现变化趋势图
项目背景以及意义
项目背景:,利用 urllib 获取网页数据,然后利用 bs4 的 beautifulSoup 进行数据的解析和获取想要的数据,再利用 re 正则表达式结合 bs4 得出想要的数据,利用 sqlite3 存储数据,把数据从数据库中取出来,然后利用 matplotlib.pyplot 进行可视化的一个项目。
生存了以下这些图:
- NBA 历年 MVP 得分变化趋势(折线图)
- NBA 历年 MVP 得分条形图
- NBA 历年 MVP 助攻变化趋势(折线图)
- NBA 历年 MVP 助攻条形图
- NBA 历年 MVP 篮板变化趋势(折线图)
- NBA 历年 MVP 篮板条形图
项目意义:一个怎么样的球员才能获得 MVP,最好球队中的最好球员才有机会获此殊荣。每一个赛季都会产生一支总冠军球队,也就是说最少会有 15 个球员获得总冠军戒指,而 MVP 只有一个。换句话说总冠军决定了一个球员的高度,而 MVP 则是体现一个球员的宽度。MVP 比总冠军更难得,拥有数量更多的总冠军能提升你的历史地位,而 MVP 是在评价球员伟大层面的指标。
- 纵观 NBA 历年 MVP 的得分,助攻,篮板,从一个横向的角度来分析 MVP 球员的总体水平,很好的体现了一个球员的宽度,有着非凡的意义。
- 总冠军是所有球员的追求,mvp 是梦想。这代表着你是最顶尖的球员,最重要的球员。
- MVP 的实际意义就是说你很伟大。
- 项目创新点
一:用到了 matplotlib 进行可视化,matplotlib 是 python 中很强大的一款绘图工具包,里面提供了类似于条形图、柱状图、折线图等一系列常见的图形的绘制方法。在绘图的时候,经常要对图中的相关数据进行标识以及添加图例、标题等。
二:利用课堂上讲过的 sqlite3 存储数据
SQLite 是目前最流行的开源嵌入式数据库,和很多其他嵌入式存储引擎相比(NoSQL),如 BerkeleyDB、MemBASE 等,SQLite 可以很好的支持关系型数据库所具备的一些基本特征,如标准 SQL 语法、事务、数据表和索引等。事实上,尽管 SQLite 拥有诸多关系型数据库的基本特征,然而由于应用场景的不同,它们之间并没有更多的可比性。下面是 SQLite 的主要特征:
1). 管理简单,甚至可以认为无需管理。 2). 操作方便,SQLite 生成的数据库文件可以在各个平台无缝移植。 3). 可以非常方便的以多种形式嵌入到其他应用程序中,如静态库、动态库等。 4). 易于维护。
综上所述,SQLite 的主要优势在于灵巧、快速和可靠性高。SQLite 的设计者们为了达到这一目标,在功能上作出了很多关键性的取舍,与此同时,也失去了一些对 RDBMS 关键性功能的支持,如高并发、细粒度访问控制(如行级锁)、丰富的内置函数、存储过程和复杂的 SQL 语句等。正是因为这些功能的牺牲才换来了简单,而简单又换来了高效性和高可靠性。
项目的设计
一:数据爬取部分
数据的爬取分为如下几个步骤:
利用 urllib 获取网页数据
urllib.request 可以用来发送 request 和获取 request 的结果:
包括 urllib.request.urlopen()基本使用
urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton (授权验证), redirections (重定向), cookies (浏览器 Cookies)以及其它内容。
可以发现,response = urllib.request.urlopen(request)我们依然是用 urlopen() 方法来发送这个请求, urlopen() 方法的参数是一个 Request ,通过构造这个这个数据结构,一方面我们可以将请求独立成一个对象,另一方面可配置参数更加丰富和灵活。
c++
headers 参数是一个字典,你可以在构造 Request 时通过 headers 参数传递,也可以通过调用 Request 对象的 add_header() 方法来添加请求头。请求头最常用的用法就是通过修改 User-Agent 来伪装浏览器,默认的 User-Agent 是 Python-urllib ,可以通过修改它来伪装浏览器,比如要伪装火狐浏览器,可以把它设置为/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/2.0.0.11
urllib.error包含了urllib.request产生的异常
urllib.error 可以接收有 urllib.request 产生的异常。urllib.error 有两个方法,URLError 和 HTTPError。URLError 是 OSError 的一个子类,HTTPError 是 URLError 的一个子类,服务器上 HTTP 的响应会返回一个状态码,根据这个 HTTP 状态码,我们可以知道我们的访问是否成功。200 状态码,表示请求成功,再比如常见的 404 错误等。
- urllib.parse 用来解析和处理 URL
- 使用 urllib.parse.urlparse 将 url 分为 6 个部分,返回一个包含 6 个字符串项目的元组:协议、位置、路径、参数、查询、片段
- 使用 urllib.parse.urlsplit 将 url 分为 5 个部分,返回一个包含字符串项目的元组:协议、位置、路径、查询、片段
- urllib.parse.parse_qs 返回字典
- urllib.parse.parse_qsl 返回列表
- urllib.robotparse 用来解析页面的 robots.txt 文件
- 利用 bs4 的 beautifulSoup 进行数据的解析和获取想要的数据
- 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
- 利用 re 正则表达式结合 bs4 得出想要的数
Re 正则表达式优点:只要熟练应用正则表达式,而且匹配的目标是纯文本,那么相比于写分析器来说,正则可以更快速的完成工作。还有在捕获字符串的能力,正则也可以很好的完成工作,比如截取 url 的域名或者其他的等等
缺点:1.正则表达式只适合匹配文本字面,不适合匹配文本意义:像匹配 url,email 这种纯文本的字符就很好,但比如匹配多少范围到多少范围的数字,如果你这个范围很复杂的话用正则就很麻烦。或者匹配 HTML,这个是很多人经常遇到的,写一个复杂匹配 HTML 的正则很麻烦,不如使用针对特定意义的处理器来处理(比如写语法分析器,dom 分析器等)。
- 易引起性能问题:像.*这种贪婪匹配符号很容易造成大量的回溯,性能有时候会有上百万倍的下降,编写好的正则表达式要对正则引擎执行方式有很清楚的理解才可以。
- 正则的替换功能较差:甚至没有基本的截取字符串或者把首字母改变大小写的功能,这对于 url 重写引擎有时候是致命的影响。
- 利用 sqlite3 存储数据
SQLite 是一个进程内的轻量级嵌入式数据库,它的数据库就是一个文件,实现了自给自足、无服务器、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这就体现出来 SQLite 与其他数据库的最大的区别:SQLite 不需要在系统中配置,直接可以使用。且 SQLite 不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite 可直接访问其存储文件。
缺点:1。并发访问的锁机制。SQLite 在并发(包括多进程和多线程)读写方面的性能一直不太理想。数据库可能会被写操作独占,从而导致其它读写操作阻塞或出错。2。SQL 标准支持不全。在它的官方网站上,具体列举了不支持哪些 SQL92 标准。不支持外键约束。3。网络文件系统(NFS)有时候需要访问其它机器上的 SQLite 数据库文件,就会把数据库文件放置到网络共享目录上。这时候你就要小心了。当 SQLite 文件放置于 NFS 时,在并发读写的情况下可能会出问题(比如数据损坏)。原因据说是由于某些 NFS 的文件锁实现上有 Bug。
- 二:数据可视化部分
- 把所有数据从数据库中取出来
- 利用了 matplotlib.pyplot
matplotlib.pyplot 是一个有命令风格的函数集合,它看起来和 MATLAB 很相似。每一个 pyplot 函数都使一副图像做出些许改变,例如创建一幅图,在图中创建一个绘图区域,在绘图区域中添加一条线等等。在 matplotlib.pyplot 中,各种状态通过函数调用保存起来,以便于可以随时跟踪像当前图像和绘图区域这样的东西。绘图函数是直接作用于当前 axes(matplotlib 中的专有名词,图形中组成部分,不是数学中的坐标系。)
随后输出下面这些图片:
- NBA 历年 MVP 得分变化趋势
- NBA 历年 MVP 得分条形图
- NBA 历年 MVP 助攻变化趋势
- NBA 历年 MVP 助攻条形图
- NBA 历年 MVP 篮板变化趋势
- NBA 历年 MVP 篮板条形图
- 如何实现
- 一:数据爬取部分
- 数据的爬取分为如下几个步骤
- 利用 urllib 获取网页数据
- 利用 bs4 的 beautifulSoup 进行数据的解析和获取想要的数据
- 利用 re 正则表达式结合 bs4 得出想要的数据
- 利用 sqlite3 存储数据
- 二:数据可视化部分
- 把所有数据从数据库中取出来
- 利用了 matplotlib.pyplot 进行可视化
- 测试
下面是在 jupyter notebook 中的一些测试截图:
输出折线图
NBA 历年 MVP 得分变化趋势
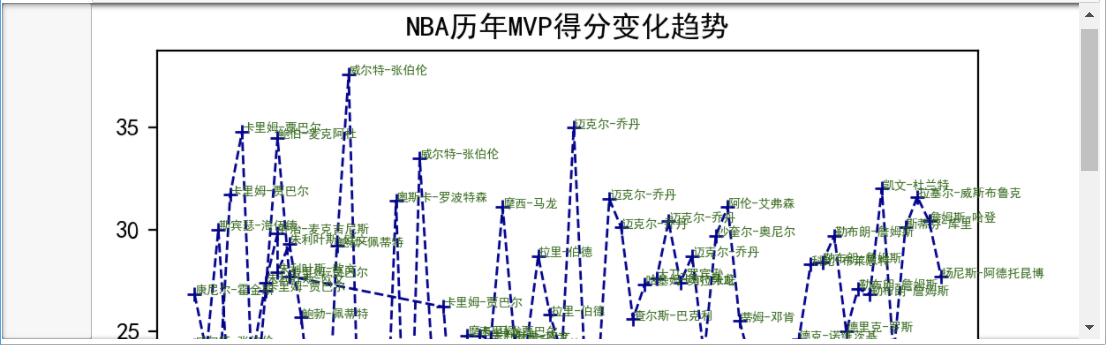

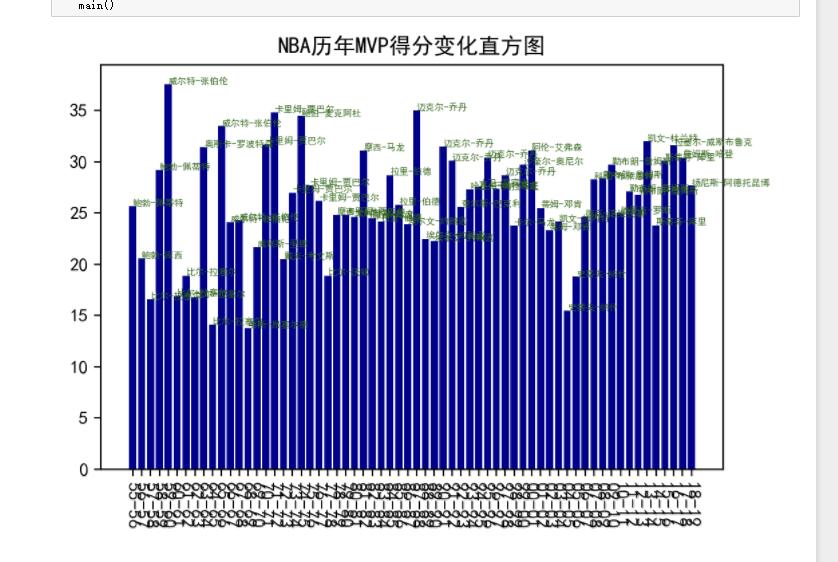
输出直方图
NBA 历年 MVP 得分变化直方图
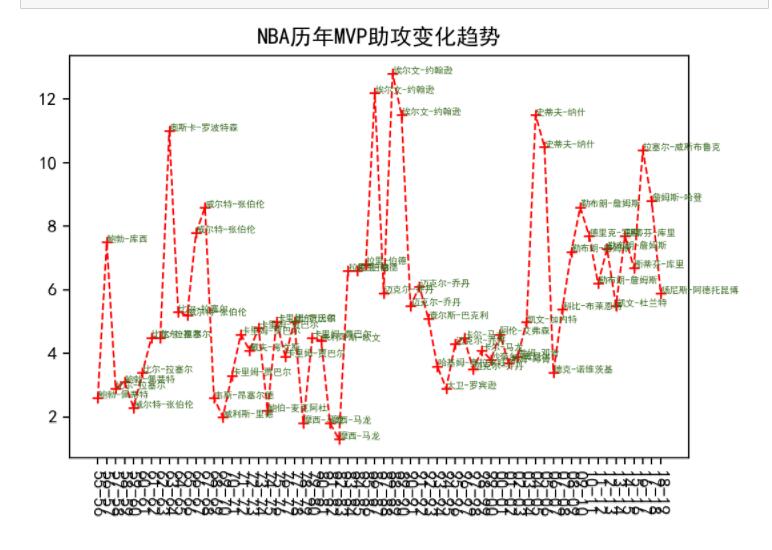
输出:NBA 历年 MVP 助攻变化趋势折线图
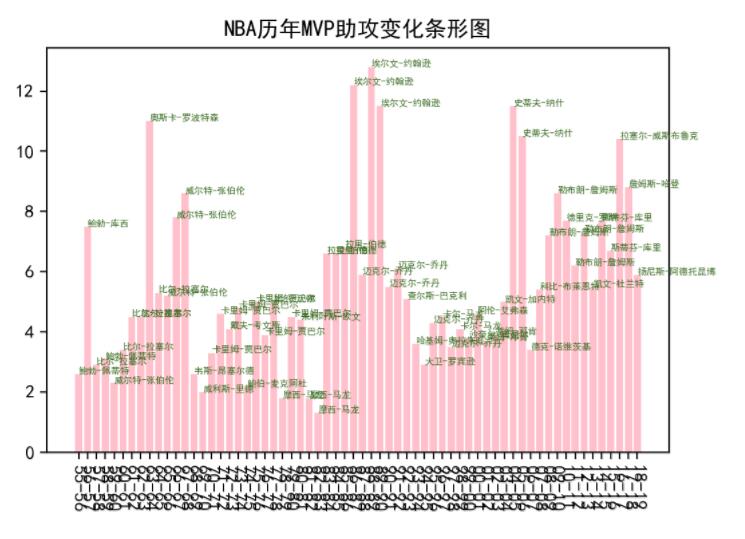
输出:
NBA 历年 MVP 助攻变化条形图
输出折线图
NBA 历年 MVP 篮板变化趋势

NBA 历年 MVP 篮板变化条形图

项目分析
利用 urllib 获取网页数据,然后利用 bs4 的 beautifulSoup 进行数据的解析和获取想要的数据,再利用 re 正则表达式结合 bs4 得出想要的数据,利用 sqlite3 存储数据,把数据从数据库中取出来,然后利用 matplotlib.pyplot 进行可视化的一个项目。
得出:
- NBA 历年 MVP 得分变化趋势(折线图)
- NBA 历年 MVP 得分条形图
- NBA 历年 MVP 助攻变化趋势(折线图)
- NBA 历年 MVP 助攻条形图
- NBA 历年 MVP 篮板变化趋势(折线图)
- NBA 历年 MVP 篮板条形图
- 这些图。
- 不足以及可改进之处
SQLite 的缺点:1。并发访问的锁机制。SQLite 在并发(包括多进程和多线程)读写方面的性能一直不太理想。数据库可能会被写操作独占,从而导致其它读写操作阻塞或出错。2。SQL 标准支持不全。在它的官方网站上,具体列举了不支持哪些 SQL92 标准。不支持外键约束。3。网络文件系统(NFS)有时候需要访问其它机器上的 SQLite 数据库文件,就会把数据库文件放置到网络共享目录上。这时候你就要小心了。当 SQLite 文件放置于 NFS 时,在并发读写的情况下可能会出问题(比如数据损坏)。原因据说是由于某些 NFS 的文件锁实现上有 Bug。
- 界面还可以做进一步美化,变得更简洁,一目了然。
- 可以多找几个网站进行数据收集,提高数据的可信度,收集的数据还不够多。
- 还可以制作更多种类的图表,有利于使用者从不同的角度来分析数据,方便使用。
- 成员贡献
- 周子康(组长)
- 工作占比:40%
主要工作内容:(1)总负责(2)撰写报告(3)选择爬取数据的网站(4)负责数据爬取代码的编写(5)负责数据可视化的代码编写(6)设计与实现前端界面(7)负责数据的存取与可视化代码的编写。
- 吴宇嘉(组员)
- 工作占比:20%
- 主要工作内容:(1)撰写报告(2)进行项目测试工作(3)进行数据的分析与前端界面的一些实现。
- 宋济廷(组员)
- 工作占比:20%
- 主要工作内容:(1)撰写报告(2)进行项目测试工作(3)负责数据的一些存取方面的代码编写。
- 李修华(组员)
- 工作占比:20%
- 主要工作内容:(1)撰写报告(2)进行项目测试工作(3)负责数据可视化的总体设计。
- 感想
首先很庆幸自己选到了这门个性化选修课,可能是我个人比较认为这门课程所用的语言很特别很奇妙,老师也很有趣,不仅能让我们更好的了解 Python 这门语言真正的用途。在学习开源软件基础这门课程的这段时间以来,并且自己也能认识并且学习到很多知识。
作为本次大作业的组长,看着项目从呱呱坠地到瓜熟蒂落,就像看着自己的孩纸长大一样。心中感慨万千,成长的过程总是快乐与痛苦并行,喜悦与烦恼同在的。其实我对 python 也有比较大的兴趣,所以自己研究了很长时间的 python,从 python 小白到小有所成吧,期间也花了很大的努力,学习 python 是一个很累的过程,但是不苦,在开源软件基础这门课中我学到的东西很多,python 基础知识、爬虫相关技术以及网站框架的架构和制作。再如实现爬虫需要用到 requests 以及 BeautifulSoup 模块和 re 正则表达式,等等这些都是完成一个项目的思维方式和构架。
通过这次开源软件基础大作业的学习,我感受到想要完成一个项目,不是一蹴而就的,需要耐心的一个一个功能的去完成,每写完一个代码模块的时候,真的会有一种非凡的成就感,不会的就去学习,然后根据自己课上所学到的知识,结合运用从而完成自己的项目。
在我看来,学习 python 的最大动力其实是兴趣。正如伟大的科学家爱因斯坦所说:“兴趣是最好的老师”。当你对编程具有浓厚的兴趣时,你就会想要自己动手编程出一个小程序,甚至是一个游戏。而编程的前提,是你需要掌握一门编程语言。在 python 的学习中,每当我从书中或在信安协会课程上学会新的语句或函数,我都会自己进行实验,编程出一个自己的小程序,同时修复各种 bug。这对我熟练掌握 python 是一个很大的帮助,在这个过程中,我慢慢掌握了各自的用法。当遇到自己无法解决的难题时,不要总是想着放弃,向老师或者同学求助也不失为一种好方法。
其实我对 python 也有比较大的兴趣,所以自己研究了很长时间的 python,因为之前也学习过 python 的一些基础知识,所以这次的大作业对我而言也是一个很好的锻炼。
通过这次的项目开发设计,我感受到了 python 的强大,大数据统计的功用,以及前端开发的魅力,以后的日子我也会继续努力学习,脚踏实地,与自己的组员一起成长。
参考文献
- 面向表达力评测的题目建设与分析系统设计与实现(南京大学·汤大业)
- 基于移动平台股票资讯搜索与预测系统研究(哈尔滨理工大学·滕文达)
- 主题网络爬虫的研究与设计(南京理工大学·朱良峰)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 面向表达力评测的题目建设与分析系统设计与实现(南京大学·汤大业)
- 基于SSH的科研绩效管理系统设计与实现(西华大学·刘全飞)
- 基于网络爬虫的排行榜系统设计与实现(北京邮电大学·刘全伟)
- 我奥网后端系统的设计、实现与优化(北京化工大学·吕登科)
- 在线投票系统设计与实现(电子科技大学·周艳萍)
- 基于数据挖掘的电视节目个性化推荐研究及实现(曲阜师范大学·徐晟杰)
- 基于深度学习的斯诺克视频解说自动生成研究(东南大学·孙照月)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 主题网络爬虫的研究与设计(南京理工大学·朱良峰)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设货栈 ,原文地址:https://bishedaima.com/yuanma/35768.html









