
基于Java的新闻热点与趋势挖掘工具
一、项目概述
1.1 项目简介
本项目为一个新闻站点文章爬取和分析工具,能够通过抓取一定时间内某个新闻网站上所发布的所有新闻,分析得出某些极具参考价值的数据结论如新闻热点和舆论变化趋势等等。本项目所实现的网络工具主要包含以下三个功能:
-
年度关键词分析:通过抓取和分析一年以来新闻站点所发布的文章内容,分析一年内最受关注的新闻热点词汇
-
热门词汇趋势:以月为单位呈现某些新闻要素的曝光率以及变化趋势
-
相关度分析:深度研究已经得到的数据,挖掘某些新闻要素所隐含的联系
1.2 优势比较
与其他产品相比较,本项目的特点和优势在于以下三个方面:
-
轻量级网络程序,数据抓取和统计工作可以同步进行
-
使用云计算平台,效率高,运行稳定
-
实时的数据采集和分析过程,灵活性好
1.3 技术难点
-
项目要求抓取某个新闻站点一年内所有的文档,因此需要设计一条合理的网站检索路径
-
对汉语文档进行词频统计首先需要对文档进行分词,词语分割是否准确直接影响之后的统计结果
-
某些常见的词语本身并无实际意义(如助词等),需要在统计过程中予以摒弃
二、文件结构说明
-
scrapy:网络爬虫代码
-
hdParse:hadoop处理爬虫结果,排序等等
-
result:网络数据爬取结果
-
infographic:数据分析结果信息图谱
-
presentation:项目展示材料
三、项目架构说明
本项目程序使用Java程序开发设计,程序包含数据爬取+数据分析两个环节的工作。项目使用阿里云平台作为运行环境,所有数据挖掘工作都将在云端执行,所获得的原始数据将在本地作进一步处理。
项目架构及运行流程如下图所示:
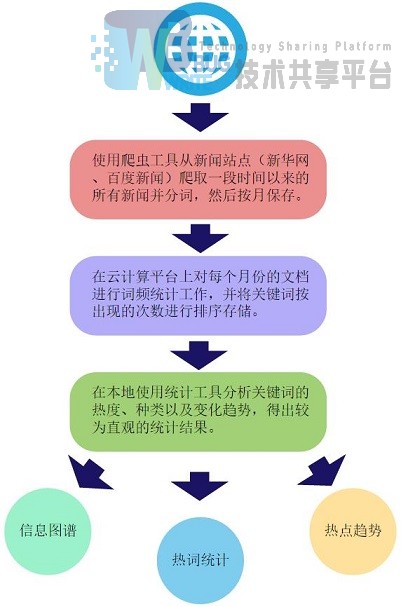
项目可分为以下三个部分:
3.1 网络数据爬取
使用设计完成的网络爬虫检索并爬取某个新闻站点(项目示例中为新华网和百度新闻)一年之内所发布的所有文章,并采集文章的正文文本进行分词按月份予以保存。
3.2 中文文档分析
使用Hadoop云计算框架对得到的新闻文本进行词频统计工作,统计出每个月以及全年的关键词出现频率,并加以排序处理。
3.3 本地结果统计
使用统计工具对所得到的原始数据进行加工和整理,得到可视性好、说服力强的统计结果(如信息图谱、折线图等等)。
四、资源引用
4.1 数据来源
本项目所使用的统计数据来自新华网以及百度新闻在2015年度所公开发布的所有新闻。
4.2 网络爬虫设计
网络爬虫的设计过程参考了开源项目WebMagic(https://github.com/code4craft/webmagic)的相关内容
4.3 文章分词功能
文章分词功能使用NLPIR汉语分词系统(http://ictclas.nlpir.org/newsdownloads?DocId=389)实现。
参考文献
- 基于J2EE的网络舆情分析系统的设计与实现(南京大学·李伟)
- 在线热点新闻推荐系统研究和实现(南京航空航天大学·许盛伍)
- 基于SSH2的新闻信息管理平台的设计与开发(青岛大学·张明瑛)
- 基于JSP的新闻发布系统的研究与实现(辽宁科技大学·魏欣)
- 基于J2EE技术的新闻发布系统的设计与实现(电子科技大学·胡小力)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 基于J2EE的网络舆情分析系统的设计与实现(南京大学·李伟)
- 基于SSH2的新闻信息管理平台的设计与开发(青岛大学·张明瑛)
- 基于多源社交媒体的热点舆情分析系统的设计与实现(北京邮电大学·梁娅)
- 基于SSH2的新闻信息管理平台的设计与开发(青岛大学·张明瑛)
- 基于多源社交媒体的热点舆情分析系统的设计与实现(北京邮电大学·梁娅)
- 基于用户日志的新闻推荐系统研究(吉林大学·高冉冉)
- 基于微博热点话题发现的关键技术研究(兰州交通大学·杨海波)
- 基于.NET架构的新闻发布管理系统的设计与实现(南昌大学·廖德伟)
- 基于twitter的个性化新闻推荐系统的设计与实现(华中科技大学·王俊)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码项目助手 ,原文地址:https://bishedaima.com/yuanma/35182.html









