基于JSP实现的网站站内检索系统
一、用户分析
1.1 中文系网站定位
北京大学中文系网站是北京大学中文系的官方主页,主要反映的是中文系师生的学习工作情况,同时又有中文系主要部门和大多数老师的职能介绍。在中文系网站首页,有以下几个板块:本系简介、动态新闻、本系公告、教工园地、学生园地、图书分馆、精品课程、教学科研、主办期刊、英文主页、中文论坛、网站管理。这些板块的内容大多是粗略地介绍中文系目前的情况,教职工、学生的工作学习生活,中文系官方的公告等。中文系网站主要面向的对象是北大中文系学生、有意向了解中文系的其他院系学生或校外人士。对于北大中文系学生,有价值的主要信息在于本系公告,他们能通过公告栏得知目前中文系的一些政策,对于非中文系的学生,简介和新闻则比较重要,他们会想要了解中文系大致的介绍,中文系一般的活动是怎样的,这些可以通过站内的这些内容进行查找。
1.2 检索系统的定位
我们做的检索系统是北大中文系的站内检索,搜索的所有内容都在站内,所以使用北大中文系网站的用户都是检索系统的用户。对于用户来说,有价值的内容主要是每一篇文章的标题和内容,在每一个网页中,只有这两部分是最有价值的,而其他的链接等,对用户而言,没有检索意义。如在上图中,导航栏的链接内容对于用户而言是没有意义的,有意义的是标题“北京大学中文系简介”,“日期”,“信息来源”和下面的正文内容。这些有检索价值的信息决定了我们在设计网页解析时要解析的内容,查看源代码可以发 现,图 1 的内容是我们并不需要的。这些内容是导航中的内容,所以我们并不把它们纳入检索范围。图 2 中的主要内容才是我们检索的对象。在后续的过程中,我们将这些内容爬下来并进行存储,然后利用工具进行切词、建立索引、检索。总而言之,这些有着实在意义的内容和标题,才是我们在建立信息系统过程中的处理对象。
** 导航菜单源代码**

正文内容源代码

1.3 用户定位

上面已经说到,使用我们的检索系统的用户是使用北大中文系网站的所有用户。在分析用户定位前,我们可以将用户群体分为北大中文系学生和非北大中文系用户。
1.3.1 北大中文系学生
对于北大中文系的学生而言,他们对本系较为了解,对本系的大致情况并没有很大的兴趣,主要的信息需求是一些确切的信息。比如他们会想要了解中文系寒假值班的具体情况,或者关于本系某一活动的具体信息。这些用户的信息需求是明确的,这种信息需求通过检索行为表达出来,就是较为明确的查询行为,且这类用户的检索水平较高,专业知识较高。所以我们提供了标题检索和全文检索,标题检索可以帮助用户可以快速准确查到特定的信息(因为官方网站的标题往往直接反映主题内容),而全文检索则有助于帮助用户定位内容中的确切信息。
1.3.2 非北大中文系用户
非北大中文系的用户往往会比较想要了解一些关于北大中文系的介绍,或者是关于部分老师的介绍,他们的信息需求较为宽泛且并不是很明确,对于检索结果也不要求精确定位,他们的潜在信息需求往往会在浏览网页时渐渐明确。比如他们会直接搜索“北大中文系”或者是搜索某位老师的名字比如“孔庆东”。对这类用户而言,全文检索比较适合他们,且他们较为宽泛的检索词往往会导致较多的检索结果。我们通过相关性的排序,保证相关性高的检索结果排在最前面,使用户在浏览查询结果时,能够获得相关性最高的信息,满足自身的信息需求。
二、工具选择
2.1 爬虫
2.1.1 Nutch
总体上 Nutch 可以分为 2 个部分:抓取部分和搜索部分。抓取程序抓取页面并把抓取回来的数据做成反向索引,搜索程序则对反向索引搜索回答用户的请求。抓取程序和搜索程序的接口是索引,两者都使用索引中的字段。抓取程序和搜索程序可以分别位于不同的机器上。
抓取程序是被 Nutch 的抓取工具驱动的。这是一组工具,用来建立和维护几个不同的数据结构: web database, a set of segments, and the index。
The web database,或者 WebDB,是一个特殊存储数据结构,用来映像被抓取网站数据的结构和属性的集合。WebDB 用来存储从抓取开始(包括重新抓取)的所有网站结构数 据和属性。WebDB 只是被抓取程序使用,搜索程序并不使用它。
Segment,是网页的集合,并且它被索引。Segment 的 Fetchlist 是抓取程序使用 的 url 列表,它是从 WebDB 中生成的。Fetcher 的输出数据是从 fetchlist 中抓取的网页。The index。索引库是反向索引所有系统中被抓取的页面,它并不直接从页面反向索引产生,而是合并很多小的 segment 的索引产生的。Nutch 使用 Lucene 来建立索引,因此所有 Lucene 相关的工具 API 都用来建立索引库。
抓取是一个循环的过程:抓取工具从 WebDB 中生成了一个 fetchlist 集合;抽取工具根据 fetchlist 从网络上下载网页内容;工具程序根据抽取工具发现的新链接更新 WebDB;然后再生成新的 fetchlist;周而复始。一般情况下,我们不需要接触底层的工具,只要从头执行程序就可以了。
在进行了相应的系统配置后,将会得到如图 4 的文件夹,并且将 Nutch.war 放到 Tomcat 中,进行一定的配置,运行界面。
nutch 爬取收文件夹
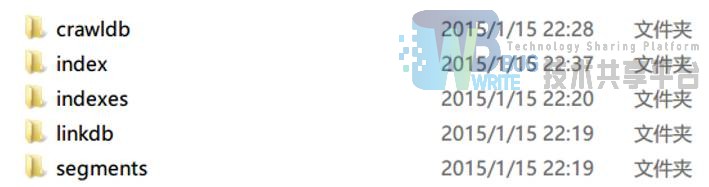
nutch 检索结果界面 1
nutch 检索页面 2

我们发现已经实现了一定程度上的站内检索图 5 图 6,但是我们最后放弃了这样的做法,一方面是想要自己动手走一遍流程,另外一方面认为这样的检索效果并不令人满意。当然可以对其进行进一步的定制,例如使用更好的切词,在深度和广度上进行进一步的设置等。
2.1.2 不用 Nutch 转用 Heritrix 的原因
Nutch 虽然不必我们接触底层的工具,但是处理起来也是非常繁琐,所以我们开始考虑换一种爬虫工具,即 Heritrix。
总体来说 Heritrix 网络蜘蛛的功能更为强大,而 Nutch 更好地支持搜索引擎(与 Lucene 紧密结合)。两者特点对比如下:
Nutch 是一个搜索引擎框架。
| Nutch | Heritrix | |
|---|---|---|
| 功能 | 获取保存索引内容 | 下载,爬取 |
| 类型 | 可索引部分 | 各种类型 |
| 任务 | 合并索引 | 任务管理 |
| 管理 | 命令行 | WEB定制界面 |
| 控制 | 参数少 | 灵活 |
Heritrix 中有几个关键模块:下载控制器 CrawlController,这是总近控部分,以主线程形式运行。通过调试,把下载地址管理器 Frontier 中地址列表传递给线程池中的 ToeThreads,完成下载任务;边界控制器 Frontier。用来确定下一个将抓取的网页。实现对网站访问的均衡处理,避免多线程同时访问同一个网站造成网站压力;服务器缓存 Servercache。实现搜索引擎中的 DNS 缓存。
除去使用开源的工具之外,我们也利用老师给的例程,通过对部分关键语句的修改,自己做了爬虫,但是效果并不理想,因此最终决定使用 heriTrix 爬虫工具。并进行一定程度上的定制,采用的是镜像保存。最后爬虫的结果保存在 chinese.pku.edu.cn 文件夹中。
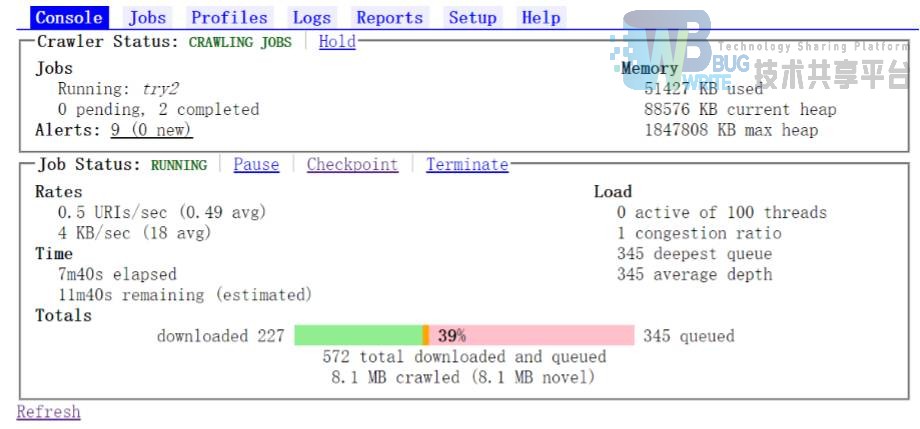
并借这个过程,我们对于信息管理系的网站也进行了爬取,两个系的网站结构上比较类似,不过,内容上,中文系的网站还是要多一些,并且网站本身在一定程度上可能还需要进一步在信息架构上进行优化。信息架构通过组织系统,导航系统,检索系统,标签系统,更好的管理查找信息,中文系的网站缺乏站内检索,而信息管理系的网站,在检索上,对于切词和排序可能需要更好的优化。如图 8,对于刘畅老师的检索,虽然刘畅老师的页面排在第一行,但我们发现,作为一个整体的词条,或许这样的检索结果还是需要更多的考虑。
信息管理系站内检索“刘畅”结果页面

2.2 网页解析
随意打开中文系网站的一个页面,如动态新闻里面的“北大中文系海外名家讲座系列— —郭实腊,英国圣教书会出版物与传教士中文小说”,会发现中文系的网站结构设计地非常简单,除 去上方各种不同的链接之外,就只剩位于中部的主要内容了,因此网页解析比较简单。
在网页解析这一步骤中,我们也是使用的开源工具 HTMLParser,这是一个小巧的网页解析工具,只是相关文档较少,很多功能需要自己模索。通过查阅资料,我们了解到,HTMLParser 的核心模块 org.htmlparser.Parser 类,这个类完成了对于 HTML 页面的分析工作。HTMLParser 遍历网页内容后,可以依据 HTML 文件以树状结构组织数据的特点,得到以树(森林)结构保存的结果。
在解析网页这一过程中,我们还使用了 Tika 框架进行网页解析,Apache Tika 可以利用现有的解析类库,从不同格式的文档中(例如 HTML, PDF, Doc),侦测和提取出元数据和结构化内容。它可以侦测文档的类型,字符编码,语言,等其他现有文档的属性;提取结构化的文字内容。
在最终的比较中,我们认为 HTMLParser 更好用,但舍弃了 Tika 框架,可能还是觉得更加适合我们的任务本身,当然如果在后期对于网站中的 doc 文件也建立索引,使用 Tika 显然也是极好的。并且有利于我们进一步掌握更多的文件的解析方法。
2.3 切词工具
分词准确性对搜索引擎来说十分重要,对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。但在我们的检索系统中,并不是动态的,所以在一定程度上,对于准确性的要求更高。切词建索引方面,我们结合课程和老师给的例子,使用了老师推荐的 IKAnalyzer 作为切词的工具,并进行相关业务的定制,以便更好的满足我们的需求。主要包括对于停用词表的定制等。
三、爬建查索
3.1 爬
爬虫,如前文提到的,我们首先使用了 Nutch 作为爬虫工具,实现了一定程度的检索,而在 Nutch 需要 Linux 环境支持,所以安装了 Cygwin64 Terminal,然后定制了 http://chinese.pku.edu.cn ,之后进行
bin/nutch crawl urls/url.txt -dir crawled -depth 4 -threads 5 -topN 1000 >&logs/log1.log
即深度为 4 线程为 5 的爬取,利用 1.2 版本自带的检索工具,进行了检索,页面如图 5 图 6。这个过程中,我们发现,可以使用 solr 工具进行检索,并且在 Nutch1.2 以上的版本中,不再携带检索的页面,而是将业务分给 solr。Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于 Web-service 的 API 接口。
但是,这些底层的封装,不利于我们进一步理解检索系统,因此,我们决定自己动手做 一个检索系统。而爬取是我们的第一步。我们的想法是将网页整体镜像爬下来,然后再考虑对镜像文件进行分析,建立索引。
我们尝试修改老师的爬虫程序,已达到自己的定制过程,但是限于精力和时间,并且对于我们的系统而言,重心是索引本身,另外,以 heritrix 为代表的开源爬虫工具比较成熟,老师上课鼓励使用开源工具,因此,我们使用了 heritrix 工具,用镜像的方式保存到本地。安装过程比较麻烦,已打包为 H1 项目,启动后,将会进入 web 的定制页面。其中需要指出的是,这个过程中对于 Jdk 的版本有一定的限制。需要 JDK1.5 以上版本。
3.2 建
将爬虫的信息导入到数据库中,以数据库为中间载体,建立全文索引,而如何将如图所示的大量网站中提取有价值的 htm 文件,并对文件进行解析是建立索引的准备工作。
中文系网站结构
** doc 文件夹中的部分截图 **
首先,根据用户需求,爬虫爬下来的网站中,存在很多文件,包括 js,css,甚至有许多的 word 文件,是该网站的文章,而我们的定位里,将这部分信息暂时并不包含在检索中,当然,如果进一步提高检索的检全率,这部分也是可以使用相应的工具进行解析的。因此,锁定网站中的 htm 文件,并指明为类似 4375.htm、4539.htm 等数字开头的文件,而不是 index1.htm 等目录文件。
具体代码为用一个队列进行本地的广度优先的变量,通过正则表达式,判断其是否为满足要求的文件,对于文件进行解析。

而文件的解析,是根据网站结构而言的,在前文已经提到,便不再赘述,主要通过
java
NodeFilter filter1=new AndFilter(new TagNameFilter("div"),new HasAttributeFilter("class","content"));
NodeFilter filter2= new AndFilter(new TagNameFilter("p"),new HasAttributeFilter("class","detail-p"));
NodeFilter filter3= new CssSelectorNodeFilter("h2"); NodeFilter filter4=new AndFilter(new TagNameFilter("div"),new HasAttributeFilter("class","detail-size"));
通过对于相应的 div 或者元素选择器,建立 filter 类,而将这些解析后的代码通过本地文件或数据库保存起来,而在本程序中使用的是 Mysql 数据库进行保存,便于进一步的开发和利用,值得一提的的是,在提取日期时,使用了正则表达式,对于非数字的文本进行了剔 除 ,最后导入数据库中,如图所示。
**数据库表单部分截图 **
其中,在 content 字段中,有许多的 nbsp,这里我们的做法是保留空格  等,而在停用词表中进行过滤,当然,也可以在进行网页解析的时候进行处理,这里不同的做法,体现不同的想法,并不是有真正的对错之分。我们的想法是在恢复原文的时候,将会出现想要的空格等,更加倾向于保存文本信息,而后者则是更注重有价值的信息文本。
3.3 查
如果单纯进行数据库的检索,其实已经可以建立一个对应的数据库的检索系统,但是我们觉得检索的效率,查询的准确性,排序算法的优化等,可能并不是令人满意的,并且数据库的 like 的数据结构是 Hashmap,查询效率上而不及以 Idf,倒排索引为主要结构的的 lucene,因此,在上述的条件下,建立 lucene 索引为检索系统的主要工具是有必要的。建立索引采用的切词工具是 IKAnalyze,因此在给出的代码包中,有 testanalyzer 包,用来测试停用词表等,基本上,满足我们对于切词的需要,当然,我们定制了一定程度上的的停用词表,将前文提到的 nbsp 等噪音去掉了,不过值得一提的是,对于人名的处理,可能还需要用词表进行,因为对于许多教授的简介,切开可能并不是好的处理方式。

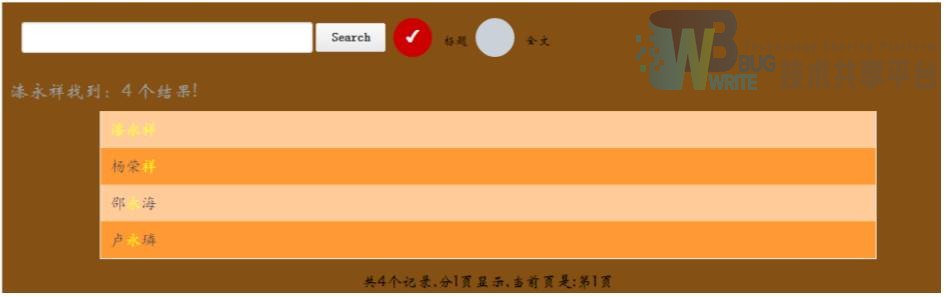
例如对于漆永详,切词将其进行了切开,或许,这并不是最好的处理方式。
Field id2=new Field("id",id1,Field.Store.YES,Field.Index.NO,Field.TermVector.NO); doc.add(id2);
Field title2=new Field("title",title,Field.Store.YES,Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS); doc.add(title2);
Field URL2=new Field("URL",URL,Field.Store.YES,Field.Index.NO,Field.TermVector.NO);
doc.add(URL2);
Field date2=new Field("date",date,Field.Store.YES,Field.Index.NO,Field.TermVector.NO);
doc.add(date2);
Field content2=new Field("content",content,Field.Store.YES,Field.Index.ANALYZED,Field.Term Vector.YES);
doc.add(content2);
对于标题和全文需要提供检索,因此对于词向量进行了处理,以便后面的高亮的工作能够正常进行。而在 buildtheindex 包中,我们写了一段小代码进行检验,结果如下。
buildtheindex 运行代码

在这个基础上,我们进一步写对于代码进行优化,在 querytheindex 包中,我们对于高亮进行了处理与测试,高亮是 Lucene 的一个扩展功能,默认为 标签,100,我们通过

对于检索到的 content 内容进行高亮处理,将相应位置的文本通过 CSS 输出,结果如下

通过上图结果能够发现,对于想要的查询字段成功实现了高亮的功能。
以上,是对于站内检索的准备工作。通过准备工作,完成了许多功能模块的测试,而如何将其成功的在网页的前段展示出来,是进行前段与用户交互的功能模块。
3.4 索
Luccene 提供了许多的工具,根据我们的自身情况,我们选择了默认的相关度排序,并且没有使用过滤器,查询结果通过 TopDoc 进行输出和展示,查询的过程并不复杂,而在前段交互中,需要提出的问题是,常常用户的检索结果会有成百上千条,而如何进行分页,是需要在开发的时候考虑的问题,常用的分页的办法是以会话的形式,或者每次进行新的检索,这里需要一提的是,对于一个检索系统而言,用户点击超过 10 页的可能性结果极低,因此使用会话其实在一定程度上并不那么恰当,因此我们的做法是每一次下一页进行一次新的检索,并且由于 lucene 的高效检索,是比较适合我们的做法。
因此网站结构很简单,并不需要累赘的 servlet,一个 JavaBean 就实现了我们想要的功能,当然在这个 JavaBean 中需要定制一定程度的方法。主页包括对于每一个页,进行相应页的提取。而结合前文提到的高亮,再次进行了一些定制

这样就实现了对于高亮的后台工作,而在前段定制界面时,我们的考虑是两个方面,一方面使用了接近中文系的 CSS,保留了其 footer 和 Header 的图片,另一方面,对于主体部分进行自己的定制。当然,限于时间和精力,在前段页面的美化上还有大量的工作要做,但是已经完成了一定程度的界面的展示功能。
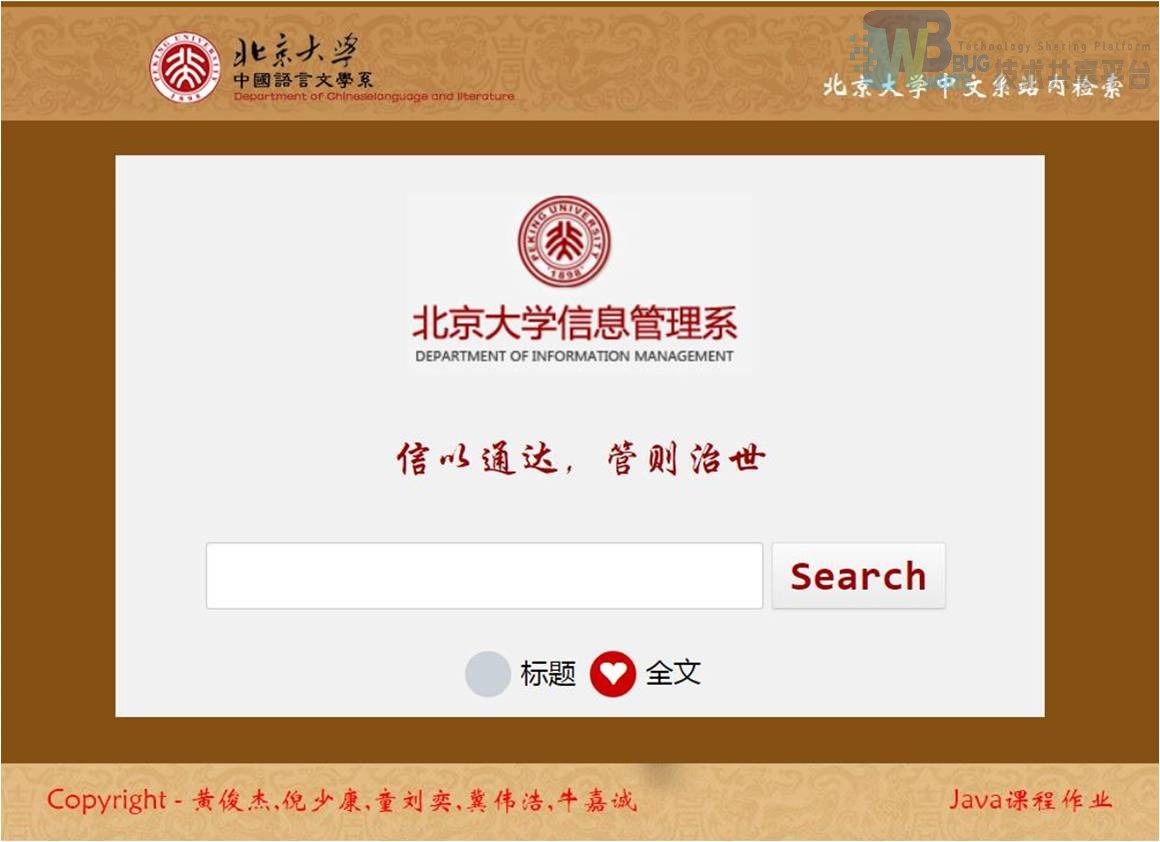
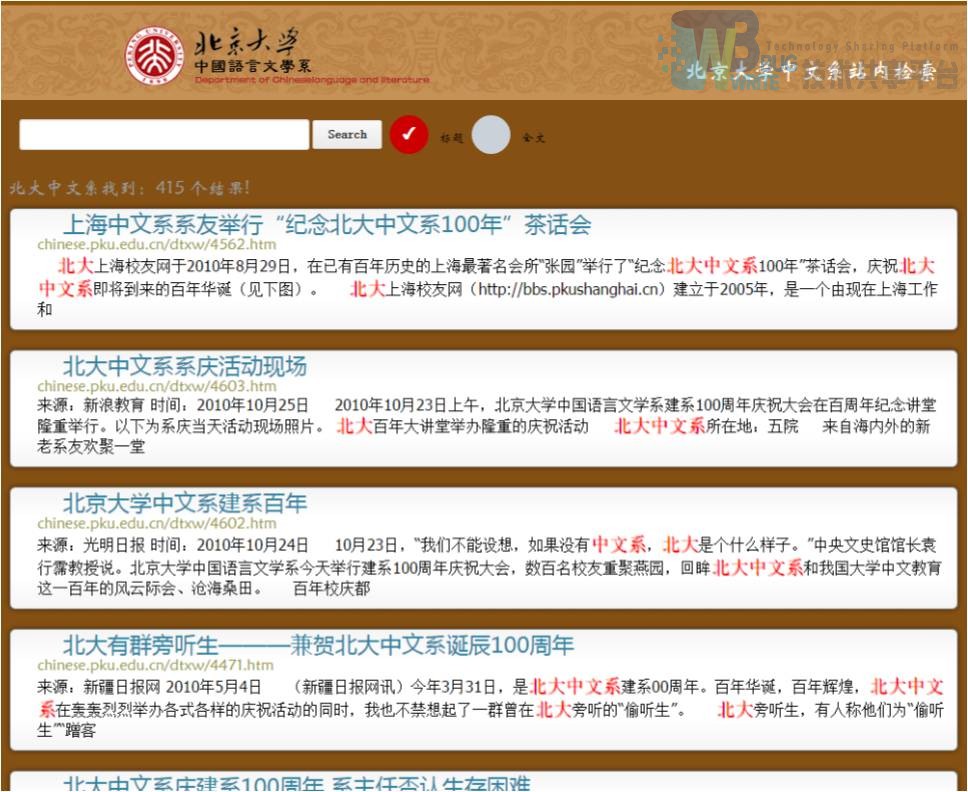
四、系统评价
我们主要通过系统自身的效率和与其他检索系统对比进行系统的评价,同时,我们还进行进一步的反思,为我们系统未来的改进提出了设想。
4.1 检全率与检准率
检索系统的检全率和检准率是评价信息系统的重要指标。检全率是指系统实施检索时检出的于某一检索提问相关的信息资源量与检索系统中与 该提问相关的实有信息资源总量之比,可以表示为
检全率 = 检出相关信息资源量÷系统相关信息资源量×100%
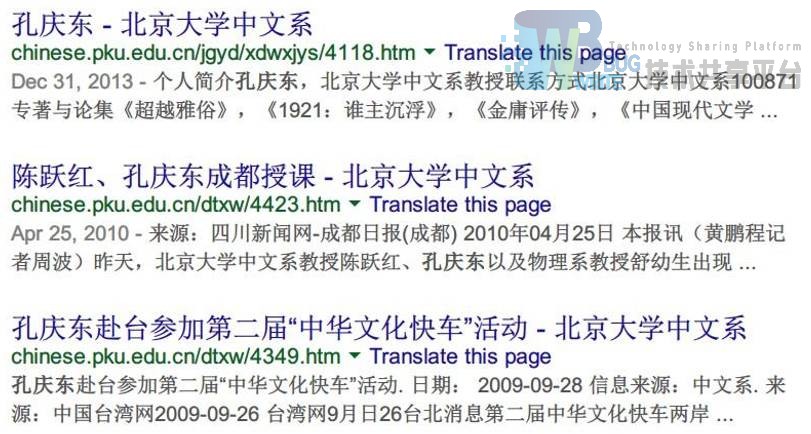
以检索“孔庆东”为例,通过百度检索出中文系网站内的资源是 10 条,通过谷歌检索出中文系网站内的相关资源是 13 条,通过我们自己的检索系统检出 12 条,在检全率这一指标上,谷歌比我们的检索系统高,而百度则比我们的检索系统低。百度没有查到“孔庆东赴台”的新闻,而谷歌比我们多查到一条资源,如图所示。究其原因,是谷歌比我们多做了目录页的索引。而在我们的定位分析中,我们认为并不需要做目录页。这就造成了我们和谷歌检索的结果的差异。
Goolge 多出的检索结果

检准率是指系统实施检索时检出的与某一提问相关的信息资源量与检出的信息资源总量之比,可以表示为
检准率 = 检出相关信息资源量÷检出信息资源总量× 100%
同样以检索“孔庆东”为例,在这个例子中,百度、谷歌和我们自己的检索系统查到的所有信息资源量都与孔庆东有关,也就是说,检准率都是 100%,是比较高的,当然这和信息资源本身容量较小也有关。
检全率与检准率两者本身也具有一定的关系,在大多数情况下,检全率与检准率具有一定的互逆关系,这在大多数系统中都通过排序的方式进行,我们的系统也不例外。我们使用的是向量空间模型的算法,通过“tf*idf”的计算方式,根据检索词和检索结果的匹配程度进行排序,保证相关性较高的检索结果排在前面,便于检索结果的展示,提高检全率和检准率。
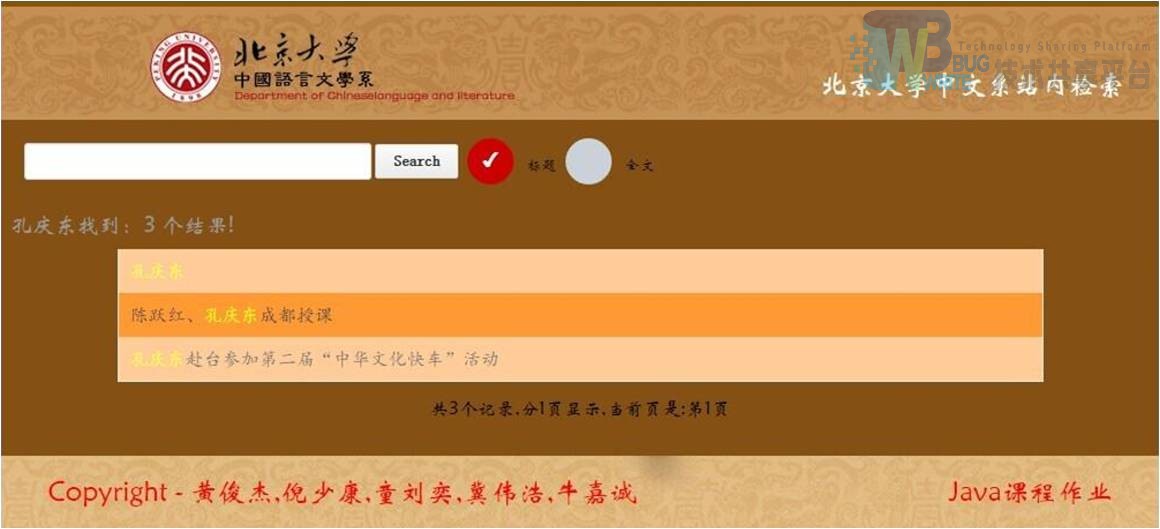
仍以检索“孔庆东”为例,下图是百度、谷歌和我们的检索系统给出的排序,值得一提的是,我们的检索系统通过标题查询的排序与谷歌是一样的,和百度有一定差别,且百度比我们的检索结果少了一个,从这个结果而言,我们的结果接近谷歌检索系统,优于百度的检索效果。
百度查询结果排序

谷歌查询结果排序
我们的检索系统排序(标题检索)
由于我们的检索系统是一个小型的检索系统,信息资源量非常小,所以在检全率和检准率方面,我们比较看重的是检全率,在信息资源量不多的情况下,如何使检索出来的结果尽可能多,尽可能包含所有相关信息资源,是我们比较关心的问题。通过一系列的测试,我们认为我们的检索系统的检全率还是比较高的。
4.2 检索速度与易用性
评价信息系统的另一个主要方面是检索速度与易用性。 信息系统的检索速度是指用户实施检索时获得检索结果花费的时间。通过测试,可能是由于检索的资源量较少,且我们使用倒排档的索引方式,所以我们的检索速度比较快,能够及时反馈给用户他们的检索结果。 信息系统的易用性对用户而言是指检索系统是否易于使用,一般会具体到操作、界面等方面,也包括容易获取信息的程度。在我们的检索系统中,操作非常简单,检索方式只有两种——标题检索和全文检索,用户只要输入想要检索的内容,系统会自动将用户指令切词,然后进行匹配检索,迅速给出结果;界面非常友好,我们的界面同时体现了中文系深厚的底蕴和信息管理系的职责使命,对于用户而言,这样的检索系统用着会比较舒服;查询结果直接点击可以进入原网站,信息获取非常容易。
4.3 改进空间
在检索系统的构建过程中,我们遇到了一系列问题,最终总算完成了作业。检索系统的很多地方都是使用开源软件,便于我们的修改和完善。在我们的检索系统中,还存在一定的不足。我们建立索引的项目并没有做到完全覆盖。如文章中的时间信息我们没有单独的提取出来建立索引,这就限制了结果展示更丰富的维度。此外,网站中以附件形式存在的 Doc 文档我们采取了存储的方式,也没有解析、建立索引。未来可以对这些文件中的信息也覆盖来提供检索。
4.4 感想
我们整体的项目框架采取了 MVC 结构,这样的结构使得我们在项目进行时的思路更为清晰。后期随着合作的进行和调整,我们将 M(Model)和 C(Controller)合并到了一个 JavaBean 之中,将 V(View)单独设置在了 JSP 中。
在系统的建设过程中,通过团队合作,交流,进一步加深了我们的团队合作精神,另外在这个过程中,我们采用了很多的开源工具,一定程度上,加深了我们的难度,但我们也因此收获很多,了解了许多成熟的技术。作为信息管理系的学生,我们发现自己需要进一步提高的地方还有很多,不断的学习的过程将会让我们在信息的处理的能力上有更多的提高。这也是我们认为在整个项目中最为重要的部分。
参考文献
- 基于J2EE的手机综合网站的设计与实现(吉林大学·宋微)
- 基于Lucene技术搜索引擎设计与实现(吉林大学·张阳)
- 沈阳超高压局通信设备运行参数管理信息系统(大连理工大学·杨楠)
- 基于三层体系结构的网络搜索与信息处理系统(广东工业大学·梁继能)
- 校园网有害信息监测系统设计与实现(西南交通大学·杨亚群)
- 基于JSP的辽宁大学毕业设计指导系统的设计与实现(吉林大学·王一凡)
- 基于Web Service的企业搜索引擎的架构及优化(吉林大学·吴学义)
- 基于JSP技术的学生宿舍管理系统的设计与实现(沈阳工业大学·杨俊宝)
- 基于Java平台的网络资源搜索系统的设计与实现(电子科技大学·李梦雅)
- 在线人才招聘系统实现研究(吉林大学·孙将超)
- 校园网有害信息监测系统设计与实现(西南交通大学·杨亚群)
- 网上交易系统的设计与实现(厦门大学·杨云)
- 基于JSP技术动态教学管理系统设计与实现(电子科技大学·董豪)
- 校园网有害信息监测系统设计与实现(西南交通大学·杨亚群)
- 基于JSP的测井资料网络查询系统的设计与实现(吉林大学·王东来)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码货栈 ,原文地址:https://bishedaima.com/yuanma/35162.html