
基于Python的拼音汉字转换程序
1、实验内容
-
利用统计语言模型实现拼音汉字转换
-
输入:拼音串,输出:对应的汉字串
-
给定10000字的测试语料,测试音字转换的准确率
-
针对音字转换结果中存在的问题给出具体分析
-
以图表的形式表示上述结果
2、实验要求和目的
-
自己准备词表
-
自己准备语料,规模应在一千万字以上
-
编程环境、汉字编码不限
3、实验环境
-
windows 10
-
Python 3.7.0
-
pypinyin 0.34.0
4、程序主要算法
4.1 HMM(隐马尔科夫模型)
马尔科夫假设
随机过程中各个状态St的概率分布,只与它的前一个状态St-1有关,即P(St|S1,S2,S3,…,St-1)= P(St|St-1)。
符合马尔可夫假设的随机过程称为马尔可夫过程,也称为马尔可夫链。在隐马尔科夫模型中,含有两条马尔科夫链:
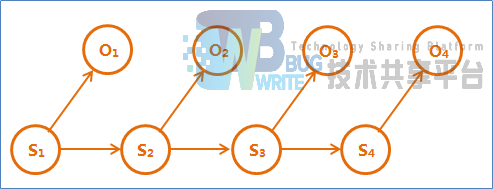
其中,S1,S2,S3,S4为隐含状态,O1,O2,O3,O4为观察到的序列在拼音转汉字实验中,拼音为观察的输出序列,而对应的汉字则为产生该输出的状态序列。拼音转汉字过程是寻找一个拼音序列所对应的汉字序列,并且该汉字序列的产生概率最大。我们可以将其描述为以下过程:给定一个模型和某个特定的输出序列,如何找到最可能产生这个输出的状态序列。该过程可以用维特比算法进行求解。
4.2 Viterbi算法
维特比算法运用了动态规划的思想,算法过程描述如下:
-
如果概率最大的路径P(或叫最短路径)经过某个点,比如下图中的X22,那么这条路径上从起始点S到X22的这一段子路径Q,一定是S到X22之间的最短路径。否则,用S到X22的最短路径R替代Q,便构成了一条比P更短的路径,这显然是矛盾的。
-
从S到E的路径必定经过第i时刻的某个状态,假定第i时刻有k个状态,那么如果记录了从S到第i个状态的所有k个节点的最短路径,最终的最短路径必经过其中的一条。这样,在任何时刻,只需要考虑非常有限条最短路径即可。
-
结合上述两点,假定当我们从状态i进入状态i+1时,从S到状态i上各个节点的最短路径已经找到,并且记录在这些节点上,那么在计算从起点S到前一个状态i所有的k个结点的最短路径,以及从这k个节点到Xi+1,j的距离即可。

Viterbi算法可以有效求出隐马尔科夫模型的最短路径(最大概率),且时间复杂度为(在拼音转汉字中,N为拼音个数,D为每个拼音对应的汉字个数,由于每个拼音对应的汉字个数是一定的,可视为常数,因此时间复杂度为O(N),满足要求)
5、实验过程
5.1 训练模型
训练集与测试集语料的格式如下:

每一行为单独的一句,不含有汉字以外的符号。在训练过程中,我们需要先得到每个字对应的拼音,然后根据对应关系获取字典,转移矩阵以及各汉字的发射概率,计算过程如下:
通过pypinying,获取每个句子对应的拼音:
python
PinYin = lazy_pinyin(words,errors="ignore")
典生成及发射概率计算:统计每个拼音所对应的所有汉字,并统计其出现频率,除以该拼音对应的汉字的总数,并存为json文件
生成的字典如下:
若在句子S中,汉字A与B满足,则A的转移转移矩阵中必包含B。统计A,得到所有的B,并根据其各自出现的频率计算转移矩阵中对应的概率大小,并存为json文件.
生成的转移矩阵文件格式如下:

训练模型时,读取的训练的语料为resource文件夹下的sentence.txt文件,运行 pretreament.py 文件,会将生成的字典存入resource文件夹下的dictionary.json文件中,将生成的转移矩阵存入resource文件夹下的transfermatrix.json文件中。
5.2 根据得到的模型完成拼音到汉字的转换
加载dictionary.json与transfermatrix.json,获取字典与对应发射概率,以及转移矩阵。并通过维特比算法完成求解,求得具有最大概率的中文序列(具体代码见Viterbi.py文件代码)
运行Viterbi.py文件可以查看效果(也可以手动输入测试用例,如pythonViterbi.py “wo shi shei”)
5.3 读取测试样本
生成对应的拼音,并调用Viterbi.py中的viterbi方法获取每个拼音对应的汉字,并与原本的汉字进行对比,计算准确率。
运行testViterbi.py文件,可以完成测试,默认的测试样本为resource文件夹下的test.txt文件,也可以通过参数指定测试样本文件。如:pythontestViterbi.py “resouce/test.txt”。
当拼音有多组汉字与之对应时,可以显示多个预选项。(按概率从大到小选择)
6、实验结果
6.1 拼音转汉字测试
拼音
ha er bingong ye da xue ji suan ji ke xue yu ji shu xue yuan
汉字
['哈尔滨工业大学计算机科学与技术学院', '哈尔滨工业大学计算机科学与技术学员', '哈尔滨工业大学计算机科学与技术学原', '哈尔滨工业大学计算机科学与技术学元', '哈尔滨工业大学计算机科学与技术学园']

拼音
zhe shi yige ce shi
汉字
['这是一个侧是', '这是一个测时', '这是一个测事', '这是一个测试', '这是一个侧适']

拼音
pin yin shuru fa
汉字
['拼音数如发', '拼音数如法', '拼音数入罚', '玭铟鉥洳乏', '玭铟鉥洳阀']

6.2 利用测试样本进行准确率测试(所有备选项中转换正确最多的个数)
| 备选项个数 | 准确率 |
|---|---|
| 1 | 0.7831163317294084 |
| 2 | 0.8022219077271441 |
| 3 | 0.8088734786300594 |
| 4 | 0.8121992640815171 |
当我们增加备选项时,可以看见,准确率有小幅度提高,因此,我们应当合理加入备选项。
6.3 结果分析
利用隐马尔科夫模型进行拼音转汉字是可行的,但是转换结果受到训练样本影响较大,语料的覆盖范围需要很广泛,否则在某些情况下结果较差。
在输入”zhe shi yi ge ce shi”时,由于训练样本中,“测试”一词出现的频率较低,因此,导致在将”zhe shi yi ge ce shi”转为汉字时,“这是一个测试”出现的概率也就偏低,与实际情况相反。因此,训练所用语料在选择时应当考虑全面。
在输入”pin yin shu ru fa”时,由于训练样本中没有“音输”两字相连的情况,因此,训练出的模型同样无法进行正确的转换。
7、实验结论和体会
在实现拼音转汉字时,所得结果受语料的影响较大。语料的覆盖应当要全面。同时,在面对不同需求时,我们应当用不同倾向的语料来进行训练,可以有效提高使用时的效率。
参考文献
- “乡妹纸”移动社交应用的设计与实现(南京大学·王凯)
- 基于Web的信息发布与信息交流平台的设计与实现(吉林大学·许昭霞)
- 文本综合处理平台的研究与实现(济南大学·王孟孟)
- 基于深度学习的中文文本校对算法研究与实现(西南交通大学·刘哲)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 基于J2EE平台的工作流管理系统的运行引擎和客户端及管理工具的设计与实现(西北大学·门浩)
- 基于J2EE架构的汉语学习游戏系统的设计与实现(电子科技大学·张银满)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 家族式汉字教学系统的设计与实现(山东大学·程继洪)
- 基于Lucene的商品垂直搜索引擎研究与实现(东华大学·潘磊宁)
- 基于B/S结构的图书销售管理系统的设计与实现(吉林大学·杨兴越)
- 基于J2EE架构的汉语学习游戏系统的设计与实现(电子科技大学·张银满)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 家族式汉字教学系统的设计与实现(山东大学·程继洪)
- 成语电子词典系统的设计与实现(电子科技大学·刘健)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码货栈 ,原文地址:https://bishedaima.com/yuanma/35489.html









