JSP实现基于Lucene框架的实时全文检索系统
摘 要
全文检索技术是现代信息检索的核心技术,它能够根据数据资料的内容而不是外在特征来进行信息检索,是在海量数据中快速、准确的找到所需要信息的一种有效手段。ApacheLucene是一个纯Java实现的高性能、可扩展的全文检索类库,设计初衷就是为需要搜索功能的应用程序提供索引和全文检索的能力。本文深入研究了全文检索的核心技术、倒排索引创建过程,相似度评分机制等。并研究了Lucene源码结构和逻辑结构,分析了Lucene的工作原理,在此基础上基于Lucene构建了一个实时全文检索系统框架。并针对普通类型的文档索引提供了默认实现。该系统既可以方便的嵌入到需要全文检索能力的各种应用中,同时还可以基于此系统开发定制个性化的全文检索引擎。最后通过实验测试了系统的索引和检索效率,并提供了一个简易的Web站内搜索应用实例。
关键词 :全文检索;Lucene;REST架构;实时检索
ABSTRACT
Full-textinformation retrieval is the core technology of modern information retrieval,which takes a variety of computer data as input, text, voice, images etc. Itprovides a way of information retrieval based on the content rather than theexternal features. This technology can help people manage a lot of documentsand enable them to find any information they want quickly and easily. ApacheLucene (TM) is designed for applications that requires full-text searchcapabilities, especially cross-platform. In this paper, first introduced thecore technology of full-text information retrieval, Lucene code structure andlogical structure, analyzed how Lucene works. Then build a near-real-timefull-text information retrieval system based on Lucene by using RESTarchitecture. The system can be easily embedded into applications that requiresfull-text search capabilities. You can also customize personalized full-textsearch engine based on this system. Finally, this paper gave the indexing andretrieval time of this system through experiments, and provided a simpleexample of Web search application.
Key words :Full-text information retrieval;Lucene;REST;Near-Real-Time
1 引言
1.1 研究背景和现状
近些年来,随着移动互联网、社交网络和电子商务的发展,互联网数据量正迅速激增,已经由TB级别跃升到了PB级别。从总体上对互联网环境下的数据进行上划分,可分为两类: 结构化数据和非结构化数据。结构化数据是指具有固定格式或有限长度的数据,如:数据库数据;非结构化数据指不定长或无固定格式的数据,如:纯文本、图片像、音视频数据、以及各种类型文档等。还有一种介于前两种数据类型之间的数据称之为半结构化数据,例如:XML,HTML等。半结构化数据可既可以按照结构化数据来处理,也可通过处理后按照按非结构化数据来处理。互联网极大的方便了我们的生活,但是数据量的爆发式增长,为我们在如此海量数据中找到所需要的信息提出了难题。
目前,大部分网站或者其它应用对用户提供的搜索功能,是通过使用SQL语句中的Like子句进行关键字查询。这种方法本质上是一种简单的字符串匹配算法,对系统性能影响极大。当数据规模达到一定程度,这种性能低下的搜索方法更加让人无法接受。全文检索技术的出现,为解决这一问题提供了有效途径。全文检索技术是检索非结构化数据的强大工具,它是现代信息检索的核心技术之一。以全文检索为核心技术的搜索引擎例如Google、百度等早已成为我们生活中不可获取的工具。
1.2 本文的工作和意义
本文首先介绍了全文检索技术的概念以及核心技术,并着重介绍了一个开源全文检索类库——Lucene[1]。Lucene是一个高性能的、可伸缩的全文检索类库,具有非常优秀的系统架构。它的贡献者是一位资深全文检索专家。Lucene遵守Apache License 2.0 协议,是开源世界一个典范,这些特点使得它成为我们学习全文检索的核心技术的不二之选。本文深入研究了全文检索的基本原理,并对Lucene源码和逻辑结构进行了深入分析,总结了Lucene的工作原理。最后,结合Lucene并采用REST[3][4]架构构建了一个实时全文检索系统,并提供了一个简易的Web站内搜索应用实例。该系统既可以方便的嵌入到需要全文检索能力的各种应用中,同时还可以基于此系统开发定制个性化的全文检索引擎。
1.2 论文结构与内容安排
本文正文部分除前言外还有6章。
- 第二章:信息检索技术概述:本章对信息检索技术的发展历程以及全文检索技术基本原理进行了简单介绍。
- 第三章:Lucene 架构与工作原理:本章详细的研究和分析了Lucene的系统架构,源码组织和工作原理。
- 第四章:实时全文检索系统设计与实现:本章重点说明了实时全文检索系统的设计方案与实现方式。
- 第五章:性能测试:本章对系统的索引吞吐量、搜索响应时间、查全率查准率等各项指标进行了测试与说明。
- 第六章:部署和接口扩展:本章以Eclipse为例,对系统的部署和集成方式以及如何对接口进行扩展进行了说明介绍。
- 第七章:总结与展望:本章总结全文,分析了系统的缺陷之处,并对未来针对本项目的工作进行了说明。
2 信息检索技术概述
2.1 信息检索技术定义
信息检索(Information Retrieval,IR)是指从原始的非结构化数据(通常是纯文本)组成的文档集合中查找满足另一个条件集合中条件的信息的过程。[5]
2.2 信息检索技术发展历程
信息检索技术的发展历程,大致可以划分为以下四个阶段:
- 手工检索阶段:发展于19世纪末,专业化的信息检索工作产生于咨询参考工作。
- 联机批处理阶段:利用计算机来进行相关信息片段的搜索工作这个想法最早Vannevar Bush于1945年在他的文章《As We May Think》提出[6]。第一个自动化的信息检索系统产生于20世纪50至60年代。到1970年时已经出现了多种有效的针对小型文档集合的检索方法。此阶段主要采用批处理方式。
- 联机检索阶段:1971年以后,产生了联机情报检索系统,如OCLC。
- 网络化联机检索阶段:1992年美国国防部和美国国家标准与技术研究院(NIST)共同举办的文本信息检索会议(TREC)中商讨了如何将信息检索技术应用于大规模文本集合的问题,并由此催生了网络搜索引擎。
全文检索技术是信息检索技术最前沿和目前的最高级阶段。
2.3 全文检索技术
全文检索(Full-textRetrieval)技术是一种将文件中所有文本与检索项匹配的文字资料检索方法。它以各种计算机数据如文字数据、音视频数据等作为输入,根据数据的内容而不是外在特征来进行信息检索。它为全文集合建立一个能精确定位每个有意义的字词的索引,然后通过此索引进行搜索。不仅能够缩减搜索资料库而且能够显著提高检索准确度和检索效率。
2.4 全文检索系统
全文检索系统就是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般具有创建索引、执行搜索请求、优化索引结构等功能。
2.5 全文检索技术原理
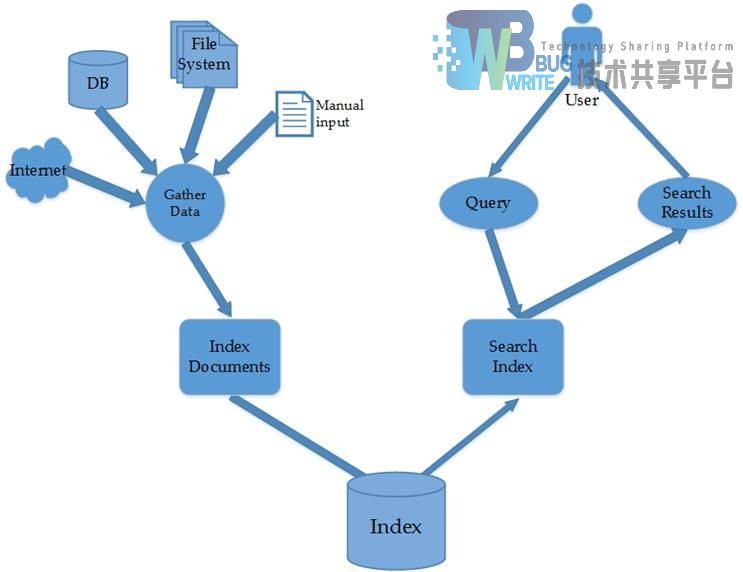
全文检索技术通过使用文档的片断信息得到原始内容在原始文档中的定位。其主要过程分为两个,创建索引(Indexing) 过程和搜索索引(Search)过程:
- 创建索引:从原始数据中提取信息,创建索引的过程;
- 搜索索引:根据用户的检索请求,搜索已经创建的索引并返回搜索结果的过程。
一般全文检索的过程如图2-1所示:
2.5.1 倒排索引
倒排索引(inverted index)是目前最成熟的全文索引实现技术,其核心思想是通过把原文档是一系列词汇单元的集合,通过对原文档进行分解,生成词汇单元集合,并记录每一单元在文档中出现的次数、频率以及位置信息,并将这些词汇单元组织成高效的数据结构,以此数据结构反向检索其所在的原始文档。
倒排索引所保存的信息一般如下:假设有一个编号从1到100的文档集合。倒排索引示例结构图如图2-2所示:

左边的一系列字符串,称为词典。词典包含指向词本身所在文档链表的指针,这个链表被称之为倒排表(Posting List)。当我们要寻找既包含字符串“China”又包含字符串“Hello”的文档,我们要针对索引进行以下几步操作:
- 找出包含“China”的链表;
- 找出包含“Hello”的链表;
- 通过对链表进行合并,找出既包含“China”又包含“Hello”的文档。
2.5.2 倒排索引的建立
全文检索的倒排索引创建过程一般有以下几步:
1.准备原始文档
为了方便说明索引创建过程,这里用两个英文文档为例:
- 文档1:Students should be allowedto go out with their friends, but not allowed to drink beer.
- 文档2:My friend Jerry went toschool to see his students but found them drunk which is not allowed.
2.分词处理
分词(Tokenizer)就是要将文档内容分为一个一个单词(词语单元)。主要步骤包括去除标点符号、去除停词(Stop Word)等。分词后得到的结果称为词元(Token)。在我们的例子中,经过分词处理便得到以下词元:
- 文档1:”Students“,“allowed”,“go”,“their”,“allowed”,“drink”,“beer”,“friends”,“My”,“friend”
- 文档2:“Jerry”,“went”,“school”,“see”,“his”,“students”,“them”,“drunk”,“found”,“allowed”
3.语言处理
语言处理就是对词元进行一些同语言相关的处理。英语语言处理处理组件(LinguisticProcessor)一般做以下几点:
- 大写变小写;
- 缩减成词根形式,如“apples”到“apple”等。又称为:stemming。
- 单词转变成词根形式,如“has”到“have”等。又称为:lemmatization。
经过语言处理的结果称为词(Term)。在我们的例子中,经过语言处理,得到的词如下:
- 文档1:“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”
- 文档2:“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”
4.建立索引
将由经过语言处理后产生的词传递给索引组件进行索引时需要经历如下步骤:
- 利用得到的词,创建一个词典,所得词典表如表2-1所示;
| Term | Document ID |
|---|---|
| student | 1 |
| allow | 1 |
| go | 1 |
| their | 1 |
| allow | 1 |
| friend | 1 |
| drink | 1 |
| beer | 1 |
| my | 1 |
| friend | 1 |
| jerry | 2 |
| go | 2 |
| school | 2 |
| see | 2 |
| his | 2 |
| student | 2 |
| find | 2 |
| them | 2 |
| drink | 2 |
| allow | 2 |
- 对上述词典按字母顺序降序排列之后的结果如表2-2所示;
| Term | Document ID |
|---|---|
| allow | 1 |
| allow | 1 |
| allow | 2 |
| beer | 1 |
| drink | 1 |
| drink | 2 |
| find | 2 |
| friend | 1 |
| friend | 1 |
| go | 1 |
| go | 2 |
| his | 2 |
| jerry | 2 |
| my | 1 |
| school | 2 |
| see | 2 |
| student | 1 |
| student | 2 |
| their | 1 |
| them | 2 |
- 最后合并相同的词形成倒排表,倒排表示例如图2-3所示。
在图2-3示中,有几个定义:
- Document Frequency:文档频次,表示总共有多少文件包含此词。
- Frequency :词频,表示此文件中包含了多少个此词。
倒排表建立好之后需要索引组件写入到倒排文件(Inverted File)中。
2.5.3 搜索索引
当文档数量较少时,我们能够比较容易的检索到自己需要的文档。但是当文档数量上升到一定程度后,如何找到我们最想的文档就是一件比较棘手的事情了。搜索索引需要解决的一个问题就是如何找到和查询语句最相关的文档。一般情况,搜索索引分为以下几步:
- 用户输入查询语句(Query);
- 查询语句处理;
- 搜索索引;
- 根据相关性排序。
2.5.4 查询语句
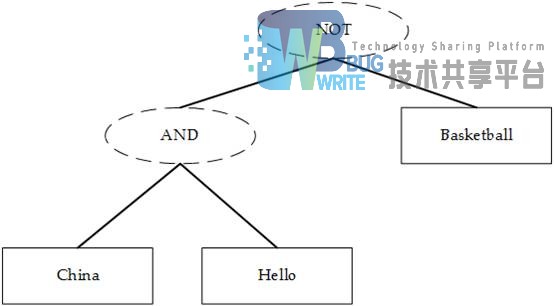
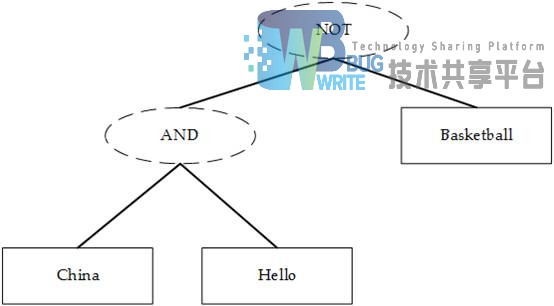
查询语句同我们普通的语言一样,具有一定语法。查询语句决定了查询结果,定义了搜索索引时对结果的筛选方式。查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND,OR,NOT 等。例如:“China AND Hello NOT Basketball”表示查找既包含“China”又包含“Hello”同时不包含“Basketball”的文档。
2.5.5 查询语句处理
对查询语句进行处理主要步骤包括词法分析,语法分析,及语言处理。
1.词法分析
查询语句的词法分析主要用来识别单词以及关键字。如上述例子中,经过词法分析,得到单词有China,Hello,Basketball,关键字有AND以及NOT。当在词法分析过程中发现非法的关键字时,会产生解析错误。当关键字拼错的时候,错误的关键字会被当做一个普通单词被查询。
2.语法分析
语法分析主要是根据查询语句的语法规则来形成一棵语法树。例如上述例子形成的语法树如图2-4所示:
3.语言处理
语言处理同索引过程中的语言处理几乎相同,主要将大写变小写,复数变单数等。
2.5.6 搜索
搜索索引就是对已经建立好的索引进行查询操作,最后得到符合查询语法树的文档。可分为以下几步:
- 首先在倒排索引中找到包含china、hello和basketball的链表;
- 其次对包含china和hello的链表进行合并操作,得到既包含china又包含hello的链表;
- 最后将合并后的链表与包含basketball的链表进行差操作,从而得到既包含china又包含hello,同时不包含basketball的链表;
- 返回上述进行差操作后的链表。
2.5.7 相关性计算模型
在上一步中,我们得到了符合语法树的文档,但并非一定是符合用户期望的。所以需要对检索结果按照一定规则进行排序。排序的依据是按照结果与与查询语句的相关性,相关性高者排名靠前。目前对于相关性排序有多种计算模型,在本文中只介绍如下三种模型:
1.布尔模型(Boolean Model)
早期的信息检索系统使用的主要模型。布尔模型根据文档中是否出现关键词来判断文档是否相关,所有相关文档与查询的相关程度都是一样的,所以不支持相关性排序。
2.向量空间模型(Vector Space Model)
向量空间模型主要采用向量的方式进行计算,此模型将文档和用户查询语句分别转化为向量形式,然后通过计算两个向量的夹角余弦,根据余弦值的大小对所得文档进行排序。是目前主要使用的一种相关性排序方法。
3.概率模型(Probabilistic Model)
概率模型通过估计文档与查询相关联的概率,根据关联概率对所有文档进行排序。
2.6 空间向量模型原理与实现
2.6.1 文档的向量表示
在向量空间模型中,文档指的是通常意义上的计算机记录,用D(Document)来表示。一篇文档主要由词(Term,用t表示)或者短语构成,文档可以用词构成的向量表示为:
D(t1, t2, t3, ..., tn),tk是第k个词,1<=k<=n
2.6.2 词的权重及计算
对于含有n个词的文档来说,通常会给予每个词一定的权重表示其对于这篇文档的重要程度。用W(weight)来表示,即:
D=D(t1, w1, t2, w2, t3, w3, ..., tn, wn),其中wk是tk的权重,1<=k<=n
简记为:
Dw(w1, w2, ..., wn)
计算词的权重就是找出该词对某个文档的重要性的过程。主要有两个参数,第一个是词,第二个是文档。影响一个词在一篇文档中的重要性主要有两个因素:Term Frequency(tf)和Document Frequency (df) [1]:前者tf用于形容一个词在文档中出现的频次,tf越大说明此词越重要;df表明有多少文档包含此词。df越大说明此词越不重要。权重的计算公式:
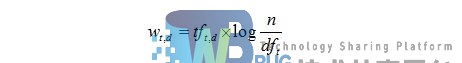
wt,d表示一个词t在文档中的权重,ft,d表示词在文档中出现的频次,n代表文档总数,dft表示包含单词t的文档数目。
这只是计算词权重的基本实现,不同的全文检索算法会有不同的实现。
2.6.3 向量空间模型计算方法
在向量空间模型中,两个文本D1和D2之间的内容相关度Sim(D1, D2)就是两个向量之间夹角的余弦值,公式为:

其中,w1k和w2k分别表示文档D1和D2中第k个词的权重。
将文档看作由词组成,每个词都有对应的权重。我们把所有词的权重视为一个向量:
D=D(t1, t2, t3, ..., tn)
Dw=Dw(w1, w2, w3, ..., wn)
同样我们把查询语句看作一个简单的文档,也用向量来表示:
Q=Q(t1, t2, t3, ..., tn)
Qw=Qw(w1, w2, w3, ..., wn)
我们把搜索出的文档向量以及查询向量一起放置于一个N 维空间中。向量空间模型计算方法如图2-5所示:
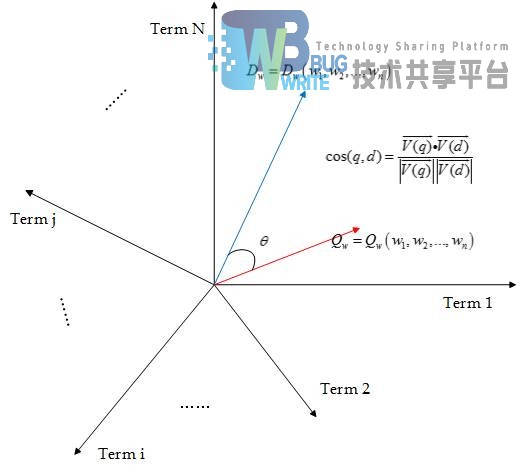
向量空间模型算法认为两个向量之间的夹角越小,表示相关性越大。所以可以通过计算两个向量的夹角的余弦值来计算文档之间的相关性。夹角越小,余弦值越大,分值越高,表示相关性越大。相关性打分公式如下:
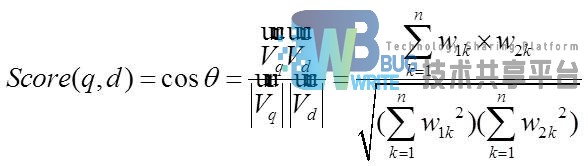
3 Lucene架构与工作原理
3.1 Lucene简介
Apache Lucene是一个高性能的、功能全面、可伸缩的全文检索类库。它并非是一个完整的全文检索引擎,只是一个全文检索引擎的架构,它100%由 Java语言实现。非常适用于跨平台应用程序[1]。开发者可以根据不同的需要对Lucene进行扩展。
作为开源项目中的一个典范,Lucene自问世就吸引了广大技术人员的亲睐,开发者们通过研究它而得以一窥全文检索的核心技术,并且用它来构建各种类型的应用,一些商业软件同样选择了Lucene。知名的例如,Apache的官方网站采用Lucene作为其全文检索引擎;开源软件eclipse也采用Lucene作为其帮助子系统的全文索引引擎。 Lucene作为一个全文检索引擎,具有如下突出的优点[1]:
1.高性能的索引能力
- 在现代基本的硬件条件下,针对纯文本拥有超过150GB/小时的索引速度;
- 内存占用约1MB的堆内存;
- 增量索引速度堪比批处理索引速度;
- 索引只占原始数据的20%-30%大小。
2.强大、精确有效的搜索算法
- 搜索结果排序,最好的结果排名最高;
- 支持多种查询方式;
- 可按任意域排序结果;
- 可同时对多个索引进行搜索,结果会进行归并;
- 支持高亮显示结果等后续处理;
- 可插播的相关性计算模型(排名计算模型),包括向量空间模型等;
- 可配置的存储引擎。
3.开源、跨平台实现
- 遵守Apache License 2.0协议;
- 100% 纯Java语言实现;
- 索引文件格式独立于应用平台;
- 分块索引功能,拥有索引合并功能;
- 独立于语言和文件格式的文本分析接口;
- 优秀的面向对象的系统架构,学习使用成本低。
本文中Lucene对应的版本为4.3.0,下文不再对此进行说明。
3.2 Lucene系统架构与源码组织
3.2.1 源码与架构
Lucene具有非常优秀的系统架构与良好的编码规范,是面向对象设计的一个典范。它定义了一种与平台无关的以8位字节为基础的索引文件格式,通过面向对象程序设计技术将系统的核心组件进行多层包装。最终形成了一个高内聚、低耦合、高效率的全文检索引擎。Lucene的系统结构与源码结构如图3-1所示。
从图中我们可以看到,7个主要模块组成Lucene的核心,各个模块所属的系统部分也如图所示。Lucene主要模块对应的包以及功能如表3-1所示:
| 包名称 | 功能 |
|---|---|
| org.apache.lucene.analysis | 这个模块主要提供对文档进行分词处理的支持。 |
| org.apache.lucene.codecs | 提供了一些类和方法用于编码和解码索引。 |
| org.apache.lucene.document | 对将原文档封装成可供Lucene索引的Document对象提供支持。 |
| org.apache.lucene.index | Lucene的核心模块之一,用于创建索引。 |
| org.apache.lucene.search | Lucene的核心模块之一,对搜索索引提供支持。 |
| org.apache.lucene.store | 提供用于将生成的索引持久化的功能。 |
| org.apache.lucene.util | 包含一些基础数据结构以及工具类。 |
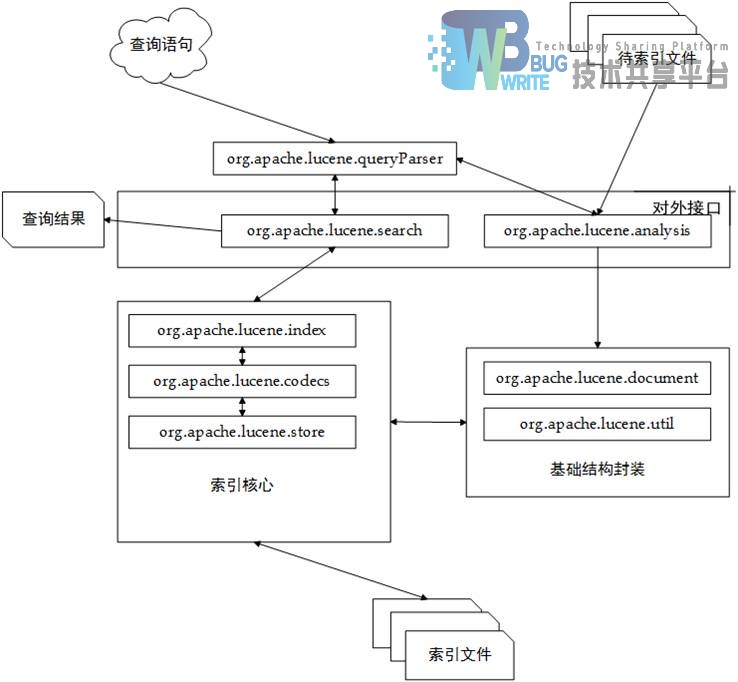
Lucene具有非常低的耦合度,这充分体现了开发者深厚的技术功底。从学习角度而言,这样的系统结构以及设计模式使得Lucene的实现容易理解,从可扩展性角度而言,低耦合,只对外提供必要的接口,这十分有利于扩展。
Lucene在系统结构上的另一个特点就是可嵌入性。Lucene可以作为一个jar库被添加到进入应用中去。这会极大方便应用程序的开发,同时也体现了Lucene的设计初衷。
3.2.2 主要类介绍
为了说明Lucene对外提供的接口(开发者应该关注的类),以及进一步了解Lucene的工作原理,现对Lucene的主要类及功能如表3-2所示:
| 类 | 所属包 | 主要功能 |
|---|---|---|
| Document | org.apache.lucene.document | Document 是用于描述文档的。一个 Document 对象由多个 Field 对象组成的。 |
| Field | org.apache.lucene.document | Field 对象是用于描述一个文档的某个域的属性。 |
| Analyzer | org.apache.lucene.analysis | 用于对文档进行分词处理。 |
| IndexWriter | org.apache.lucene.index | IndexWriter 是 Lucene 用来创建索引的一个核心的类,通过将Document对象添加到此类中用以生成索引结构。 |
| IndexReader | org.apache.lucene.index | IndexReader用于读取索引文件的内容。 |
| Directory | org.apache.lucene.index | 抽象了 Lucene 的索引的存储的位置。 |
| Query | org.apache.lucene.search | 这是一个代表查询对象的抽象类目的是把用户输入的查询字符串封装成 Lucene 能够识别的 Query。 |
| Term | org.apache.lucene.search | Term 是搜索的基本单位。 |
| TermQuery | org.apache.lucene.search | TermQuery 是抽象类 Query 的一个子类,是最为基本的一个查询类。 |
| IndexSearcher | org.apache.lucene.search | IndexSearcher 是用于在建立好的索引上进行搜索。 |
| Hits | org.apache.lucene.search | Hits 是用于保存搜索的结果的 |
3.3 索引文件
理解Lucene的索引文件的格式是深入理解Lucene工作原理的一种有效方式。Lucene 的索引过程,就是按照全文检索的基本原理,将文档分词处理后生成将倒排表,并将倒排表写成索引文件的过程。Lucene 的搜索过程,就是根据索引文件的写入格式将索引进去的信息读出来,并对搜索结果打分(score)排序的过程。一个Lucene索引如图3-2所示:
3.3.1 索引文件基本数据类型
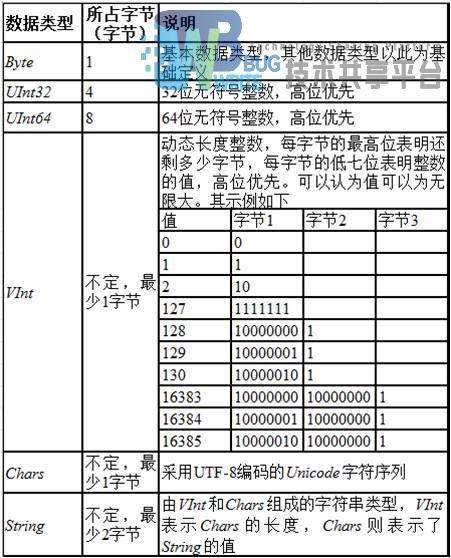
Lucene为了保证平台的无关性,所以自定义了一套数据类型,Lucene主要数据类型如表3-3所示:
3.3.2 索引文件概念性结构
Lucene 的索引结构采用了层次化设计,便于理解。索引层次结构如图3-3所示:
- 索引(Index):一个索引通常位于一个文件夹中,但并不是一个单独的文件,而是由一组相互关联的不同类型的文件组成;
- 段(Segment):一个索引可以由多个段组成,段是Lucene索引的特殊数据存储方式,段与段之间是相互独立的,新文档的添加会生成新的段,不同的段之间可以按照某种合并策略进行合并;
- 文档(Document):文档是创建索引的基本单位,它是所有可被索引的数据的一种抽象;
- 域(Field):域是文档不同属性的表示。一篇文档拥有不同的属性,可以分开索引,比如标题、时间和正文等,可以相应的保存在标题域、时间域和正文域中;
- 词(Term):词是经过词法分析和语言处理后的字符串,是一篇文档的基本组成单位。
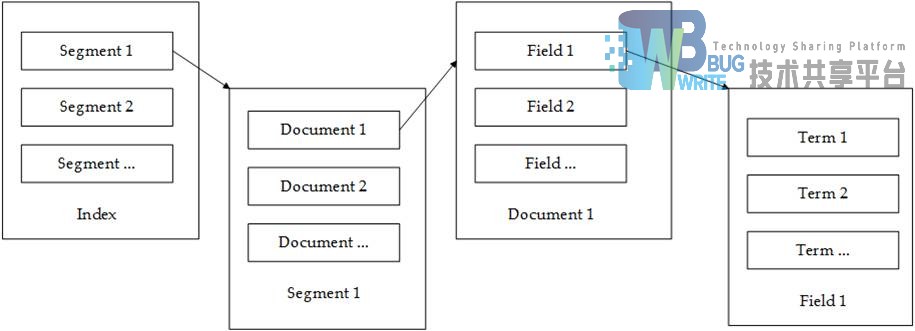
Lucene 的索引结构中,保存了正向和反向信息。
正向信息:按层次保存了从索引到词的包含关系:索引(Index) -> 段(Segment) -> 文档(Document) -> 域(Field) -> 词(Term);
反向信息:保存了词典到倒排表的映射:词(Term) -> 文档(Document)。
3.3.3 索引文件组织结构
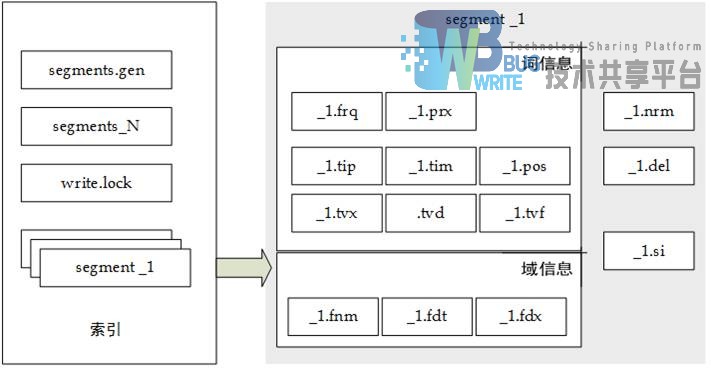
在上一节介绍了Lucene索引文件的概念结构。Lucene的一个索引存放于一个目录(文件夹)中,文件夹下的文件按照一定方式存放。Lucene索引文件数据类型如表3-4所示:
| 文件类型 | 后缀 | 描述 |
|---|---|---|
| Segments File | segments.gen, segments_N | 存储段文件的提交点信息 |
| Lock File | write.lock | 文件锁,保证任何时刻只有一个线程可以写入索引 |
| Segment Info | .si | 存储每个段文件的元数据信息 |
| Compound File | .cfs, .cfe | 复合索引的文件,在系统上虚拟的一个文件,用于频繁的文件句柄 |
| Fields | .fnm | 存储域文件的信息 |
| Field Index | .fdx | 存储域数据的指针 |
| Field Data | .fdt | 存储所有文档的字段信息 |
| Term Dictionary | .tim | term字典,存储term信息 |
| Term Index | .tip | term字典的索引文件 |
| Frequencies | .frq | 词频文件,包含文档列表以及每一个term和其词频 |
| Positions | .prx | 位置信息,存储每个term,在索引中的准确位置 |
| Norms | .nrm.cfs, .nrm.cfe | 存储文档和域的编码长度以及加权因子 |
| Per-Document Values | .dv.cfs, .dv.cfe | 编码除外的额外的打分因素, |
| Term Vector Index | .tvx | term向量索引,存储term在文档中的偏移距离 |
| Term Vector Documents | .tvd | 包含每个文档向量的信息 |
| Term Vector Fields | .tvf | 存储filed级别的向量信息 |
| Deleted Documents | .del | 存储索引删除文件的信息 |
Lucene索引文件整体组成结构如图3-4所示:
3.4 Lucene工作原理
在前两节的基础上,来分析Lucene的工作原理。Lucene 的索引过程,就是按照全文检索的基本过程,根据文档内容生成倒排表,并将倒排表按照一定格式写入到索引文件的过程。Lucene 的搜索过程,就是按照索引文件的格式将索引进去的信息读出来,然后计算每篇文档并打分(score)排序的过程。
接下来来研究Lucene数据流的流动过程,通过对数据流分析可以明确Lucene内部各个模块的调用顺序。这样,我们能够更加深入的理解Lucene的系统结构和工作原理。 Lucene系统中数据流如图3-5所示:
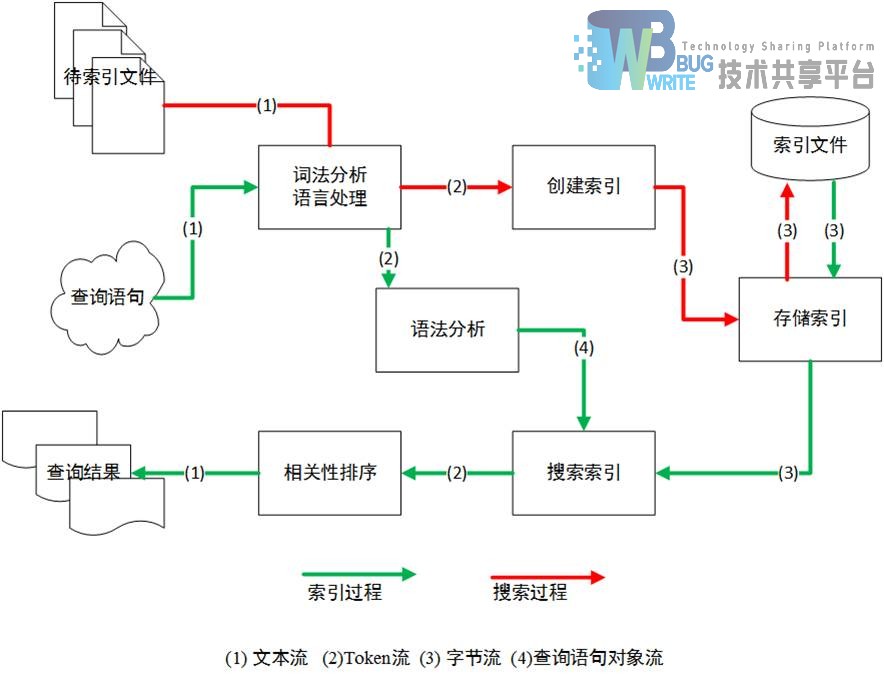
接下来我们对图3-5中的关键流类型以及作用进行说明。 Lucene的4种主要数据流已经在图中进行标注。文本流是待索引对象和检索结果的抽象;Token流是对传统文本中的词的抽象,是创建索引时最小单位,一篇文档经过分词处理后形成Token流,Token流传递给索引组件进行进一步处理;字节流是8比特长字节组成的统一二进制流,Lucene中通过这种方式将对文件的操作独立于系统平台之上。查询语句对象流是对查询语句的抽象,生命周期非常短。
3.5 Lucene排序算法
一个优秀的全文检索系统能够使用户在前几十条结果中找到所期望的结果。所以查询结果的分值计算以及排序算法是全文检索系统的核心部分。Lucene之所以知名,有一个重要的原因就是它的评分机制(Lucene scoring)。搜索引擎的评分机制是一项专门的领域,算法复杂。Lucene对用户隐藏了评分实现的复杂细节,致使用户可以简单地使用Lucene。同时为了适应多种评分模型,Lucene对外提供评分模型的扩展接口。在本文中将对Lucene的评分机制[9]进行简单介绍。
3.5.1 相似度
相似度是一个复杂的概念,在信息检索中.相似度反映的是文本与用户查询在意义上的符合程度。
3.5.2 评分机制
Lucene中的检索排序算法中,文档相似度的计算方法是以向量空间模型为理论基础而推导出来的。文档的得分取决于用户输入的关键字,每个文档的评分不是固定不变的,是很据搜索关键字实时计算而得出的结果。其评分公式如下:
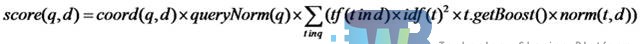
在详细介绍评分机制前对公式各部分说明如下:
-
t:这里的Term是指包含域信息的Term;
-
coord(q,d):此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高;
-
queryNorm(q):计算每个查询条目的方差和,此值仅仅使得不同的query之间的分数可以比较。
其公式如下:
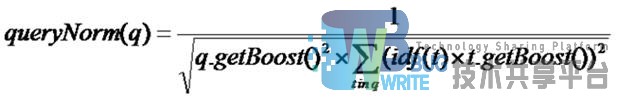
- tf(t in d):t在文档d中出现的词频。计算方式如下:
tf(t in d) = frequency½
- idf(t):t 出现的文档数目docFreq,计算方式如下:
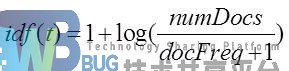
-
norm(t, d):标准化因子,它包括三个参数:
-
Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。
norm(t, d)的计算公式如下:

-
各类Boost值
-
t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,例如:common^4 hello
- d.getBoost():文档权重,在索引阶段写入.nrm文件,表明某些文档比其他文档更重要。
- f.getBoost():域的权重,在索引阶段写入.nrm文件,表明某些域比其他的域更重要。
4 实时全文检索系统设计与实现
4.1 系统概述
通常的全文检索系统中,创建索引和查询是分开的,即创建索引是离线的。新的索引会以一定频率(比如每隔5分钟)供查询端使用。对于一些站内检索来说,这种延迟性使得:不需要创建索引的速度足够快(只要能跟的上提交频率就行),查询的效果不必完全精确。对于不经常频繁更新的资料文档而言,这种检索系统是适用的。相对于非实时全文检索系统,实时检索系统具有更广泛的适用性。同样以站内检索为例,每当新发布一篇文章,新生成一个网页,这篇文章或者网页即可以被及时索引并检索。Esearch核心即是一个高度可配置的实时检索全文检索系统,一篇文档一经索引就可以马上对其进行检索,同时提供了大量接口可以按需扩展。
Esearch能够对不同格式的文档进行索引和检索,同时对外提供解析器接口,用户可以自定义针对不同文档的解析方式。同时Esearch可以自定义数据源,比如数据库或者网络,以及本地文件。
Esearch由两个主要模块组成,esearch-core是Esearch的核心,与具体应用类型无关。esearch-web是Esearch基于Web的具体实现。
4.2 需求分析
4.2.1 核心功能需求
作为一个实时全文检索系统,Esearch的主要核心功能应满足如下需求:
1.实时性
-
支持实时索引和检索,一篇文档一经索引即可对其进行检索;
-
实时性与否可进行配置。
2.数据源与文档类型
-
数据源可进行配置,支持数据库、本地文件、网络流;
-
支持对不同类型文档进行索引和检索;
-
支持自定义解析过程,索引域和索引方式。
3.组件配置
-
支持使用不同类型分词器(默认采用Lucene的StandardAnalyzer)以及相似度匹配算法;
-
支持针对不同语言文档进行索引(默认为英文);
-
支持主要组件自由配置。
4.检索策略
-
支持按关键词、域、主题等查询方式;
-
支持复杂查询,支持运用逻辑操作符进行检索、支持模糊检索等。
5.检索结果
-
包装原始检索结果;
-
支持用户扩展检索结果,例如高亮显示。
6.系统监控
- 支持对检索系统的监控,例如索引文档数量,占用空间,系统状态等。
7.运行
- 支持以嵌入式方式或者单独服务方式运行。
4.2.2 接口需求
Esearch设计为可扩展的全文检索系统,用户可以根据需要以及应用场景对其进行定制与扩展,接口需求用于说明Esearch对外提供的接口,主要包括:
-
数据源接口:数据源接口定义了系统数据来源,系统默认实现为本地文件系统,用户可对其进行扩展,例如以数据库为数据源、以网络流为数据源;
-
解析器接口:解析器接口定义了数据的解析方式,由于数据源提供的数据可能不止一种格式,系统需要通过解析器来将不同类型的文档解析为可被Lucene索引的Document对象。同时该接口允许用户自定义要索引的域以及索引方式;
-
监视器接口:监视器接口对外提供系统运行状态信息。
4.2.3 Web实现功能需求
Esearch的Web实现对外提供了一个Web界面用于检索以及展示检索结果。并设计拥有一个符合RESTful架构风格的API接口。其功能需求在核心功能需求的基础上包括:
1.界面
-
提供良好风格的界面用于用户输入检索关键词以及显示检索结果;
-
高亮显示检索结果,显示检索耗时与结果数目。
2.API
- 支持RESTful风格的API直接调用。
3.部署运行
-
支持Tomcat以及常见Web服务器部署;
-
支持单独运行;
-
可嵌入。
4.3 开发环境
开发环境选择是否合理,对系统的开发效率,有时甚至是系统的功能都将产生重要影响。Esearch开发测试环境如表4-1所示:
| 条目 | 说明 |
|---|---|
| 操作系统 | Windows 7 专业版 64bit |
| CPU | Core(TM) i5-2520M CPU @2.50GHz |
| IDE | Intellij IDEA 14 |
| JDK | 版本1.7.0_60 |
| Apache Tomcat | 版本7.0.52 |
| Lucene | 版本4.3.0 |
| 硬盘 | Samsung SSD 120GB固态硬盘 |
| 内存 | 4G |
4.4 总体设计
取得实时检索效果,典型的思路是:创建索引和查询是在一个进程内,这样每一次的添加索引都会被下一次的查询用到。整个Esearch核心即是基于此思路设计的。Esearch核心由逻辑上独立的索引系统和搜索系统结合在一起。
在系统Web实现部分,采用Spring MVC架构,这种架构可以更方便的提供符合RESTful风格的API。
4.4.1 生产者消费者模式
系统假定数据源提供持续的数据,数据不断的输入到索引系统,索引系统则不断的对新增数据进行索引操作。数据源即是生产者,而索引系统是消费者。Esearch的总体架构如图4-2所示:
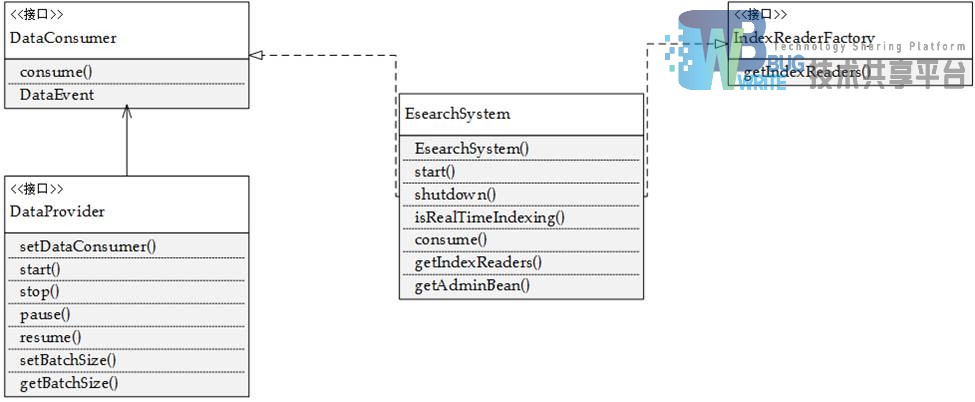
EsearchSystem通过实现消费者接口表明自己是一个消费者,同时通过实现索引读取器工厂接口,表明自己是一个索引读取器工厂。通过这种方式将索引熊和搜索系统结合在一起。下面对图中各部分进行简要说明。
- DataEvent:数据事件对象,系统将每一次的数据的到来抽象为一个数据事件;
- DataConsumer:消费者类接口,只包含一个 consume 方法,用于消费自身的DataEvent;
- DataProvider:生产者接口,提供给DataConsumer以DataEvent,并包含一些控制数据事件产生的方法;
- IndexReaderFactory:索引读取器工厂接口,用于产生读取索引的Reader,以便进行索引检索;
- EsearchSystem:Esearch系统核心类。
对于索引系统来讲,EsearchSystem是一个DataConsumer,它通过方法 consume 消费DataEvent对象而完成索引操作。DataProvider作为生产者向它提供索引数据,用户需要提供自己的生产者来使用Esearch建立实时搜索系统。系统默认实现有以本地文件为数据源的FileDataProvider。对于搜索系统而言,EsearchSystem是一个能够得到IndexReader索引工厂,它通过方法getIndexReaders得到指向内存和硬盘索引的IndexReader列表,从而可以完成对索引数据读取的功能。用户根据得到的IndexReader按需实现自己的搜索逻辑即可。
4.4.2 实时索引设计
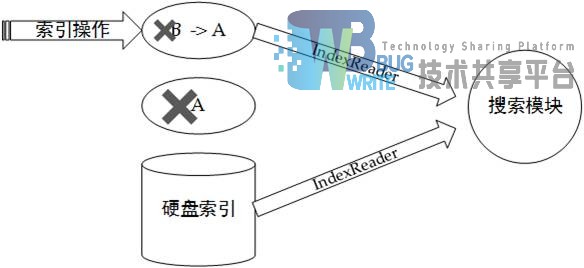
Esearch采用了两个内存索引和一个硬盘索引的方式来实现实时索引与搜索,。硬盘索引是最终存储索引的地方。两个内存索引用于交换和合并操作。实时索引架构如图4-2示:
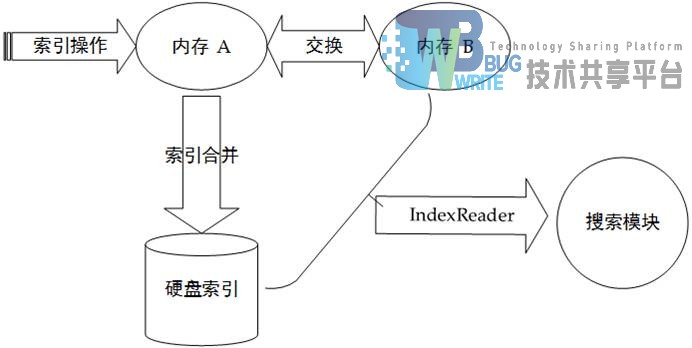
设计原理如下:
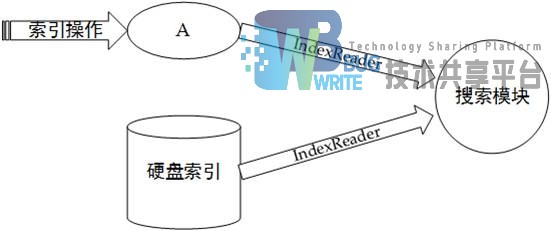
当系统启动时,创建用于读取硬盘索引的IndexReader,并在内存中创建一片缓冲区A用于存储新增文档的索引,并创建指向此缓冲区的IndexReader。此时进行文档索引操作会将新增文档索引缓存至A,系统初始状态如图4-3所示:
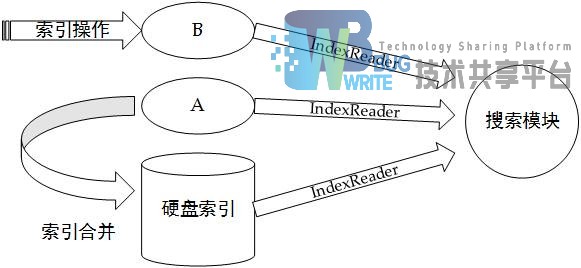
当内存索引A中缓存的的文档达到一定的数量后,就需要同硬盘上索引进行合并操作。合并过程相对较长,这时候会创建内存索引B用于添加新的文档。此时内存中有两个索引缓冲区A和B索引A目前状态为只读,索引B为可写。此时进行搜索则返回三个索引区域的IndexReader,索引合并状态如图4-4所示:
当内存索引A中的索引数据与硬盘索引合并完成后,交换内存索引A,B区域并重新打开硬盘索引的IndexReader,原来的索引A被抛弃。然后通过无缝切换用新的内存结构替代旧的内存结构,合并完成后状态如图4-5所示:
4.4.3 Web实现设计
Spring MVC[10]是一种基于Java的轻量级Web框架,框架的目的就是帮助我们简化开发。具体的关于Spring MVC框架的介绍本文不再详述。
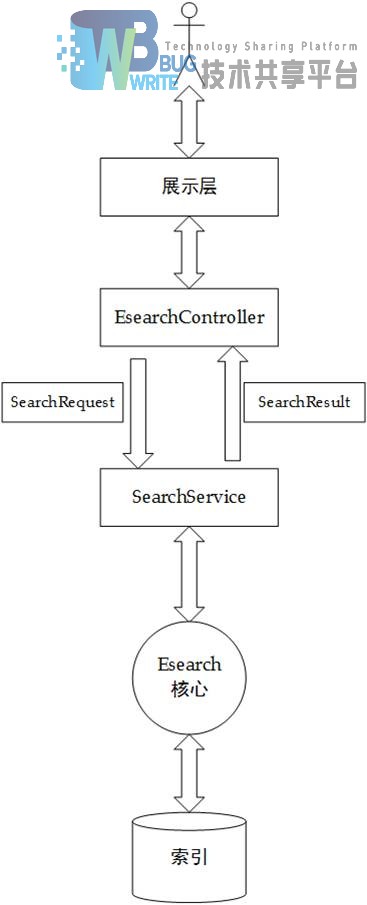
Esearch基于Web的实现主要分为四个层面:展示层,控制层,服务层,模型层。控制层调用服务层的搜索服务,服务层构建模型层定义的结果模型并返回给控制层,最后控制层将结果模型传递给展示层,Esearch MVC系统架构图如图4-6所示。
用户通过展示层(通过JSP实现)输入检索关键词并查看检索结果,由控制层生成检索对象SearchRequest,并调用搜索服务层SearchService,服务层通过调用Eserach核心来完成检索,并生成检索结果SearchResult对象返回给控制层EsearchController,最后控制层将结果返回给展示层。
4.4.4 API设计
Esearch基于Web的实现对外提供直接的API调用功能,用户可以直接调用系统提供的API,进行检索和管理操作。
API设计主要工作是设计符合RESTful风格的API,主要包括:检索、索引、信息查询三个部分。将在详细设计部分予以说明。
4.5 详细设计
根据上一小节可知详细设计主要分为:数据源设计,索引系统设计,搜索系统设计,Web实现设计,API设计。
4.5.1 数据源设计
Esearch考虑到实际应用的数据来源有多种,所以通过抽象,将实际可能的数据源隐藏,对消费者(索引系统)而言,数据实际来源是透明的。数据源结构图如图4-7所示:
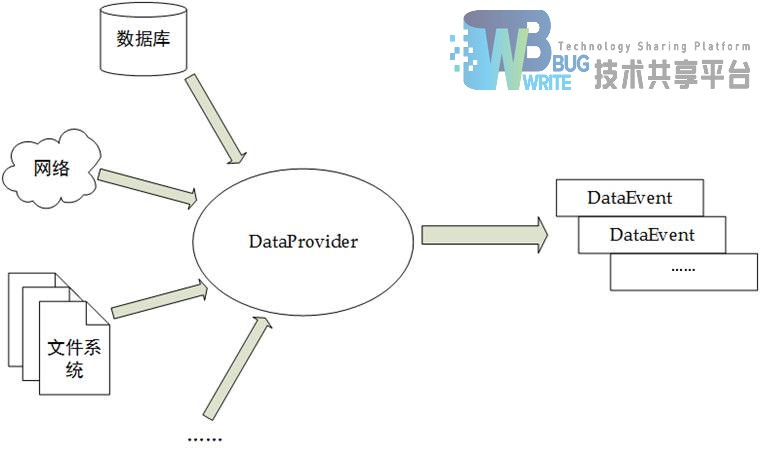
所有数据来源抽象为DataProvider,DataProvider不提供任何方法,只表示抽象的数据源。通过其子类来进行针对不同数据来源的实现,对外提供一系列的数据事件(DataEvent)。图4-8为DataEvent的UML图示:

DataEvent是DataConsumer的内部类,一个DataEvent封装了一个数据的所有信息。供DataConsumer消费。
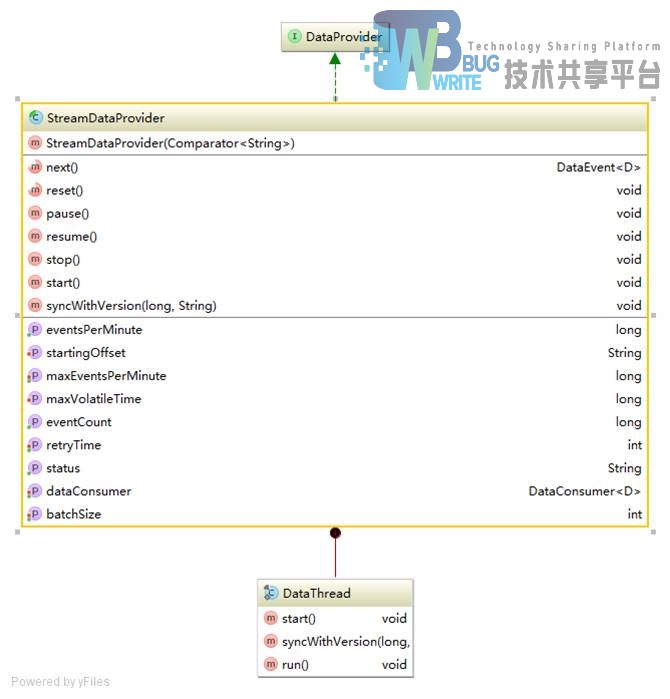
直接继承自DataProvider的是StreamDataProvider,流式数据源。所有具体数据源子类都要继承此类。StreamDataProvider提供了对数据的基本处理操作,并在内部实现一个数据处理线程,用多线程方式来产生数据事件。StreamDataProvider的UML图示如图4-9:
Esearch默认实现了基于文件系统的数据源。在文件系统中,需要为数据源指定一个根目录。接下来,针对文件系统的数据源会递归的查找此指定根目录下未被索引的文件。一个DataEvent就是一个新发现的未经索引的文件。
将DataEvent转换为Lucene能够进行索引的文档Document对象也是系统的一个模块。Esearch设计了一个解释器接口Interpreter,解析器接口UML图如图4-10所示:
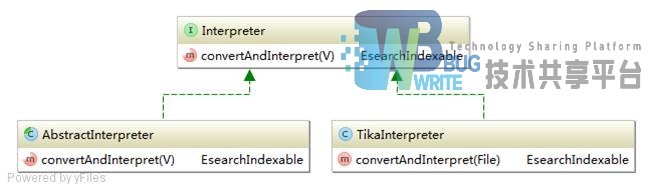
在Esearch中默认采用的是TikaInterpreter解析器,该解析器通过使用Apache Tika[11]提取各种不同类型文档的元数据,并转化为EsearchIndexable对象,EsearchIndexable对象是对Document对象的简单封装。
4.5.2 索引系统设计
索引系统是Esearch系统设计的核心部分之一,索引系统的整体设计图如图4-11所示:
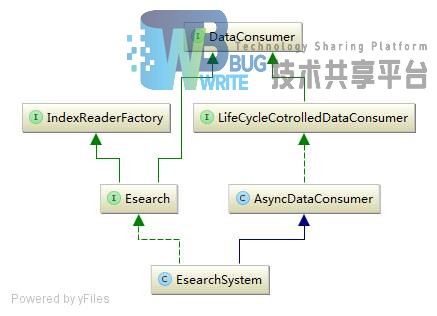
在4.3.1节中我们知道,EsearchSystem实现了消费者接口,即它是索引系统的入口。现在详细说明将文档进行索引的过程。主要分为两步:将文档添加到内存索引,将内存索引合并到硬盘索引:
1.将文档添加到内存索引
Esearch的索引过程由DataProvider中调用EsearchSystem的 consume 方法开始,其实是调用AsyncDataConsumer的 consume 方法,其仅仅将DataEvent放在一个事件集合中。
AsyncDataConsumer设计有一个背后的消费者线程,同时采用了设计模式中的装饰器模式,在AsyncDataConsumer内部有一个DataConsumer用于实际消费数据事件,上述调用实际会调用其内部DataConsumer的consume(currentBatch)方法,由EsearchSystem传递给AsyncDataConsumer其内部的DataConsumer,为RealtimeIndexDataLoader。AsyncDataConsumer和RealtimeIndexDataLoader都是DataConsumer的一种实现。来看DataConsumer的继承层次如图4-12所示:
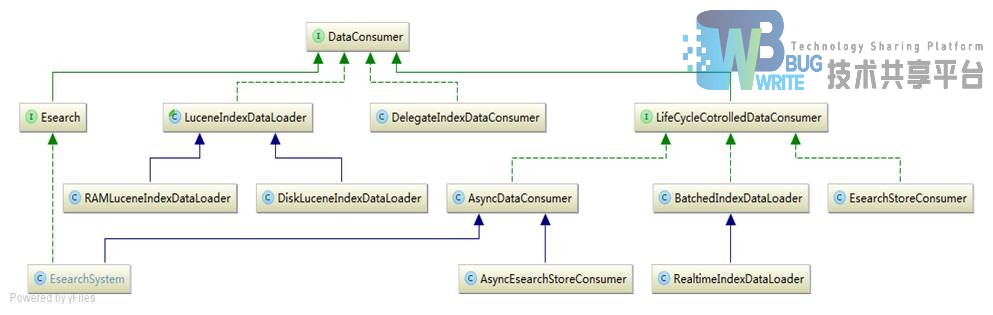
接下来RealtimeIndexDataLoader的 consume 方法首先调用其解析器的解析转换方法convertAndInterpret将所有的DataEvent对象转换为可被Lucene索引的Document对象,并将转换后的结果存放至一个待消费的集合中。同时RealtimeIndexDataLoader会创建指向内存索引的RAMLuceneIndexDataLoader ,并调用它的consume方法将上述集合索引到内存中。
2.将内存索引合并到硬盘索引
RealtimeIndexDataLoader的父类是BatchedIndexDataLoader,其有一个背后的线程会调用 processBatch 方法。RealtimeIndexDataLoader的 processBatch 方法会在内存索引中的文档数量超过配置参数的时候,进行内存索引到硬盘索引的合并。索引合并的过程见4.3.2节。
Esearch目前没有提供删除索引的接口,它认为每一次的提交或者是add或者是update。Esearch设计有自己的索引合并策略。在Lucene中默认使用的MergePolicy是LogByteSizeMergePolicy,这个MergePolicy在选择合并的segment时,是计算segment的总的字节大小。这种方式的一个缺陷是,像用户profile这种如果update操作多的话(每次update会有一次delete操作),会使得一些segment看起来很大,实际上其中有效的索引数据会很少,这些无用索引数据会给查询带来负担。EsearchMergePolicy在计算索引大小时就去除了已删除的文档,使计算更加精确。对于两种索引合并策略的性能测试见第五章。
在不同的索引阶段,可供搜索系统使用的索引不同。对搜索系统而言,没有必要关心可用的索引为何种索引,索引时间线参见图4-13:

4.5.3 搜索系统设计
在使用Esearch进行搜索的时候,要调用EsearchSystem的getIndexReaders()方法,分别得到指向内存的两个索引的IndexReader以及指向硬盘索引的IndexReader。用户可以根据得到的IndexReader来自定义搜索过程,在后续章节实现基于Esearch的Web站内检索系统的时候介绍实现样例,搜索系统设计如图4-13所示:

4.5.4 Web实现设计
在4.3.3节说明了Web实现的四个层级:展示层,控制层,服务层,模型层。现在对四个层级进行详细设计:
1.展示层
展示层主要用于用户输入检索关键词,并显示检索结果,属于UI设计,展示界面模拟图如图4-15所示:
2.控制层
控制层负责生成查询对象,调用搜索服务,并返回搜索结果,同时控制层对外提供API调用支持,所以设计有两个Controller,EsearchController负责普通业务逻辑,EsearchRestController负责对外提供API支持。
3.服务层
服务层主要负责根据控制层传来的SearchRequest对象,调用Esearch核心完成检索并生成SearchResult对象。主要有一个SearchService接口和SearchServiceImpl实现组成。服务层UML如图4-16所示:
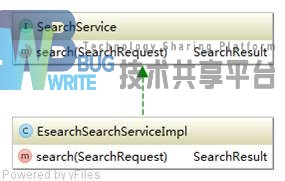
4.模型层
在前面章节我们已经介绍过,Esearch核心并未提供对检索结果的处理,这部分需要用户来自己实现。这样能够给予用户最灵活的处理方式。模型层提供三个类对检索请求检索结果进行包装:SearchRequest用于包装检索请求,SearchHit用于包装原始检索结果,SearchResult用于高亮显示检索结果。
4.5.5 API设计
API设计主要工作是设计符合RESTful风格的API,主要包括:检索、索引、信息查询三个部分,采用Json格式的定义,API格式定义设计如下:
json
{
"API名称": { //api名称
"methods": ["POST", "PUT"], //用于进行方法说明
"url": { //用于进行URL说明
"path": "URL路径",
"parts":"URL路径的各部分说明",
"params": { //用于进行参数说明
"param1": { //参数具体属性
"type" : "参数类型",
"options" : "参数选项",
"default" : "默认选项",
"description" : "参数描述"
}
}
},
"body": { //请求体属性
"description" : "请求体描述",
}
}
}
1.检索API
json
{
"index": {
"methods": ["POST", "PUT"],
"url": {
"path": "/api/v1/_index/{id}",
"parts": {
"id": {
"type" : "string",
"description" : "文档ID"
}
},
"params": {
"op_type": {
"type" : "enum",
"options" : ["index", "create"],
"default" : "index",
"description" : "操作类型,创建或更新"
},
"refresh": {
"type" : "boolean",
"description" : "用于指定索引完后是否进行刷新操作"
},
"timeout": {
"type" : "time",
"description" : "超过设置的时间则放弃索引"
},
"version" : {
"type" : "number",
"description" : "用户同步控制指定的版本号"
}
}
},
"body": {
"description" : "文档内容或路径",
"required" : true
}
}
}
2.搜索API
json
{
"search": {
"methods": [
"POST",
"GET"
],
"url": {
"path": "/api/v1/_search/"
},
"params": {
"query": {
"type": "string",
"description": "查询字符串"
},
"field": {
"type": "string",
"default": "_source",
"description": "查询域"
},
"size": {
"type": "number",
"description": "指定返回的TopN结果数目"
},
"search_type": {
"type": "enum",
"options": [
"query_and_fetch",
"simple_query",
"count"
],
"description": "查询类型"
},
"_source": {
"type": "boolean",
"description": "指定是否显示原始数据"
},
"pretty": {
"type": "boolean",
"description": "指定是否格式化返回内容"
}
}
},
"body": {
"description": "查询体",
"required": false
}
}
3.信息API
json
{
"search": {
"methods": [
"POST",
"GET"
],
"url": {
"path": "/api/v1/_search/"
},
"params": {
"query": {
"type": "string",
"description": "查询字符串"
},
"field": {
"type": "string",
"default": "_source",
"description": "查询域"
},
"size": {
"type": "number",
"description": "指定返回的TopN结果数目"
},
"search_type": {
"type": "enum",
"options": [
"query_and_fetch",
"simple_query",
"count"
],
"description": "查询类型"
},
"_source": {
"type": "boolean",
"description": "指定是否显示原始数据"
},
"pretty": {
"type": "boolean",
"description": "指定是否格式化返回内容"
}
}
},
"body": {
"description": "查询体",
"required": false
}
}
4.6 系统实现
4.6.1 核心模块实现
Esearch使用Maven来进行项目管理[11]。采用模块化设计思路,在Java代码中以package(包)为组织单位。代码组织图如图4-17所示:
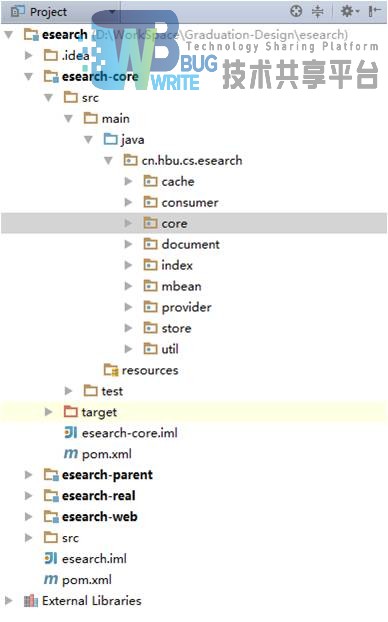
现在对各模块进行说明:
- cache :此模块主要用于辅助索引的读取,在内存中建立缓存;
- consumer:此模块包含了多种DataConsumer接口的实现;
- core:此模块是索引和搜索系统的核心实现部分;
- document:此模块主要提供对数据源数据事件到Lucene的Document对象映射的支持;
- index:此模块是索引系统的核心部分;
- mbean:此模块对系统监控提供支持;
- provider:此模块包含了基本的DataProvider实现;
- store:此模块对索引存储进行了抽象;
- util:此模块提供一些工具类对系统各部分提供工具支持。
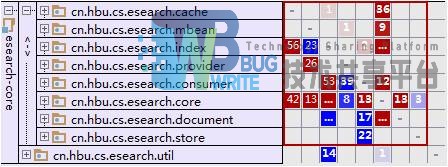
模块之间遵守严格的分层规则,模块内不存在相互依赖现象。模块的依赖矩阵(DSM)如图4-18所示:
4.6.2 Web实现
在Web实现中,同样采用明确的分层设计方式,源码组织如图4-19所示:

系统分为控制层controller,服务层service,模型层model,展示层为jsp页面。在展示层,使用了Bootstrap类库来简化前端页面的开发。
service层定义了一个SearchService,并在实现部分进行了实现。UML图如图4-20所示:
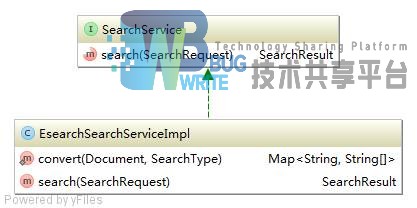
SearchResult是对搜索结果Hits的一种封装。用户需要根据EsearchSystem获取IndexReader后执行搜索逻辑。在Web实现部分主要对搜索结果进行了高亮处理以及显示排序。
controller层主要用于进行页面导航,以及对外提供RESTfulAPI。EsearchController是系统执行搜索任务的入口。
系统最终的Web实现,未输入关键词裕兴效果如图4-21所示,输入关键词查询显示效果如图4-22所示:
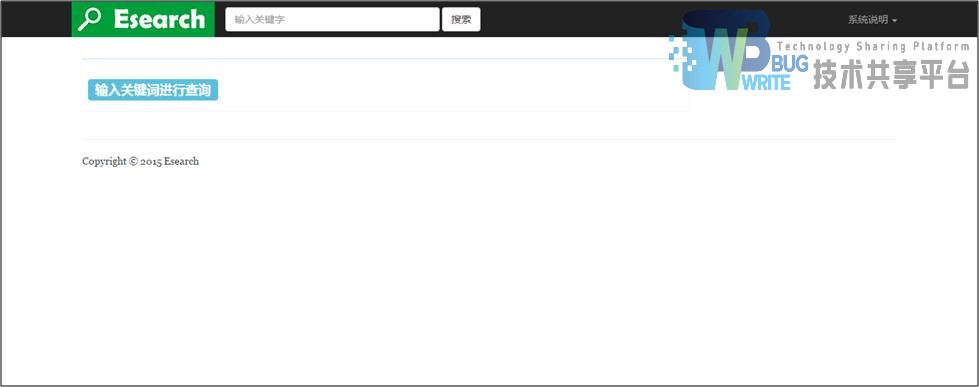
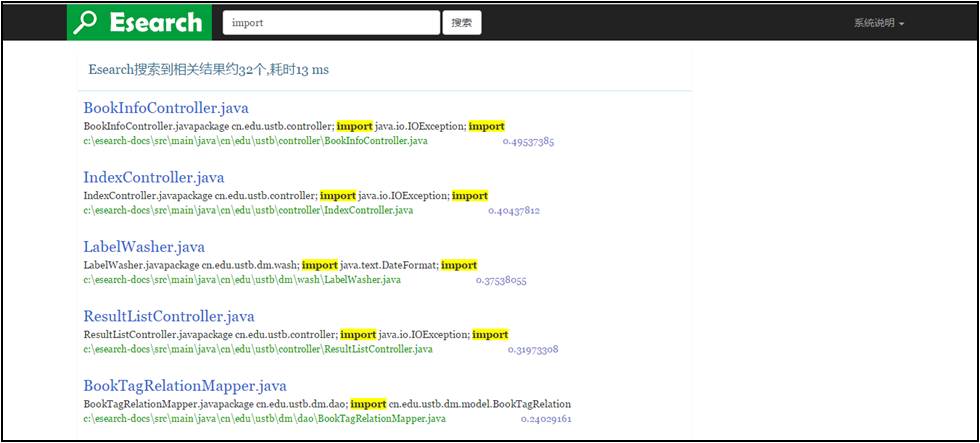
5 性能测试
5.1 概述
在信息检索领域,评估全文检索引擎一般有如下几个指标:查全率(recall)和查准率(precision)、检索时间和结果排序等,本文对查全率和查准率进行了测试。同时为了衡量Esearch整体性能,本文对Esearch的索引效率进行了测试。
5.2 索引效率测试
Lucene的性能指标与多种因素有关,分词器和相似度算法是其中的重要因素,在本文中,均选用Lucene默认的StandardAnalyzer和DefaultSimilarity。索引的缓存数目maxBufferedDocs以及索引合并因子mergeFactor对检索效率也有影响。maxBufferedDocs该参数决定写入内存索引文档个数,到达maxBufferedDocs后就把该内存索引写入到硬盘中,生成一个新的索引段文件。所以该参数也就是一个内存buffer,一般来说越大索引速度越快。mergeFactor这个参数就是控制当硬盘中有多少个子索引segments,我们就需要现把这些索引合并成一个大些的索引。mergeFactor这个参数不能设置过大,特别是当maxBufferedDocs比较小时(segment越多),否则会导致open too many files错误,甚至导致虚拟机出错。在本次测试中,缓存数目默认取100,合并因子取6。
Esearch整体的索引效率主要取决于两部分:将不同类型文档解析为可被Lucene索引的Document对象;索引核心根据Document对象建立索引。测试结果如表4-2所示:
| 类型 | 数目 | 文档大小(MB) | 索引耗时(s) | 索引大小(MB) | 索引效率(MB/s) | 索引效率(个/s) |
|---|---|---|---|---|---|---|
| .html | 5765 | 93.7 | 60.87s | 8.76 | 1.54 | 94.7 |
| .xml | 4863 | 72.6 | 45.86 | 10.24 | 1.58 | 106.1 |
| .txt | 1778 | 38.3 | 32.42s | 18.1 | 1.18 | 54.8 |
| .java | 7454 | 91.7 | 124.94 | 49.0 | 0.74 | 59.6 |
| 34 | 120.3 | 67.28 | 11.8 | 1.78 | 0.5 |
实验结果说明:对半结构化数据,例如html页面,xml文档,等索引具有较高的压缩比,索引效率较高;对于非结构化数据,例如txt,java源码等压缩比小,索引效率较低。同时总体试验数据表明,索引速度和索引文档类型以及文档大小有关。对一般应用而言,本系统索引效率足够胜任。
5.3 检索性能测试
查全率(recall)和查准率(precision)是目前衡量检索效果的相对合理的指标,计算方式如下:
- 查全率=(检索出的相关信息量/系统中的相关信息总量)*100%
- 查准率=(检索出的相关信息量/检索出的信息总量)*100%
前者是衡量检索系统和检索者检出相关信息的能力,后者是衡量检索系统和检索者拒绝非相关信息的能力。两者合起来,即表示检索效率。试验数据来源于多本英文版名著,名著列表见附录,试验数据如下:
| 结果类别 | 查询关键词 | ||
|---|---|---|---|
| 结果类别 | world | happy | people |
| 全部相关文档数/个 | 310 | 234 | 461 |
| 查询的结果/个 | 213 | 164 | 320 |
| 查询返回的正确结果/个 | 111 | 127 | 164 |
| 查询查全率/% | 68.9 |
参考文献
- 基于J2EE的站群管理平台的设计与实现(电子科技大学·葛世海)
- 基于JavaEE的企业信息资源平台的设计与实现(武汉理工大学·王平)
- 异构数据联合检索系统的设计与实现(东北大学·高巍)
- 基于.NET的对象持久化研究与应用(沈阳理工大学·吕增辉)
- 网络新闻分类系统及个性化新闻网站的研究与应用(内蒙古工业大学·王继明)
- 基于J2EE的远程网络教育系统研究与实现(电子科技大学·陈南荪)
- 基于J2EE的远程网络教育系统研究与实现(电子科技大学·陈南荪)
- 校园视频网络信息检索研究及设计(电子科技大学·姜岚)
- 基于Lucene的应用系统内部搜索的研究与设计(南京理工大学·张琦玉)
- 基于iOS平台的文本型图像的检索与实现(北京邮电大学·杨扬)
- 基于JavaEE的企业信息资源平台的设计与实现(武汉理工大学·王平)
- 基于Lucene和HTML Parser技术的搜索引擎的设计与实现(西安电子科技大学·牛春山)
- 基于MVC+Lucene.Net.net框架下的垂直搜索引擎研究与设计(吉林大学·贾捷)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 基于Lucene的应用系统内部搜索的研究与设计(南京理工大学·张琦玉)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设工坊 ,原文地址:https://bishedaima.com/yuanma/35424.html