
奇异值分解(SVD)及其扩展详解
本文算法主要考虑个性化推荐领域
1.Matrix Factorization Model 和 Baseline Predictors
SVD 其实就是 Matrix Factorization Model 和 Baseline Predictor 的结合,所以为了方便我们先在这里介绍这两个东西。
(1)Matrix Factorization Model
把我们的用户评分想象成一个表:
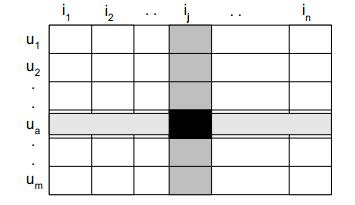 每一行代表一个用户,每一列代表一个物品,这其实就是一个矩形,只是我们拥有的这个矩形可能是非常稀疏的,也就是我们知道的评分占总量很少,但现在我们知道它是一个矩形,一个矩形自然可以表示为另两个矩形的乘积(后续会给出证明):
每一行代表一个用户,每一列代表一个物品,这其实就是一个矩形,只是我们拥有的这个矩形可能是非常稀疏的,也就是我们知道的评分占总量很少,但现在我们知道它是一个矩形,一个矩形自然可以表示为另两个矩形的乘积(后续会给出证明):
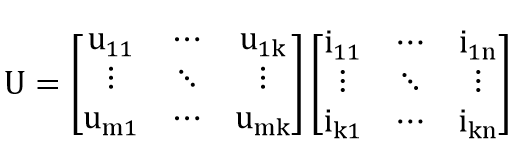 将这种分解方式体现协同过滤中,即有:
将这种分解方式体现协同过滤中,即有:
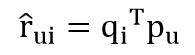 在这样的分解模型中,Pu 代表用户隐因子矩阵(表示用户 u 对因子 k 的喜好程度),Qi 表示电影隐因子矩阵(表示电影 i 在因子 k 上的程度)。
在这样的分解模型中,Pu 代表用户隐因子矩阵(表示用户 u 对因子 k 的喜好程度),Qi 表示电影隐因子矩阵(表示电影 i 在因子 k 上的程度)。
(2)Baseline Predictors
Baseline Predictors 使用向量 bi 表示电影 i 的评分相对于平均评分的偏差,向量 bu 表示用户 u 做出的评分相对于平均评分的偏差,将平均评分记做 μ。

2.SVD 数学原理及推导
对任意 M*N 的矩阵,能否找到一组正交基使得经过它变换后还是正交基?答案是肯定的,它就是 SVD 分解的精髓所在。
现在假设存在 M*N 矩阵 A,事实上,A 矩阵将 n 维空间中的向量映射到 k(k<=m)维空间中,k=Rank(A)。现在的目标就是:在 n 维空间中找一组正交基,使得经过 A 变换后还是正交的。假设已经找到这样一组正交基:
 则 A 矩阵将这组基映射为:
则 A 矩阵将这组基映射为:
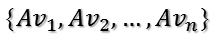 如果要使他们两两正交,即
如果要使他们两两正交,即
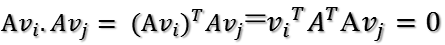 根据假设,存在
根据假设,存在
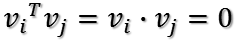 所以如果正交基 v 选择为 A’A 的特征向量的话,由于 A’A 是对称阵,v 之间两两正交,那么
所以如果正交基 v 选择为 A’A 的特征向量的话,由于 A’A 是对称阵,v 之间两两正交,那么
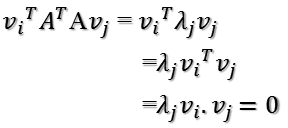 这样就找到了正交基使其映射后还是正交基了,现在,将映射后的正交基单位化:
这样就找到了正交基使其映射后还是正交基了,现在,将映射后的正交基单位化:
因为
 所以有
所以有
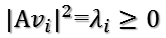 所以取单位向量
所以取单位向量
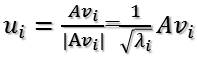 由此可得
由此可得
 当 k < i <= m 时,对 u1,u2,…,uk 进行扩展 u(k+1),…,um,使得 u1,u2,…,um 为 m 维空间中的一组正交基,即将{u1,u2,…,uk}正交基扩展成{u1,u2,…,um}单位正交基。同样的,对 v1,v2,…,vk 进行扩展 v(k+1),…,vn(这 n-k 个向量存在于 A 的零空间中,即 Ax=0 的解空间的基),使得 v1,v2,…,vn 为 n 维空间中的一组正交基。
当 k < i <= m 时,对 u1,u2,…,uk 进行扩展 u(k+1),…,um,使得 u1,u2,…,um 为 m 维空间中的一组正交基,即将{u1,u2,…,uk}正交基扩展成{u1,u2,…,um}单位正交基。同样的,对 v1,v2,…,vk 进行扩展 v(k+1),…,vn(这 n-k 个向量存在于 A 的零空间中,即 Ax=0 的解空间的基),使得 v1,v2,…,vn 为 n 维空间中的一组正交基。
则可得到
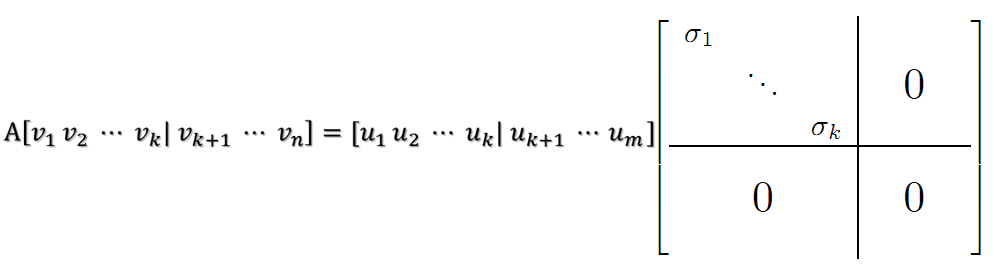 继而可以得到 A 矩阵的奇异值分解(两边同乘以 VT):
继而可以得到 A 矩阵的奇异值分解(两边同乘以 VT):
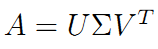 V 是 n×n 的正交阵,U 是 n×n 的正交阵,∑ 是 n×m 的对角阵
现在可以来对 A 矩阵的映射过程进行分析了:如果在 n 维空间中找到一个(超)矩形,其边都落在 A’A 的特征向量的方向上,那么经过 A 变换后的形状仍然为(超)矩形!
V 是 n×n 的正交阵,U 是 n×n 的正交阵,∑ 是 n×m 的对角阵
现在可以来对 A 矩阵的映射过程进行分析了:如果在 n 维空间中找到一个(超)矩形,其边都落在 A’A 的特征向量的方向上,那么经过 A 变换后的形状仍然为(超)矩形!
vi 为 A’A 的特征向量,称为 A 的右奇异向量,ui=Avi 实际上为 AA’的特征向量,称为 A 的左奇异向量。下面利用 SVD 证明文章一开始的满秩分解:
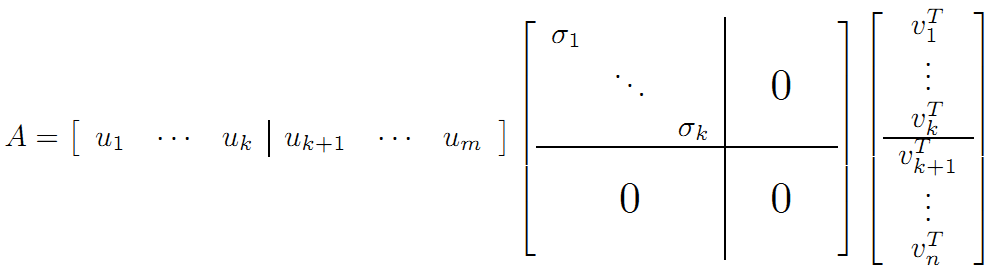 利用矩阵分块乘法展开得:
利用矩阵分块乘法展开得:
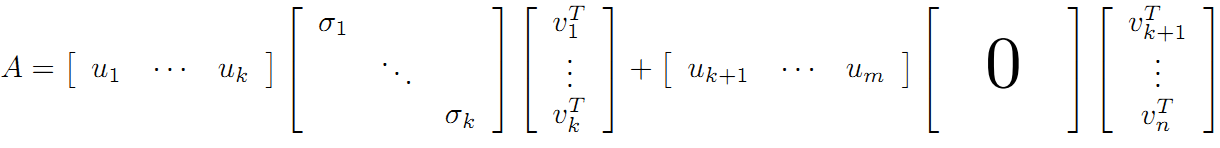 可以看到第二项为 0,有
可以看到第二项为 0,有
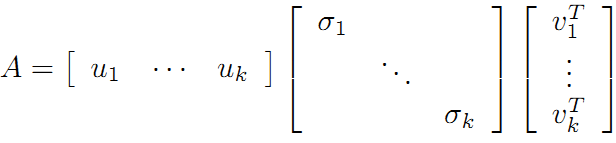 令
令
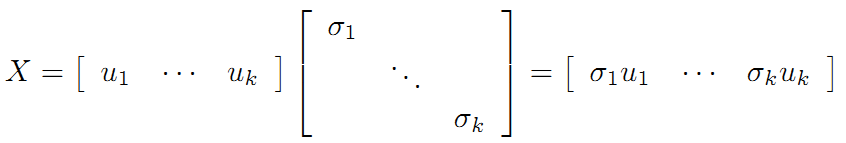
 则 A=XY 即是 A 的满秩分解。
则 A=XY 即是 A 的满秩分解。
3.Basic SVD
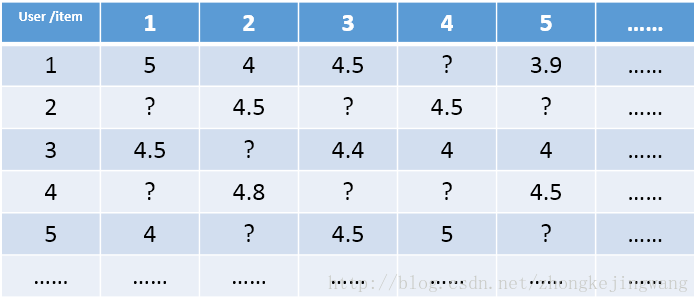 如上所证,评分矩阵 R 存在这样一个分解,所以可以用两个矩阵 P 和 Q 的乘积来表示评分矩阵 R:
如上所证,评分矩阵 R 存在这样一个分解,所以可以用两个矩阵 P 和 Q 的乘积来表示评分矩阵 R:
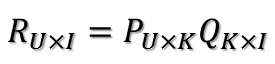 U 表示用户数,I 表示商品数,K=Rank。然后就是利用 R 中的已知评分训练 P 和 Q 使得 P 和 Q 相乘的结果最好地拟合已知的评分,那么未知的评分也就可以用 P 的某一行乘上 Q 的某一列得到了:
U 表示用户数,I 表示商品数,K=Rank。然后就是利用 R 中的已知评分训练 P 和 Q 使得 P 和 Q 相乘的结果最好地拟合已知的评分,那么未知的评分也就可以用 P 的某一行乘上 Q 的某一列得到了:
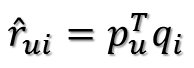 这是预测用户 u 对商品 i 的评分,它等于 P 矩阵的第 u 行乘上 Q 矩阵的第 i 列。这个是最基本的 SVD 算法,那么如何通过已知评分训练得到 P 和 Q 的具体数值呢?
这是预测用户 u 对商品 i 的评分,它等于 P 矩阵的第 u 行乘上 Q 矩阵的第 i 列。这个是最基本的 SVD 算法,那么如何通过已知评分训练得到 P 和 Q 的具体数值呢?
假设已知的评分为:
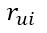 则真实值与预测值的误差为:
则真实值与预测值的误差为:
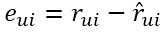 继而可以计算出总的误差平方和:
继而可以计算出总的误差平方和:
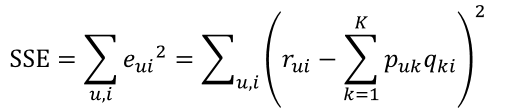 只要通过训练把 SSE 降到最小那么 P、Q 就能最好地拟合 R 了。那又如何使 SSE 降到最小呢(本文使用梯度下降优化方法)?
只要通过训练把 SSE 降到最小那么 P、Q 就能最好地拟合 R 了。那又如何使 SSE 降到最小呢(本文使用梯度下降优化方法)?
利用梯度下降法可以求得 SSE 在 Puk 变量(也就是 P 矩阵的第 u 行第 k 列的值)处的梯度:
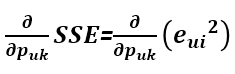 利用求导链式法则,e^2 先对 e 求导再乘以 e 对 Puk 的求导:
利用求导链式法则,e^2 先对 e 求导再乘以 e 对 Puk 的求导:
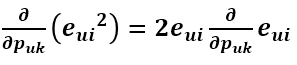 由于
由于
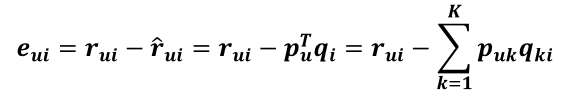 所以
所以
 上式中括号里的那一坨式子如果展开来看的话,其与 Puk 有关的项只有 PukQki,其他的无关项对 Puk 的求导均等于 0,所以求导结果为:
上式中括号里的那一坨式子如果展开来看的话,其与 Puk 有关的项只有 PukQki,其他的无关项对 Puk 的求导均等于 0,所以求导结果为:
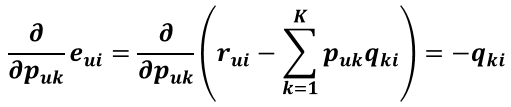 所以
所以
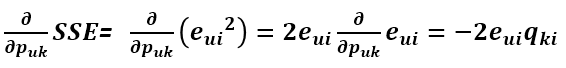 为了让式子更简洁,令
为了让式子更简洁,令
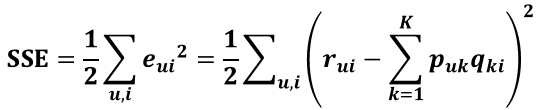 这样做对结果没有影响,只是为了把求导结果前的 2 去掉,更好看点。得到
这样做对结果没有影响,只是为了把求导结果前的 2 去掉,更好看点。得到
 现在得到了目标函数在 Puk 处的梯度了,那么按照梯度下降法,将 Puk 往负梯度方向变化。令更新的步长(也就是学习速率)为
现在得到了目标函数在 Puk 处的梯度了,那么按照梯度下降法,将 Puk 往负梯度方向变化。令更新的步长(也就是学习速率)为
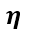 则 Puk 的更新式为
则 Puk 的更新式为
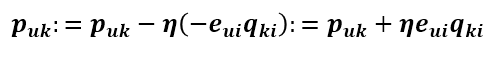 同样的方式可得到 Qik 的更新式为
同样的方式可得到 Qik 的更新式为
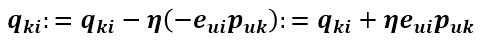 得到了更新的式子,现在开始来讨论这个更新要怎么进行。有两种选择:1、计算完所有已知评分的预测误差后再对 P、Q 进行更新。2、每计算完一个 eui 后立即对 Pu 和 qi 进行更新。这两种方式都有名称,分别叫:1、批梯度下降。2、随机梯度下降。两者的区别就是批梯度下降在下一轮迭代才能使用本次迭代的更新值,随机梯度下降本次迭代中当前样本使用的值可能就是上一个样本更新的值。由于随机性可以带来很多好处,比如有利于避免局部最优解,所以现在大多倾向于使用随机梯度下降进行更新。
得到了更新的式子,现在开始来讨论这个更新要怎么进行。有两种选择:1、计算完所有已知评分的预测误差后再对 P、Q 进行更新。2、每计算完一个 eui 后立即对 Pu 和 qi 进行更新。这两种方式都有名称,分别叫:1、批梯度下降。2、随机梯度下降。两者的区别就是批梯度下降在下一轮迭代才能使用本次迭代的更新值,随机梯度下降本次迭代中当前样本使用的值可能就是上一个样本更新的值。由于随机性可以带来很多好处,比如有利于避免局部最优解,所以现在大多倾向于使用随机梯度下降进行更新。
4.RSVD
上面就是基本的 SVD 算法,但是,问题来了,上面的训练是针对已知评分数据的,过分地拟合这部分数据有可能导致模型的测试效果很差,在测试集上面表现很糟糕,这就是过拟合问题。
那么如何避免过拟合呢?那就是在目标函数中加入正则化参数(加入惩罚项),对于目标函数来说,P 矩阵和 Q 矩阵中的所有值都是变量,这些变量在不知道哪个变量会带来过拟合的情况下,对所有变量都进行惩罚:
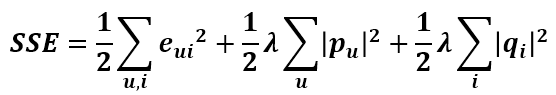 这时候目标函数对 Puk 的导数就发生变化了,现在就来求加入惩罚项后的导数。
这时候目标函数对 Puk 的导数就发生变化了,现在就来求加入惩罚项后的导数。
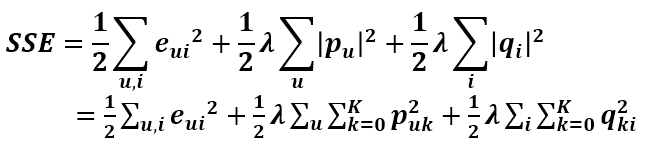 括号里第一项对 Puk 的求导前面已经求过了,第二项对 Puk 的求导很容易求得,第三项与 Puk 无关,导数为 0,所以
括号里第一项对 Puk 的求导前面已经求过了,第二项对 Puk 的求导很容易求得,第三项与 Puk 无关,导数为 0,所以
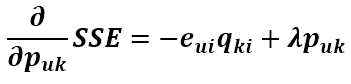 同理可得 SSE 对 qik 的导数为
同理可得 SSE 对 qik 的导数为
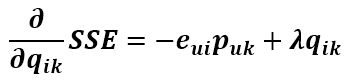 将这两个变量往负梯度方向变化,则更新式为
将这两个变量往负梯度方向变化,则更新式为
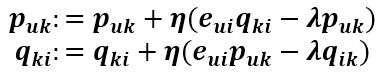 这就是正则化后的 SVD,也叫 RSVD。
这就是正则化后的 SVD,也叫 RSVD。
5.加入偏置的 SVD、RSVD
关于 SVD 算法的变种太多了,叫法也不统一,在预测式子上加点参数又会出来一个名称。由于用户对商品的打分不仅取决于用户和商品间的某种关系,还取决于用户和商品独有的性质,Koren 将 SVD 的预测公式改成这样
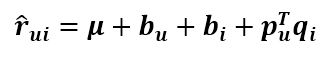 第一项为总的平均分,bu 为用户 u 的属性值,bi 为商品 i 的属性值,加入的这两个变量在 SSE 式子中同样需要惩罚,那么 SSE 就变成了下面这样:
第一项为总的平均分,bu 为用户 u 的属性值,bi 为商品 i 的属性值,加入的这两个变量在 SSE 式子中同样需要惩罚,那么 SSE 就变成了下面这样:
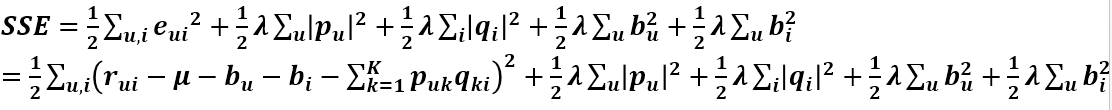 由上式可以看出 SSE 对 Puk 和 qik 的导数都没有变化,但此时多了 bu 和 bi 变量,同样要求出其更新式。首先求 SSE 对 bu 的导数,只有第一项和第四项和 bu 有关,第一项对 bu 的求导和之前的求导类似,用链式法则即可求得,第四项直接求导即可,最后可得偏导数为
由上式可以看出 SSE 对 Puk 和 qik 的导数都没有变化,但此时多了 bu 和 bi 变量,同样要求出其更新式。首先求 SSE 对 bu 的导数,只有第一项和第四项和 bu 有关,第一项对 bu 的求导和之前的求导类似,用链式法则即可求得,第四项直接求导即可,最后可得偏导数为
 同理可得对 bi 的导数为
同理可得对 bi 的导数为
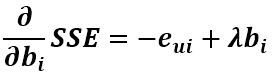 所以往其负梯度方向变化得到其更新式为
所以往其负梯度方向变化得到其更新式为
 这就是加入偏置后的 SVD(RSVD)。
这就是加入偏置后的 SVD(RSVD)。
6.Asymmetric-SVD(ASVD)
全称叫 Asymmetric-SVD,即非对称 SVD,其预测式子为
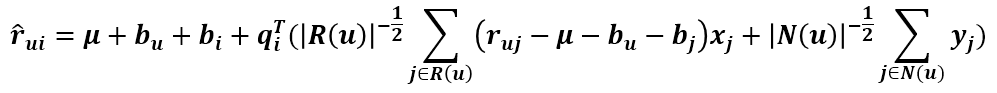 R(u)表示用户 u 评过分的商品集合,N(u)表示用户 u 浏览过但没有评过分的商品集合,Xj 和 Yj 是商品的属性。
R(u)表示用户 u 评过分的商品集合,N(u)表示用户 u 浏览过但没有评过分的商品集合,Xj 和 Yj 是商品的属性。
这个模型很有意思,看预测式子,用户矩阵 P 已经被去掉了,取而代之的是利用用户评过分的商品和用户浏览过尚未评分的商品属性来表示用户属性,这有一定的合理性,因为用户的行为记录本身就能反应用户的喜好。而且,这个模型可以带来一个很大的好处,一个商场或者网站的用户数成千上万甚至过亿,存储用户属性的二维矩阵会占用巨大的存储空间,而商品数却没有那么多,所以这个模型的好处显而易见。但是它有个缺点,就是迭代时间太长了,这是可以预见的,以时间换空间嘛。
同样的,需要计算其各个参数的偏导数,求出更新式,显然,bu 和 bi 的更新式和刚才求出的一样
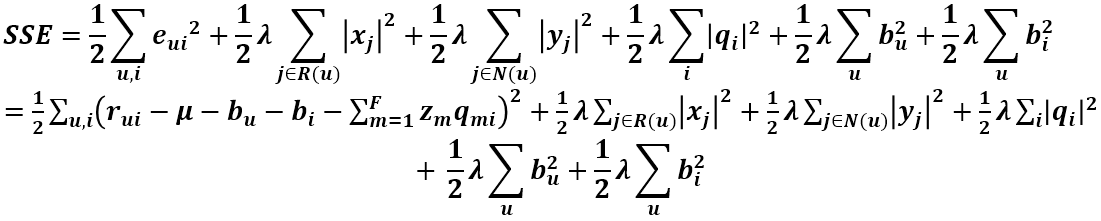 其中的向量 z 如下:
其中的向量 z 如下:
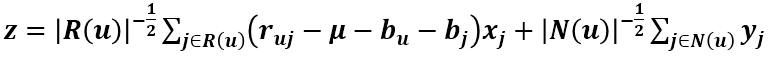 现在要求 qik、x 和 y 的更新式,在这里如果把 z 看成 Pu 则根据前面求得的更新式可得 qik 的更新式:
现在要求 qik、x 和 y 的更新式,在这里如果把 z 看成 Pu 则根据前面求得的更新式可得 qik 的更新式:
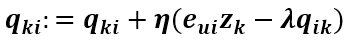 求 Xj 的导数需要有点耐心,SSE 的第二项对 Xj 的导数很容易得到,现在来求第一项对 Xj 的导数:
求 Xj 的导数需要有点耐心,SSE 的第二项对 Xj 的导数很容易得到,现在来求第一项对 Xj 的导数:
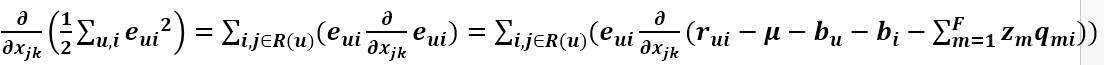 上式求和符号中的 i,j 都是属于 R(u)的,可以看到 Zm 只有当 m==k 时才与 Xjk 有关,所以
上式求和符号中的 i,j 都是属于 R(u)的,可以看到 Zm 只有当 m==k 时才与 Xjk 有关,所以
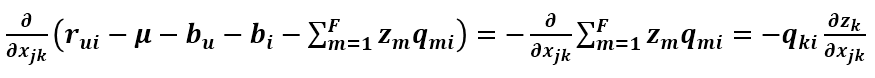 因为
因为
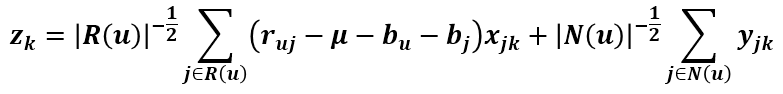 所以
所以
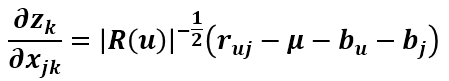 所以得到 SSE 对 Xjk 的导数为
所以得到 SSE 对 Xjk 的导数为
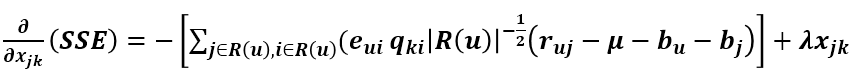 同理可得 SSE 对 Yjk 的导数为
同理可得 SSE 对 Yjk 的导数为
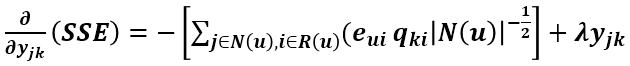 所以得到 Xjk 和 Yjk 的更新方程
所以得到 Xjk 和 Yjk 的更新方程
这就叫非对称 SVD(ASVD)
7.SVD++
这个模型也是 Koren 文章中提到的,SVDPlusPlus(SVD++),它的预测式子为
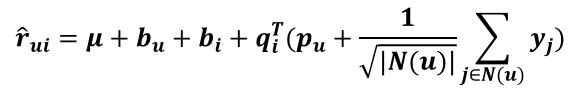 这里的 N(u)表示用户 u 行为记录(包括浏览的和评过分的商品集合)。看了 ASVD 的更新式推导过程再来看这个应该很简单,Puk 和 qik 的更新式子不变,Yjk 的更新式子和 ASVD 的更新式一样:
这里的 N(u)表示用户 u 行为记录(包括浏览的和评过分的商品集合)。看了 ASVD 的更新式推导过程再来看这个应该很简单,Puk 和 qik 的更新式子不变,Yjk 的更新式子和 ASVD 的更新式一样:
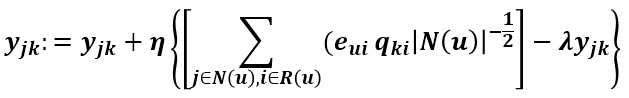 这些就是 Koren 在 NetFlix 大赛中用到的 SVD 算法
这些就是 Koren 在 NetFlix 大赛中用到的 SVD 算法
8.对偶算法
将前面预测公式中的 u 和 i 调换位置得到其对偶算法,对于 RSVD 而言,u 和 i 的位置是等价的、对称的,所以其对偶算法和其本身没有区别,但对于 ASVD 和 SVD++ 则不同,有时候对偶算法得到的结果更加精确,并且,如果将对偶算法和原始算法的预测结果融合在一起的话,效果的提升会让你吃惊!
对偶的 ASVD 预测公式:
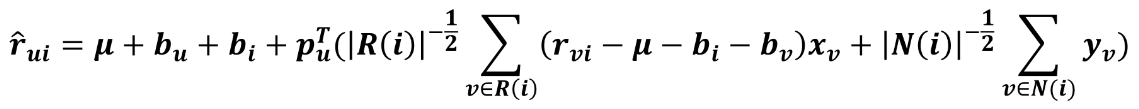 这里 R(i)表示评论过商品 i 的用户集合,N(i)表示浏览过商品 i 但没有评论的用户集合。由于用户数量庞大,所以对偶的 ASVD 会占用很大空间,这里需要做取舍了。
这里 R(i)表示评论过商品 i 的用户集合,N(i)表示浏览过商品 i 但没有评论的用户集合。由于用户数量庞大,所以对偶的 ASVD 会占用很大空间,这里需要做取舍了。
对偶的 SVD++ 预测公式:
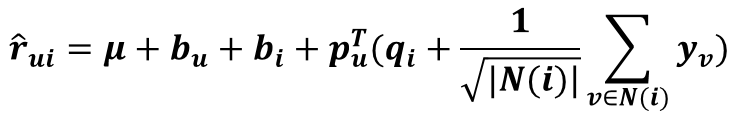 这里 N(i)表示对商品 i 有过行为(浏览或评分)的用户集合。
这里 N(i)表示对商品 i 有过行为(浏览或评分)的用户集合。
实现这一对偶的操作其实很简单,只要读取数据的时候把用户 id 和商品 id 对调位置即可,也就是将 R 矩阵转置后再训练。
9.SVD 实战
任务介绍:
数据集 :MovieLens100k 的 u1 数据 算法 :有偏置的 SVD(具体参数更新公式可以看第 5 部分) 评价指标 :RMSE
``` -- coding: utf-8 --
from future import print_function #引入python 3.x print函数 from future import division #精准除法
import numpy as np
def load_data(path): data = [] with open(name=path,mode='r') as file: for line in file: (user_id,moive_id,rating,time_stamp) = line.strip().split('\t') data.append([user_id,moive_id,rating]) data = np.array(data).astype(np.uint16) return data
重要变量 ave,bi,bu,qi,qu
核心参数 k(rank),gamma(学习速率),Lambda(正则项系数)
class SVD: def init(self,X,k=20): ''''' k is the length of vector ''' self.X=np.array(X) self.k=k self.ave=np.mean(self.X[:,2]) print("the train data size is ",self.X.shape) self.bi={} self.bu={} self.qi={} self.pu={} self.movie_user={} self.user_movie={} for i in range(self.X.shape[0]): uid=self.Xi mid=self.Xi rat=self.Xi self.movie_user.setdefault(mid,{}) self.user_movie.setdefault(uid,{}) self.movie_usermid=rat self.user_movieuid=rat self.bi.setdefault(mid,0) self.bu.setdefault(uid,0) self.qi.setdefault(mid,np.random.random((self.k,1))/10(np.sqrt(self.k))) self.pu.setdefault(uid,np.random.random((self.k,1))/10(np.sqrt(self.k))) def pred(self,uid,mid): self.bi.setdefault(mid,0) self.bu.setdefault(uid,0) self.qi.setdefault(mid,np.zeros((self.k,1))) self.pu.setdefault(uid,np.zeros((self.k,1))) if (self.qi[mid]==None): self.qi[mid]=np.zeros((self.k,1)) if (self.pu[uid]==None): self.pu[uid]=np.zeros((self.k,1)) ans=self.ave+self.bi[mid]+self.bu[uid]+np.sum(self.qi[mid]*self.pu[uid]) if ans>5: return 5 elif ans<1: return 1 return ans
def train(self,steps=20,gamma=0.04,Lambda=0.15): for step in range(steps): print('the ',step,'th step is running') rmse_sum=0.0 kk=np.random.permutation(self.X.shape[0]) #np.random.permutation(5) [3,1,2,0,4] 顺序打乱 for j in range(self.X.shape[0]): i=kk[j] uid=self.X[i][0] mid=self.X[i][1] rat=self.X[i][2] #参数更新 eui=rat-self.pred(uid,mid) rmse_sum+=eui 2 self.bu[uid]+=gamma (eui-Lambda self.bu[uid]) self.bi[mid]+=gamma (eui-Lambda self.bi[mid]) temp=self.qi[mid] self.qi[mid]+=gamma (eui self.pu[uid]-Lambda self.qi[mid]) self.pu[uid]+=gamma (eui temp-Lambda self.pu[uid]) #学习速率递减 gamma=gamma*0.93 print("the rmse of this step on train data is ",np.sqrt(rmse_sum/self.X.shape[0]))
def test(self,test_X): output=[] sums=0 test_X=np.array(test_X) print("the test data size is ",test_X.shape) for i in range(test_X.shape[0]): pre=self.pred(test_X[i][0],test_X[i][1]) output.append(pre) sums+=(pre-test_X[i][2])**2 rmse=np.sqrt(sums/test_X.shape[0]) print("the rmse on test data is ",rmse) return output
train_data = load_data('./ml-100k/u1.base') test_data = load_data('./ml-100k/u1.test')
svd = SVD(train_data,k=30) svd.train(steps=20,gamma=0.04,Lambda=0.15) svd.test(test_data) ```
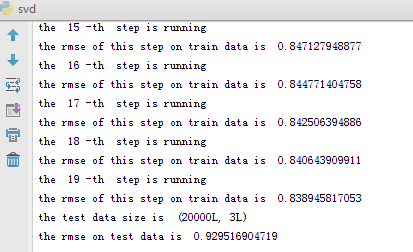
运行结果
参考文献
- 基于.NET平台的ETF终端设计与实现(吉林大学·刘健)
- 专题资源在线视频学习网站的设计与实现(电子科技大学·余浪)
- 面向人物简介的主题爬虫设计与实现(吉林大学·蒋超)
- Recommendation Algorithm Based on Blending Learning(华南理工大学·Malik Fayaz Ahmed)
- 工作流系统可预测异常处理的设计与实现(吉林大学·唐白)
- 异质网络中基于语义元路径的推荐系统研究与实现(北京邮电大学·张志强)
- 工作流系统可预测异常处理的设计与实现(吉林大学·唐白)
- 动漫衍生品设计研究与开发(天津科技大学·刘芳)
- 癌症体细胞突变致病性多维评估系统的开发与应用(东南大学·胡月)
- 异质网络中基于语义元路径的推荐系统研究与实现(北京邮电大学·张志强)
- 豆玩手机游戏平台的设计与实现(吉林大学·李天明)
- 偏微分方程有限差分法求解软件研发(宁夏大学·马天龙)
- 基于协同学的游戏衍生产品的设计与开发(燕山大学·吕洁)
- 豆玩手机游戏平台的设计与实现(吉林大学·李天明)
- 专题资源在线视频学习网站的设计与实现(电子科技大学·余浪)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头 ,原文地址:https://bishedaima.com/yuanma/35751.html









