
网上智能导购系统
本文主要的对象为消费者常购产品,基于此开发以 Web 为基础的导购系统,其中主要用的 Web 数据挖掘技术包括应用 Web 实现的挖掘以及商品关联的规则等。同时,网络购物系统还综合的利用 Java 技术、MVC 模式以及 J2EE 平台。
功能概述
网上智能导购系统为用户在网上海购提供支持,对在该系统中注册过的网上商店搜索,找出满足用户需要的商品,根据系统要完成的任务,可以将系统分为前台处理和后台处理两部分。
前台功能主要为客户提供各种操作,来实现客户与系统之间的交互,包指消费者用户注册、登录、商品搜索和购买等,企业用户的在线注册、发布商品信息等。
后台管理主要有系统管理员的维护操作和系统的后台的智能挖掘处理等。其中管理员信息维护包指对消费者、企业的注册信息的维护和搜集的商品信息的维护,后台智能挖掘主要包括系统对商品信息的搜索、智能推荐等。
功能模块描述
(1)用户管理模块:该模块主要包括消费者、企业和管理员三类用户的操作。
消费者用户主要是在系统中进行注册,描述自己个人倾向信息等。企业用户指各个网上商店在该系统中进行注册,在系统中存储网店信息,以便于系统对该网站进行查询,来搜取商品销售信息。系统管理员用户主要对消费者用户和企业用户进行管理、维护。
(2)商品管理模块:主要对商品的信息进行存储和管理,包指商品本身的信息和商家的信息等。
商品信息管理是对商品本身的信息进行管理,包招商品的名称、定价、类别和产地等。商家商品信息主要用来对从各个注册网上商店所出售的商品信息进行存储和管理,如出售该商品的商家站点、网址及出售价格等。发布统计报告是系统定期的对商品的信息进行统计和分析,为系统提供决策提供数据。
(3)网上购物模块:网上购物是系统的核心,用来完成消费者与系统之间的交互,消费者通过网上购物来选取和购买所需要的商品。该模块分三个关键功能:商品浏览、商品搜索和商品购买。
商品浏览是指系统会将近期热销的商品在系统的首页进行展示,以便用户的查找,并对定期的对热销商品进行更新,做到实时性。商品搜索是指消费者可以通过系统的搜索引擎与系统进行交互,向系统提交自己的需求,系统通过搜索分析来返回用户所需要的商品信息,来供用户进行选择。商品购买主要是指当消费者查询到了所需要的商品,将其添加到购物车中,系统通过代理来向商家进行下订单。
(4)智能椎荐模块:智能椎荐是该系统的另一个关键功能,它主要是根据商品的销售情况或根据消费者的购买倾向实时向用户进行商品推荐,主要有周期性商品排行和实时商品推荐两个功能。
周期性商品排行是指系统根据近期商品的销售情况及清单来进行分析,将热销商品按照其销量进行排名,然后放到系统的首页,供消费者进行选购。实时推荐是指系统根据消费的购买情况及同类消费者的购买情况或商品的关联性,向消费者进行商品推荐,为实现实时推荐功能,本系统设计两种推荐策略:消费者倾向推荐和关联商品推荐。
功能结构图
第一章绪论
1.1 课题背景和意义
随着计算机网络的蓬勃发展,特别是电子商务和 Web 服务的广泛利用,网络消费者的数量也急剧的增加,商家期望依靠有效的网络营销赢得更多的顾客,获得丰厚的利润。如何在立足网络消费者特点的基础上,有效的做好引导顾客购买服务工作是广大网络商家积极思考的问题。
电子商务规模不断发展,其规模也得到了一定的扩展,消费者利用引擎实现对目前浏览器中存在的大量的信息进行优选难度较大。对于消费者而言,其通过网站进行信息的采集,获取有效信息,并对所选择的商品进行有效的类比。该过程具有时间成本很高,工作量很大的特点。能够对消费者不需要的信息进行筛选,增加了购买者的愿望[1]。
要支撑消费者的购物活动,开发合理的智能导购系统,能够实现信息服务的个性化特征。通过导购系统能够有效的对网购中遇到的多余的信息进行筛选,对于导购站点而言,能够为消费者提供足够多的优质的产品,而站点同时给消费者创建了自动搜索功能,因此,能够最大程度的满足消费者的需要。所以,智能导购系统的开发主要是要解决消费者对 Internet 海量信息检索及比较商品难度大的问题。也就是说该系统能够实现代替消费者进行相关信息的筛选,以满足其中的消费者需求为目的,基于购买历史进行相关商品的提供[2]。
近期,对于电子商务而言,其导购系统,不仅在理论上,同样在实践上都得到了极大程度的发展。而电子商务系统要深入的发展,必然是给智能导购系统提出了新的更高的要求,其也必然面临更多的挑战。对于需要克服的困难和亟需解决的问题,本文深入的进行研究和探索。
1.2 国内外研究现状
Web 挖掘是基于数据挖掘理论建立的,目前,在国外成果也是丰硕的。世界范围内多个高校也针对其进行了研究,同时也提出了新型的原型系统的构思,其中典型的有美国明尼苏达州立以及澳大利亚的 Simon Fraser 等大学。而他们提出的系统主要有 WebMinner、WebLogMiner 以及 WebWatcherl 等。对系统进行分类主要有站点文档的自动分类及用户导航和用户访问模式两种挖掘系统。其中 Oracle 公司近期开放并发布了 Oracle 8i 数据库,其能实现的数据对象也突破了传统数据的局限,也扩展到了 Web 页面的数据。此外,由微软公司也开发出了 SQLServer 2000,对于此系统而言,其功能更具备较为完善的 Web 功能,同时,能够对扩展标记语言(XML)进行支持,此外其挖掘引擎具有新颖性以及集成的特点,其中电子商务包括 B2B 以及 B2C 型在内的具有较高的效率[3-4]。
通常智能导购也叫做个性化的推荐系统,众多的学者都有各自不同的开发版本,首先是由 Robert Armstrong 等在 1995 年 3 月完成的,这些开发者多数来自卡耐基.梅隆大学,Web Watcher 即性化的导航系统;LIRA 则是由斯坦福大学 Marko Balabanovic 等研发出的;随后在 1999 年,由 Tanja Joerding 开发出最早的 TELLIM 即电子商务的原型,该开发者为德国 Dresden 技术大学的;在 2001 年由纽约大学实现了用户建模系统的构建,其中著名的研发者是 Gediminas Adoavicius 以及 Alexander Tuzhilin,该系统即 1:1Pro;同年, IBM 公司也做出了调整,对公司的电子商务平台进行了更新,主要是针对 Websphere 加入个性化的功能,也就对商务企业的电子商务网站实现了个性化[5-6]。
近期,Microsoft 公司开发并发布了以 XML 为基础的数据访问协议,此协议实现了开发商有效的将相关的数据提供给客户及平台。其中,对于.NET Web 服务协议中插入商业智能主要是由 XMLforAnalysis 辅助实现的。而 OLEDB for OLAP 以及 OLEDB for DateMining 都推动了此协议功能的不断强大,就 Microsoft 数据源访问能够提供支撑,同时以 Web 为基础的数据挖掘功能也能够被实现。对于 Internet 而言,也包括相当数量的 KDD 的电子的出版物,其中包括半月刊等,也就实现了各挖掘工具软件以及样本数据仓库等的下载,从而实现测试以及评价。网络中,利用自由论 DM Email Club 的理论对 DMKD 问题进行探讨,以此能够对 Web 站点进行适应,而通过浏览完成的路劲挖掘技术,主要是 Ming-SyanChen 等研究出的,此方法功能是分析 Web 站点日志[7]。
在日常中中文信息处理过程中,其中的相似度计算是基础且重要的,其针对部分领域发展起到决定性的作用。典型的包括了自动问答、信息检索、以实例为基础的机器翻译以及自动文摘等等。
目前,国内外关注和研究计算句子相似度方法的学者众多。对于英语而言,其对语义相似度计算过程中,要实现近义词集合及其间关系主要是利用 WordNet 以及 WordNet 完成。而中文的语义词典主要是应用 Hownet,该辞典主要是能实现网状分御结构的提供,对词语语义能够实现精确说明。
我国的智能导购系统的发展都是最近些年的事情,但其每一个发展过程都没有少,智能导购系统的进程经历了单机,多用户,局域网,互联网等几个发展时期,由小型的单机系统发展成为如今的产品采、编,合理检索综合管理的系统,并逐步实现网络化,现代化。从整体上来看,国内的大型购物系统网站如淘宝商城、当当网、京东商城、
易购商品、酷八商城等都是比较成功的案例,但是这些商店都是根据自己的网店进行内部研发,各个网店之间没有关联。因此,消费者为了购买某一种商品,需要同时登录几家网站进行商品的搜取和对比,然后再决定要购买哪家的商品,这样给消费者的网上购物增加了负担。
另外,已有的系统在各个相关的领域取得了一定成果,而对于如何平衡实时性以及推荐质量仍然缺少较合理的办法。通常情况下,推荐技术在实时性和质量保证方面是不能两全的,通常都忽视了质量问题。实时的进行推荐服务,也同时做到推荐质量得到保障,这是亟需解决的,也是极有研究价值的。
1.3 主要思路及主要内容
1.研究思路为了解决当前网上购物系统相分离的问题,为用户网上购物提供一个统一的平台,设计和开发了一种网上智能导购系统,它将现有的网上商城的商品信息进行搜取和整理,为用户提供了一个统一的平台,用户可以在此平台上搜索各个网上商城中的商品信息,然后进行比较购买。本问所设计的智能导购系统主要集中在智能分类与周期性排行、智能搜索、智能推荐三个方面。其中智能分类和智能搜索为消费者在线进行商品浏览和查询提供了方便,便于消费者轻松的查询和定位到个人所需要的商品上;周期性排行和智能推荐是根据商品的销量或用户的购买倾向及购买种类,系统自动向用户推荐商品,来满足消费者的需求,既为消费者提供了方便,也有益于提高商品的销售量[8]。
2.研究内容
本文研究了智能导购系统,在对 Web 数据挖掘技术和推荐系统的研究的基础上,设计和实现了一种网上购物的智能导购系统。本文所涉及的主要内容包括:
(1)通过对导购系统的全面阐述,分析了目前智能导购发展的现状和不足,为自己的研究工作划定了问题域范围;
(2)调研目前国内外现行推荐算法,在智能导购系统中主要加入以消费者以商品为基础的推荐协同过滤的推荐算法,建立相应的推荐模型,分别实现了推荐系统中消费者偏好分析和商品关联规则两个关键功能;
(3)在理论研究的基础上,采用 Java 技术、J2EE 平台和 MVC 模式,基于 Web 数据挖掘技术,对网上购物系统的可行性、系统需求、系统设计技术以及实现方法进行了深入分析,设计与开发了一个网上购物系统,并将其应用于网上图书的销售。
1.4 章节安排
本文组织结构为:
第一章绪论,本章对研究背景和意义进行阐述,调研国内外该研究方向的发展现状,同时也详细的描述论文思路和内容;重点叙述实际问题、项目背景、项目必要性、要解决的关键问题。
第二章相关知识,对本文所使用的相关知识进行了介绍,包括智能导购系统、Web 数据挖掘和实现本系统所需要的 J2EE 技术等。
第三章以数据挖掘为基础的推荐系统,本章主要研究内容包括就智能导购系统相关挖掘技术和推荐算法。为了实现网上购物系统的智能化,本章提出两种智能系统推荐算法:基于消费者的推荐算法和基于商品的推荐算法。
第四章设计智能导购系统,本章主要设计系统的模型,确定系统总体框架,然后详细介绍了系统的功能模块及各个子模块的设计,最后对系统所用到的数据库进行了设计,包括普通数据表和 Web 日志数据表两种。
第五章智能导购系统的实现,本章采用 J2EE 技术在系统模型设计的基础上对其进行了实现,对系统所涉及到的关键功能模块及挖掘算法进行了介绍。
总结与展望对本文所完成的工作进行了归纳和总结,并讨论了下一步的重点工作方向。
第二章相关知识
2.1 Web 数据挖掘
2.1.1 Web 数据挖掘概念
所谓的 Web 数据挖掘实质上是提取 Web 文档及活动内的具有隐含性以及有价值信息及数据。应用数据挖掘过程中,主要是结合 Web 技术共同进行的,实现 Web 应用,因此,就 Web 数据挖掘而言,其定义同数据挖掘的类似。然而类比后差异还是较大的。
对于数据挖掘技术而言,其发展特别 Web 相关的技术都极大的支持了智能推荐技术。该技术很大程度的解决了有效收集隐式数据的目的,同时,对于内容以及协同的过滤都是能很好的支持的。该技术的功能表现在,一方面利用分析用户访问模式类似程度的方法对基于访问模式用户进行分组,同时也能实现支持协同过滤技术目的;另一方面,分析页面内容类似程度的方法对页面内容进行分组,同时也能支持以内容为基础的过滤技术[9]。而对应用 Web 数据挖掘对相关信息能够有效的获取。因此,该技术在保证用户信息的准确性的同时,使用户得到的智能推荐服务是高质量及可靠的。
2.1.2 Web 数据挖掘的分类
对于 Web 站点,其的数据包括了内容、结构以及使用三种数据。由于挖掘数据存在差异性,因此 Web 挖掘也包括了 Web 的内容、结构以及使用三种数据挖掘,具体如图 2-1。
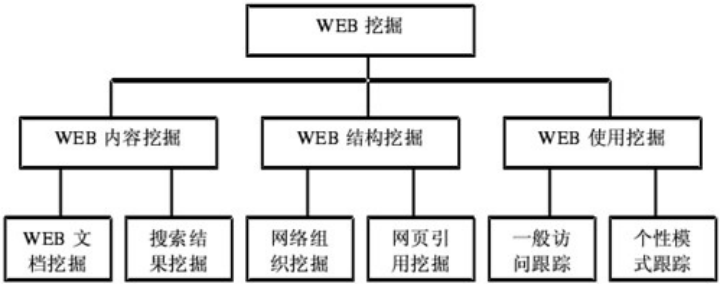
图 2-1 Web 挖掘分类
1.Web 内容挖掘(WebContentMining)
Web 内容挖掘的对象为 Web 页面内容[10],具体为:
(1)实现 WWW 中信息提取的搜索引擎,包括 WebCrawler 等在内。
(2)Web 页面具有分析半结构化特征,功能是提取 HTML 或者是 XML 页面的信息。
(3)挖掘出 HTML 或者是 XML 页面有用的内容,同时进行页面的相关文本挖掘,而信息挖掘的对象则是针对多媒体信息的。主要有确定页面内容中的摘要、聚类、分类和关联规则等部分。
2.Web 结构挖掘
Web 结构挖掘的挖掘对象为 Web 页面与页面间结构,其中典型的包括 Web 页面与页面存在的关联即超级链接[11]。对于完全 Web 空间而言,其有效信息和知识在 Web 页面的内容及结构中都存在。对于挖掘所获取的知识,能够给搜索引擎或者是站点结构等的改进和完善提供依据。
3.Web 使用挖掘(Web Usage Mining)
Web 使用挖掘的挖掘对象为用户访问 Web 时留在服务器下,有其保存的访问记录,也就是挖掘存取方式。服务器中挖掘的也将服务器日志文件等包括在内。而该挖掘过程由数据清理,事务识别以及模式生成组成。通过挖掘能够生成的主要包括路径模式、分类、关联和序列规则以及聚类等等[12]。
2.1.3 Web 使用挖掘的过程
对于 Web 使用挖掘而言,其主要过程由数据预处理,模式挖掘,模式分析和应用三部分组成[13]。如图 2-2:
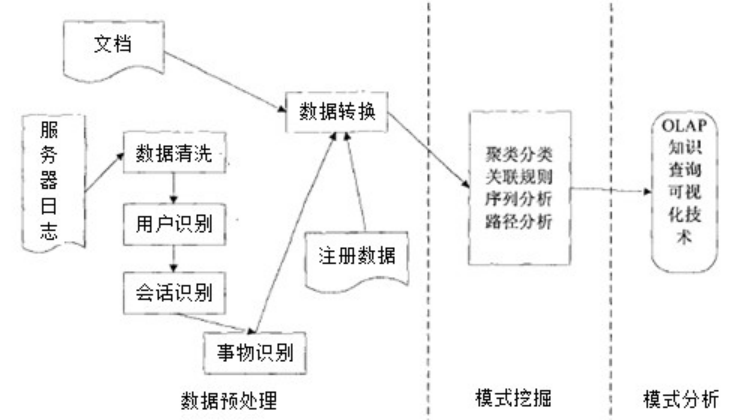
图 2-2 Web 使用挖掘流程
1.数据预处理阶段
该阶段主要是对 Web 日志文件进行处理。但是,Web 日志提供的数据存在不准确和不确定性,同时其格式也有可能为半结构化,此外缓存、防火墙以及代理等都会导致挖掘到的数据不可靠。因此,预处理 Web 日志文件很有必要,经过处理的数据格式满足挖掘需要,同时也便于存储和核对。通常的预处理有数据清理、会话以及用户的识别等等。
2.模式挖掘阶段该阶段实现了用户访问规律的判断和归纳,主要是通过数据挖掘技术实现
的,通过对规律的分析和判断,能够准确的掌握用户购物倾向以及兴趣点,也就奠定了用户个性化服务的基石,从而使实现了网站用户的访问体验的改善[14-15]。其中算法主要包括:
(1)统计分析所谓的统计分析实际上是结合定量好定性的综合分析方法,其主要用到的方
法为统计和分析对象相关知识等。采取对 Web 服务器内相关的 Web 日志文件进行分析,因此实现了 Web 用户行为利用统计分析获取准确统计的描述,同时,对用户在页面上的时间等详细信息均能进行统计。
(2)关联规则的发现
该规则最早是在 1993 年的 SIGMOD 会议由 Agrawal,Swami and Imielinski 公布的。在用户数据库挖掘过程中,该方法主要应用于项目间存在的关联规则的获取。对于 Web 使用挖掘过程而言,此技术进行发掘时,忽略了页面和页面被访问顺序,即非序列关系。通常关联规则的挖掘过程应用了 Apriori 算法。
(3)聚类所谓的聚类是对样本进行类别的归类,分类原则是相似性,且分类过程中要
保证同类个体间距最小,不同的类个体间距最大。该操作过程中,区分类是未知的,产生类实质上是提供了无指导学习的方法,数据驱动主要形式,此处有别于分类。利用聚类针对用户访问日志提取相似用户的访问兴趣的功能。
(4)分类分类即把数据进行映射至已预先规定类中。因网站经营者需要对访问者分类
和特征进行获取,因此,有必要进行相关属性的抽取和抉择,主要是对访问者不同类别实现描述。
(5)序列挖掘
序列挖掘也叫做序列模式挖掘,其研发人为 Agrawal 及 srikant,实质上为由序列数据库中发掘出潜在的序列的模式。其最早是希望通过分析数据库,得到相关用户购买物品时间规律,从而对购买相关的项目信息进行计算,从而实现对其间购买规律的统计。
3.模式分析及应用阶段
对于 Web 使用挖掘而言,该阶段实质为最后的阶段,主要实现了对使用模式挖掘规则以及模式等的分析,从而将有用及有意义规律及模式进行提取。该阶段上一阶段对数据库中不感兴趣和无关数据和模式筛选内容进行收集。
2.1.4 数据挖掘常用算法
2.1.4.1 k-means 聚类算法
k-means 聚类算法具有简洁化以及有效性。利用 k-means 聚类算法实现整个用户空间的聚类步骤为: [16]。
(1)初始簇中心是随机进行选择的,其数目主要是 k 个,而对应的起始聚类中心则是这 k 个用户相应项评分数据。
(2)针对选择剩下的用户进行集合,对各用户以及聚类中心所具有的相似性进行计算,然后实现各用户的分配,主要原则是归到相似性最高中。
(3)而新产生聚类,则要进行其中的全部有用户项平均评分的计算,从而得到新聚类的中心。
(4)对 2 到 3 进行重复,聚类不改变停止。聚类产生后,以聚类协同过滤推荐算法为基础,主要的步骤包括[17]:
(1)虚拟用户集生成:因各不相同聚类产生不同的聚类的中心,此中心和对应其他用户距离和的值为最小值,各聚类对应聚类中心实质上说明了其中用户针对商品进行的典型评分。而全部聚类中心实质上是集合了虚拟用户。
(2)推荐产生:对虚拟用户进行集合,主要采取利用各相似性度量途径对用户相邻用户进行搜索,最后,推荐结果的获取则是依靠最近用户针对不同商品评分信息获取的。
2.1.4.2 关联规则挖掘算法
该算法实际上是针对大型的数据集中而言的,主要是在其中发掘出有趣关联或者相关的关联,也就是针对数据集中对常有的属性集进行识别,最后,根据频繁项集对关联关系的规则进行创建[18]。
假设存在一事务数据库 D,其组成包括多个事务记录,用 I={i1,i2,…,in}物品集来表征所有项目,而对于 D 而言,其中各记录 T 均为对应 I 中的子集,也就是存在 T∈D 以及 T ≤I 的关系,若 T 内包含 X ≤I 也就说明了 T 能对项目 X 进行支持。
通常情况下的关联规则形式也包括了:
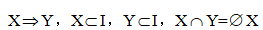 , X 和 Y 分别代表规则前项及后项的项集,分别简称为前项和后项。此规则表明对于事务数据而言,若出现任一记录中有 X,则也也就增加了包含 Y 的可能。对于
, X 和 Y 分别代表规则前项及后项的项集,分别简称为前项和后项。此规则表明对于事务数据而言,若出现任一记录中有 X,则也也就增加了包含 Y 的可能。对于
 的关联规则而言,其信任度对应是 c%,说明对于事务数据库 D 而言,其中支持 X 的同时也对 Y 实现支持的为 c%;对于
的关联规则而言,其信任度对应是 c%,说明对于事务数据库 D 而言,其中支持 X 的同时也对 Y 实现支持的为 c%;对于
 关联规则而言,其中的支持度则是 s%,也就说明了 D 中存在 s% 的是对 X 和 Y 都支持的,也就是说同时含 X 及 Y 的事务概率[19]。其中 s、c 表示见公式(2-1)和(2-2):
关联规则而言,其中的支持度则是 s%,也就说明了 D 中存在 s% 的是对 X 和 Y 都支持的,也就是说同时含 X 及 Y 的事务概率[19]。其中 s、c 表示见公式(2-1)和(2-2):

一般情况下,感兴趣的范围主要是针对某些支持度及可信度关联规则实现。要找到具有价值的关联规则,则假设两闲值是有必要的,主要包括最小支持度及最小可信度,前者是确定关联规则需要满足的最小支持度,后者则是必须满足的最小的可信度。而挖掘关联规则则是为了确定其中能够对最小支持度以及最小信任度都满足的全部的规则[20]。
若事务数据库 D 中支持物品集 X 的程度比最小支持度要大,那么这个物品集
X 就是高频的。对于关联规则挖掘而言,其问题包括[21]:
1、对事务数据库 D 内全部比最小支持度要大的用户实现确定。其中,最大项目集实质上是能够包含最小支持度的。而所谓的项目集支持度实际上为 D 中所具有的此类项目集个数。
2、通过最大项目集得到相应的有用关联规则。确定各最大项目集 A 的全部非空子集 a。若出现比率 support(A)/Support(a)>minconf 的情况,则产生的关联规则为 a(A-a),其确信度则由 support(A)/support(a)表征。
利用关联规则挖掘的技术能够实现针对不相同的商品相关特性规律的掌握,对于智能导购系统,该技术也得到了认可而很常用。以关联规则推荐算法为基础,以生成关联规则为指导确定推荐的模型,同时也掌握用户购买行为,对用户实现推荐。
2.2 基于数据挖掘的推荐算法
2.2.1 推荐算法概述
对于智能推荐算法而言,其主要功能是利用数据挖掘技术分析各用户数据,特别针对用户访问数据,从而掌握用户兴趣以及构建出购买行为的模型。以数据挖掘技术为基础的电子商务推荐算法通常应用阶段包括了学习及应用两个阶段,前一阶段,对于数据挖掘系统而言,分析相关数据的同时,构建出相关推荐的模型,该模型主要对用户行为模式进行解释;后一阶段,推荐算法以上述推荐模型及用户行为能够为用户提供实性的推荐的服务。对于部分电子商务推荐算法而言,是不存在离线情况构建推荐模型学习这一环节的,而推荐行为实际上在现阶段就已经实时完成,若出现同一阶段对电子商务系统进行访问的用户数量十分庞大的情况,实时性的推荐系统就很难实现了[22]。
通常可以将电子商务推荐算法分成以内存为基础以及以模型为基础的推荐算法:
(1)前者运行过程中,主要是把全部用户数据库调到内存中,所以,推荐同样也能够通过最新用户数据获取。
(2)后者中,第一步是以用户数据为基础进行模型的构建,算法运行过程中调整到内存中的是模型。对于较大规模的电子商务系统而言,用户数据库实际上十分的大,因此,对于全部用户数据库进行推荐行为的生成时间成本较高,因此,全部电子商务推荐系统很难实现实时性,也就给该算法提出了很大的挑战。
该算法中的模型比原始数据集小很多,所以,对于推荐算法实时性能够很好的缓解。而模型同样和原始用户数据相比是较滞后的,因此要使模型有效得到保证,那模型的周期性更新是很必要的。要找到有效的平衡推荐系统的实时性及推荐质量,本文主要是通过以模型为基础的推荐算法实现。
2.2.2 协同过滤推荐算法
该算法对整个用户空间进行划分,划分原则是用户购买喜好以及评分,划分得到的聚类的内部用户在项评分方面保持相似,但各聚类间用户在商品评分方面则需要存在一定的差别。同时以各聚类用户针对各商品进行评分而得到虚拟的用户,该用户说明聚类内包含的用户是典型评分的,把全部的虚拟用户针对各商品进行的评分当做是新搜索的空间,对现行虚拟用户目前的最近用户实现查询,得到推荐的结果。类比原始用户和虚拟用户的空间,后者很大程度的小于前者,所以,最近用户的查询效率相应就要高很多,因此,对于推荐算法在实时性的响应速度方面,能够得到很大的提升[23]。
2.2.3 关联规则推荐算法
该算法运行阶段主要包括了离线的关联规则推荐模型构建和在线的应用两个阶段。前者主要是对各关联规则挖掘算法进行推荐模型的构建,该阶段时间成本较高,而离线时也能实现运行是其优点;对于后一阶段,主要是为用户提供具有实时性的推荐的服务,该服务主要是以推荐模型及用户购买行为为基础[24]。
关联规则推荐算法的应用能够得到 top-N 推荐的算法,主要步骤为:
1)事物数据库的建立,其中的数据主要是交易数据库记录的各用户购买历史交易的数据。
2)挖掘关联规则时,主要利用了各关联规则挖掘算法,对最小支持度阈值进行满足,同时也要满足最小置信度阈值,将全部符合条件的关联规则记为集合 R。
3)针对于各当前用户 u 设定相应的候选的推荐集 Pu,同时将此推荐集假设是空集。
4)针对各当前的用户 u,进行关联规则集合 R 的搜集,确定此用户所支持全部关联规则集合用 RI 表示,也就是对于关联规则而言,其左边商品是用户 U 的购买数据及记录的一部分。
5)对于关联规则而言,将其集合 RI 的右边全部商品列入到候选的推荐集 Pu 中。
6)删除候选推荐集 Pu 用户经购买记录。
7)以关联规则集合 RI 置信度为基础,排列候选推荐集 Pu 内全部候选项,若各项针对各条关联规则都会出现,那么排列标准则是选取置信度最高的情况。
8)推荐结果的确定则是以候选推荐集 Pu 内 N 个置信度最高,同时将该结果返回给用户 u。
2.3 J2EE 技术
2.3.1 J2EE 体系结构
目前,J2EE 在较大规模的网络应用系统中广泛的用于软件系统平台,其主要是能够支持网络系统中的多层分布式结构。对于 J2EE 体系结构而言,其实际上包括了客户层、应用层、表示层以及数据层,如图 2-3。该结构实现了网络应用程序的较清楚的划分,主要包括表示层、数据层和应用层。

图 2-3 J2EE 体系结构
(1)客户层客户层的主要功能是实现在网络程序中,能够有效合理的处理客户表示以及用户界面的问题。对于客户层用户而言,能够依靠个人计算机、无线移动设备以及网络设备等实现交互网络应用系统。
(2)表示层
该层也是 Web 层,其主要组成是 Web 容器,主要功能是对瘦客户的 HTTP 请求以及响应进行处理。对于 Web 容器而言,其所包含的技术包括了 Servlet 以及 JSP。两种技术对客户端的请求能够协同完成,同时,对应用层接收到的请求也能实现有效处理,之后能够创建出动态情况,并将客户端对应的页面内容实现返回。
(3)应用层
对于 J2EE 平台而言,其应用层的主要组成部分包括 Enterprise Java Bean s 容器。EJB 实质上为封装的应用逻辑,同时该软件组件也能够实现其运行在 EJB 容器上服务器端上。EJB 的职能是能够实现对客户端请求的处理,同时,对请求进行处理的时候能够对数据层进行访问。EJB 包括会话、实体以及消息驱动三种类型。
(4)数据层数据层数据的主要组成有数据库、事务处理信息以及企业资源规划等内容。要实现数据层标准以及可移植访问提供则主要要依靠 J2EE 的 Java 数据库连接以及连接器完成。对于数据层而言,其中运行组件要成功的存取分布式数据则主要利用 CORBA 或 Java 连接器以及其他的资源通信完成。
2.3.2 MVC 设计模式
MVC 模式,即模型-视图-控制器(Model-View-Controller,MVC),它是可以满足那些需要为同样的数据提供多个视图的应用程序的开发需要,在开发与用户界面相关,特别是对用户界面要求较复杂的相关的应用程序时,可以很好地以不同的方式来显示同一数据,也就是在不改变软件功能的前提下,可以实现用户对用户界面的个性化要求,而且 MVC 模式的最大特点就是将业务层与表示层分离,而且提供了很多使显示界面更加个性化的标签库,所以它能更好地实现用户界面的各种个性化需求。它的三个核心部件分别是模型、视图和控制器,它们各自处理各自的任务[25]:
(1)模型封装了应用问题的核心数据、逻辑关系和业务规则,提供了完成问题处理的操作过程。一方面,模型被控制器所调用;另一方面,模型还为视图获取显示数据提供了相应的访问其数据的操作。
(2)视图是应用程序的用户界面,实现模块的外观,它是应用程序的外观表现。它可以访问模型(model)的数据,却不必了解模型的具体情况,同时它也不需要去了解控制器的具体情况,它只是作为用户输入数据并进行操作的方式和界面。
(3)控制器根据用户的输入调用相应的模型和视图去完成用户的需求和相关的操作。控制器本身不输出任何东西和做出任何处理。它只是接收客户的请求并进一步决定调用哪个模型构件去处理该请求,并根据处理结果来确定用哪个视图来显示模型处理之后返回的数据。它们三者之间的关系如图 2-4 所示。

图 2-4 MVC 组件类型的关系和功能
2.4 本章小结
本章对本文所涉及到的基本理论进行了详细的介绍和总结,包括智能导购系统、Web 数据挖掘和 J2EE 技术,为后面章节的工作奠定了基础。首先介绍了智能导购系统的概念、特点、目标及主要步骤;然后对 Web 数据挖掘进行了介绍,对其概念及常用技术和挖掘过程进行了详细的说明,最后 J2EE 体系结构和 MVC 设计模式等相关内容进行了介绍。
第三章智能导购系统需求分析
3.1 智能导购系统概述
智能导购系统的英文为 Intelligence Guide。其在学术界的定义为,该系统是以 Web 平台为基础的智能化的导购系统,基于客户需求,从而实现系统对用户的喜好以及倾向以及存在的人机交互的模拟及识别,系统利用某些后台智能算法对客户智能化进行掌握,主要内容包括思维方式、生理特征以及喜好特点,同时基于此对客户身份自动选购进行模拟,同时将此向前台进行推荐,最终也就得到了导购服务的智能化[26]。
智能导购系统主要是以用户喜好以及习惯通过系统对其进行信息及商品的推荐的程序,其实现了和用户间直接的交互行为,对销售人员推销商品进行了模拟,满足顾客需求的同时,也确保了交易的顺利进行。基于用户角度,该系统实现浏览信息的挖掘,主要是利用针对用户访问行为、频度以及内容等进行提取的方法,同时实现对用户特征以及访问的 Web 模式的提取,此外对页面结构也实现
了动态调整,从而实现了用户的主动推荐使服务实现了个性化;而企业角度出发,企业有很强的愿望掌握用户 z 访 kq 问的 2 规 01 律 51,1 从 25 而能够对顾客消费生命周期进行确定,对于各产品能够确定合理营销的策略,从而能够对网站组织结构以及服务方式进行优化,从而使网站效率的到提升。对于智能导购系统而言,方便客户也使商务活动更能满足消费者,也就能够实现商务网站的顺利发展。
通常智能导购系统将要解决的问题包括:帮助客户筛选有效的产品信息,从而能够购到满意商品;在筛选出的商品中,根据顾客的喜好以及倾向,为顾客找到中意产品;以客户购买历史模拟出顾客的购物行为及偏好。网上智能导购系统和传统的系统差别很大,同时与其他的营销手段也是不尽相同的。其中网上只能导购系统特点主要有[27]:
1.智能性对于网上智能导购系统而言,其包括学习功能,其根据用户对系统的使用,实现用户特征的学习,同时,由用户特点对活动规律进行变更,从而能够对用户的特征进行适应,其中系统能对客户浏览的痕迹进行自动的记录,能够实现历史的查询,从而产生的页面具有独特性,且包括用户使用特点。
2.自主性该系统向消费者进行服务的时候采取自主的方式,实现此服务所应用的程序也是先设定好的,以消费者行为的研究理论为基础,能够满足普通消费者购买特点,对软件条件进行预先的设置,凡是能符合条件的,软件进行服务的提供都是自主的,同时,也希望能够对消费者的要求进行最大程度的满足。例如其中的自动的页面跳转以及电子名片的网站导购系统( TraCQ)提供服务过程中均是自主实现的。
3.交互性对于网上智能导购系统而言,能够和消费者有效的产生互动的行为,对消费者的行为及时的响应,有效的进行交流,其中动态的进行互动都能极大的使网络营销效益得到提升。其中部分的动态网页技术能够实现嵌入聊天工具的功能,消费者能够通过该工具和卖家进行沟通,也就和面对面交流是一样效果的。
4.整体性通常情况下,存在众多的智能导购工具,而网上智能导购系统在组成要素的确定中主要是以网上商店消费群体特点为基础的,而各要素之间的关系则是相互影响及配合的,同时对消费者进行服务的提供时是看作整体的。导购工具的使用过程中,对消费者而言,仅能满足部分的要求,当各工具结合才能对消费者需求进行满足,这即购买流程的全部的服务。
3.2 智能导购系统设计目标
通常智能导购系统对于电子商务活动起到的功能包括[28]:
1.把浏览者转变成购买者
对于客户而言,当其存在较为确定的目标时,通过搜索便能够找到中意的商品,而通常顾客均为漫无目的的冲浪者,也可以说是没有明确需求的购买者,其对于较长的商品目录是没有耐心进行挑选的。通过推荐系统便能够采取较合理的推荐措施,实现浏览者和购买者身份的转变。
2.增加交叉销售量
推荐系统利用给客户推荐一定的商品,从而实现了站点企业能够实现销售量的交叉提升。如站点能够参考客户购物车为其推荐相关商品。若推荐系统较完善,则更容易实提升企业平均定购量。
3.个性化的服务
个性化服务实质为用户浏览 Web 站点过程中能够得到较满意的浏览效果的调整和变动,对其兴趣能很好的适应的同时,也能够让其感受到顾客至上的感受。通常较成功推荐系统也就实现了对各顾客都提供一个购物的场所—商店,网站不是固定的应随客户特点完成调整。
4.提高客户忠诚度
提供个性化服务能拉起商家及顾客间稳固的纽带,顾客应用推荐系统越多,推荐系统在满足顾客需求方面就越准确,能够吸引顾客的效果也就越好,这样便能更有效的构建牢靠的关联。这样就能建立牢固的顾客群,也使得用户不至于流失。
3.3 智能导购系统主要步骤
通常对智能化电子系统进行实现,主要要经过信息采集及分析与智能化服务环节[29]:
1.信息收集
智能化服务的提供是基于客户个人信息收集的。通常收集的主要方法包括注册和网络行为。前者,则是在顾客进行注册时得到性别、学历、出生、收入以及职业等等;后者,则是通过其在网上的行为对其爱好进行判断,然后得到相关的信息。若客户对某种商品或者是广告较高频率的浏览,则可以获取其去此类产品的购买倾向。
2.信息分析
通常情况下,家电产品电子商城若具有较完善智能导购系统,则能够实现对客户的透明,分析客户资料以及行为,同时,对客户在页面处理时间做到影响最小,分析时间成本较高,分类处理过程中,则处理时应为系统空闲和客户退出时,从而有效节约客户的时间。对信息进行分析主要包括:
(1)对网站客户群实现有效的分类,设定内容主要是以客户群兴趣特点为基础,同时实现内容的归类;
(2)对客户类别相应内容进行分类,也就是针对各客户确定其所需内容;
(3)对消费者的行为及登录进行分析,同时对其客户所属类别进行判定;
(4)当客户在浏览网站的不同页面过程中,同时也在进行购买定单提交过程中,能对有关行为资料进行修正。
3.智能化服务
以客户类别为依据向客户显示对应有关内容,从而实现智能化导购。要保证分类可信及稳定,抽样时,最先是以注册时间长,浏览和购买都比较稳定的进行。
3.4 系统功能分析
3.4.1 系统功能概述
网上智能导购系统为用户在网上选购提供支持,对在该系统中注册过的网上商店搜索,找出满足用户需要的商品,根据系统要完成的任务,可以将系统分为前台处理和后台处理两部分。
前台功能主要为客户提供各种操作,来实现客户与系统之间的交互,包括消费者用户注册、登录、商品搜索和购买等,企业用户的在线注册、发布商品信息等。
后台管理主要有系统管理员的维护操作和系统的后台的智能挖掘处理等。其中管理员信息维护包括对消费者、企业的注册信息的维护和搜集的商品信息的维护,后台智能挖掘主要包括系统对商品信息的搜索、智能推荐等。
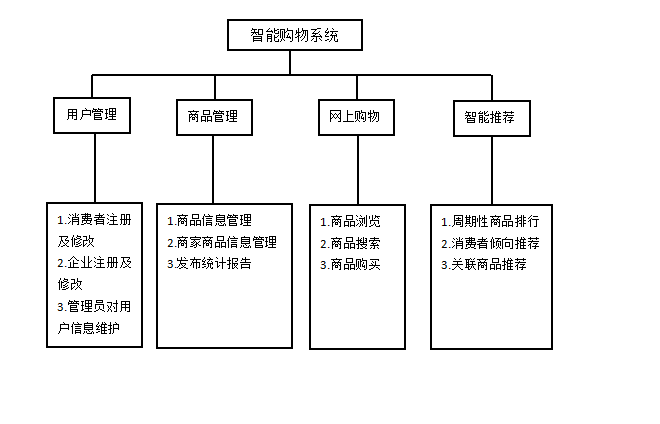
根据对系统需求的分析,可以将其功能分为如图 3-1 所示的模块。
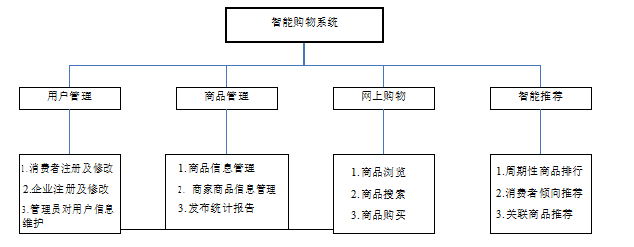
图 3-1 系统功能结构图
3.4.2 功能模块描述
(1)用户管理模块:该模块主要包括消费者、企业和管理员三类用户的操作。
消费者用户主要是在系统中进行注册,描述自己个人倾向信息等。企业用户指各个网上商店在该系统中进行注册,在系统中存储网店信息,以便于系统对该网站进行查询,来搜取商品销售信息。系统管理员用户主要对消费者用户和企业用户进行管理、维护。
(2)商品管理模块:主要对商品的信息进行存储和管理,包括商品本身的信息和商家的信息等。
商品信息管理是对商品本身的信息进行管理,包括商品的名称、定价、类别和产地等。商家商品信息主要用来对从各个注册网上商店所出售的商品信息进行存储和管理,如出售该商品的商家站点、网址及出售价格等。发布统计报告是系统定期的对商品的信息进行统计和分析,为系统提供决策提供数据。
(3)网上购物模块:网上购物是系统的核心,用来完成消费者与系统之间的交互,消费者通过网上购物来选取和购买所需要的商品。该模块分三个关键功能:商品浏览、商品搜索和商品购买。
商品浏览是指系统会将近期热销的商品在系统的首页进行展示,以便用户的查找,并对定期的对热销商品进行更新,做到实时性。商品搜索是指消费者可以通过系统的搜索引擎与系统进行交互,向系统提交自己的需求,系统通过搜索分析来返回用户所需要的商品信息,来供用户进行选择。商品购买主要是指当消费者查询到了所需要的商品,将其添加到购物车中,系统通过代理来向商家进行下订单。
(4)智能推荐模块:智能推荐是该系统的另一个关键功能,它主要是根据商品的销售情况或根据消费者的购买倾向实时向用户进行商品推荐,主要有周期性商品排行和实时商品推荐两个功能。
周期性商品排行是指系统根据近期商品的销售情况及清单来进行分析,将热销商品按照其销量进行排名,然后放到系统的首页,供消费者进行选购。实时推荐是指系统根据消费的购买情况及同类消费者的购买情况或商品的关联性,向消费者进行商品推荐,为实现实时推荐功能,本系统设计两种推荐策略:消费者倾向推荐和关联商品推荐。
3.5 本章小结
本章对智能导购系统进行了需求分析,首先对智能导购系统进行了概述,通过对现实的需求的分析,给出了智能导购系统的设计目标及实现步骤。在此基础上,对智能智能导购系统进行了详细分析,根据本文要实现的功能,设计了系统的各个功能模块。
第四章智能导购系统设计
4.1 系统整体框架设计
本文设计的导购系统由三个关键模块包括搜索、协同推荐以及购物三个模块。而搜索模块用来获取用户的购买需求,将用户需求传入智能导购系统,后台程序采用网页抽取技术来实现在各个网上商店进行商品搜索,获取用户所需的商品出售页面进行返回,然后对返回的结果进行筛选和排行。协同推荐模块主要是根据用户的购买偏好或相似用户的购买信息来对用户需求进行分析,自动推荐满足用户需求的商品,来供用户选择。购物模块用来选取顾客所需的商品,完成购物过程,主要包括顾客购买决定、购物车管理和电子付款三个阶段。各模块能够针对特定任务进行实现,各模块存在相互合作的关系,且能够实现智能导购目标的实现。
4.2 搜索模块设计
4.2.1 搜索模块流程
搜索引擎模块用来根据用户的需求搜索满足用户要求的商品,该过程首先根据在本地数据库中查找用户需求的商品,然后再利用网页抽取技术从互联网上访问各个网上商店网站,来获取满足条件的商品,最后所搜索到的商品信息及网店信息返回。具体的搜索流程如图 4-2 所示。
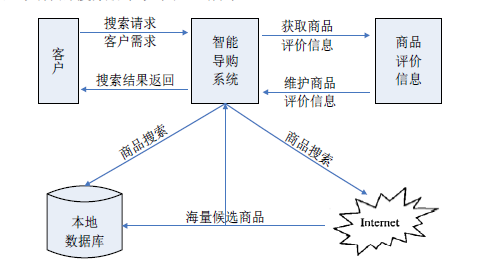
图 4-2 搜索模块工作流程
4.2.2 网页抽取设计
网页抽取模块用来从各个网上商店抽取商品销售信息页面,将抽出的页面存储到数据库中,分两个表进行存储:商品信息表和商品销售表。商品信息表用来存储商品的详细信息,包括商品类别、名称、描述等;商品销售表主要用来存储该商品在各个网站上的销售信息,包括商品所属网店、URL 地址、价格等。为了实现此功能,该系统的实现主要是利用网络爬虫技术完成的,对于近期商品信息,同时也根据需要实现其在数据库中的保存[30]。
图 4-3 给出了网页抽取的流程,可以分为以下步骤:
(1)对页面的内容进行获取。实现的蛀牙途径是,针对于信息源 URL 库以及查询关键字库而言,对其中的项的构造查询表达式实现了有效的读取,请求发至服务器中,因此,能够获取服务器产生图书的信息页面。技术的角度出发,能够实现 Java 输入流,此外也能实现 HTTP 的处理类等。
(2)解析网页内容。解析过程主要是包括页面结构和内容两方面的解析。首先解析页面结构时,主要利用开源工具主要包括 HTML Parser 等,该工具实现目的的主要原理则是依靠实现 HTML 与 XML 间的转换,从而,能够实现原网页各段内容存在 XML 的标记,同时,利用 XML 标记对所要求的信息进行确定。而要有效的识别以及解析页面内容最核心的部分是实现正则的表达式,而信息模式则为其中的一种,这对于特定信息提取也起到了决定性的作用。正则表达式 API 主要是 Java 提供的,能够根据需求对内容进行匹配,同时对于匹配的准确性能够有效的进行判决,同时,根据制定规则对有价值的内容进行储存。
(3)将解析后的信息存储到数据库中。将抽取的数据与数据库中的数据进行比较,如果抽取出的信息在数据库中不存在或已发生改变,则将该信息保存或更新到数据库中。将抽取的信息分两部分进行存储,一是商品的信息,包括商品名称、产地、描述等,一是该网店对应信息,包括所属网店、商品的价格、网址等。
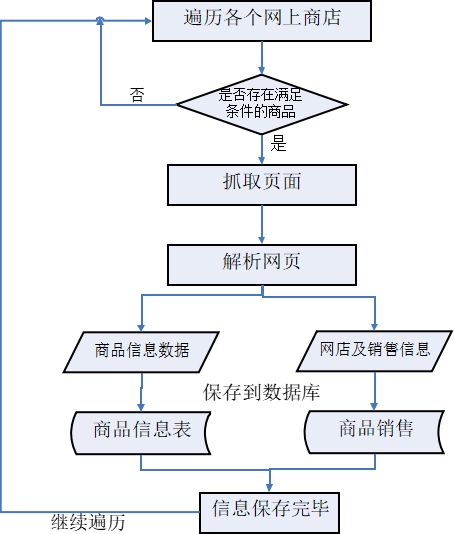
图 4-3 网页抽取流程图
4.2.3 搜索信息处理
网页抽取得到的数据需要进行处理,对其符合程度进行排序,然后返回给客户。当获取网页信息后,将商品信息和用户需求相一致的定性特征进行评分,接下来对各商品报价所对应的效用值进行计算主要是通过多属性决策方法实现的。 TOPSIS 主体的思路是要实现排序,主要利用的技术是依靠多属性决策问题,而主要是“理想解”及“负理想解”,从而对方案的好坏进行确定,若存在解的最接近的理想解,且与离负理想解较远,那么此解必是 m 个方案对应的最优的解。
以 TOPSIS 方法为基础,排列商品,主要以符合度为依据算法求解[31],具体公式是从(4-1)到(4-4)所示:
(1)对评价商品和顾客的定性需求指标进行确定,构建初始的决策矩阵 F.
详细说明该过程,首先是设定商家商品信息集为 X= {x1,x2,,xm},顾客的定性需求指标为 Y= {y1 , y2 ,, yn}。因此,对于初始矩阵包括 F = ( fij )mn,式中的 fij 是第 i 个商品第 j 个指标对应的评分值。
(2)规范决策矩阵 F,最终能够得到规范决策矩阵 F′= ( f′ij )mn,具体为:

(3 )规范化顾客定性需求向量 w = ( w 1 , w 2 ,..., w n ),得到规范需求向量
w '= ( w ', w ',..., w '),式中 w '实际为规范需求指标 j 权重。
(4)针对各候选商品 xi (1 i m)计算其理想解到负理想解间距离:

(5)对全部的候选商品 xi(1 i m)相应的效用值 Ui 进行计算:

(6)将商品按照效用值的大小进行排序,然后返回给用户,供其查看。
4.3 推荐模块设计
为了能够充分发挥网上智能导购系统的优势,为用户提供全面的商品信息,本系统子智能导购中加入系统推荐功能,该功能根据用户以往的购买倾向和商品关联规则来推荐与用户需求关联的商品,来满足用户的需求。
4.3.1 框架设计
在前面的叙述中提到了现有的推荐系统在实时性和推荐质量之间存在着不平衡的问题,现有的大部分系统在保证实时性要求的同时,是以牺牲推荐质量为代价的,为了解决此问题,本文设计了一种改进的系统模型。
为了解决此问题,本文采用协同过滤算法进行设计,将推荐模块的体系结构分两部分组成:离线模块和在线模块。离线模块由数据预处理和 Web 挖掘组成,在线模块由实时的推荐引擎组成[32]。
从图 4-4 可以看出,推荐系统在数据预处理阶段将数据进行预处理,主要步骤为数据的清洗及识别和会话识别。对于离线分析阶段而言,对数据是实现分析主要算法是以消费者以及商品的推荐为推荐的两协同的过滤推荐算法。通过推荐引擎模块对活动用户的信息进行获取,利用离线分析生成数据,从而能够对在线的商品推荐功能进行实现,同时,也利用推荐引擎对用户信息实现在线的获取,随后,以现行用户访问信息以及历史数据为基础,利用推荐算法实现商品的推荐。
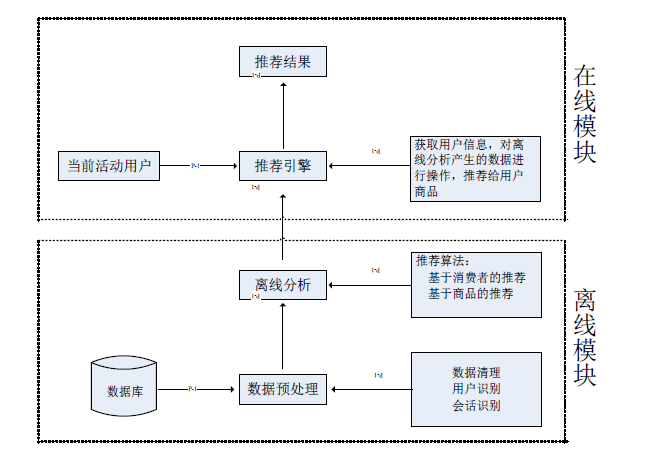
图 4-4 推荐系统结构
4.3.2 推荐流程
前面对推荐子系统的框架进行了设计,为了实现推荐功能,我们根据用户以往的购买倾向和商品关联规则来推荐与用户需求关联的商品,来满足用户的需求。图 4-5 给出了推荐流程。
可见整个导购流程,其中第一阶段,主要是利用对商务网站内消费者购物行为进行有效的追踪,基于此分析消费者的偏好;第二阶段,则是通过挖掘算法挖掘商品间关联规则,因此,能够实现对商品关联度的获取;第三阶段,是建立在上述阶段的基础上,实现推荐商品给消费者。
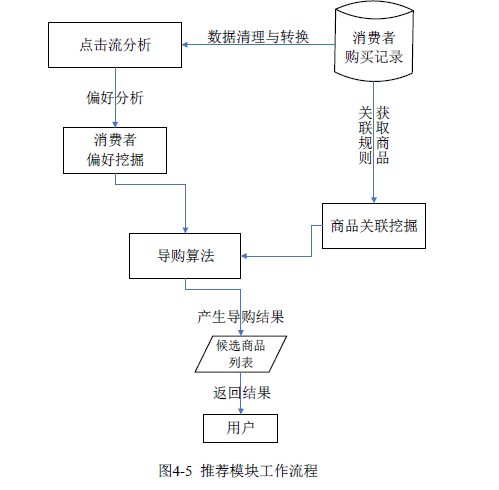
对于分析用户偏好过程中,应用的算法是以聚类为基础且协同过滤的,对于用户群而言,均能发掘各用户间存在类似的爱好以及行为,上述类似用户在购买物品方面对实现目前用户推荐物品可作为基础;对于商品关联推荐过程而言,要实现商品关联性的推荐主要用的技术是 Web 数据挖掘关联规则技术,主要是以商品属性和商品间关联性及客户偏好等信息为基础,从而实现推荐合理商品给购买者,也就是若物品 A 能实现购买,那物品 B 也就会一并卖出。
4.4 购物模块设计
4.4.1 购物处理流程
购物模块作为网上购物的最后一个阶段,主要实现顾客对搜索商品的选择,将其加入到购物车,然后执行网上支付的处理,来完成整个购物过程。具体处理流程如图 4-6 所示:

图 4-6 购物模块工作流程
顾客在搜索引擎返回的商品列表中选择满足自己需求的商品,将其加入到购物车,循环选择直到不再选购,结束选购过程;将购物车中的商品生成订单,在此过程中可以对订单进行修改和返回到购物车进行修改;在订单确定后,进入到支付界面,对所购买的商品进行付款,在付款结束后,整个购物过程结束。
4.4.2 购物子模块
根据购物处理流程,可以将该模块分为购物车管理、订单管理、付款管理等功能模块。
购物车管理:对于网购子系统而言,购物车作为其核心部分应当将商品检索和浏览以及会员的注册和登录进行结合,然后才能获得到网上订单。
订单管理:订单管理主要对顾客购买的商品生成订单,根据订单信息进行发货。顾客可以对订单进行修改,在修改完成之后进行订单确认,然后进入到结账付款界面。
付款管理:该功能的设计目标是将客户端通过网络与银行相连接,来完成网上支付过程,该过程的关键问题是保证交易各方的安全保密。
4.5 数据库设计
4.5.1 数据库建模
而数据库需求因其功能主要表现在提供、储存、查询以及更新信息等部分上,所以,由上述系统功能和业务逻辑模型对数据应用的需求隐含,因此能够对数据库结构进行完善。而数据库实体关系如图 4-7:

图 4-7 数据库实体关系图
4.5.2 数据表设计
(1)商品类型表商品类型表主要用来存储商品的类别,用来对商品进行分类,包括类型编号、名称和类别描述等信息。见表 4-1。
表 4-1 GoodsType(商品类型表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 类型编号 | int | 4 | 否 | 主键 |
| Name | 类型名称 | char | 50 | 否 | |
| Describe | 类型描述 | char | 200 | 是 |
(2)商品信息表商品信息表用来存储商品的信息,包括商品的编号、名称、价格、类别及产地。见表 4-2。
表 4-2 GoodsInfo(商品信息表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 商品编号 | Int | 4 | 否 | 主键 |
| Type | 商品类型 | Int | 4 | 否 | 外键 |
| Name | 商品名称 | Char | 20 | 否 | |
| Price | 价格 | Int | 8 | 是 | |
| Place | 产地 | Char | 30 | 是 |
(3)消费者信息表消费者信息表主要用来存储消费者的注册信息,包括顾客编号、名称、年龄、联系人、邮箱、行业、所在地址等。见表 4-3。
表 4-3 UserInfo(消费者信息表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 顾客编号 | char | 15 | 否 | 主键 |
| Name | 顾客名称 | char | 50 | 是 | |
| Sex | 性别 | char | 10 | 是 | |
| Age | 年龄 | char | 10 | 是 | |
| 邮箱 | char | 10 | 是 | ||
| WorkField | 行业 | char | 10 | 是 | |
| Address | 所在地址 | char | 10 | 是 |
(4)商家信息表商家信息表主要用来存储在该系统中注册的网上商店的商家信息,包括商店编号、商店名称、商店网址和商店描述等。见表 4-4。
表 4-4 ShopInfo(商家信息表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 商店编号 | char | 15 | 否 | 主键 |
| Name | 商店名称 | char | 50 | 是 | |
| URL | 商店网址 | char | 10 | 是 | |
| Describe | 商店描述 | char | 10 | 是 |
(5)商家商品信息表
商家商品信息表主要存储了各个商家关于商品的信息情况,包括商品的编号、所属网店、网页 URL、实时价格、库存量、销量和进货日期等。见表 4-5。
表 4-5 商家商品信息表 SalesInfo
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 商品编号 | int | 4 | 否 | 主键 |
| ShopId | 所属网店 | char | 50 | 是 | |
| URL | 页面 URL | char | 50 | 是 | |
| Price | 实时价格 | int | 8 | 是 | |
| Storage | 库存量 | int | 4 | 是 | |
| SaleNum | 销量 | int | 4 | 是 | |
| Date | 进货日期 | datetime | 8 | 是 |
(6)订单信息表主要存储了消费者的订单信息,包括订单编号、用户编号、下单日期、配送地址及订单状态等。见表 4-7。
表 4-7 Orders(订单信息表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 订单编号 | Int | 4 | 否 | 主键 |
| UserId | 用户编号 | Int | 4 | 否 | 外键 |
| OrderDate | 下单日期 | Datetime | 8 | 否 | |
| Address | 配送地址 | Char | 80 | 否 | |
| Status | 订单状态 | Bit | 1 | 否 |
(7)订单详细表订单详细表主要是对订单购买商品信息的详细记录,包括编号、订单编号、商品编号及购买商品数量等。见表 4-8。
表 4-8 OrderDetails(订单详细表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 编号 | int | 4 | 否 | 主键 |
| OrderId | 订单编号 | int | 4 | 否 | 外键 |
| ShopId | 商家编号 | int | 4 | 否 | |
| GoodsId | 商品编号 | int | 4 | 否 | |
| GoodsNum | 商品数量 | int | 4 | 否 |
(8)客户浏览分析表客户购买分析表主要对消费者的购买情况进行记录,以便于网站管理员进行统计、分析,为系统推荐提供依据,包括顾客编号、商品编号、访问站点、页面 URL、是否购买、访问日期等。见表 4-9。
表 4-9 TradeInfo(客户交易商品表)
| 字段名 | 字段描述 | 类型 | 长度 | 是否允许空 | 备注 |
|---|---|---|---|---|---|
| Id | 编号 | int | 4 | 否 | 主键 |
| UserId | 顾客编号 | int | 4 | 否 | 外键 |
| GoodsId | 商品编号 | Int | 4 | 否 | 外键 |
| ShopId | 商家编号 | Int | 4 | 否 | 外键 |
| URL | 页面 URL | char | 50 | 是 | |
| IsBuy | 是否购买 | int | 2 | 是 | |
| Comment | 商品评价 | char | 100 | 是 | |
| Date | 访问日期 | datetime | 4 | 是 |
4.5.3 数据表应用
本文所设计的智能导购系统主要将数据分为两类:商品的管理及购物数据、推荐处理所需要的数据,这两类数据相互交叉,存储在上一节所给出的八个数据表中。
商品的管理及购物数据主要包括商品信息的管理和订单信息的管理。其中 GoodsType 表和 GoodInfo 表存储了各类商品的具体信息,Orders 表和 OrderDetail 表存储了用户购买商品的订单信息,这两种表是网上购物系统的基本数据表,是网上购物系统的基础,传统的网上购物系统主要就是对这类表的维护。
本文设计的智能导购系统除了具有传统的网上浏览、购物之外,关键的是提供了智能推荐功能,为了实现该功能,需要对顾客以往购买信息的数据进行分析。SaleInfo 表中的 SaleNum 主要主要记录了该类商品的销量,为顾客购买该商品的期望度提供了依据,TradeInfo 表对消费者的网上浏览情况进行了记录,为消费者的购买倾向的分析提供了依据。Order 表主要记录了每一个顾客的一次购买商品的情况,为商品的关联度提供了依据。
4.6 本章小结
本章在前面工作的基础之上,给出了 Web 基于数据挖掘的智能导购系统的具体设计。首先给出了系统架构的整体设计,并给出了系统结构图,然后对分别对系统各功能模块进行了详细设计。最后对数据库进行了设计,给出了系统所用到的数据表之间的关系模型,并给出了各个数据表的逻辑结构。
第五章智能导购系统的实现
5.1 智能搜索模块的算法及实现
5.1.1 Crawler 网络爬虫
Waiter 是一个使用 Ruby 实现的开源的 Web 自动化框架,它小巧灵活,功能齐全。利用结合 Ruby 和 Watir 的办法,实现网络数据库的下载,主要是保存在本地数据库内,因此,用户能够在搜索商品时得到充足的信息。
Ruby 对 Web 数据库进行 Crawl,首先通过 Watir 获取 IE 对象;然后 Ruby 从本地数据库中读取出要进行数据抓取的产品名,通常购物网站以 Ruby 请求为基础,查询本地数据库,然后对结果进行返回处理[33];最终,Ruby 分析查询结果时主要依靠正则表达式完成,同时,对其中的有价值的信息进行提取,同时将其填入到数据库表内,其流程图如图 5-1 所示。

图 5-1 Ruby Crawler 过程
5.1.2 智能搜索实现算法
此算法实现过程中,关键类创建主要包括 Crawler 、 CrawlerWork 、 CrawlerInteral Workload、CrawlerSQLWorkload 以及 CrawlerDone 等 5 类,类,核心的接口包括 CrawlerReportable 以及 IworkloadStorable 的接口。
Crawler 类主要是能够对网络爬虫功能进行实现,也就是能够实现多线程抓取的以及监视与处理的网页,对新链接实现提取功能等。此外,其也能作为 Crawler 接口,同时对线程池进行管理主要是应用 Crawler 对象完成。
对于上述的分类均创建了各自对应的对象,其中,CrawlerWork 对象创建也为 CrawlerWork 的对象,处理过程进行 URL 的访问是必要的,若该对象是第一次进行启动,那么其首先是向 URL 提出请求处理。此对象同时能对 Crawler 对象中的 getWorkload()的办法进行调用,同时该方法将实现新 URL 的返回,且需要进行检查,若不存在正在等待中的 URL,那么,getWorkload()方法则对新任务进行候命[34]。
对于 CrawlerDone 类而言,其对现行线程个数需要实现精确跟踪。而对于 CrawlerSQLWorkload 类任务的结果主要是由 SQL 数据库进行储存。对于 IworkloadStorable 接口而言,其主要功能是实现 Crawler 在网页中的存入以及取出。
模块关键函数为:
``` publc cless Crowler extcnds Thrcad implcmemts ICrowlcrRepartohle { publiic Crowler( manogeurl, http polSizc );
public Crcwler( menageurl htlp pooSiize w );
privote Cravler( mamager, urrl, hitp wark pooSize w );
symchronizcd publiic vaid adWarklead( Sttring url );
synchranizcd publlic vold campletcPage( poge eror ) ;
synohronizod publlic Boalecn FottndImtenal_Limk( Sttringurrl ) ;
synohromizcd publlic Boalcan fonndExtternal_Limk( Sttringnrl ) ;
publlic imt gotMaxBady() ;
symchionised puhlic Boalecn gettRcmaveQucrry() ;
puhlic CrowlcrDame gotCrcwlcrDamne() ;
symcbranized puhlic SttringetWarklead() ;
puhlic Baolcan gotWadCrewlcr() ;
synahranizcd publlic vaid holt() ;
symcbronizcd puhlic vaid prrooesPage( HrPpoge ) ;
publlic vaid rum() ;
publlic vaid sctMaxBady( imt mx ) ;
puhlic vaid sctWorrldCrowler( boalcan b );
syncbramizcd publlic vaid CrravlerCamplette() ;
public Boalcan isHoltcdO ;
} ```
5.1.3 数据库处理算法
对于网络爬虫而言,主要应该的管理机制为利用以 SQLServer 数据库为基础的队列形式,则具备数据库的访问技术是必要的,对于 Java 而言,其能够给出访问数据库接口 JDBC[35]。
1)数据库建立
要实现对以 SQLServer 为基础的队列管理,主要是实现 SQLServer2005 内数据库 search 的构建,同时也要对表 tblworkloadl 以及表 tblworkload2 进行构建,同时对对应字段也实现合理设定。
2)Socket 连接的实现
构建连接,从而能够连接到客户端,主要应用的是 Java BOT 内的 HTTPSocket 类,代码为:
Try{
If(_URL.gotTextt().lenggth()>0){ HTTPSackct httlp = nev HTTPSackct(); http.scmnd(_URL.gotTextt(), nul);
}
}
这些代码主要实现对输入 URL 字段准确性的判定,之后就是对 HTTPSocket 对象的构建,对于 HTTPSocket 类而言,其实际上继承了 HTTP 类,此类主要是对利用 HTTP 对 Web 服务器进行连接的有效方法进行了实现。对于 HTTP 类而言, send()方法对 Web 服务器能提出检索请求,同时也实现了数据的发送。
3)SQLServer 的队列管理
对 SQL 队列管理要实现,则 Crawler 和数据库间连接的建立是有必要的,连接实现主要包括:
try {
Sttringdotasaurce = “jdbc: odhc: seoch”;
Sttring DriwerNone = “sunn.jdhc.odha.JdhoOdbcDrrivcf”;
Wll = ncw CrowllerSQLWorrklead(DrrivcrNome,
datosaurce,”uscr”,”pasward '’);
}
对于 CrawlerSQLWorkload 对象而言,其构造函数参数的内容包括了 DriverName、“user”、datasource 以及“password”,而 DriverName 实际代表了 JDBC 连接的驱动程序;datasource 即连接数据源;“user”及“password”以此是用户名及密码。要实现队列管理的方法,则 JDBC 连接构建是必要的。
对 CrawlerWork 对象中 run()方法进行运行中,对包含在 Crawler 类中的 getWorkload()方法进行了调用,确定 Crawler 对象对应的 URL 的目标,其中 getWorkload()方法进行执行具体为:
Symcbonizcd publiic Sttring gotWorklead() {
try {
For(;;) {
if (_hallted) returrn nul;
String v = _warklload.asignWorrkiood();
if (w != mull) returrn w;
walt();
}
}
Catch(jawa.1amg.IntemuptcdExoepriame) {}
return nul;
}
对于 getWorkload()方法而言,其关键程序主要为_workload 对象中的 asigm Worklead()的方法,对_workload 对象进行定义主要是:
prrotachtted warklleaddSttoroblre worrklead;
其间了接口定义为 IworkloadStorable 方法,其实现对要是由 CrawlerSQL Workload 类实现。此类定义为:
pubblic closs CrowlcrrSQLWarrklead inplenemts IwarkleadSttoreblle;
5.1.4 智能搜索页面实现
在本文设计的智能导购系统中,为了提高系统的效率,在离线时间对网页进行网页抽取,将返回结果存储到本地数据库中,以便用户进行查询。为了提供查询效果,对本地数据库进行实时更新。在智能搜索功能方面,根据关键字首先在本地数据库中进行搜索,如果没有搜索结果,则进行网络爬虫搜索,然后将搜索到的结果返回到用户和本地数据库。
用户点击搜索按钮,可以对商品进行快速搜索,也可对商品进行高级搜索。在高级搜索中,可以选择商品分类,根据类型进行搜索。
5.2 推荐模块的算法及实现
5.2.1 商品关联推荐
为了正确分析消费者偏好,本文采用的消费者偏好模型分为三个阶段:(1)首先是点击网页,说明消费者对其点击的商品有兴趣,通过点击则对商品 URL 地址进行链接,也就实现相关内容的查询。(2)将目标商品放入购物车中,消费者点击相应的产品受,说明其对相应商品实现了选购,然后将其放入购物车内,此商品则是候选品。(3)实现线上的购买,说明消费者类比购物车中的商品,然后对比较中意的产品实现交易,通过电子付款完成。
对于消费者而言,其实现购物后,系统对于其访问的地址就进行了记录,主要是在 Web 日志中储存,这样通过日志就能对消费者偏好进行模拟和获取。该系统对商品进行分组主要包括购买的,只加入购物车的,只点击点击查看的以及其它四种商品。根据各组商品以偏好为参考进行排序,偏好有小到大依次为未被用户点击的、仅被点击的、仅添加到购物车中的、实际购买。
对于商品关联推荐过程而言,主要是通过关联规则办法确定商品事务,同时对商品和商品关联实现集中。因消费者实现在线购物主要有三个环节,而要使获取的消费者购物倾向较准确,对 Web 日志内存储商品事务集合进行划分,主要是包括在线购买、购物车放置以及网页点击三个事务子集。对于商品关联分析阶段而言,针对上述的个子集,通过算法确定关联规则的集合,算法主要思想为:
算法:Produot-Asociattion-Minmg()
输入:从 Web 日志得到三个事务子集
输出:各事务子集商品关联的规则
方法:a.设定各事务子集的时间区间;b.对特定时间区间事务记录仅采集,同时对记录进行形式的转换,通常转换为
对于各事物子集中而言,得到其全部关联规则后,设定
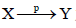 为在线购买事物子集内一关联规则,而 X 及 Y 以此为商品类型。相类似,
为在线购买事物子集内一关联规则,而 X 及 Y 以此为商品类型。相类似,
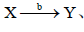 、
、
 依次为购物车放置以及网页点击的事务子集对应的关联的规则。
依次为购物车放置以及网页点击的事务子集对应的关联的规则。
对于全部各类型商品存在关联规则挖掘得到后,就能实现商品关联矩阵的构建,分析各类型商品关联度。商品关联的矩阵的定义是 P=(pij),i=1,…,N(表示商品类型的数量),j=1,…,N(表示商品类型数量),而:

上式中的矩阵元素 pij 是商品间关联度,对于公式(4-3)中,首个等式实际是同类非同个商品间存在的最大关联度,也就是消费者对某类型商品实现购买,其对于其他的商品可能会存在购买的倾向。第二个等式为购买事物子集内,商品间存在的关联度是 1,正是由于在线购买和购物车放置的阶段进行类比,商品关联度对消费者购买的倾向能够充分的进行体现。此外,类比购物车放置以及网页点击事物的子集,关联规则显示商品关联度处于较高值。
上述算法实现的流程图如下:

图 5-2 Produot-Asociattion-Minmg 算法的流程图
5.2.2 商品关联推荐算法实现
本设计用到的数据表为 Web 日志表,首先进行数据库连接:
``` Class.forName(“com.microsoft.jdbc.sqlserver.SQLServerDriver”);
//建立 JDBC-ODBC 桥连接
Connection con =DirverManager.getConnection(dbURL,username,userPwd);
//连接到数据库,提供相应的用户名和密码
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE);
```
2)位图矩阵的建立
在查询数据库的数据的基础上,建立位图矩阵。在此基础上创建各个购买单元项视图:
``` Create view distinct_trans as select distinct tranobject from TradeInf;然后各个事务内部的购买单元项:
create view all_trans as select tranid,MAX(tranobjects) tranobjects from (select tranid,WMSYS.WM_CONCAT(tranobject) OVER(PARTITION BY tranid ORDER BY tranobject) tranobjects from TradeInf) group by tranid;
```
3)频繁项集
在寻找频繁项集时,根据 Apriori 算法的要求,需要依次找出频繁项集。
``` Private NumberCount[] GetItem();//找出所有的一项集
Private NumberCount[] GetOneItem_t(float ComparePercent);//选出满足支持度的一项集
Private NumberCount[] GetTowItem_t(float ComparePercent);//选出满足支持度的二项集
```
4)关联规则在找到频繁项集后,我们设定一个置信度来获取一些有意义的数据,它的值越大,表示关联程度越高,调用如下方法来进行处理:
``` Private String GetTowItem(float ComparePercent, float Percent_G);
//在找关联规则时,我们调用了两个类的方法,一个是 Terms,主要实现按照需求的频繁项集个数去组合构成一个数组。 Class Terms {
Private int GetItemCount();
Private void GetTermArray(int tNumber);
Public int GetTerm();
}
```
另一个类是 Different,它的主要功能是找出符合要求的商品编号,在它们构成数组的时候,去掉它们之间的重复的项。
``` Class Different{
Public int[] GetDescNumbers(Numbers); Public int[] GetDifferentNnmbers();
Static public int[] GetDescNumbers(int aNumbers[]);
}
```
5.2.3 Aprior 算法
在关联规则推荐过程中,Apriori 算法是实现的关键,该算法的思路为,对于频繁项集而言,其中包含的子集都频繁。而频繁集通常为对最小的支持度实现满足的项目的集合,若{A,B}为频繁集,那么{A}和{B}都为频繁集。频繁项集获取后,则会得到以此频繁集为基础的强关联规则。
对于 Apriori 算法而言,其应用主要是利用逐层搜索迭代方法完成和实现,也就是对 K-项集进行探索,从而得到(K+1)-的项集,同时利用数据库扫描以及模式匹配方式对候选集支持程度进行计算。第一步,确定频繁 1-项集集合。记为 L1。 L1 的功能是确定频繁 2-的项集合,同理 L2 是确定 L3,依次进行,至无频繁 K-项集为止。实现的流程图如图 5-3 所示。

图 5-3 Apriori 算法的流程图
以下是本系统所采用的 Apriori 算法中的部分程序代码:
public static mergeltenSets(itemSets, int size, int totalTrans) {
ItemSet result;
Int numFound, k;
for (int i = 0; i < itemSets.size(); i++) {
ItemSet first = (ItemSet) itemSets.elementAt(i);
for (j = i + 1; j < itemSets.size(); j++) {
ItemSet second = (ItemSet) itemSets.size.elementAt(j);
result = new ItemSet(totalTrans);
result.m_items = new int[first.m_items.length];
//搜索项集前面相同项的个数 NumFound = 0;
k = 0;
while (numFound < size) {
if (first.m_item[k] == second.m_items[k]) {
if (first.m_ietm[k] != 1) numFound++;
} else result.items[k] = first.m_items[k];
break out;
k++;
}
//找到不同项并连接,生成新项集 While(k<first.m_items.length){
if ((first.m_items[k]) != -1) && (second.m_items[k])) break;
else if (first.m_items[k] != -1) result.m_items[k] = first.m_items[k];
else result.m_items[k] = second.m_items[k];
k++;
}
if (k = first.m_item.length) result.m_counter = 0;
newVector.addElement(result);
}
5.3 效果展示
到目前为止,本文所设计的智能导购系统已用于网上图书商店的应用中,本节通过一个完整的实例来展示该系统的应用过程。
5.3.1 首页
当用户进入系统,首先显示的是系统的首页,如图 5-4 所示。系统的首页主要是按照不同类别、各种推荐及销量情况来向用户进行系统自动推荐,以便方便用户的选择。

图 5-4 系统首页
5.3.2 用户登录
在用户进入系统首页后,未注册用户可以进行注册,已注册用户可以进行用户登录操作。在用户登录系统后,系统根据用户的个人资料信息及用户以往的购买情况,向用户提供了个性化用户推荐模块,来更好的满足用户的购买体验,如图 5-5 所示。
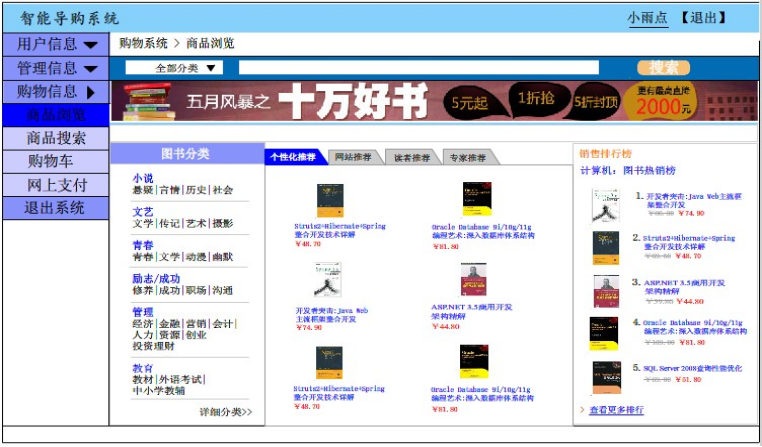
图 5-5 用户登录
5.3.3 商品搜索
在用户进入系统后,可以通过商品搜索来查找自己所需要的商品,系统根据用户所输入的关键字,来进行对各个在线注册的商品网站搜索,选择出满足要求的商品。如图 5-6 所示,对于一种商品,系统列出了各个网站的商品信息,通过对不同网站的商品信息的出售情况进行分析,用户选择自己所需要的商品。
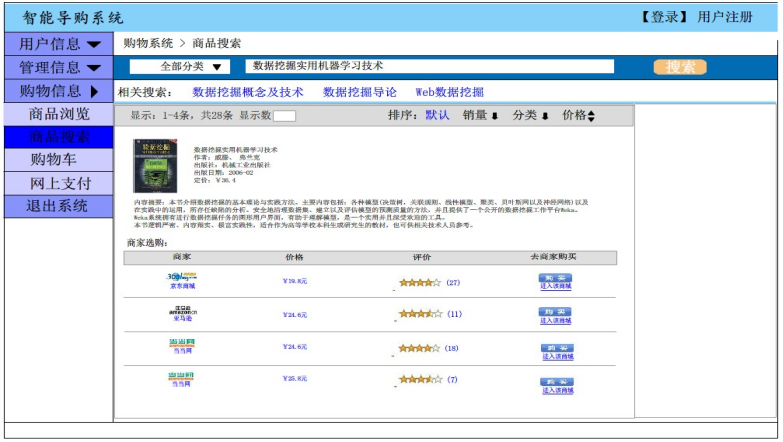
图 5-6 商品搜索页面
5.3.4 购物车
在用户选择好自己所需要的商品后,可以将其加入到购物车中,如图 5-7 所示。

图 5-7 购物车页面
5.3.5 商品推荐
购物车页面主要显示的是消费者的商品购买情况,在此页面中,除了含有消费者的购买信息外,还包含网站的智能推荐信息。本页面中包含两种推荐信息,一是根据用户的购买情况进行推荐,在页面中显示为“购买此商品的顾客同时也购买”;一个是根据商品的关联规则进行推荐,在页面中显示为“经常一起购买的商品”。
5.3.6 订单处理
账单处理模块主要包括生成账单和生成订单两部分,生成账单的动作在客户单机购物车界面的“结账”按钮时触发,该操作生成一个当前购物车内容的统计页面,即一个账单对象。在用户完成了从购物车生成账单的操作后,早账单界面中单击“生成订单”按钮,则可以填写订单页面。在填写完订单表之后,单击“提交”即可生成订单。
5.3.7 代理支付
在该系统中所购买的商品,可以直接在该系统中进行结算,该系统代理各个网上商店进行收取货款。
5.4 本章小结
本章对基于 Web 数据挖掘的智能导购系统进行了实现。首先给出了系统的总体设计思路,然后具体讨论了导购系统的常用模块,包括用户注册、商品搜索、购物车和订单管理等功能模块。最后对智能导购的两个核心模块进行了详细介绍,并给出了实现代码。
第六章智能导购系统的测试
6.1 测试方法和测试流程
软件测试是软件开发过程中最为关键的一个步骤,通常大致占整个软件生命时间的五成左右。例如,操作系统软件的测试阶段时间大约占整个软件生命周期的 54%,而控制功能的软件的测试阶段时间较短,约占整个软件生命周期的 28%。测试阶段的重要性不言而喻,软件测试不但要在软件开发完毕后进行,还要在开发过程中进行性能测试,这样可以有效降低软件开发过程中的潜在问题出现的概率。
通常情况下,软件的测试方法主要包括模拟用户操作测试方法、静态与动态测试方法、回归测试方法等。
软件静态测试方法主要利用代码对目标数据进行相关检测。软件动态测试测试可以划分为软件操作界面的测试与软件的主要功能测试,以白盒测试和黑盒测试为主。其中,白盒测试主要采取代码测试,而黑盒测试主要进行软件的功能与操作环境测试。模拟用户操作测试方法主要是从使用者角度对软件的实际使用性能进行分析,用来测试软件的开发是否存在某些错误。回归测试通过验证软件的各个程序部分是否存在错误从而对软件进行特定修正。本文中设计的交易网站主要采取黑盒测试方法,黑盒测试方法可以在软件开发过程中对软件的功能和操作环境进行测试,即在软件中输入相关的数据后,观察系统是否可以得到正确结果,软件的测试流程主要有设计可测试计划,设计测试计划,设计测试用例,设计测试日志。
6.2 系统的测试
6.2.1 系统功能测试
系统研发完成后,为了确保系统能够正常的运行,需要对系统的各个功能进行测试。测试方法包括很多,其中最常用的包括白盒测试、黑盒测试和单元测试。黑盒测试即将测试对象假设为黑盒子,我们不知道黑盒子内部的构成。对比黑盒测试,白盒测试的特点即我们对系统内部的各个部件或者操作过程完全了解,测试完成后,我们可以了解哪些部件与规范是完全相符,哪些与规范不相符。
为了更好地了解白盒测试的操作步骤,我们对系统的登录过程进行测试,并
以此做例子,介绍测试步骤如下:登录系统设置中对用户进行了区分,不同用户可以根据自己的自身情况,选择身份进行登录,然后进行随后的操作,我们就以此来做白盒测试,见表 6-1 到表 6-6 所示。
(1)在浏览器的地址栏中,输入系统的登陆地址,按回车键,则可进入系统的登录界面。
(2)根据用户的身份不同,选择和自身身份相一致的按钮,并且键入自己的用户名和密码,系统会根据用户名和密码是否相符出现提示。
(3)输入过程中,只输入用户名或者只输入密码,就点击登录,想要进入系统,这种情况下,系统会做提示。
(4)如果用户输入的用户名与密码不相符,或者输入错误的用户名,系统而暂停其访问系统的权利,只有用户名和密码完全相对应,则表示操作成功。
(5)登录界面中还存在推出键,如果想中止操作,可以直接按退出。
表 6-1 登录界面测试
| 测试用例 ID | 场景 | 测试步骤 | 预期结果 | 备注 |
|---|---|---|---|---|
| TC1 | 显示最初页面 | 进入用例入口 | 页面内容完整显示,与设计初衷一致 | |
| TC3 | 检测用户名 | 录入:user123456789123456789 | 超过蓝色输入范围之内时,继续输入无效 | 录入的数据越界 |
| TC6 | 用户登录系统 | 不输任何信息,直接点击登录 | 不能进入系统,并给出提示 | |
| TC7 | 无密码验证 | 在只输入用户名的情况下直接点击登录 | 不能进入系统,并给出提示 | |
| TC8 | 有密码验证 | 输入错误的密码 | 不能通过验证,并提示密码输入错误 | |
| TC9 | 安全验证 | 连续输入 3 次错误的信息 | 系统提示:您无权操作 |
表 6-2 考核界面测试
| 测试用例 ID | 场景 | 测试步骤 | 预期结果 | 备注 |
|---|---|---|---|---|
| 00107 | 导航栏 | 浏览\点击导航连接 | 1)正确显示所在页面的模块名称,2)正确导航 | |
| 00108 | 添加按钮 | 1)该按钮是否可用 | 1)不可用 | |
| 00109 | 修改删除按钮 | 1)该按钮是否可用 | 1)不可用 | |
| 00110 | 接受\汇报按钮 | 1)该按钮是否可用 | 1)不可用 | |
| 00111 | 考核按钮 | 1)不是自己负责的数据未接受之前能否考核 2)自己以及自己负责部门人员负责的任务数据未接受之前能否考核 3)自己负责的任务数据接受后能否考核 4)自己负责部门人员的任务数据未接受之前能否考核 5)自己负责部门人员的任务数据接受了但未汇报能否考核 6)自己负责部门人员的任务数据汇报后能否考核 7)自己负责部门人员的任务数据考核后,能否再考核 8)自己负责部门人员的任务数据审核后,能否再考核 | 1)不能 2)不能 3)按钮正常显示,不能自己对自己考核,有提示 4)不能 5)考核人为自己才能考核,进入页面,否则不能考核 6)考核人为自己才能考核,进入考核页面,否则不能考核 7)不能,此时考核按钮置灰 8)不能,此时考核按钮置灰 |
表 6-3 公司动态-公司大事界面测试
| 用例 ID | 01 |
|---|---|
| 用例简述 | 测试“公司动态-公司大事”页面信息是否正常显示 |
| 用例详述 | 后台操作路径:后台-信息管理-信息内容管理-网站栏目-走进公司动态-公司大事 1、撰写一条信息 2、发布此条信息 3、修改此条信息 4、打回此条信息 5、删除此条信息分别进行以上操作,分别查看前台:走进公司动态-公司大事 |
| 预期结果 | 上述操作会影响如下页面:后台-信息管理-信息内容管理-网站栏目-走进公司动态-公司大事;前台-走进公司动态-公司大事 1、撰写的信息:后台显示,状态为待审;前台不显示 2、发布的信息:后台显示,状态为发布;前台显示 3、修改的信息:后台显示,状态为待审;前台不显示 4、打回的信息:后台显示,状态为打回;前台不显示 5、删除的信息:后台消失;前台消失 |
| 实际结果 |
表 6-4 公司动态-媒体报道界面测试
| 用例 ID | 02 |
|---|---|
| 用例简述 | 测试“公司动态-媒体报道”页面信息是否正常显示 |
| 用例详述 | 后台操作路径:后台-信息管理-信息内容管理-网站栏目-走进公司动态-媒体报道 1、撰写一条信息 2、发布此条信息 3、修改此条信息 4、打回此条信息 5、删除此条信息分别进行以上操作,分别查看前台:走进公司动态-媒体报道 |
| 预期结果 | 上述操作会影响如下页面:后台-信息管理-信息内容管理-网站栏目-走进-公司动态-媒体报道;前台-走进公司动态-媒体报道 1、撰写的信息:后台显示,状态为待审;前台不显示 2、发布的信息:后台显示,状态为发布;前台显示 3、修改的信息:后台显示,状态为待审;前台不显示 4、打回的信息:后台显示,状态为打回;前台不显示 5、删除的信息:后台消失;前台消失 |
| 实际结果 |
表 6-5 信息详细内容页显示测试
| 用例 ID | 03 |
|---|---|
| 用例简述 | 测试信息详细内容页各项功能是否正常 |
| 用例详述 | 点击打开前台公司大事或媒体报道一条信息的详细内容页面查看正文内容,并试用以下功能:1、字体大中小,2、打印,3、关闭窗口 |
| 预期结果 | 正文内容与后台输入一致,包括作者、时间、来源 1、字体大中小功能正常 2、打印功能正常 3、关闭窗口功能正常 |
| 实际结果 |
表 6-6 信息详细内容页显示测试
| 用例 ID | 04 |
|---|---|
| 用例简述 | 测试“翻页”功能 |
| 用例详述 | 一、分别点击:1、首页 2、上一页 3、下一页 4、尾页二、输入数字,点击“GO” |
| 预期结果 | 一、1、跳转到首页 2、跳转到上一页 3、跳转到下一页 4、跳转到尾页二、跳转到输入的数字的页面 |
| 实际结果 |
6.2.2 系统性能测试
系统功能完成后如何没有问题,则说明系统能够正常运行。但是考察系统时,不仅要考察系统能够正常运行,还要考察系统中的功能是否可以达到客户的需求,我们将这种测试叫做性能测试。我们以访问系统的最高的用户数做研究对象,考察系统能够支持的数目。具体测试操作步骤分为两步。首先,编写符合测试要求的流程,并且按照流程进行操作。然后,使用多个浏览器在某一特定的时间段内同时登录系统,但有时会出现登录成功,但有时会出现登录失败。随后,记录计算机系统所能够支持的最高的用户数。在此过程中,我们还需要记录成功次数、数据库服务器 CPU 利用率、测试时间、Web 服务器 CPU 利用率和失败次数等共同考察系统的性能指数。
(1)表 6-7 中描述的是测试过程中需要记录的一些参数
表 6-7 测试环境
| 编号 | 作用 | 硬件 | 软件 |
|---|---|---|---|
| 1 | 测试计算机 | CPU 双核 intel e7500 RAM 2048M | Win2003server + sp3 测试工具(loadrunner7.5) |
| 2 | 被测试用到 Web 服务器 | CPU 四核至强 E5604 RAM 8096M | Win2003server + sp3 Weblogic 6.1 |
| 3 | 被测试的数据库服务器 | CPU 四核至强 E5604 RAM 8096M | Win2003server + sp3 SQL Server |
(2)测试模型如图 6-1 所示。
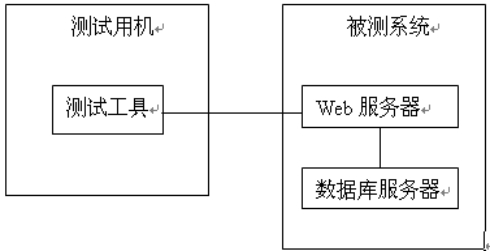
图 6-1 测试模型示意图
(3)测试用例用户并发测试是性能测试最主要的部分,主要是通过增加用户数量来加重系统负担,以检验测试对象能接收的最大用户数来确定功能是否达到要求。见表 6-8 所示。
表 6-8 用户并发测试用例举例
| 测试目的 | 主要是通过增加用户数量来加重系统负担,以检验测试对象能接收的最大用户数来确定功能是否达到要求。 | |||
|---|---|---|---|---|
| 前提条件 | 系统运行正常,网络连通 | |||
| 测试需求 | 输入(并发用户数) | 用户通过率 | 期望性能(平均值) | 实际性能(平均值) |
| 功能 1 | 50 | 100% | 0.5 | 0.54 |
| 100 | 100% | 0.73 | 0.8 | |
| 200 | 100% | 1.12 | 1.3 | |
| 功能 2 | 50 | 100% | 0.6 | 0.66 |
| 100 | 100% | 0.82 | 0.8 | |
| 200 | 100% | 1.3 | 1.4 | |
| 备注: |
6.2.3 系统界面测试
表 6-9 给出了主要的关于界面方面的测试指标。
表 6-9 用户界面测试检查表
| 检查项 | 结果 |
|---|---|
| 窗口切换、移动、改变大小时正常吗? | 正常 |
| 各种界面元素的文字正确吗?(如标题、提示等) | 正常 |
| 各种界面元素的状态正确吗?(如有效、无效、选中等状态) | 正常 |
| 操作顺序合理吗? | 正常 |
| 有联机帮助吗? | 正常 |
| 各种界面元素的布局合理吗?美观吗? | 正常 |
| 各种界面元素的颜色协调吗? | 正常 |
| 各种界面元素的形状美观吗? | 正常 |
| 字体美观吗? | 正常 |
| 图标直观吗? | 正常 |
6.2.4 兼容性测试
在大多数生产环境中,客户机工作站、网络连接和数据库服务器的具体硬件规格会有所不同。客户机工作站可能会安装不同的软件例如,应用程序、驱动程序等而且在任何时候,都可能运行许多不同的软件组合,从而占用不同的资源。表 6-10 所示。
表 6-10 用户界面测试检查表
| 测试目的 | 检验软件在不同的操作系统下运行情况 | ||||
|---|---|---|---|---|---|
| 配置说明 | 操作系统 | 系统软件 | 外设 | 应用软件 | 结果 |
| 服务器 | Window2000(S) | 正常 | |||
| WindowXp | 正常 | ||||
| Window2000(P) | 正常 | ||||
| Window2003 | 正常 | ||||
| 客户端 | Window2000(S) | 正常 | |||
| WindowXp | 正常 | ||||
| Window2000(P) | 正常 | ||||
| Window2003 | 正常 | ||||
| 数据库服务器 | Window2000(S) | 正常 | |||
| WindowXp | 正常 | ||||
| Window2000(P) | 正常 | ||||
| Window2003 | 正常 | ||||
| 浏览器 | IE6.0 以上 | 正常 | |||
| 360 浏览器 | 正常 | ||||
| Firefox | 正常 | ||||
| Maxthon | 正常 | ||||
| QQ 浏览器 | 正常 | ||||
| 其他 | 正常 | ||||
| 备注 |
6.2.5 疲劳强度测试用例
强度测试也是性能测试是的一种,实施和执行此类测试的目的是找出因资源不足或资源争用而导致的错误。如果内存或磁盘空间不足,测试对象就可能会表现出一些在正常条件下并不明显的缺陷。而其他缺陷则可能由于争用共享资源(如数据库锁或网络带宽)而造成的。强度测试还可用于确定测试对象能够处理的最大工作量。
表 6-11 疲劳强度检测表
| 测试目的 | 测试软件的健壮性 | ||
|---|---|---|---|
| 测试说明 | 系统软件和硬件运行正常 | ||
| 前提条件 | 连续运行 8 小时,设置添加 10 用户并发 | ||
| 测试需求 | 输入/动作 | 输出/响应 | 是否正常运行 |
| 功能 1 | 2 小时 | 响应 | 正常 |
| 4 小时 | 响应 | 正常 | |
| 6 小时 | 响应 | 正常 | |
| 8 小时 | 响应 | 正常 | |
| 功能 1 | 2 小时 | 响应 | 正常 |
| 4 小时 | 响应 | 正常 | |
| 6 小时 | 响应 | 正常 | |
| 8 小时 | 响应 | 正常 |
6.2.6 安装、卸载测试用例
注:安装、卸载测试应在其它测试工作完成后进行!测试用例如表 6-12 和表 6-13 所示。
表 6-12 安装、卸载测试用例一
| 开始条件 | 1、尚未安装过网站软件或已卸载网站软件。 |
|---|---|
| 测试动作 | 根据安装向导进行安装 |
| 预计输出 | 1、成功安装网站软件。 |
表 6-13 安装、卸载测试用例二
| 开始条件 | 1、已安装过网站软件。 |
|---|---|
| 测试动作 | 根据安装向导进行安装 |
| 预计输出 | 1、安装向导应询问要进行“重新安装”还是“卸载”。注:两种情况都要进行测试。(因此安装、卸载测试用例一和安装、卸载测试用例二要运行两遍) |
6.2.7 测试结果
资源系统中是由许多模块组成的,但是在设计时各个模块又有相通之处,因此我们在对系统的功能和性能进行测试时只需要对那些用户访问较多,相对来说能够表达用户需要的模块做相关测试,只要这些模块符合规范和用户需求,根据相似原理,系统整个测试结果也是满意的。服务器为通用的 03 版 windows server 企业版,而客户端则为 XP 或者 windows7。
受到自身知识水平和时间的限制,我们只对部分模块进行了测试,但是值得一提的是各个模块存在相通之处,只要这些模块符合规范和用户需求,根据相似原理,系统整个测试结果也是满意的。测试完成后,为了核算系统的性能指数,我们需要对记录的数据进行处理,处理内容包括以下几方面:成功率、处理能力、最短平均相应时间、最大并发用户和最高处理能力。其中成功率等于成功次数除以总次数,处理能力等于成功率乘以总次数除以测试时间,最高处理能力等于最大的处理能力乘以(1-cache 影响系数),同时进行计算时还需注意单位是否一致。
根据记录的数据和一些计算公式就能够得到图 6-2 中的测试结果,通过结果我们可以看出,系统性能能够满足用户需要。
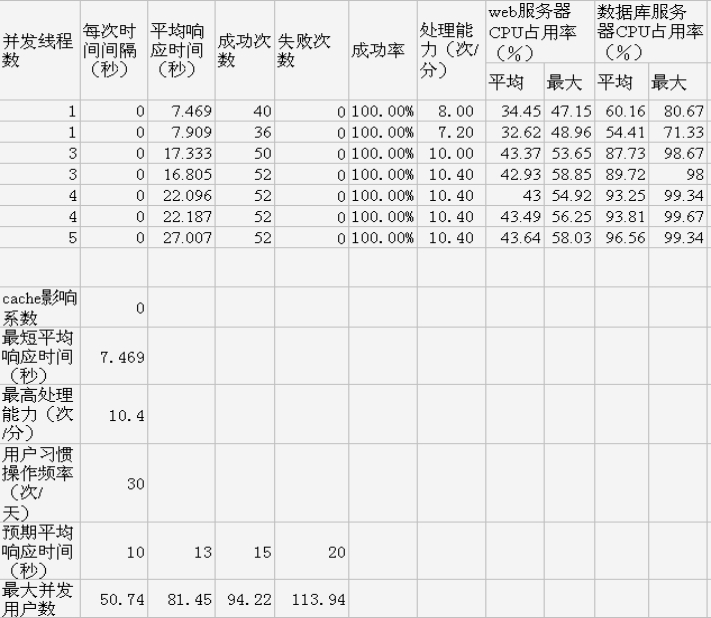
图 6-2 测试结果数据
本文论述的智能导购系统的方案,已运用在多个商场,其成功不仅有效提高了商品的销售的速度,同时大大节省了管理的操作时间,提升了工作效率。
6.3 本章小结
本章主要是严格按照软件工程的流程,对系统进行了功能测试和性能测试,测试结果符合软件设计的要求。
第七章总结与展望
7.1 本文总结
随着我国导购系统的不断完善,参与商品智能导购的单位数量在持续快速的增长。而与此同时,在我国社会经济近年来持续快速增长的带动下,广大群众的消费需求与商品价格都出现的高速增长。这一切因素都在不断推动着我国商品导购的完善。在这样一个复杂的环境下,原有的商品购物网站从架构到功能均已无法适应当前业务发展的需要,逐渐出现了购物记录统计工作量大,消耗了大量人力资源;而且各个购物网站之间的竞争压力增大,需要通过客户的购物需求,分析客户的购物趋势。
基于当前购物网站的发展现状,本文从分析客户购物趋势的视角出发,采用新的技术架构建立以联机处理为核心、相互渗透并结合的业务流程,以此为突破口研究探讨新的智能导购系统架构与设计实现。新系统具备以下特点:
1、引入了 J2EE 企业级应用系统架构,系统具备良好的可伸缩性和可扩展性,并且可跨平台部署,能够适应未来消费者购物的快速增长的趋势。
2、建立了一套基于数据挖掘的智能导购业务的流程,使得商品导购的业务管理更加规范、精细、高效和便捷。
3、在数据挖掘的基础上实现了分类决策树的客户关系数据挖掘,及商品的智能推荐。
本文针对消费者经常购买的商品,设计了一种个性化的导购系统。该智能导购系统主要集中在智能分类与周期性排行、智能搜索、智能推荐三个方面。其中智能分类和智能搜索为消费者在线进行商品浏览和查询提供了方便,便于消费者轻松的查询和定位到个人所需要的商品上;周期性排行和智能推荐是根据商品的销量或用户的购买倾向及购买种类,系统自动向用户推荐商品,来满足消费者的需求,既为消费者提供了方便,也有益于提高商品的销售量。
目前,此系统主要是在图书用品的导购中被应用,针对原型系统进行了开发,效果显示系统具备商业价值的潜质。以研究工作为基础,笔者则针对此系统进行不断的完善,实现其能够支持和提供更加丰富和全面的服务。
7.2 下一步研究展望
本文研究的基于基于 Web 数据挖掘的智能导购系统,虽然取得了较好的效果,但是本课题还存在一些需要探讨和完善的问题,今后我们将在以下几个方面进行研究:
(1)目前电子商务智能导购系统存在不完善的体系结构的问题,多数导购系统仅作为单一性质工具,仅能够对推荐模型进行提供。而因电子商务系统其自身存在一定的繁琐和复杂特性,针对各场合均需针对情况采取特定类型推荐。而新电子商务的推荐系统体系结构构建也是很有必要的,对各类型数据进行收集,则能够形成对应的多类型的推荐模型,因此对不同推荐需求都能实现满足。
(2)缺少推荐结果的解释,电子商务推荐系统主要是对用户进行说服,因此对用户解释推荐原因是有必要的。而现行系统推荐仅是以销售排行以及用户商品评价的等为依据实现推荐。因此,要深入的对用户解释形成推荐原因进行研究,这样能实现用户更信任推荐,也就使得推荐更有说服力。
致谢
回顾硕士论文从构思到完成的全过程,感慨颇多。本论文能够顺利完成,最 应当感谢的就是尊敬的李会勇教授。虽然老师平日工作繁忙,但是始终关心我论 文写作的进度,并在论文撰写的各个阶段对我进行悉心的指导,让我认识到论文 设计的不足,同时也让我对论文的整体有了系统的理解,对论文的相关内容进行 全面掌握,给我的写作带来了巨大的启迪。可以这样说,在对论文撰写完成的工 作,也是我的学术积累升华的过程,是我的人生中一次无法忘怀的成长过程。
一年多来,李教授教给我的不仅仅是如何做学术,更是如何做人,如何做出 色的人。由衷感谢李教授,您为我倾注的辛劳和期望,将成为我人生生涯中最宝 贵的财富。
当然,本篇论文得以顺利完成,也离不开研究生在读期间给我上过课的各位 老师们,是您们传授了我理论知识和思维方式,让我得以拓宽研究视角、强化逻 辑链条。
最后,我还要感谢研究生期间在我身边的家人和朋友,谢谢你们对我的支持 与鼓励,让我走过三年以来的每个日夜,愿你们一切如意。
参考文献
[1] 黄雪斌. 使用 XML 和 PKI 构建安全 Web 服务[D]. 上海: 上海交通, 2002.
[2] Lonnie wall, Andrew Lader. 构建 Web 服务和.NET 应用程序(康博译)[M]. 清华出版社, 2002, 10, 21-49.
[3] Ben Galbraith, Whitney Hankison. Web 服务安全性编程(吴旭超等译)[M]. 清华出版社,2006, 5, 36-38.
[4] Alan Dennis, Barb Wixom, David Tegarden, Systems Analysis&Design. 2002.8:138-142
[5] Pierre N.Robilard, Phillippe Kruchten, Patrick d'Astous, Software Engineering Process with the UPEDU 2003.8:69-71.
[6] Keith Thomas PhalP, Peter Henderson, Rboert John Walters, et al.RoiEnact:role- based enact able models of business processes [I].Information and Software Technology, 1998, 40:123-133.
[7] 王继梅, 金连甫. Web 服务安全问题研究和解决[J]. 计算机应用与软件, 2004, 21(2):91-93.
[8] 罗荣良, 朱勇. 基于模型驱动架构的 Web Services 应用开发[J]. 计算机应用与软件, 2004, 21(1):110-112.
[9] 吴文明, 瞿裕忠, 董逸生. Web 服务及相关技术[J]. 计算机应用与软件, 2004, 21(3): 14-15.
[10] James Rumbaugh, Ivar Jacobson, Crrady Booch[J] .The Unified Modeling Language Reference Manual OMQ 1997: 256-268.
[11] Rational Unified Process: Best Practices For Software development Teams[J]. Rational Software Corp. White Paper, 1999: 19-21.
[12] Ronal J.Norman, Object-Oriented Systems Analysis and Design[J], Prentice-Hall International, Inc, 2000: 62-68.
[13] 李腊元, 李春林等. 计算机网络技术[M]. 北京: 国防工业出版社, 2001: 55-57.
[14] 孙永强著. Web 服务深入编程[M]. 清华出版社, 2007:101-105.
[15] 宗平, 邓赛峰. Web 服务安全结构模型研究和设计[J]. 计算机与现代化, 2004, 11:89-90.
[16] 萨师煊, 王珊. 数据库系统概论[M]. 图档信息管理出版社, 2003:26-31.
[17] 李慧勇, 郑艳明. 国内外办公自动化的研究现状及发展趋势[J]. 科技信息(学术研究), 2008, 17:169-171.
[18] [美]Ed Roman 著. 刘晓华译. 精通 EJB(第二版)[M]. 电子工业出版社, 2002.50: 209-244.
[19] [美]波德夫, 颜承译. The J2EE Tutorial 中文版[M]. 中国铁道出版社, 2003.7:268-280.
[20] Rod Johnson. JZEE Development Frameworks [J]. Computer, 2005, 38(1):107-110.
[21] D.Florescu. An XML Programming Language for Services Pacification and Com Position [A], In Proceeding of the 11th International world Wide Web Conference[C], 2005, 12(3):6-12.
[22] GeertVan. Using Web services for business integrations [J], Intelligent Systems, 2006:18-23.
[23] 刘晓华. J2EE 企业级应用开发[M]. 电子工业出版社, 2003.8:378-381.
[24] 刘洋, 葛声. 一种基于 Web 服务的分布式工作流系统的研究与实现[J]. 计算机工程与应用, 2003.1:208-217.
[25] 陈天河等. Struts, Hibernate, Spring 集成开发宝典[M]. 北京: 电子工业出版社, 2007:56-58.
[26] Jreg Rarish. J2ee Web 应用高级编程[M]. 北京: 清华出版社, 2002.50:33.
[27] 麦特纳. J2EE 平台上的 EJB 组件开发[M]. 北京: 机械工业出版社, 2002.6:19-25.
[28] 尹志军. 基于 J2EE 体系结构的办公自动化系统的研究与实现[D]. 上海: 上海交通, 2003.
[29] Joseph Schmuller, Teach Yourself UML in 24 Hours, Second Edition. Sams, 2002.6: 135-137.
[30] Grady Booch, James Rumbaugh, Ivar Jacobson(美), The Unified Modeling Language User Guide, Addison Wesley Longman Inc, 1999:334-338.
[31] Khanar Gaman Ahmed, Cary E.umrvsh. 用 J2EE 和 UML 开发 Java 企业级应用程序[M]. 北 京: 清华出版社, 2002.7:213-215.
[32] 宋坤, 李伟明, 刘锐宁. Visual c++ 数据库系统开发案例精选[M]. 人面邮电出版社, 2006:143-146.
[33] 颜志军. Visual c++ 数据库开发典型模块与实例精讲[M]. 电子工业出版社, 2007:98-101.
[34] Abraham Silberchatz. Database System Concepts[M]. 机械工业出版社, 2003: 76-79.
参考文献
- 基于用户评论挖掘的Web导购系统设计与实现(西安电子科技大学·耿霄)
- 基于Asp.net的B2C电子商务系统设计与实现(重庆大学·李俊)
- 基于J2EE的德威公司产品销售管理系统的设计与实现(吉林大学·朴海燕)
- 基于用户评论挖掘的Web导购系统设计与实现(西安电子科技大学·耿霄)
- 基于PHP和MySQL的网上购物系统设计与实现(电子科技大学·李华明)
- 基于J2EE的网络购物中心设计和实现(电子科技大学·张晓军)
- 基于B/S架构的网上书店系统的设计与实现(吉林大学·王骁)
- 基于B/S架构的网上书店系统的设计与实现(吉林大学·王骁)
- 基于B/S架构的网上书店系统的设计与实现(吉林大学·王骁)
- 现代网上购物信息管理系统的研究(吉林大学·王宇龙)
- 基于ASP.NET的网上购物系统的设计与实现(电子科技大学·易扬)
- 手机销售网站设计与实现(电子科技大学·杨俊升)
- 网购平台的设计与实现(吉林大学·王萱筠)
- 基于ASP.NET的网上购物系统的设计与实现(电子科技大学·易扬)
- 现代网上购物信息管理系统的研究(吉林大学·王宇龙)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计客栈 ,原文地址:https://bishedaima.com/yuanma/35767.html









