
基于ASR的语音词频提取云平台(python)
摘要
随着互联网的发展,语音文件成为了人们接触得越来越多文件。如何高效的从一段录音中提取出关键信息,提取出其中人们感兴趣的内容,直观的呈现给人门。而搭建一个语音词频提取的云平台可以很好的解决这些问题。从需求出发,学习阿里云平台的使用,搭建出了一个基于ASR的语音词频提取云平台。面向日常应用为商业、教育等领域提供关键信息提取的解决方案。
关键字: 云计算;语音识别;自然语言分词;
1.Introduction
1.1.概述
随着互联网的发展,诸如微信、soul等语音聊天软件的普及,人们接触到的语音文件的机会也越来越多。录音文件的途径也越来越多,应用场景也越来越方丰富。下面我们从以下几个不同的行业不同的场景进行需求分析。

1.2.商务
语音文件在商务领域可作为会议记录。会议的录音文件通常是作为会议的留档。企业可以通过会议录音文件的关键字提取从而对会议进行大致总结方便会议记录人员的工作。而一场会议的录音文件通常具有一下几个特点
-
录音时长长 : 企业会议时间都比较长,企业需要在会议中讨论和交代重要的商业战略,以及对过去的总结和未来规划,这需要花费相当长的篇幅进行梳理和总结。自然其对应的录音文件就比较长。
-
录音质量高 : 企业会议往往有有序的组织发言,不会出现多个人同时发言或者争论。会议环境也相对较好,安静的会议环境,
-
高度可概括 : 企业会议发言通常有事先组织草稿,并且进行结构的梳理。
具体场景: A公司B部门定期开办总结会议,会议内容会以录音的形式保存下来。部门领导需要秘书C进行会议的总结和梳理以方便部门领导进行后期的进程安排和项目指定。秘书C需要对语音文件进项处理,从中提取出关键要点信息。
1.3.教育
教育领域中,可以使用授课录音对教师教学的内容进行评估。教学录音通常具有一下几个特点。
-
时长固定 。一堂课的时间都是确定。
-
语音质量一般 。课堂中存在互动或者学生纪律不行会对录音文件的质量产生干扰。
具体场景:学校需要对教师的授课能能力进行评估。学校需要对教师的录音进行关键词提取作为教学质量的评测的估计。
1.4.刑侦
语音文件在刑侦领域通常是作为录音文件的取证。司法部门需要从审讯录音中获得关键信息,或者需要对一段语音通话文件分析其中的关键内容。这些可以获取词频,查看关键词进行预览。而司法取证的文件具有一下几个特点:
-
语音时长不确定 。由于取证的来源语音文件并没有确定的时长,可能长达几个小时,也可能只有几分钟。
-
语音质量没有保障 。由于通话或者录音的环境难以确定和保证,在刑侦领域接触到的语音质量不能得到很好的确认。可能包含干扰杂音或者受采集设备的限制,人声并不突出都是有可能的。
-
干扰项较多 。取证通常来自于日常的对话,存咋大量的无意义或者说没有价值的内容,关键信息并不能很方便的从里面提取出来。
具体场景:警方需要对犯罪嫌疑人A的进一个月的通话记录进行取证确认犯罪嫌疑人A的活动轨迹,对犯罪嫌疑人A进行刻画。警方需要对一个月采集到的通话录音进行大致关键信息的提取和判断。
1.5.国家安全
在国家安全领域,语音文件通常的应用场景为对可疑人员或者敏感单位的语音通话监听或者保密检查对音频文件的预处理。
-
信息量大 。如果是对一个敏感单位的所有人的语音通话进行监听而得到的语音文件内容量是十分庞大的。
-
不一定可读 。对于间谍可能采用内部的隐语进行交流。提取的结果并不一定是可读的。
-
语音时长不确定 。同样的录音时长并不能实现进行估计
-
干扰项较多 。来自生活录音的内容垃圾信息比较多,有很多我们并不关心的内容,高价值内容比较少。
具体场景:保密单位需要对单位内的电话机进行录音和定期进行保密检查。单位得到的数据量非常庞大,采取人工的方式进行检查效率很低。保密单位需要对庞大的文件进行大致的预处理,以便筛选出含有敏感内容的录音文件。
1.6.总结
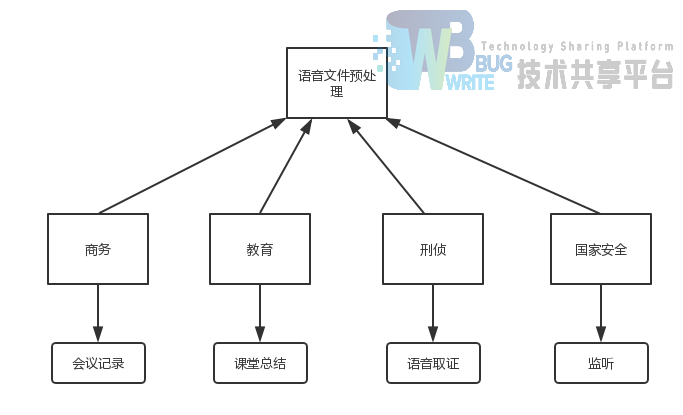
综上在商业、教育、刑侦、国家安全等四个领域中对于语音的不同的应用环境都需要对语音文件提取关键信息作为预处理,或者为其他行动做参考。由此可见语音关键字提取需求是广大的。
2.Implementation
2.1.实现的功能
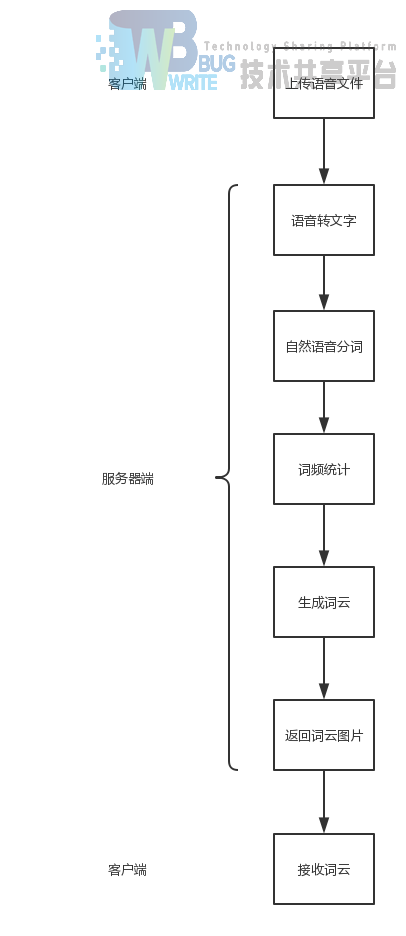
我们做的该云计算的项目是一个集云存储,云计算,以及网络通信于一体的项目,在客户端我们实现了可以从本地上传一个音频文件到云服务器上,存储在云服务器中。同时我们也实现了通过这个用这个上传到云服务器上的文件进行语音识别,返回语音识别的结果,并且在服务器中完成中文分词再进行绘制词云。通过通讯服务器与客户端的TCP连接,将词云图片发送给客户端。将转码的录音文件(采样率为16000或者是8000)上传至阿里云所提供oss平台(面向对象存储),并返回文件的URL,再用自己的服务器去阿里云的录音文件识别模块发出请求,识别录音文件,将文件的内容进行分词,生成一张词云返回至本地。
2.2.使用的环境
-
服务器端 :Linux:CentOS,阿里云服务器,轻量应用服务器
-
客户端 :Windows10,笔记本电脑
-
使用的语言 :Python 3
-
IDE :VisualStdio Code,
-
调用的第三方库 :aliyun-core,jieba,matplotlib,wordcloud
2.3.环境配置
-
服务器端的配置 :在阿里云上购买轻量应用服务器,将系统镜像导入服务器中。通过SSH与该服务器远程相连,开放服务器的某些端口用于TCP/UDP访问,通过Linux系统中的命令下载python安装包,并且通过pip命令安装必要的python第三方库。通过VIM写python代码。用python xxx命令运行py程序
-
客户端配置 :pip install PyQt5:安装qt5
-
pip install oss2 :安装阿里云oss
2.4.文件上传
阅读阿里云文档:
https://help.aliyun.com/product/31815.html?spm=5176.7933691.744462.c2.76576a56K0PaMH
其中有相当丰富oss(面向对象存储)的SDK介绍和环境配置,包括文件的上传,文件的下载,文件的管理,文件url的获取有详细的代码介绍。
2.5.通信
2.5.1.文件上传通信
2.5.2.通信服务器和客户端通信
通信服务器和客户端通信使用的是Socket套接字进行的通信,目的地址的ip为客户端选择的,如果服务器1的访问量过大,则选择备用服务器进行访问,提升了服务器的弹性。同时,在服务器端,我们使用的是多线程的Socket编程进行的通信,当连接完成时自动创建一个线程,当连接断开时自动释放该线程,尽可能的将能同时连接的客户端数量提高。
在图片的传输时,也是通过该连接进行的传递,先将文件的大小和名称打包传给客户端,让后将图片的各个KB依次传给客户端,客户端将其命名为new+原名称存储在本地的与工程文件相同的目录下,当然为了保证文件名称的不同,采用了一个随机函数,随机生成了一个有着精确到小数点后面十位的数字来命名图片的名称,保证了文件名称的不同。
2.7.分词并制作词云
2.7.1.分词
分词首先得先将获得的识别后的文本中不需要的内容删除。由于返回的文本文件时一个json文件,内容中有很多的英文单词作为标识,但时在分词中我们是不需要的,所以我们在进行分词之前首先得先把所有的英文单词标识给删除,这时我想所有的符号也是不需要的,所以我同时将他们中的所有的单词以及符号移出该文件。写入一个文本文件中,再用另一个类将这个文件读取出来,使用jieba进行中文分词,将其转为set的数据类型,将所有的重复的数据删除。
2.7.2.制作词云
使用分词获得的分词结果,数据类型为set,使用wordcloud库,将分词结果传入使用wordcloud建立的词云类,使用matplotlib进行绘画,画出这个词云并且写入一个图片文件中,至此分词以及制作词云就完成了。
2.8.界面的实现
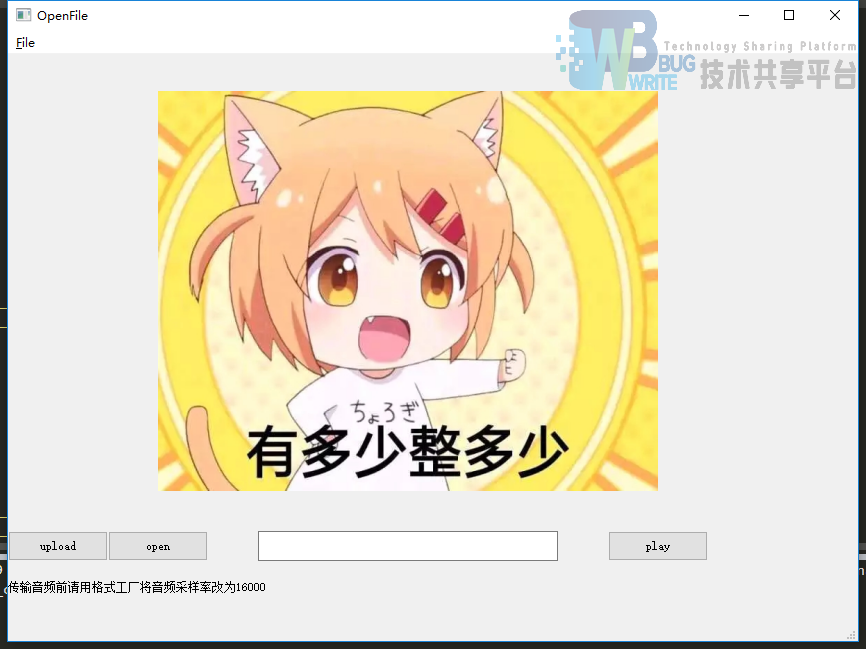
Open打开一个文件,选中文件之后,只读编辑框将会显示音频文件的本地,按钮play将会播放语音文件,upload则会通服务器建立连接上传文件、服务器通信、并将词云图片更新。
由于页面没有开多线程所以在上传文件的时候会卡住,请耐心等待。
3.Evaluation
3.1.体系结构
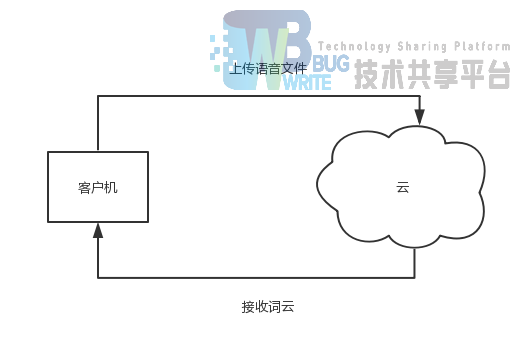
我们采用CS架构,由客户端向云平台传送语音文件,之后平台将词云返回给用户。
3.2.工作流程
3.3.实例
3.3.1.上传语音文件
上传一期新闻联播语音文件(采样率为16000HZ)
3.3.2.语音识别
云平台将语音转化为文字返回为JSON文件

3.3.1.最终结果
客户端收到最终的词云图片

4.Related Works
4.1.基于云平台的自然语言识别系统的设计
4.1.1.文献概要
针对一些嵌入式设备在特定的工作场景下无法实现语音识别的问题,提出了一种适用于嵌入式平台语音识别的解决方案。采用百度语音云平台提供的语音识别服务,对自然语言进行语音识别。通过对十个人的录音进行处理,进行测试和验证,准确性达到了93%[1]。
4.1.2.总结体会
虽然这篇文章使用的是百度云,但是里面的应用场景的分析以及测试方面给了我们很大的启发,为我们的测试环节提供了参考。让我们确定自己的研究方向,结合实际运用场景,搭建属于自己的云平台。
4.2.中文语音关键词检出技术研究
4.2.1.文献概要
该文献主要研究了分别用深度神经网络-隐马尔科夫模型(Deep Neural Network-Hidden Markov Model,DNN-HMM)和带有长短时记忆单元的循环神经网络(Long Short Term Memory RNN,LSTM-RNN)对中文声韵母进行声学建模,从而优化现有中文语音关键词检出系统性能。首先介绍了连续语音识别的框架与原理,包括语音信号的特征提取、语音信号声学建模技术、发音字典和语言模型以及基于加权有限状态转换器的语音解码网络。其次研究了基于连续语音识别器的语音关键词检出技术,包括基于网格结构建立索引、关键词搜索方法、关键词确认置信度以及语音关键词检出系统的评价指标。该文献还研究了一种中文语音关键词检出系统,此系统采用高识别率的声韵母进行声学建模和检索,通过查表法将输入汉字字符形式的关键字转化为声韵母进行关键词检出[2]。
4.2.2.总结体会
我们的关键词部分还需要进一步的完善,这篇文章很好的给我们指出了方向
参考文献
[1] 李登峰,王雷鸣,徐雪洁.基于云平台的自然语言识别系统的设计[J].信息技术,2017,(11):117-120.
[2] 侯云飞.中文语音关键词检出技术研究[D].南京理工大学,2017.
参考文献
- 基于知识图谱的文本-视频跨模态搜索系统的设计与实现(华东师范大学·倪麒开)
- 汉语词法分析平台的构建(大连理工大学·叶子语)
- 基于云服务的智能语音技术在智能家居中的应用(南京邮电大学·唐文凯)
- 基于SSM框架的语音管理平台的设计与开发(浙江工业大学·赵雨滴)
- 基于知识图谱的文本-视频跨模态搜索系统的设计与实现(华东师范大学·倪麒开)
- 基于大数据的语音导游数据仓库的设计与实现(华中科技大学·张学清)
- 汉语词法分析平台的构建(大连理工大学·叶子语)
- XX公安局执法音视频数据平台设计与实现(大连理工大学·李晓阳)
- 基于微服务与推荐算法的云课堂平台设计和实现(华东师范大学·杨磊)
- 基于云服务的智能语音技术在智能家居中的应用(南京邮电大学·唐文凯)
- 基于云服务的智能语音技术在智能家居中的应用(南京邮电大学·唐文凯)
- 基于云服务的智能语音技术在智能家居中的应用(南京邮电大学·唐文凯)
- 基于云计算模式的社会服务管理信息化平台项目设计与建设(吉林大学·杨刚)
- 基于人工智能的音视频内容检索系统的设计与实现(北京邮电大学·张金硕)
- 文本综合处理平台的研究与实现(济南大学·王孟孟)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设工厂 ,原文地址:https://bishedaima.com/yuanma/35450.html









