基于SpringBoot+Quartz实现的任务调度中心
1.项目简介
因为想要做一个类似于调度中心的东西,定时执行一些Job(通常是一些自定义程序或者可执行的jar包),搭了一个例子,总结了前辈们的相关经验和自己的一些理解,如有雷同或不当之处,望各位大佬见谅和帮忙指正。
本例是一个将quartz集成为调度器中心的典型示例,主要用于定时执行一些Job(通常是一些自定义程序或者可执行的jar包),基于Spring Boot 2.0.1,Quartz 2.2.3。
如果你只是想要简单的SpringBoot整合Quartz,对定时任务进行 自定义逻辑,启动,暂停,恢复,删除,修改。 可以参考 : https://github.com/EalenXie/springboot-quartz-simple (这个例子相当于算是个整合Quartz入门的例子,我也做了完整和详细的注释说明)
2.系统设计
2.1新建项目
选用的技术栈为 SpringBoot + Quartz + Spring Data Jpa
**pom.xml依赖 : **
```xml
2.2搭建数据库
sql
-- in your Quartz properties file, you'll need to set org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
-- 你需要在你的quartz.properties文件中设置org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
-- StdJDBCDelegate说明支持集群,所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务
-- This is the script from Quartz to create the tables in a MySQL database, modified to use INNODB instead of MYISAM
-- 这是来自quartz的脚本,在MySQL数据库中创建以下的表,修改为使用INNODB而不是MYISAM
-- 你需要在数据库中执行以下的sql脚本
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
-- 存储每一个已配置的Job的详细信息
CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
-- 存储已配置的Trigger的信息
CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
-- 存储已配置的Simple Trigger的信息
CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
-- 存储Cron Trigger,包括Cron表达式和时区信息
CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
-- Trigger作为Blob类型存储(用于Quartz用户用JDBC创建他们自己定制的Trigger类型,JobStore并不知道如何存储实例的时候)
CREATE TABLE QRTZ_BLOB_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
-- 以Blob类型存储Quartz的Calendar日历信息,quartz可配置一个日历来指定一个时间范围
CREATE TABLE QRTZ_CALENDARS (
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME))
ENGINE=InnoDB;
-- 存储已暂停的Trigger组的信息
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
-- 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息
CREATE TABLE QRTZ_FIRED_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID))
ENGINE=InnoDB;
-- 存储少量的有关 Scheduler的状态信息,和别的 Scheduler 实例(假如是用于一个集群中)
CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB;
-- 存储程序的非观锁的信息(假如使用了悲观锁)
CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB;
CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
commit;
2.3项目配置
yaml
quartz:
enabled: true
server:
port: 9090
spring:
datasource:
url: jdbc:mysql://localhost:3306/spring_quartz
username: yourname
password: yourpassword
tomcat:
initialSize: 20
maxActive: 100
maxIdle: 100
minIdle: 20
maxWait: 10000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
quartz.properties
```properties
ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的)
org.quartz.scheduler.instanceId=AUTO
指定调度程序的主线程是否应该是守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon=true
ThreadPool实现的类名
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
ThreadPool配置线程守护进程
org.quartz.threadPool.makeThreadsDaemons=true
线程数量
org.quartz.threadPool.threadCount:20
线程优先级
org.quartz.threadPool.threadPriority:5
数据保存方式为持久化
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
StdJDBCDelegate说明支持集群
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
quartz内部表的前缀
org.quartz.jobStore.tablePrefix=QRTZ_
是否加入集群
org.quartz.jobStore.isClustered=true
容许的最大作业延长时间
org.quartz.jobStore.misfireThreshold=25000 ```
2.4调度数据库中的Job实例定义
java
package com.ealen.entity;
import javax.persistence.*;
import java.io.Serializable;
/**
* Created by EalenXie on 2018/6/4 14:09
* 这里个人示例,可自定义相关属性
*/
@Entity
@Table(name = "JOB_ENTITY")
public class JobEntity implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name; //job名称
private String group; //job组名
private String cron; //执行的cron
private String parameter; //job的参数
private String description; //job描述信息
@Column(name = "vm_param")
private String vmParam; //vm参数
@Column(name = "jar_path")
private String jarPath; //job的jar路径,在这里我选择的是定时执行一些可执行的jar包
private String status; //job的执行状态,这里我设置为OPEN/CLOSE且只有该值为OPEN才会执行该Job
public JobEntity() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGroup() {
return group;
}
public void setGroup(String group) {
this.group = group;
}
public String getCron() {
return cron;
}
public void setCron(String cron) {
this.cron = cron;
}
public String getParameter() {
return parameter;
}
public void setParameter(String parameter) {
this.parameter = parameter;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getVmParam() {
return vmParam;
}
public void setVmParam(String vmParam) {
this.vmParam = vmParam;
}
public String getJarPath() {
return jarPath;
}
public void setJarPath(String jarPath) {
this.jarPath = jarPath;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
@Override
public String toString() {
return "JobEntity{" +
"id=" + id +
", name='" + name + '\'' +
", group='" + group + '\'' +
", cron='" + cron + '\'' +
", parameter='" + parameter + '\'' +
", description='" + description + '\'' +
", vmParam='" + vmParam + '\'' +
", jarPath='" + jarPath + '\'' +
", status='" + status + '\'' +
'}';
}
//新增Builder模式,可选,选择设置任意属性初始化对象
public JobEntity(Builder builder) {
id = builder.id;
name = builder.name;
group = builder.group;
cron = builder.cron;
parameter = builder.parameter;
description = builder.description;
vmParam = builder.vmParam;
jarPath = builder.jarPath;
status = builder.status;
}
public static class Builder {
private Integer id;
private String name = ""; //job名称
private String group = ""; //job组名
private String cron = ""; //执行的cron
private String parameter = ""; //job的参数
private String description = ""; //job描述信息
private String vmParam = ""; //vm参数
private String jarPath = ""; //job的jar路径
private String status = ""; //job的执行状态,只有该值为OPEN才会执行该Job
public Builder withId(Integer i) {
id = i;
return this;
}
public Builder withName(String n) {
name = n;
return this;
}
public Builder withGroup(String g) {
group = g;
return this;
}
public Builder withCron(String c) {
cron = c;
return this;
}
public Builder withParameter(String p) {
parameter = p;
return this;
}
public Builder withDescription(String d) {
description = d;
return this;
}
public Builder withVMParameter(String vm) {
vmParam = vm;
return this;
}
public Builder withJarPath(String jar) {
jarPath = jar;
return this;
}
public Builder withStatus(String s) {
status = s;
return this;
}
public JobEntity newJobEntity() {
return new JobEntity(this);
}
}
}
**为了方便测试,设计好表之后先插入几条记录,job_entity.sql,相关sql语句如下: **
sql
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `job_entity`;
CREATE TABLE `job_entity` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`group` varchar(255) DEFAULT NULL,
`cron` varchar(255) DEFAULT NULL,
`parameter` varchar(255) NOT NULL,
`description` varchar(255) DEFAULT NULL,
`vm_param` varchar(255) DEFAULT NULL,
`jar_path` varchar(255) DEFAULT NULL,
`status` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
INSERT INTO `job_entity` VALUES ('1', 'first', 'helloworld', '0/2 * * * * ? ', '1', '第一个', '', null, 'OPEN');
INSERT INTO `job_entity` VALUES ('2', 'second', 'helloworld', '0/5 * * * * ? ', '2', '第二个', null, null, 'OPEN');
INSERT INTO `job_entity` VALUES ('3', 'third', 'helloworld', '0/15 * * * * ? ', '3', '第三个', null, null, 'OPEN');
INSERT INTO `job_entity` VALUES ('4', 'four', 'helloworld', '0 0/1 * * * ? *', '4', '第四个', null, null, 'CLOSE');
INSERT INTO `job_entity` VALUES ('5', 'OLAY Job', 'Nomal', '0 0/2 * * * ?', '5', '第五个', null, 'C:\\EalenXie\\Download\\JDE-Order-1.0-SNAPSHOT.jar', 'CLOSE');
2.5Quartz的核心配置类 : ConfigureQuartz.class
java
package com.ealen.config;
import org.quartz.spi.JobFactory;
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import org.springframework.scheduling.quartz.SpringBeanJobFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.Properties;
/**
* Created by EalenXie on 2018/6/4 11:02
* Quartz的核心配置类
*/
@Configuration
public class ConfigureQuartz {
//配置JobFactory
@Bean
public JobFactory jobFactory(ApplicationContext applicationContext) {
AutowiringSpringBeanJobFactory jobFactory = new AutowiringSpringBeanJobFactory();
jobFactory.setApplicationContext(applicationContext);
return jobFactory;
}
/**
* SchedulerFactoryBean这个类的真正作用提供了对org.quartz.Scheduler的创建与配置,并且会管理它的生命周期与Spring同步。
* org.quartz.Scheduler: 调度器。所有的调度都是由它控制。
* @param dataSource 为SchedulerFactory配置数据源
* @param jobFactory 为SchedulerFactory配置JobFactory
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(DataSource dataSource, JobFactory jobFactory) throws IOException {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
//可选,QuartzScheduler启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录
factory.setOverwriteExistingJobs(true);
factory.setAutoStartup(true); //设置自行启动
factory.setDataSource(dataSource);
factory.setJobFactory(jobFactory);
factory.setQuartzProperties(quartzProperties());
return factory;
}
//从quartz.properties文件中读取Quartz配置属性
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
//配置JobFactory,为quartz作业添加自动连接支持
public final class AutowiringSpringBeanJobFactory extends SpringBeanJobFactory implements
ApplicationContextAware {
private transient AutowireCapableBeanFactory beanFactory;
@Override
public void setApplicationContext(final ApplicationContext context) {
beanFactory = context.getAutowireCapableBeanFactory();
}
@Override
protected Object createJobInstance(final TriggerFiredBundle bundle) throws Exception {
final Object job = super.createJobInstance(bundle);
beanFactory.autowireBean(job);
return job;
}
}
}
2.6写一个dao访问数据库
java
package com.ealen.dao;
import com.ealen.entity.JobEntity;
import org.springframework.data.repository.CrudRepository;
/**
* Created by EalenXie on 2018/6/4 14:27
*/
public interface JobEntityRepository extends CrudRepository<JobEntity, Long> {
JobEntity getById(Integer id);
}
2.7.定义调度中心执行逻辑的Job,
这个Job的作用就是按照数据库中的Job的逻辑,规则去执行数据库中的Job。这里使用了一个自定义的枚举工具类StringUtils , StringUtils.class :
java
package com.ealen.util;
import java.util.List;
import java.util.Map;
/**
* Created by EalenXie on 2018/6/4 14:20
* 自定义枚举单例对象 StringUtil
*/
public enum StringUtils {
getStringUtil;
//是否为空
public boolean isEmpty(String str) {
return (str == null) || (str.length() == 0) || (str.equals(""));
}
//去空格
public String trim(String str) {
return str == null ? null : str.trim();
}
//获取Map参数值
public String getMapString(Map<String, String> map) {
String result = "";
for (Map.Entry entry : map.entrySet()) {
result += entry.getValue() + " ";
}
return result;
}
//获取List参数值
public String getListString(List<String> list) {
String result = "";
for (String s : list) {
result += s + " ";
}
return result;
}
}
调度中心执行逻辑的Job。
java
package com.ealen.job;
import com.ealen.util.StringUtils;
import org.quartz.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* Created by EalenXie on 2018/6/4 14:29
* :@DisallowConcurrentExecution : 此标记用在实现Job的类上面,意思是不允许并发执行.
* :注意org.quartz.threadPool.threadCount线程池中线程的数量至少要多个,否则@DisallowConcurrentExecution不生效
* :假如Job的设置时间间隔为3秒,但Job执行时间是5秒,设置@DisallowConcurrentExecution以后程序会等任务执行完毕以后再去执行,否则会在3秒时再启用新的线程执行
*/
@DisallowConcurrentExecution
@Component
public class DynamicJob implements Job {
private Logger logger = LoggerFactory.getLogger(DynamicJob.class);
/**
* 核心方法,Quartz Job真正的执行逻辑.
* @param executorContext executorContext JobExecutionContext中封装有Quartz运行所需要的所有信息
* @throws JobExecutionException execute()方法只允许抛出JobExecutionException异常
*/
@Override
public void execute(JobExecutionContext executorContext) throws JobExecutionException {
//JobDetail中的JobDataMap是共用的,从getMergedJobDataMap获取的JobDataMap是全新的对象
JobDataMap map = executorContext.getMergedJobDataMap();
String jarPath = map.getString("jarPath");
String parameter = map.getString("parameter");
String vmParam = map.getString("vmParam");
logger.info("Running Job name : {} ", map.getString("name"));
logger.info("Running Job description : " + map.getString("JobDescription"));
logger.info("Running Job group: {} ", map.getString("group"));
logger.info("Running Job cron : " + map.getString("cronExpression"));
logger.info("Running Job jar path : {} ", jarPath);
logger.info("Running Job parameter : {} ", parameter);
logger.info("Running Job vmParam : {} ", vmParam);
long startTime = System.currentTimeMillis();
if (!StringUtils.getStringUtil.isEmpty(jarPath)) {
File jar = new File(jarPath);
if (jar.exists()) {
ProcessBuilder processBuilder = new ProcessBuilder();
processBuilder.directory(jar.getParentFile());
List<String> commands = new ArrayList<>();
commands.add("java");
if (!StringUtils.getStringUtil.isEmpty(vmParam)) commands.add(vmParam);
commands.add("-jar");
commands.add(jarPath);
if (!StringUtils.getStringUtil.isEmpty(parameter)) commands.add(parameter);
processBuilder.command(commands);
logger.info("Running Job details as follows >>>>>>>>>>>>>>>>>>>>: ");
logger.info("Running Job commands : {} ", StringUtils.getStringUtil.getListString(commands));
try {
Process process = processBuilder.start();
logProcess(process.getInputStream(), process.getErrorStream());
} catch (IOException e) {
throw new JobExecutionException(e);
}
} else throw new JobExecutionException("Job Jar not found >> " + jarPath);
}
long endTime = System.currentTimeMillis();
logger.info(">>>>>>>>>>>>> Running Job has been completed , cost time : " + (endTime - startTime) + "ms\n");
}
//打印Job执行内容的日志
private void logProcess(InputStream inputStream, InputStream errorStream) throws IOException {
String inputLine;
String errorLine;
BufferedReader inputReader = new BufferedReader(new InputStreamReader(inputStream));
BufferedReader errorReader = new BufferedReader(new InputStreamReader(errorStream));
while ((inputLine = inputReader.readLine()) != null) logger.info(inputLine);
while ((errorLine = errorReader.readLine()) != null) logger.error(errorLine);
}
}
2.8为了方便控制Job的运行,为调度中心添加相关的业务逻辑 :
java
package com.ealen.service;
import com.ealen.dao.JobEntityRepository;
import com.ealen.entity.JobEntity;
import com.ealen.job.DynamicJob;
import org.quartz.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
/**
* Created by EalenXie on 2018/6/4 14:25
*/
@Service
public class DynamicJobService {
@Autowired
private JobEntityRepository repository;
//通过Id获取Job
public JobEntity getJobEntityById(Integer id) {
return repository.getById(id);
}
//从数据库中加载获取到所有Job
public List<JobEntity> loadJobs() {
List<JobEntity> list = new ArrayList<>();
repository.findAll().forEach(list::add);
return list;
}
//获取JobDataMap.(Job参数对象)
public JobDataMap getJobDataMap(JobEntity job) {
JobDataMap map = new JobDataMap();
map.put("name", job.getName());
map.put("group", job.getGroup());
map.put("cronExpression", job.getCron());
map.put("parameter", job.getParameter());
map.put("JobDescription", job.getDescription());
map.put("vmParam", job.getVmParam());
map.put("jarPath", job.getJarPath());
map.put("status", job.getStatus());
return map;
}
//获取JobDetail,JobDetail是任务的定义,而Job是任务的执行逻辑,JobDetail里会引用一个Job Class来定义
public JobDetail geJobDetail(JobKey jobKey, String description, JobDataMap map) {
return JobBuilder.newJob(DynamicJob.class)
.withIdentity(jobKey)
.withDescription(description)
.setJobData(map)
.storeDurably()
.build();
}
//获取Trigger (Job的触发器,执行规则)
public Trigger getTrigger(JobEntity job) {
return TriggerBuilder.newTrigger()
.withIdentity(job.getName(), job.getGroup())
.withSchedule(CronScheduleBuilder.cronSchedule(job.getCron()))
.build();
}
//获取JobKey,包含Name和Group
public JobKey getJobKey(JobEntity job) {
return JobKey.jobKey(job.getName(), job.getGroup());
}
}
2.9启动类
java
package com.ealen;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* Created by EalenXie on 2018/6/4 11:00
*/
@SpringBootApplication
public class QuartzApplication {
public static void main(String[] args) {
SpringApplication.run(QuartzApplication.class, args);
}
}
3.系统展示
运行效果如图 :

看到这里,说明Quartz集群已经搭建成功了。如果部署该项目应用到多个服务器上面,Job会在多个服务器上面执行,但同一个Job只会在某个服务器上面执行,即如果服务器A在某个时间执行了某个Job,则其他服务器如B,C,D在此时间均不会执行此Job。即不会造成该Job被多次执行。
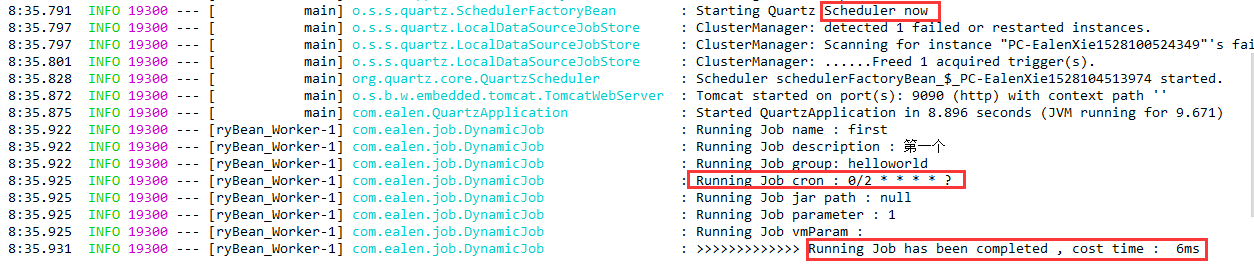
这里可以看到数据库中的Job已经在Quartz注册并初始化成功了,Scheduler也在工作了,Job也已经按照cron在定时执行。
本例中,如果job包含一个jar的路径,并且该jar包是一个可执行的JOB,则可以看到该JOB的运行情况 :
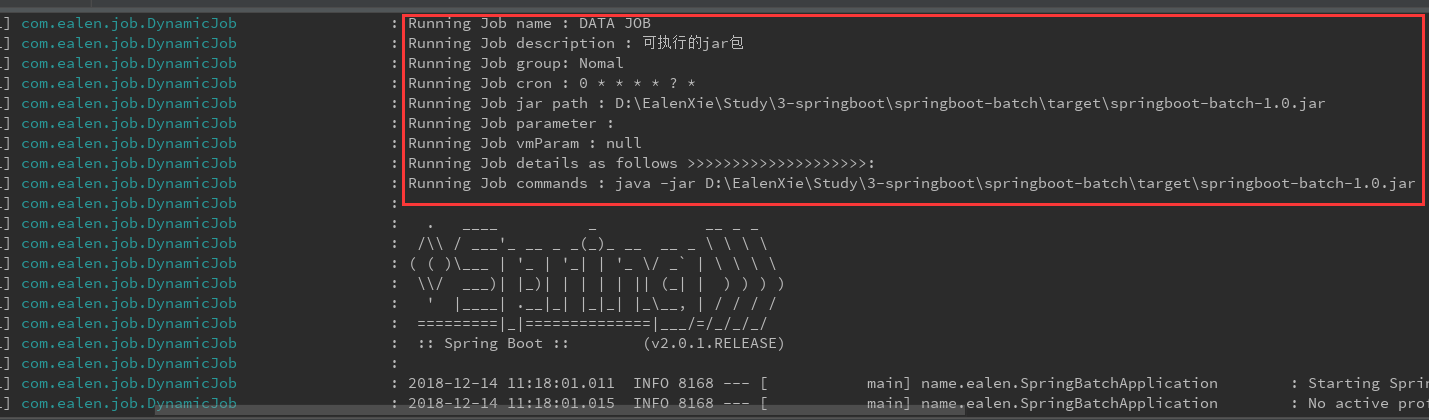
看到JOB已经执行完成了 :

此时如果在数据库中手动修改某个Job的执行cron,并不会马上生效,则可以调用上面写到的业务方法,/refresh/all,则可刷新所有的Job,或/refresh/{id},刷新某个Job。
4.注意. 在你启动该应用之前:
-
请自行修改数据库配置: /application.yml
-
请准备Quartz的元数据表 : quartz_innodb.sql
-
请为这个例子的Job配置准备一个表 : job_entity.sql
-
如果想要查看真实的jar包运行,请准备一个真实的jar包路径,并且该jar包是可执行的(有主程序运行清单),并设置该JOB的状态为OPEN。
参考文献
- 基于Zookeeper的大数据处理调度系统的设计与实现(华中科技大学·程庚)
- 面向异构平台的混合任务调度系统设计与实现(北京邮电大学·吴超宇)
- 基于Spring技术的大型视频网站后台上传系统的设计与实现(南京大学·徐悦轩)
- 基于Zookeeper的大数据处理调度系统的设计与实现(华中科技大学·程庚)
- 大数据应用调度系统的设计与实现(北京交通大学·何明光)
- 网络服务质量管理系统的设计与实现(华中科技大学·彭湃)
- 基于Dubbo框架的开发者中心的设计与实现(北京交通大学·涂鹏程)
- 基于Quartz的任务调度系统的设计与实现(南京大学·殷玮玮)
- 基于Zookeeper的大数据处理调度系统的设计与实现(华中科技大学·程庚)
- 面向异构平台的混合任务调度系统设计与实现(北京邮电大学·吴超宇)
- 基于SpringCloud微服务治理平台的设计与实现(北京邮电大学·祁晖)
- 基于Zookeeper的大数据处理调度系统的设计与实现(华中科技大学·程庚)
- 基于Dubbo框架的开发者中心的设计与实现(北京交通大学·涂鹏程)
- 基于共享计算资源的任务调度系统研究与设计(南京邮电大学·胡鹏)
- 基于Zookeeper的大数据处理调度系统的设计与实现(华中科技大学·程庚)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码货栈 ,原文地址:https://bishedaima.com/yuanma/35613.html