python数据分析(5)——数据预处理(下)
3. 数据变换
3.1 简单函数变换
常用的变换包括平方、开方、取对数、差分运算等

3.2 规范化
为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区别。
3.2.1 最小—最大规范化(离差标准化)
将数值映射到[0,1]
x'=(x-min)/(max-min)
3.2.2 零—均值规范化

3.2.3 小数定标规范化
将数值映射到[-1,1]

我们对同一个数据源使用三种规约化的方法进行对比。
代码data_normalization 数据集normalization_data.xls
```python
- - coding: utf-8 - -
数据规范化
import pandas as pd import numpy as np
datafile = 'normalization_data.xls' #参数初始化 data = pd.read_excel(datafile, header = None) #读取数据
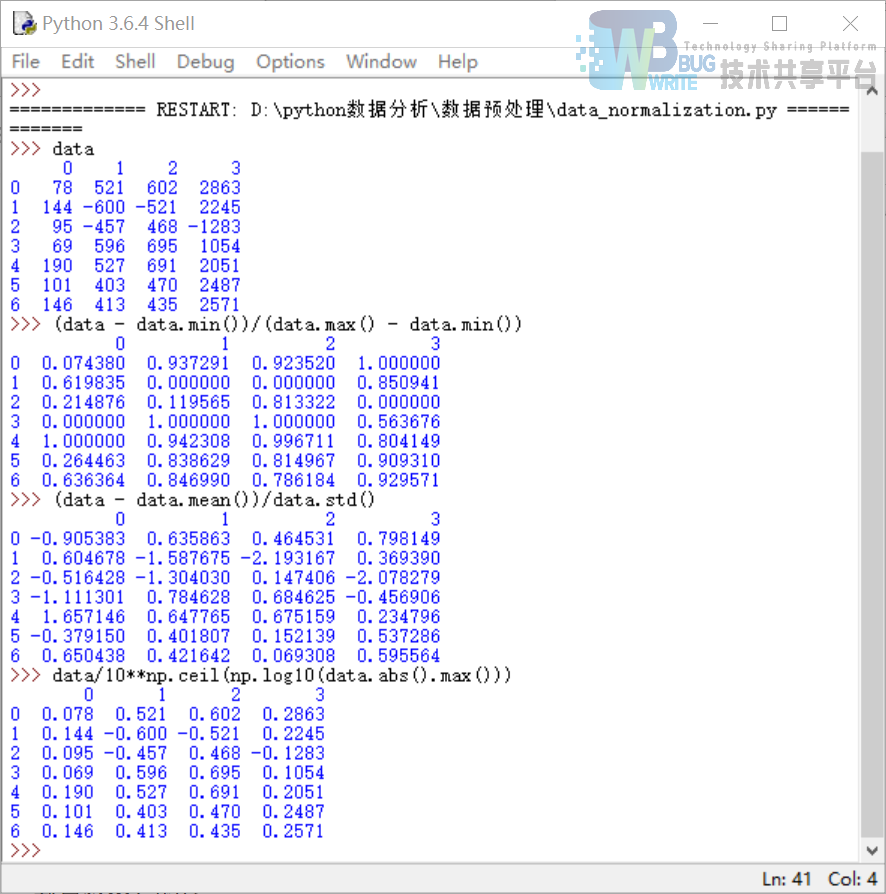
(data - data.min())/(data.max() - data.min()) #最小-最大规范化
(data - data.mean())/data.std() #零-均值规范化
data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
```
3.3 连续属性离散化
3.3.1 离散化的过程
确定分类数以及如何将连续属性值映射到这些分类值
3.3.2 常用的离散化方法
- 等宽法
将属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由用户指定。
- 等频法
将相同数量的记录放进每个区间。
- 基于聚类分析的方法
首先将连续属性的值用聚类算法进行聚类,然后再将聚类得到的簇进行处理,合并到一个簇的连续属性值并做同一标记。聚类分析的离散化方法也需要用户指定簇的个数,从而决定产生的区间数。
代码data_discretization 数据集discretization_data.xls
```python
- - coding: utf-8 - -
数据规范化
import pandas as pd
datafile = 'discretization_data.xls' #参数初始化 data = pd.read_excel(datafile) #读取数据 data = data[u'肝气郁结证型系数'].copy() k = 4
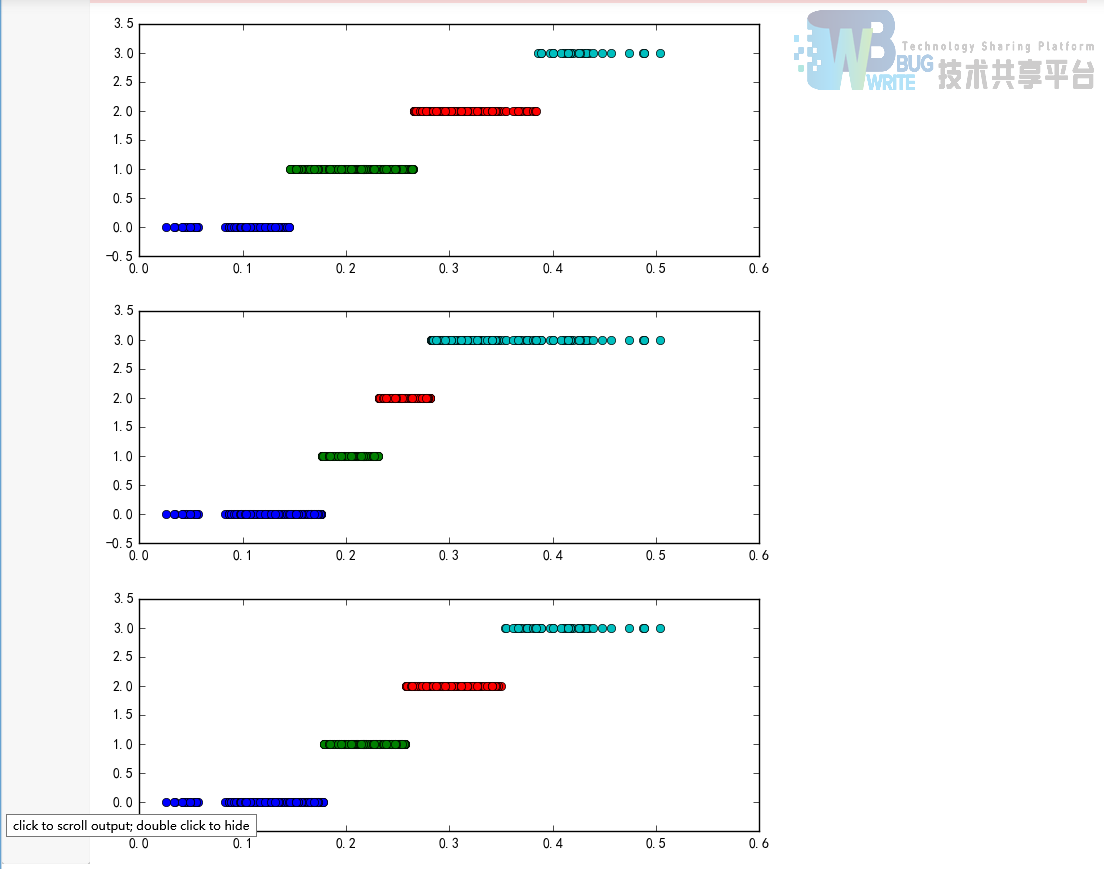
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
等频率离散化
w = [1.0 i/k for i in range(k+1)] w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数 w[0] = w[0] (1-1e-10) d2 = pd.cut(data, w, labels = range(k))
from sklearn.cluster import KMeans #引入KMeans kmodel = KMeans(n_clusters = k, n_jobs = 4) #建立模型,n_jobs是并行数,一般等于CPU数较好 kmodel.fit(data.values.reshape((len(data), 1))) #训练模型 c = pd.DataFrame(kmodel.cluster_centers_).sort(0) #输出聚类中心,并且排序(默认是随机序的) w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点 w = [0] + list(w[0]) + [data.max()] #把首末边界点加上 d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k): #自定义作图函数来显示聚类结果 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3)) for j in range(0, k): plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5) return plt
cluster_plot(d1, k).show() cluster_plot(d2, k).show() cluster_plot(d3, k).show() ```
3.4 属性构造
为更好的数据挖掘,需要利用已有的属性集构造出新的属性。 比如:线损率 = [(供入电量 - 供出电量)/供入电量] * 100% 线损率超过3%~15%,认为用户存在窃漏电行为。
代码为line_rate_construct 数据集
```python
- - coding: utf-8 - -
线损率属性构造
import pandas as pd
参数初始化
inputfile= 'electricity_data.xls' #供入供出电量数据 outputfile = 'electricity_data1.xls' #属性构造后数据文件
data = pd.read_excel(inputfile) #读入数据 data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) #保存结果 ```
3.5 小波变换
小波变换具有多分辨率特点,在时域和频域都有表征信号局部特征的能力,通过伸缩和平移等运算对信号进行多尺度聚焦分析,提供了一种非平稳信号的时频分析手段,可以由粗到细观察信号。
3.5.1 基于小波变换的特征提取方法


3.5.2 小波基函数
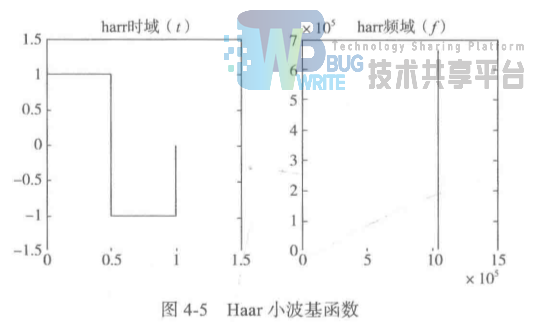
一种具有局部之集的函数,平均值为0,满足Ψ(0) = ∫Ψ(t)dt = 0. 常用的小波基有Haar小波基、db系列小波基。
3.5.3 小波变换
伸缩和平移变换:

3.5.4 基于小波变换多尺度空间能量分布特征提取方法
小波分析技术可以把信号在各频率波段中的特征提取出来,基于小波变化的多尺度空间能量分布特征提取方法是对信号进行频带分析,再分别以计算所得的各个频带的能量作为特征向量。
信号f(t)的二进小波分解可表示为:
f(t) = Aj + ΣDj
其中A是近似信号,为低频部分;D是细节信号,为高频部分,此时信号的频带分布如图:

信号的总能量为:
E = EAj + ∑EDj
选择第j层的近似信号和各层的细节信号的能量作为特征,构造特征向量:
F = [EAj, ED1 , ED2 , .......EDj]
利用小波变换提取出可以代表声波信号的向量数据,即完成从声波信号的特征向量数据的变换。本例利用小波函数对声波信号数据进行分解,得到5个层次的小波系数。
利用这些小波系数求得各个能量值,这些能量值即可作为声波信号的特征数据。
在python中,Scipy本身提供一些信号处理函数,但不够全面,更好的信号处理库是PyWaves(pywt)。
```python
- - coding: utf-8 - -
利用小波分析进行特征分析
参数初始化
inputfile= 'leleccum.mat' #提取自Matlab的信号文件
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它 mat = loadmat(inputfile) signal = mat['leleccum'][0]
import pywt #导入PyWavelets coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
返回结果为level+1个数字,第一个数组为逼近系数数组,后面的依次是细节系数数组
print(coeffs) ```
4 数据规约
数据规约产生更小但保持原数据完整性的新数据集。在规约后的数据集上进行分析和挖掘更有效。
4.1 属性规约
属性规约通过属性合并来创新属性维数,或删除不相关的属性(维)来减少数据维数,从而提高数据挖掘效率。
属性规约的目标是寻找出最小的属性子集并确保新数据子集的概率分布。
属性规约常用方法:
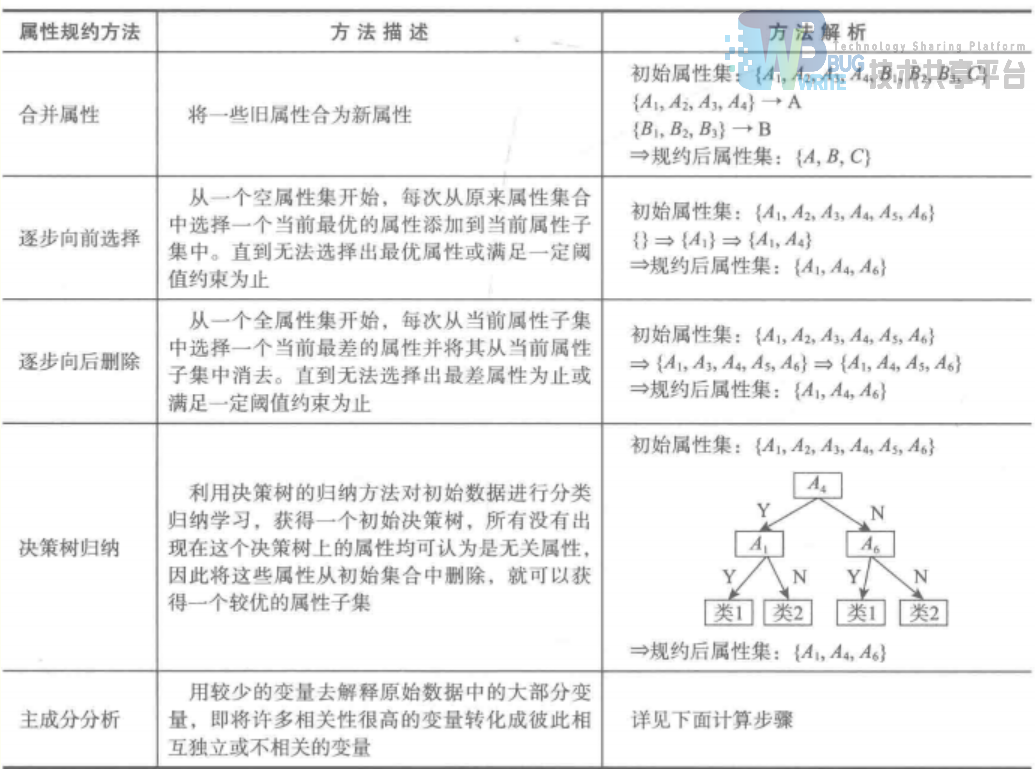
逐步向前选择,逐步向后删除和决策树归纳属于直接删除不相关属性(维)方法。
主成分分析是一种用于连续属性的数据降维方法,它构造了原始数据的一个正交变换,新空间的基底去除原始空间基底下数据的相关性,只需使用少数新变量就能解释原始数据大部分变异。

在python中,主成分分析的函数位于Scikit-Learn下:
sklearn.decomposition.PCA(n_components = None, copy = True, whiten = False) # decomposition 分解;components 成分;whiten 漂白
参数说明:
- n_components
意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n。
类型:int或者string,缺省时默认为None,所有成分被保留。赋值为int,比如n_components = 1,将把原始数据降到一个维度。赋值为string,比如n_components = 'mle',将自动选取特征个数n,使得满足所要求的方差百分比。
- copy
类型:bool,True,False,缺省时默认为True。
意义:表示是否在运行算法时,将原始训练数据复制一份。若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会变,因为是在原始数据上进行降维运算。
- whiten
类型:bool,缺省时默认为False。
意义:白化,使得每个特征具有相同的方差。
使用主成分分析降维的程序代码如下:
```python import pandas as pd
参数初始化
inputfile = 'principal_component.xls' outputfile = 'dimention_reducted.xls' # 降维后的数据
data = pd.read_excel(inputfile, header = None) # 读入数据
from sklearn.decomposition import PCA
pca = PCA() pca.fit(data) print(pca.components_) # 返回模型的各个特征向量 print(pca.explained_variance_ratio_) # 返回各个成分各自的方差百分比; variance(方差); ratio(比率) ```
4.2 数值规约
- 直方图
- 聚类
- 抽样
- 参数回归# python数据分析(5)——数据预处理(下)
参考文献
- 基于商品名称的电商平台商品自动分类的研究与实现(西南交通大学·黄超)
- 文本综合处理平台的研究与实现(济南大学·王孟孟)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
- 基于Django的模型参数分析系统的设计与实现(南京大学·府洁)
- 数据统计分析应用软件的研究与实现(西安工程大学·贺艳琴)
- 零售业大数据下载与分析系统的设计与实现(西安电子科技大学·吴霜)
- 运营商网络监测数据分析管理系统设计与实现(西安电子科技大学·成天旸)
- 基于云计算的用户网络行为挖掘分析系统的研究与设计(湖北大学·皮健夫)
- 基于Web使用挖掘的在线报名推荐系统的研究与实现(电子科技大学·王玥)
- 基于商品名称的电商平台商品自动分类的研究与实现(西南交通大学·黄超)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
- 数据统计分析应用软件的研究与实现(西安工程大学·贺艳琴)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
- 音视频数据获取与同源性分析关键技术研究(电子科技大学·范清宇)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码项目助手 ,原文地址:https://bishedaima.com/yuanma/35391.html